小白学Pytorch 系列–Torch API
Torch version 1.13
Tensors
TORCH.IS_TENSOR
如果obj是PyTorch张量,则返回True。
注意,这个函数只是简单地执行isinstance(obj, Tensor)。使用isinstance 更适合用mypy进行类型检查,而且更显式-所以建议使用它而不是is_tensor。
obj (Object) – Object to test
True if obj is a PyTorch tensor.
import torch
x = torch.tensor([1,2,3])
is_t = torch.is_tensor(x)
print(is_t)
TORCH.IS_STORAGE
判断是否是存储对象

x = torch.tensor([1,2,3])
is_s = torch.is_storage(x)
print(is_s)
TORCH.IS_COMPLEX
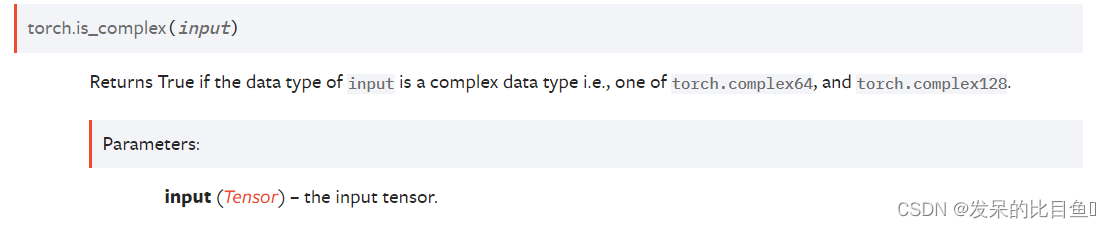
此方法的意思是如果输入是一个复数数据类型(例如torch.complex64或者 torch.complex128)就返回True,否则返回False。
import torch
a = torch.tensor([1, 2], dtype=torch.float32)
b = torch.tensor([3, 4], dtype=torch.float32)
z = torch.complex(a, b)
print(z)
print(z.dytpe)
print(torch.is_complex(z))
TORCH.IS_CONJ
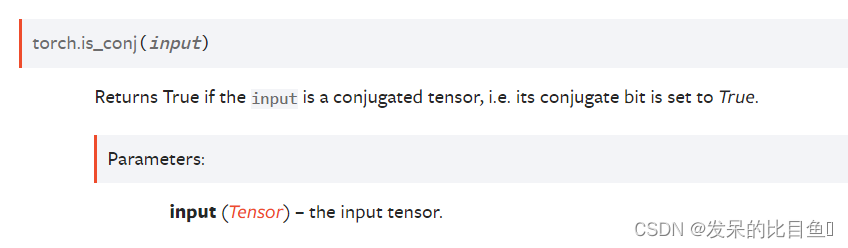
如果输入是一个共轭张量,即它的共轭位被设置为True,则返回True。
x = torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j])
x.is_conj()
y = torch.conj(x)
tensor([-1.-1.j, -2.-2.j, 3.+3.j])
y.is_conj()
TORCH.IS_FLOATING_POINT
判断给定的input中data的值是不是浮点类型
import torch
a = torch.tensor([1, 2], dtype=torch.float16)
torch.is_floating_point(a)
TORCH.IS_NONZERO
判断一个标量是不是为0, 不能使用多维度张量。
torch.is_nonzero(torch.tensor([0.]))
torch.is_nonzero(torch.tensor([1.5]))
torch.is_nonzero(torch.tensor([False]))
torch.is_nonzero(torch.tensor([3]))
torch.is_nonzero(torch.tensor([1, 3, 5]))
torch.is_nonzero(torch.tensor([]))
TORCH.SET_DEFAULT_DTYPE

设置pytorch中浮点数的默认类型。pytorch中有很多浮点类型,例如torch.float16、torch.float32、torch.float64这些在初始化一个浮点tensor的时候是可以指定的,如果我们不指定,那么pytorch就是默认给其一个类型,此方法的作用就是指定pytorch默认给不指定浮点类型的浮点数哪个类型。
torch.set_default_dtype(torch.float64)
set_default_tensor_type
设置pytorch中张量的默认类型
torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32
torch.set_default_tensor_type(torch.DoubleTensor)
torch.tensor([1.2, 3]).dtype # a new floating point tensor
numel

返回input中的元素个数
a = torch.randn(1, 2, 3, 4, 5)
torch.numel(a)
a = torch.zeros(4,4)
torch.numel(a)
set_printoptions

打印时显示浮点tensor中元素的精度(显示到小数点后几位),默认是4
# Limit the precision of elements
torch.set_printoptions(precision=2)
torch.tensor([1.12345])
# Limit the number of elements shown
torch.set_printoptions(threshold=5)
torch.arange(10)
# Restore defaults
torch.set_printoptions(profile='default')
torch.tensor([1.12345])
torch.arange(10)
set_flush_denormal
使CPU上不正规的浮点数失效。
torch.set_flush_denormal(True)
torch.tensor([1e-323], dtype=torch.float64)
torch.set_flush_denormal(False)
torch.tensor([1e-323], dtype=torch.float64)
Creation Ops
TORCH.TENSOR
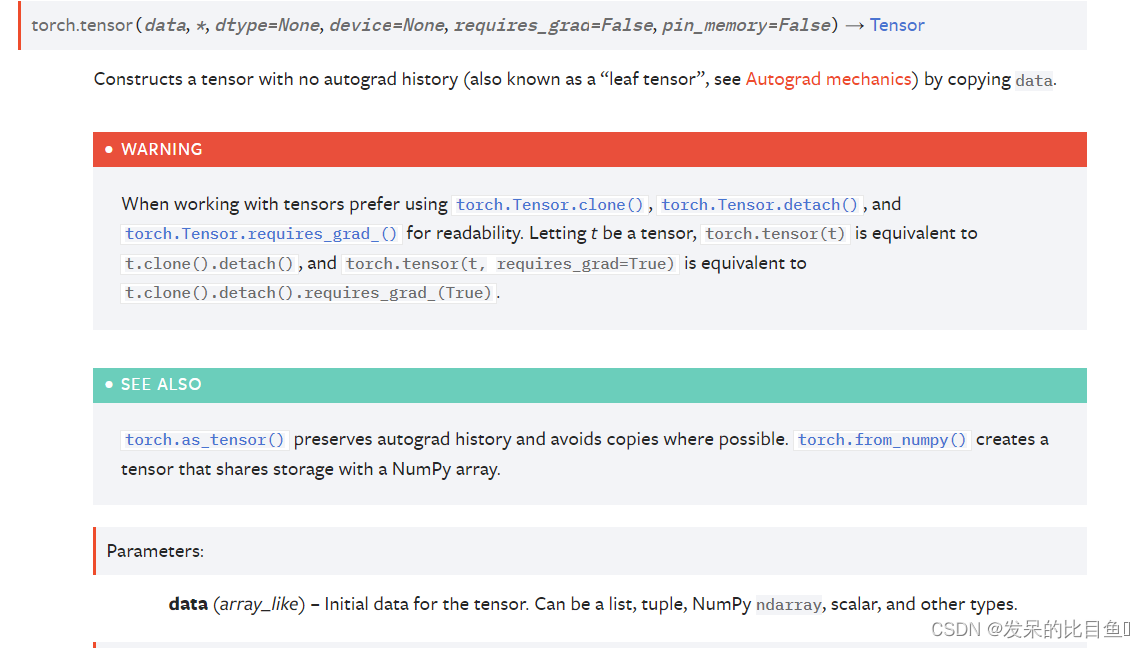
dtype (torch.dtype, optional)– t返回张量的期望数据类型。默认值:如果为None,则从数据推断数据类型。device (torch.device, optional)– 构造张量的装置。如果None且data是一个张量,则使用data的设备。如果None且data不是一个张量,那么结果张量将在CPU上构造。requires_grad (bool, optional)– 如果autograd应该记录对返回张量的操作。默认值:False。pin_memory (bool, optional)– 如果设置,返回的张量将被分配到固定内存中。仅适用于CPU张量。默认值:False。
torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
torch.tensor([0, 1]) # Type inference on data
torch.tensor([[0.11111, 0.222222, 0.3333333]],
dtype=torch.float64,
device=torch.device('cuda:0')) # creates a double tensor on a CUDA device
torch.tensor(3.14159) # Create a zero-dimensional (scalar) tensor
torch.tensor([]) # Create an empty tensor (of size (0,))
TORCH.SPARSE_COO_TENSOR
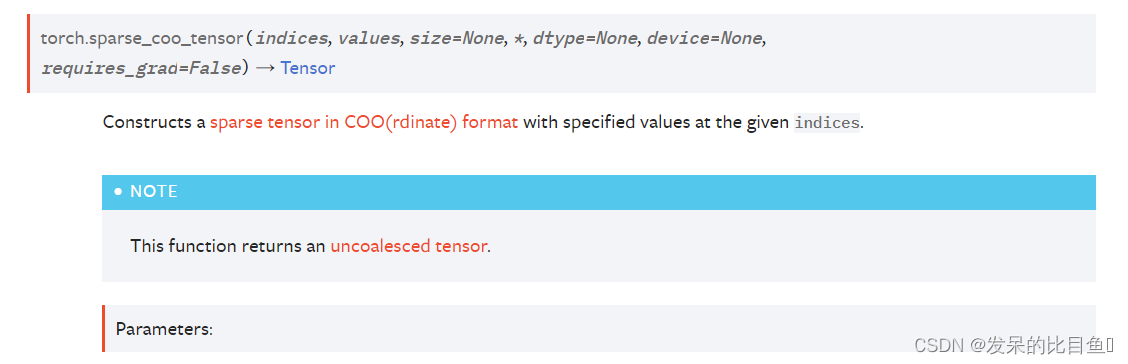
构造一个在给定索引处具有指定值的COO(径向)格式的稀疏张量。
参数
indices (array_like)张量的初始数据。可以是列表、元组、NumPy ndarray、标量和其他类型。将在内部转换为一个torch.LongTensor。索引是矩阵中非零值的坐标,因此应该是二维的,其中第一个维度是张量维度的数量,第二个维度是非零值的数量。values (array_like)张量的初值。可以是List、Tupe、NumPy ndarray、标量和其他类型。size (list, tuple, or torch.Size, optional)稀疏张量的大小。如果没有提供,则大小将被推断为足以容纳所有非零元素的最小大小。
关键字参数
dtype (torch.dtype, optional)返回张量的期望数据类型。默认值:如果为None,则从值推断数据类型。device (torch.device, optional)返回张量的期望单位。Default:如果为None,则使用当前设备作为默认张量类型(参见settorch.set_default_tensor_type())。device将是CPU张量类型的CPU, CUDA张量类型的当前CUDA设备。requires_grad (bool, optional)如果autograd应该记录对返回张量的操作。默认值:False。
i = torch.tensor([[0, 1, 1],
[2, 0, 2]])
v = torch.tensor([3, 4, 5], dtype=torch.float32)
torch.sparse_coo_tensor(i, v, [2, 4])
torch.sparse_coo_tensor(i, v) # Shape inference
torch.sparse_coo_tensor(i, v, [2, 4],
dtype=torch.float64,
device=torch.device('cuda:0'))
S = torch.sparse_coo_tensor(torch.empty([1, 0]), [], [1])
S = torch.sparse_coo_tensor(torch.empty([1, 0]), torch.empty([0, 2]), [1, 2])
TORCH.ASARRAY
将obj转换为一个张量。
Obj可以是其中之一
- a tensor
- a NumPy array
- a DLPack capsule
- an object that implements Python’s buffer protocol
- a scalar
- a sequence of scalars
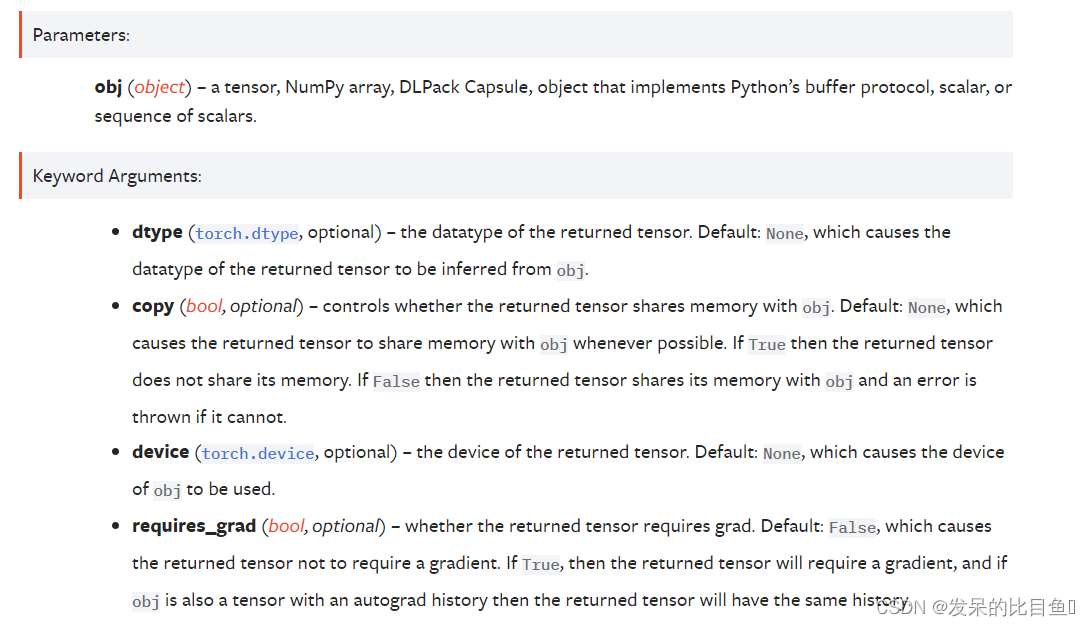
当obj是一个张量、NumPy数组或DLPack胶囊时,返回的张量默认情况下不需要梯度,与obj具有相同的数据类型,在同一设备上,并与其共享内存。这些属性可以用dtype、device、copy控制,并且需要grad关键字参数。如果返回的张量是不同的数据类型,在不同的设备上,或者请求一个副本,那么它将不会与obj共享它的内存。如果require_grad为True,那么返回的张量将需要一个梯度,如果obj也是一个具有autograd历史的张量,那么返回的张量将有
当obj不是一个张量、NumPy数组或DLPack胶囊,而是实现了Python的缓冲区协议时,缓冲区将被解释为一个字节数组,根据传递给dtype关键字参数的数据类型的大小分组。(如果没有传递数据类型,则使用默认的浮点数据类型。)返回的张量将具有指定的数据类型(或默认的浮点数据类型,如果没有指定),默认情况下,在CPU设备上并与缓冲区共享内存。
a = torch.tensor([1, 2, 3])
# Shares memory with tensor 'a'
b = torch.asarray(a)
a.data_ptr() == b.data_ptr()
# Forces memory copy
c = torch.asarray(a, copy=True)
a.data_ptr() == c.data_ptr()
a = torch.tensor([1, 2, 3], requires_grad=True).float()
b = a + 2
b
# Shares memory with tensor 'b', with no grad
c = torch.asarray(b)
c
# Shares memory with tensor 'b', retaining autograd history
d = torch.asarray(b, requires_grad=True)
d
array = numpy.array([1, 2, 3])
# Shares memory with array 'array'
t1 = torch.asarray(array)
array.__array_interface__['data'][0] == t1.data_ptr()
# Copies memory due to dtype mismatch
t2 = torch.asarray(array, dtype=torch.float32)
array.__array_interface__['data'][0] == t1.data_ptr()
TORCH.AS_TENSOR
将数据转换为一个张量,如果可能的话,共享数据并保存自动梯度历史。
如果数据已经是具有所请求的dtype和device的张量,则返回数据本身,但如果数据是具有不同dtype或device的张量,则复制它,就像使用data.to(dtype=dtype, device=device)。
如果data是一个具有相同dtype和设备的NumPy数组(ndarray),则使用torch.from NumPy()构造一个张量。

a = numpy.array([1, 2, 3])
t = torch.as_tensor(a)
t
t[0] = -1
a
a = numpy.array([1, 2, 3])
t = torch.as_tensor(a, device=torch.device('cuda'))
t
t[0] = -1
a
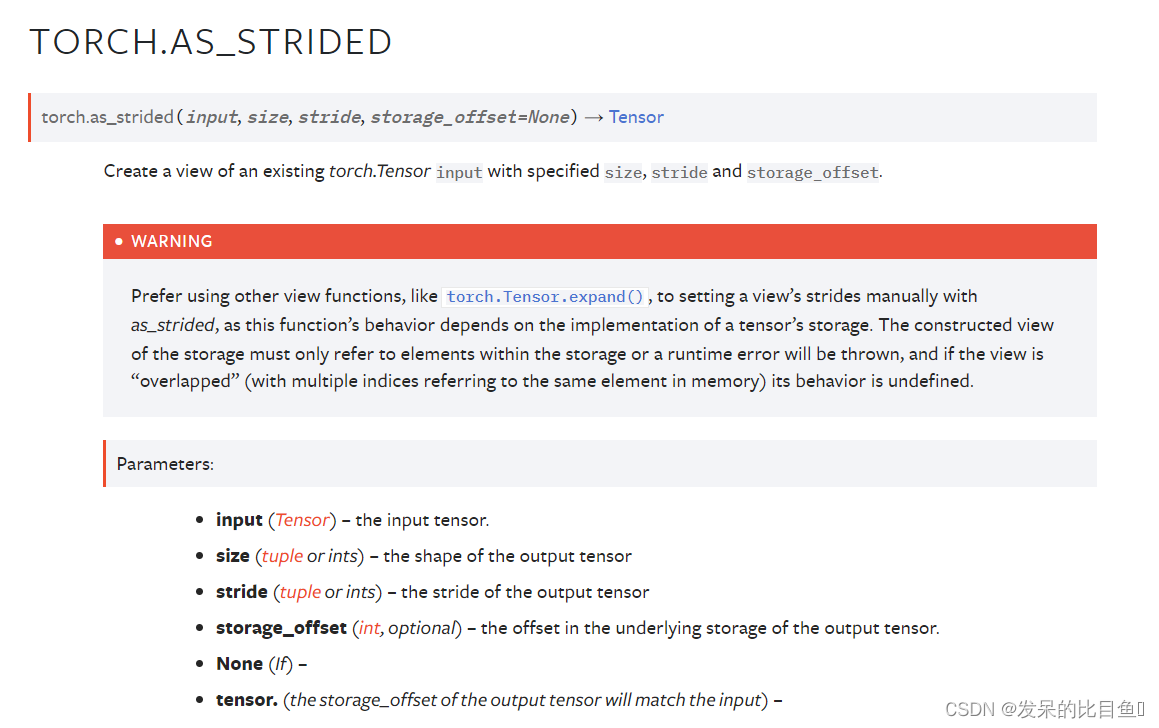
TORCH.AS_STRIDED
创建现有torch.tensor输入的视图具有指定的大小、步幅和storage_offset。
x = torch.randn(3, 3)
x
t = torch.as_strided(x, (2, 2), (1, 2))
t
t = torch.as_strided(x, (2, 2), (1, 2), 1)
TORCH.FROM_NUMPY
从numpy.ndarray创建一个张量。
返回的张量和ndarray共享相同的内存。对张量的修改将反映在ndarray中,反之亦然。返回的张量是不可调整的。
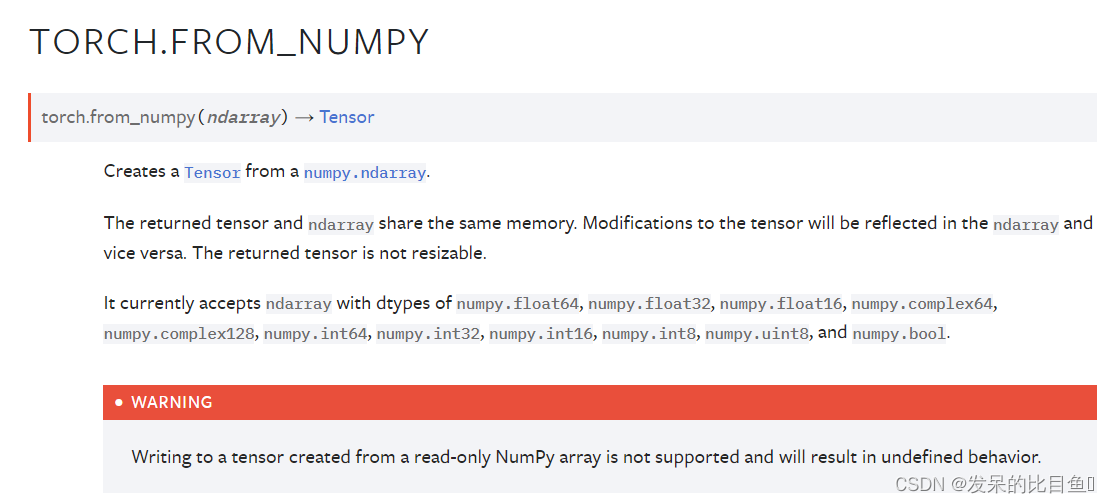
a = numpy.array([1, 2, 3])
t = torch.from_numpy(a)
t
t[0] = -1
a
TORCH.FROM_DLPACK
将一个张量从外部库转换为torch.Tensor。
返回的PyTorch张量将与输入张量(可能来自另一个库)共享内存。注意,原地操作也会因此影响输入张量的数据。这可能会导致意想不到的问题(例如,其他库可能有只读标志或不可变的数据结构),所以用户只有在确定这样做是正确的情况下才应该这样做。
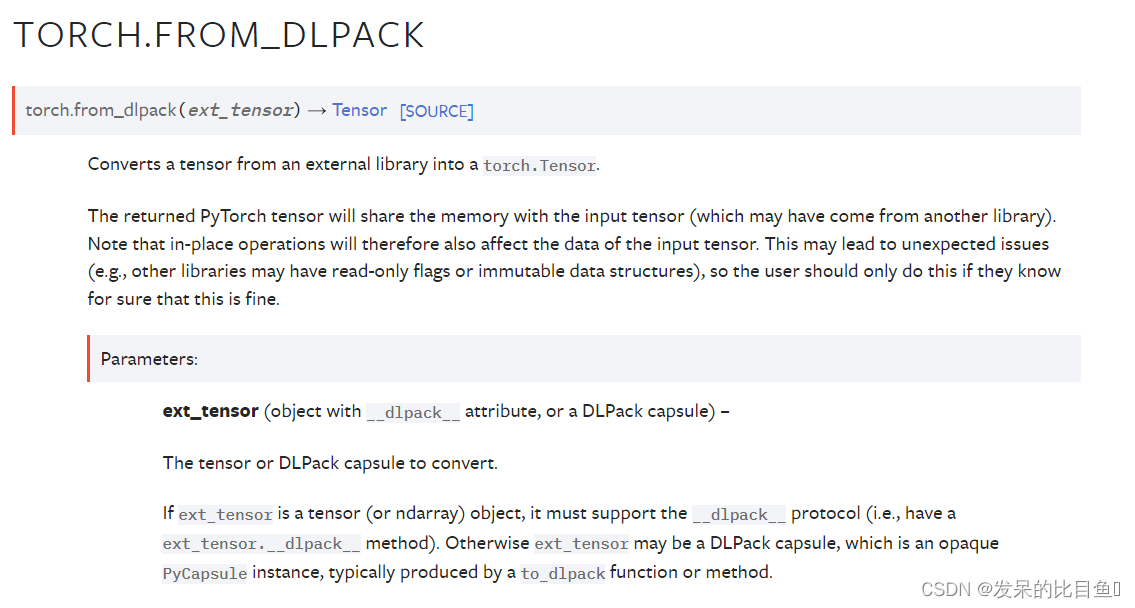
import torch.utils.dlpack
t = torch.arange(4)
t2 = torch.from_dlpack(t)
t2[:2] = -1 # show that memory is shared
t2
t
capsule = torch.utils.dlpack.to_dlpack(t)
capsule
t3 = torch.from_dlpack(capsule)
t3
t3[0] = -9 # now we're sharing memory between 3 tensors
t3
t2
t
TORCH.FROMBUFFER
从实现Python缓冲区协议的对象创建一个一维张量。
跳过缓冲区中的第一个偏移字节,并将剩余的原始字节解释为具有count元素的dtype类型的1维张量。
注意,下列任一项必须为真
- Count是一个正的非零数,缓冲区中的总字节数小于offset加上Count乘以dtype的大小(以字节为单位)。
- Count为负数,缓冲区的长度(字节数)减去偏移量是dtype的size(字节数)的倍数。
返回的张量和缓冲区共享相同的内存。对张量的修改将反映在缓冲区中,反之亦然。返回的张量是不可调整的
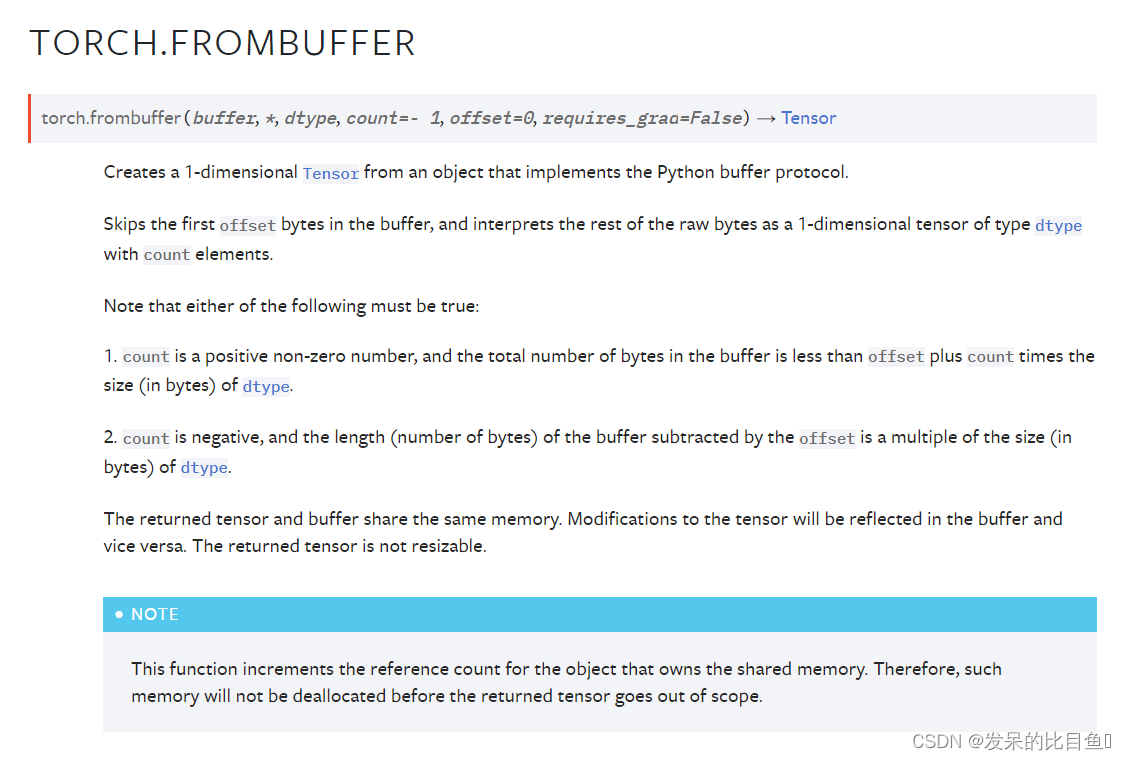
import array
a = array.array('i', [1, 2, 3])
t = torch.frombuffer(a, dtype=torch.int32)
t
t[0] = -1
a
# Interprets the signed char bytes as 32-bit integers.
# Each 4 signed char elements will be interpreted as
# 1 signed 32-bit integer.
import array
a = array.array('b', [-1, 0, 0, 0])
torch.frombuffer(a, dtype=torch.int32)
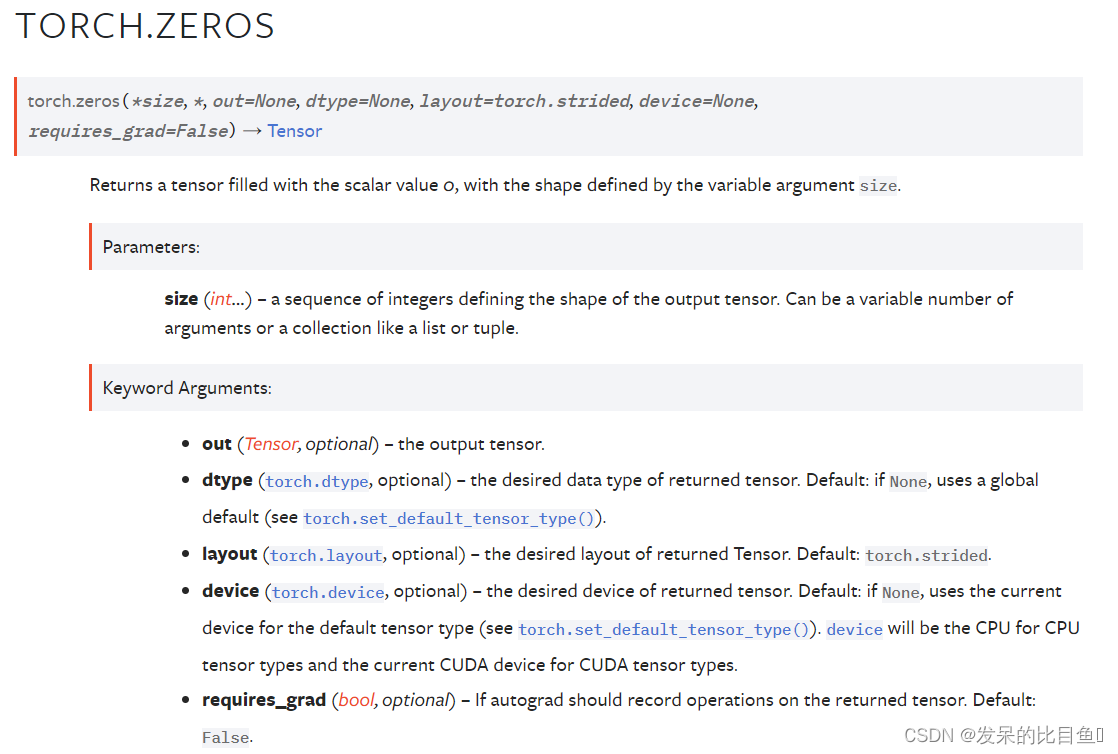
TORCH.ZEROS
返回一个用标量值0填充的张量,其形状由变量参数size定义。
torch.zeros(2, 3)
torch.zeros(5)
TORCH.ZEROS_LIKE
返回用标量值0填充的张量,其大小与输入值相同。torch.zeros-like(input)等同于torch.zeros(input.size(),dtype=input.dtype,layout=input.layout,device=input.device)。

input = torch.empty(2, 3)
torch.zeros_like(input)
TORCH.ONES
返回一个用标量值1填充的张量,其形状由变量参数size定义。
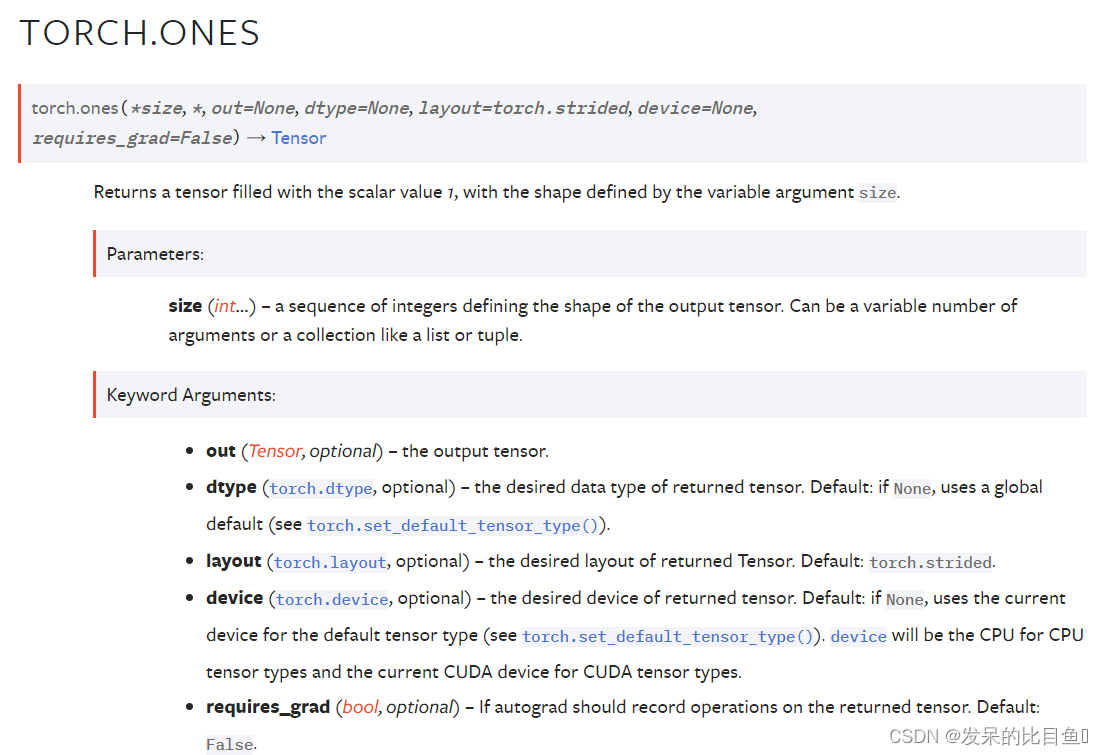
torch.ones(2, 3)
torch.ones(5)
TORCH.ONES_LIKE
返回用标量值1填充的张量,其大小与输入值相同。torch.ones_like(input)等同于torch.ones(input.size(),dtype=input.dtype,layout=input.layout,device=input.device)。

input = torch.empty(2, 3)
torch.ones_like(input)
TORCH.ARANGE
返回大小为
[
e
n
d
−
s
t
a
r
t
s
t
e
p
]
[\frac{end-start}{step}]
[stepend−start]的一维张量,其值来自间隔[start,end),从开始开始使用公共差分步长。
请注意,非整数步长在与末端进行比较时会受到浮点舍入误差的影响;为了避免不一致,我们建议在这种情况下在末尾添加一个小epsilon。
torch.arange(5)
torch.arange(1, 4)
torch.arange(1, 2.5, 0.5)
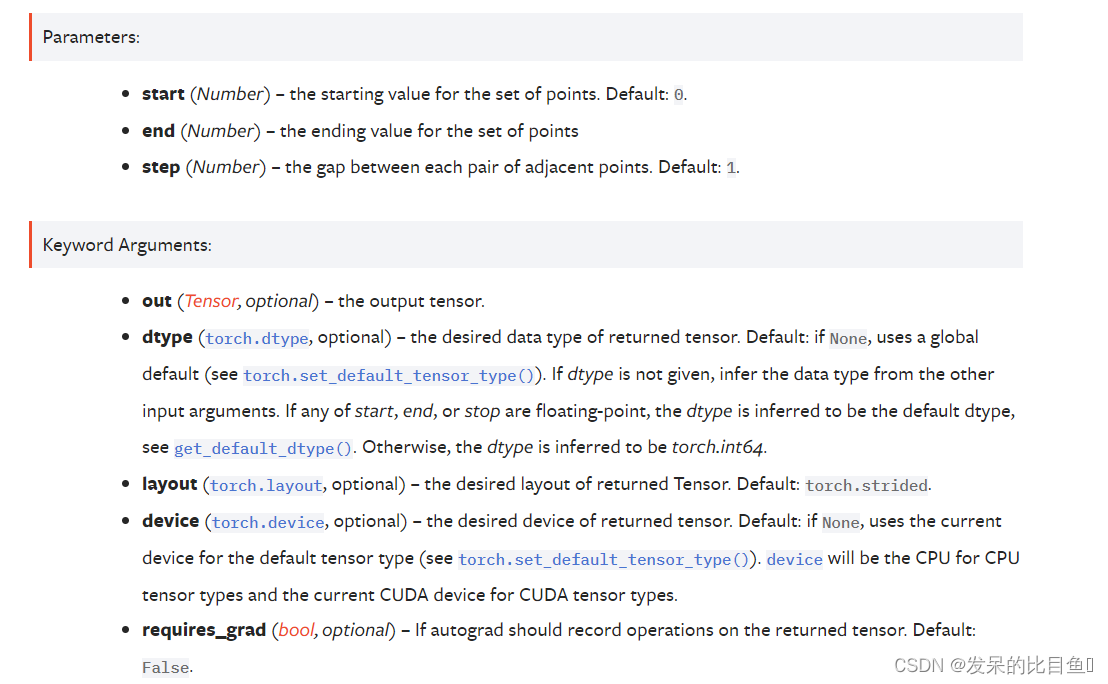
TORCH.RANGE
返回大小为
[
e
n
d
−
s
t
a
r
t
s
t
e
p
]
+
1
[\frac{end-start}{step}]+1
[stepend−start]+1的一维张量,其值从开始到结束均为step。步长是张量中两个值之间的间隙。
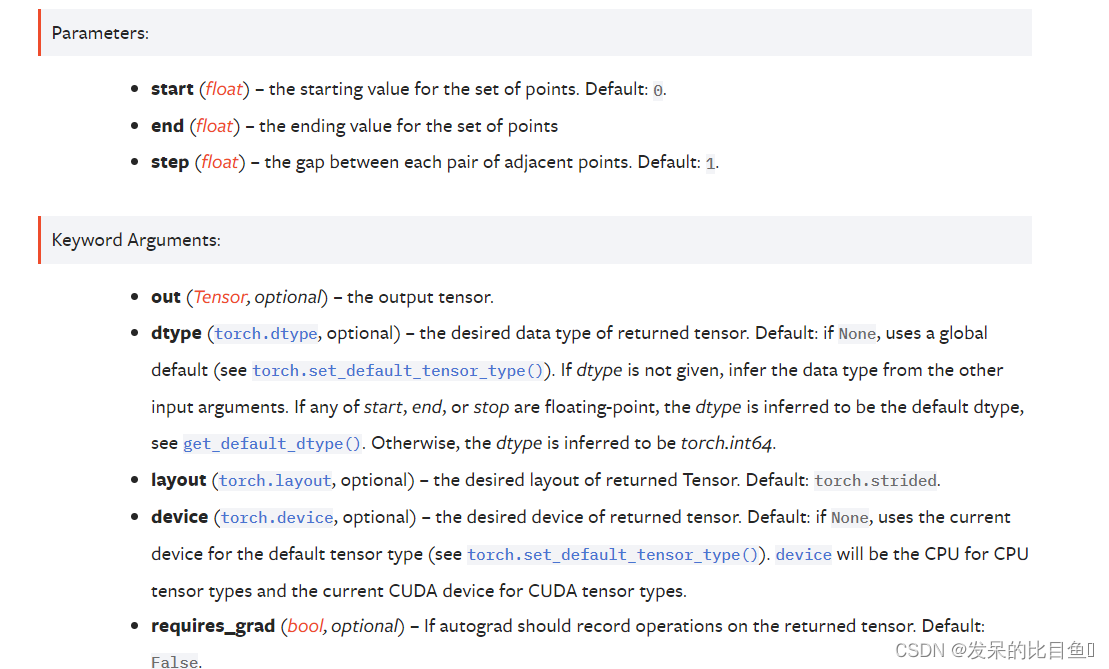
torch.range(1, 4)
torch.range(1, 4, 0.5)
TORCH.LINSPACE
创建一个一维大小步长的张量,其值从开始到结束都是均匀间隔的。即,值为
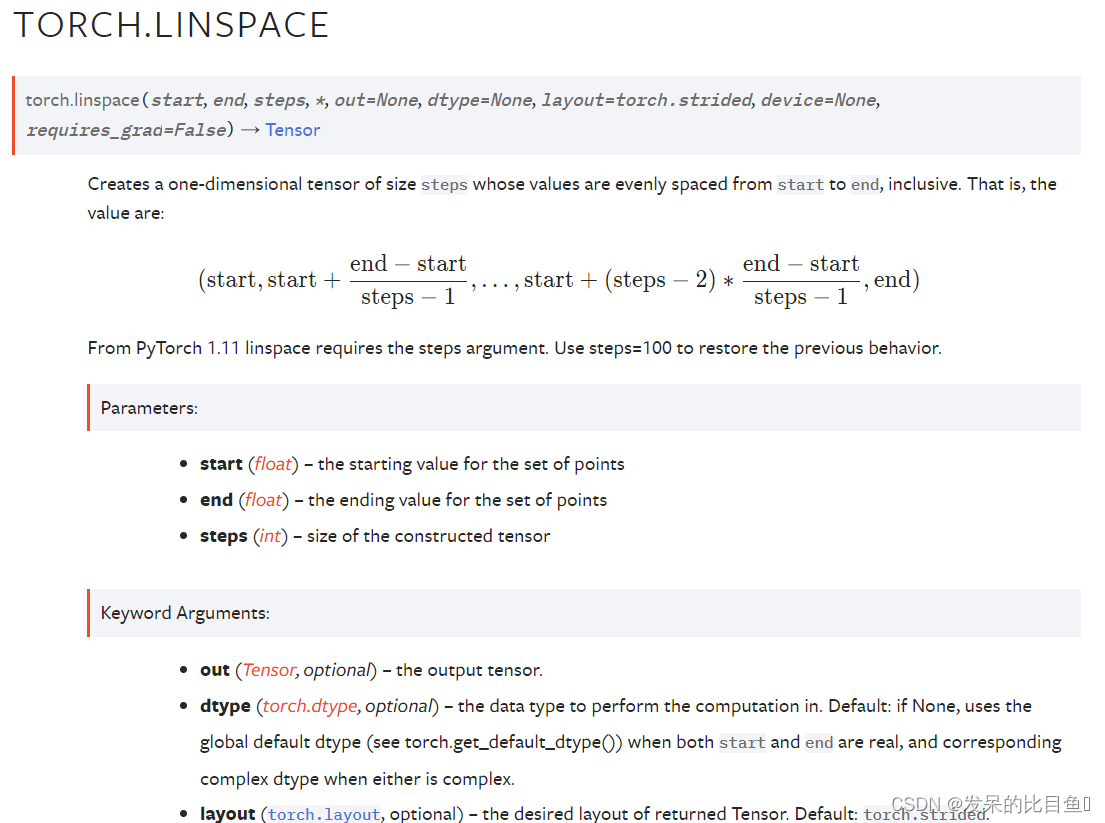
torch.linspace(3, 10, steps=5)
torch.linspace(-10, 10, steps=5)
torch.linspace(start=-10, end=10, steps=5)
torch.linspace(start=-10, end=10, steps=1)
TORCH.LOGSPACE
创建一个一维大小步长的张量,其值在以基数为基础的对数刻度上,从基数开始,基数开始到基数结束,包括基数结束。也就是说,值是
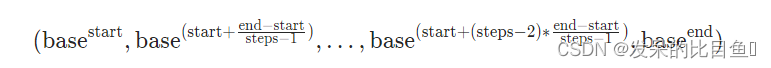
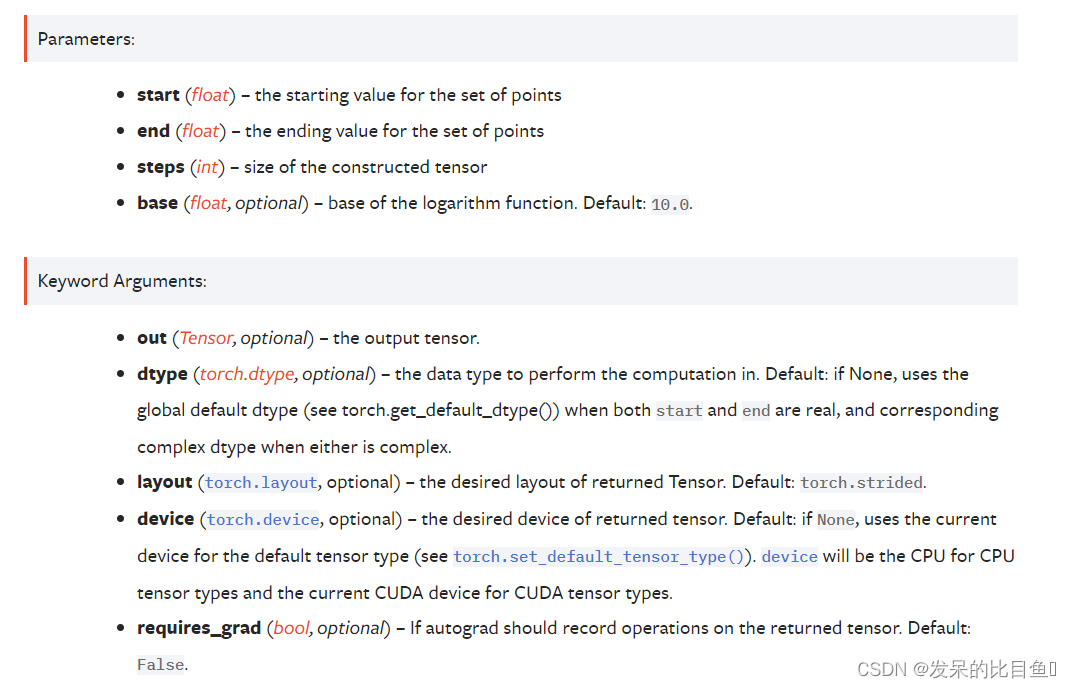
torch.logspace(start=-10, end=10, steps=5)
torch.logspace(start=0.1, end=1.0, steps=5)
torch.logspace(start=0.1, end=1.0, steps=1)
torch.logspace(start=2, end=2, steps=1, base=2)
TORCH.EYE
返回一个二维张量,对角线上为1,其他地方为0。
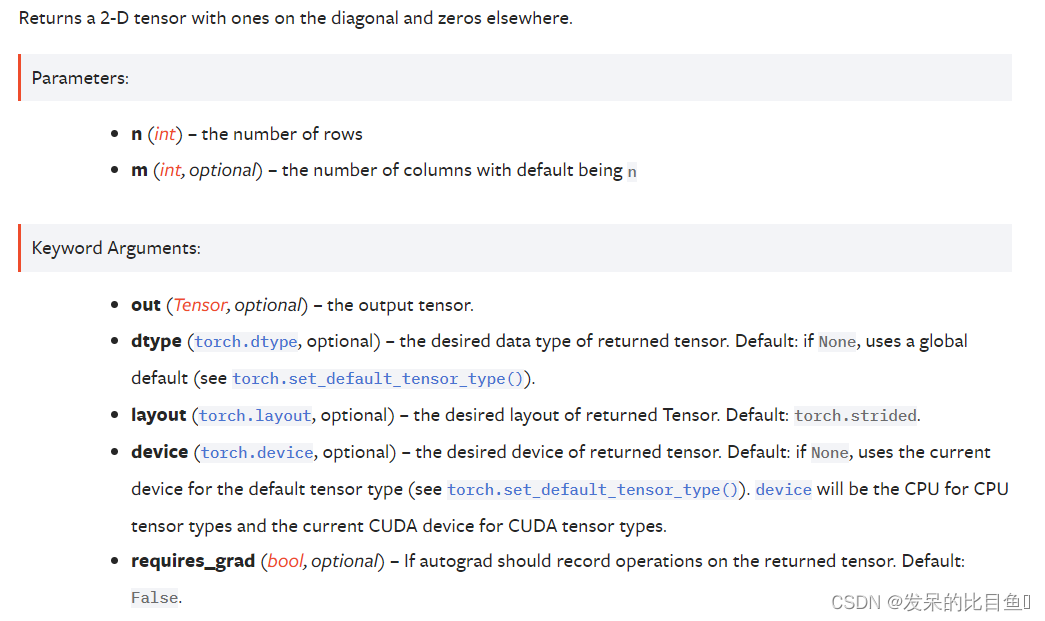
torch.eye(3)
TORCH.EMPTY
返回一个充满未初始化数据的张量。张量的形状由变量参数大小定义。
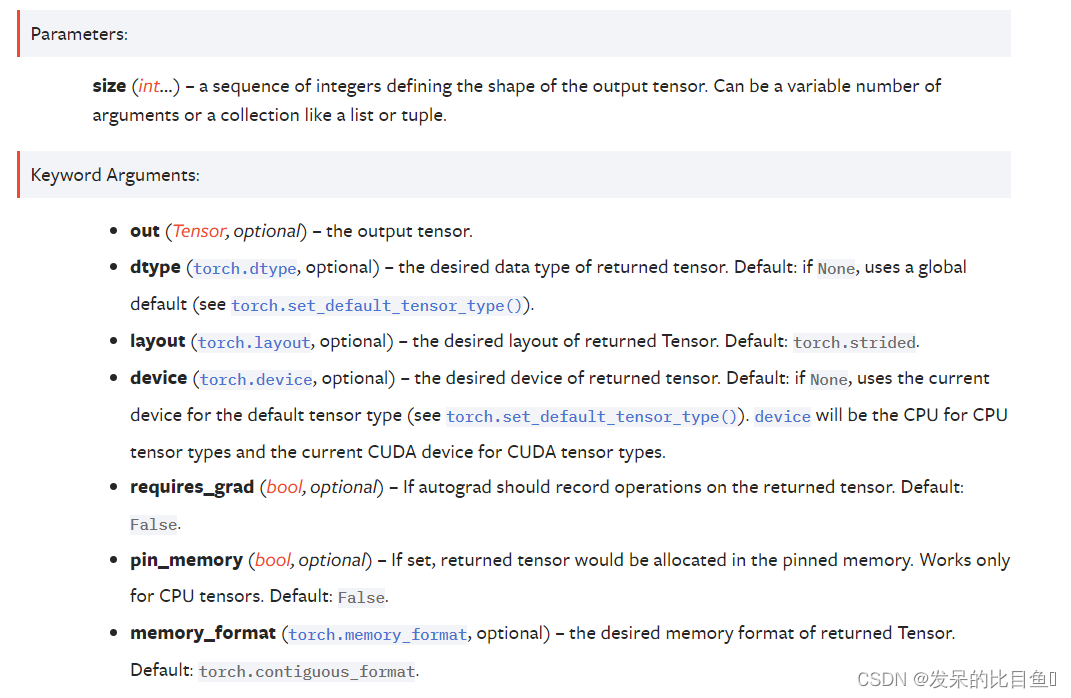
TORCH.EMPTY_LIKE
返回与输入大小相同的未初始化张量。torch.empty-like(input)等同于torch.empty(input.size(),dtype=input.dtype,layout=input.layout,device=input.device)。
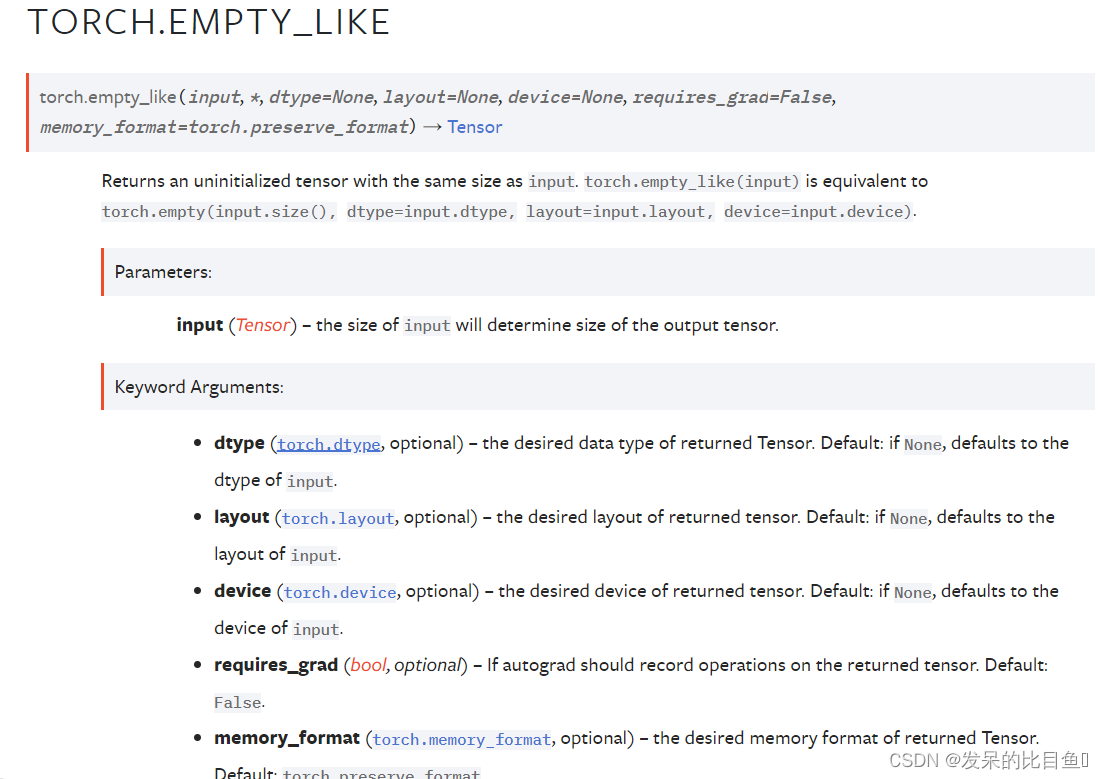
a=torch.empty((2,3), dtype=torch.int32, device = 'cuda')
torch.empty_like(a)
TORCH.EMPTY_STRIDED
创建一个具有指定大小和步幅的张量,并填充未定义的数据。警告
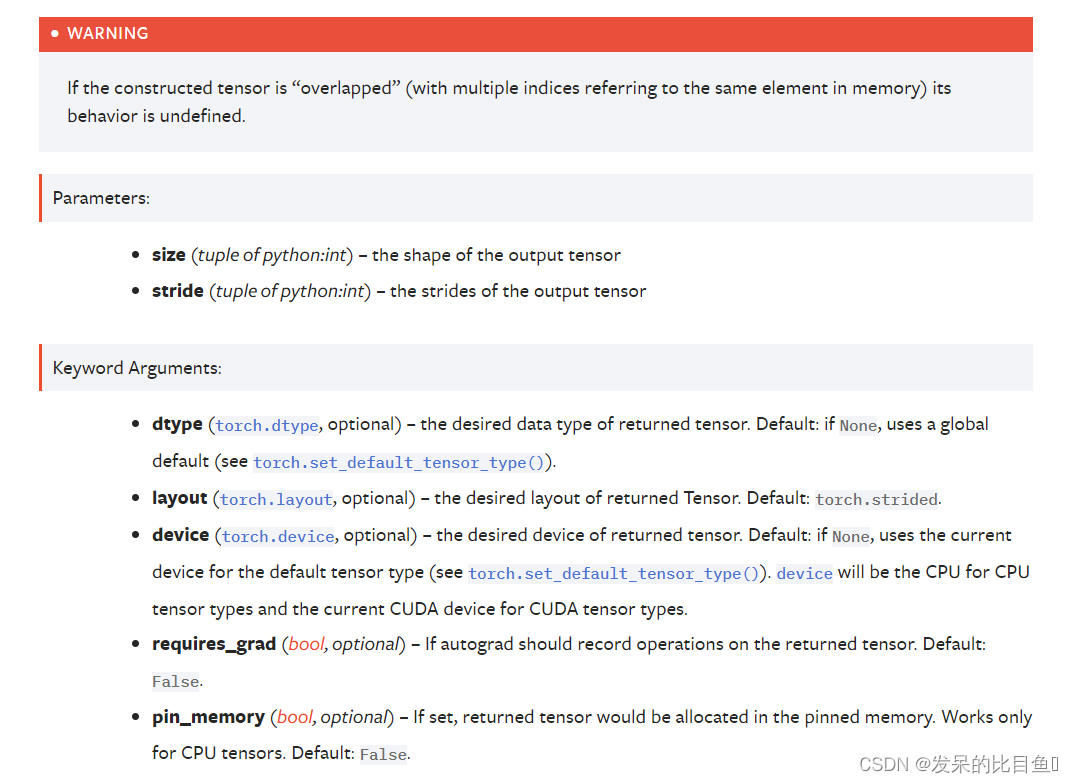
a = torch.empty_strided((2, 3), (1, 2))
a
a.stride()
a.size()
TORCH.FULL
创建一个大小为size且填充值为fill的张量。张量的dtype是从填充值推断出来的。

torch.full((2, 3), 3.141592)
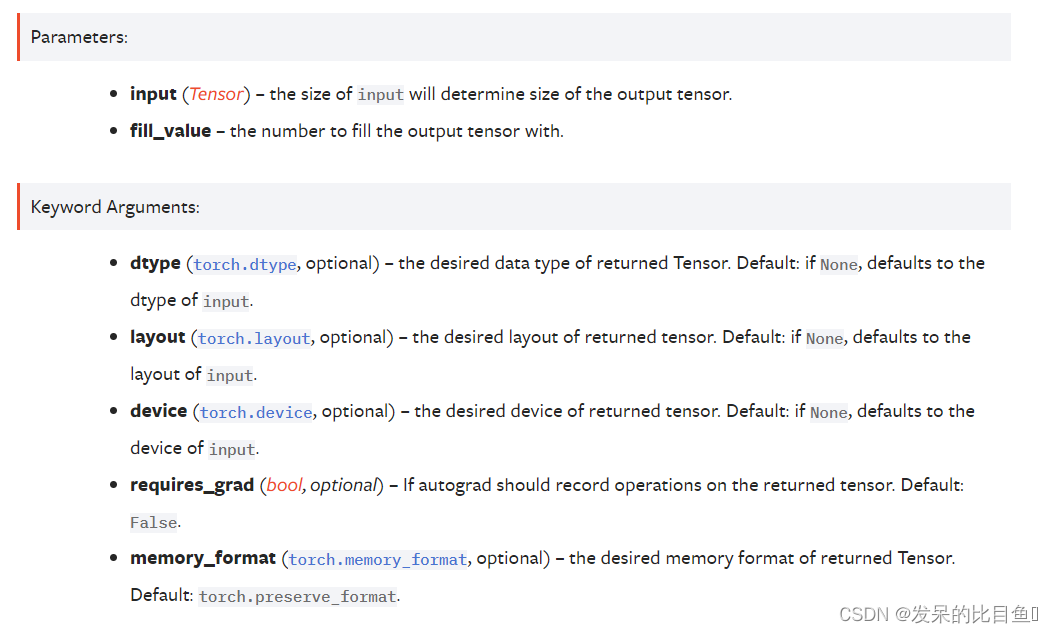
TORCH.FULL_LIKE
返回一个大小与填充了fill_value的输入相同的张量。torch.full_like(input,fill_value)等同于torch.full(input.size(),fill_value,dtype=input.dtype,layout=input.layout,device=input.device)。
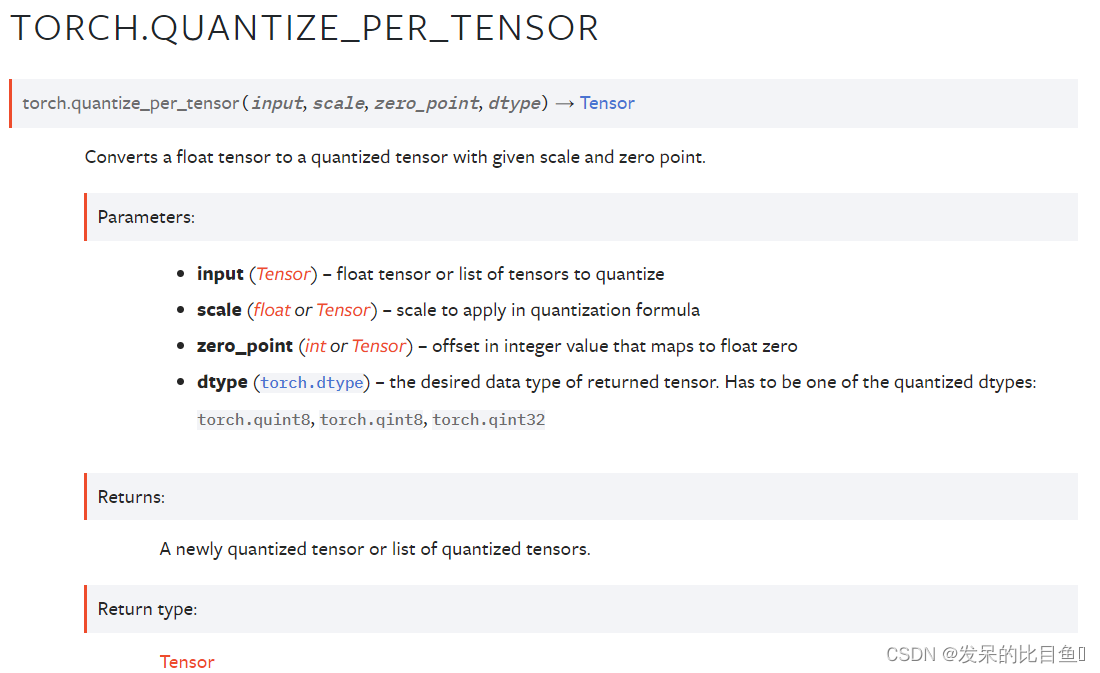
TORCH.QUANTIZE_PER_TENSOR
将一个浮点张量转换为具有给定尺度和零点的量子化张量。
TORCH.QUANTIZE_PER_CHANNEL
将一个浮点张量转换为具有给定尺度和零点的每通道量化张量。

x = torch.tensor([[-1.0, 0.0], [1.0, 2.0]])
torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8)
torch.quantize_per_channel(x, torch.tensor([0.1, 0.01]), torch.tensor([10, 0]), 0, torch.quint8).int_repr()
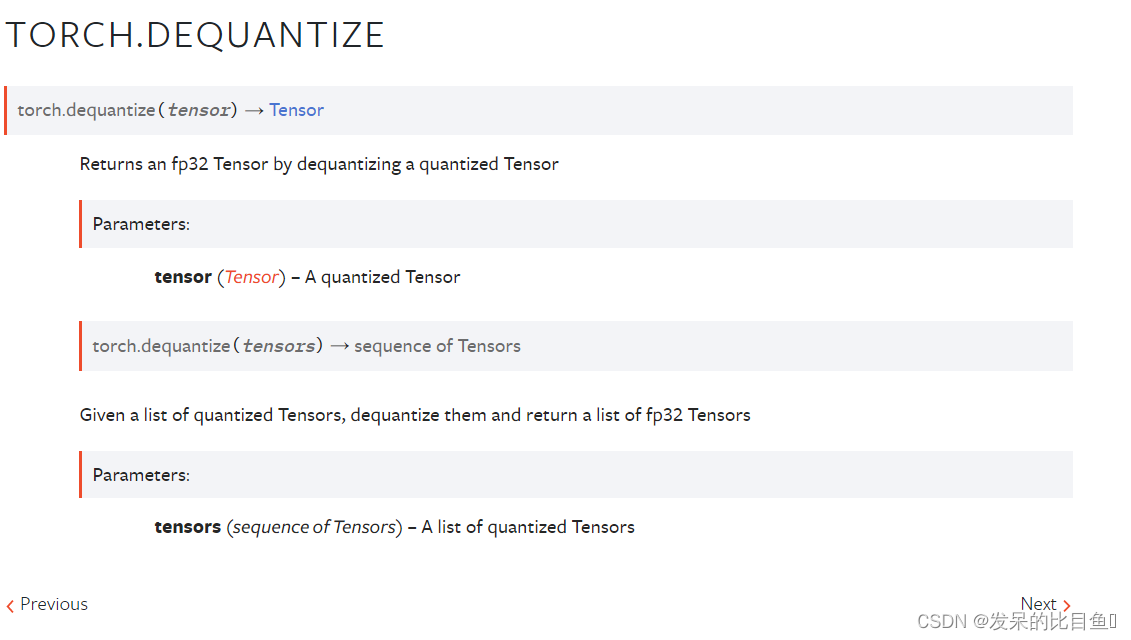
TORCH.DEQUANTIZE
通过去量化一个量化的张量,返回一个fp32张量
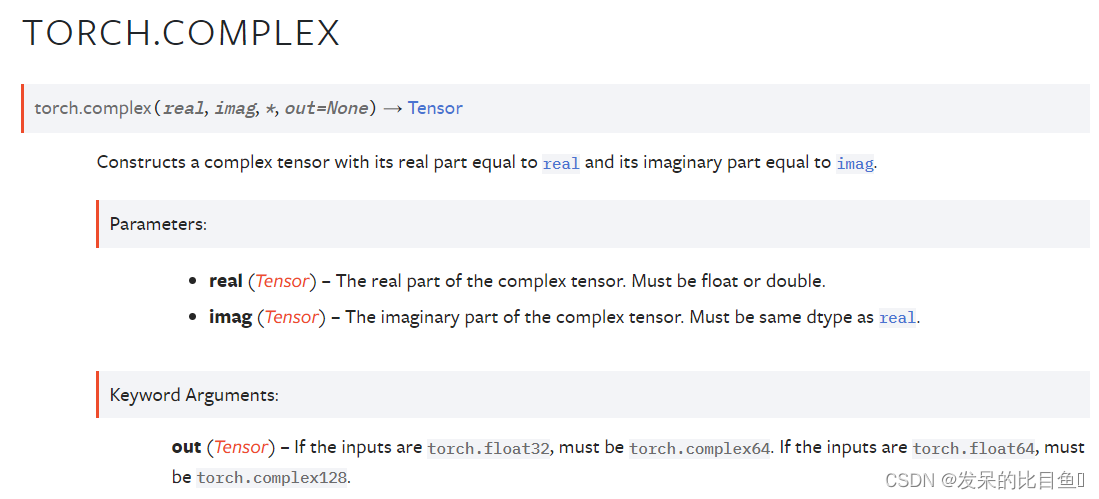
TORCH.COMPLEX
构造一个实部等于实部且虚部等于imag的复数张量。
real = torch.tensor([1, 2], dtype=torch.float32)
imag = torch.tensor([3, 4], dtype=torch.float32)
z = torch.complex(real, imag)
z
z.dtype
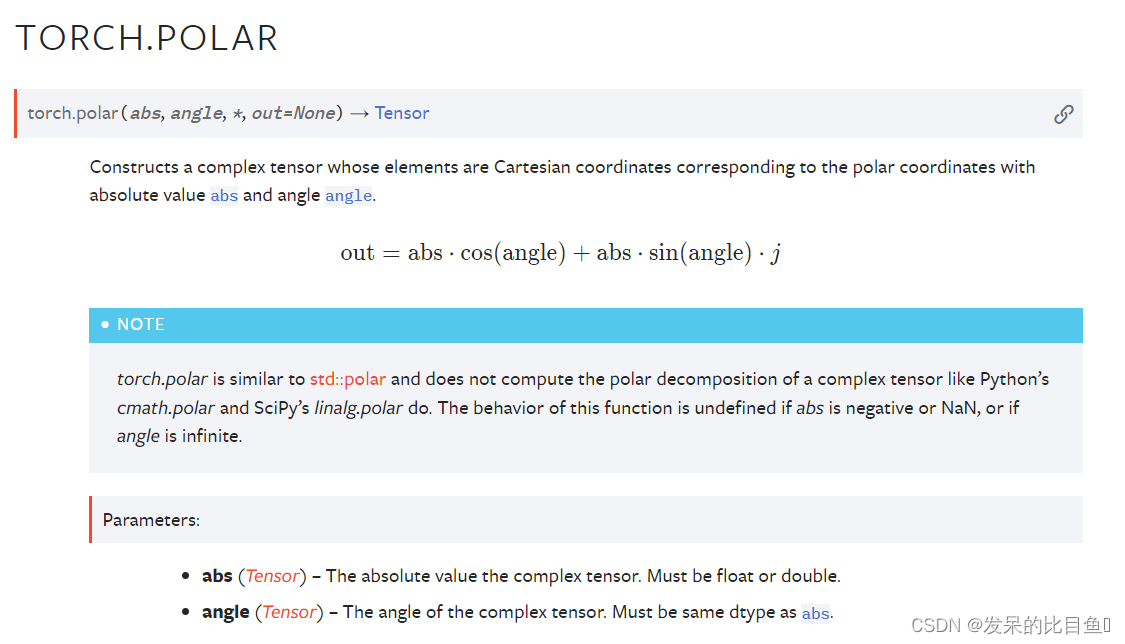
TORCH.POLAR
构造一个复张量,其元素是笛卡尔坐标,对应于绝对值为abs和角角度的极坐标。
import numpy as np
abs = torch.tensor([1, 2], dtype=torch.float64)
angle = torch.tensor([np.pi / 2, 5 * np.pi / 4], dtype=torch.float64)
z = torch.polar(abs, angle)
z
TORCH.HEAVISIDE
为输入中的每个元素计算Heaviside阶跃函数。Heaviside阶跃函数定义为

input = torch.tensor([-1.5, 0, 2.0])
values = torch.tensor([0.5])
torch.heaviside(input, values)
values = torch.tensor([1.2, -2.0, 3.5])
torch.heaviside(input, values)
Indexing, Slicing, Joining, Mutating Ops
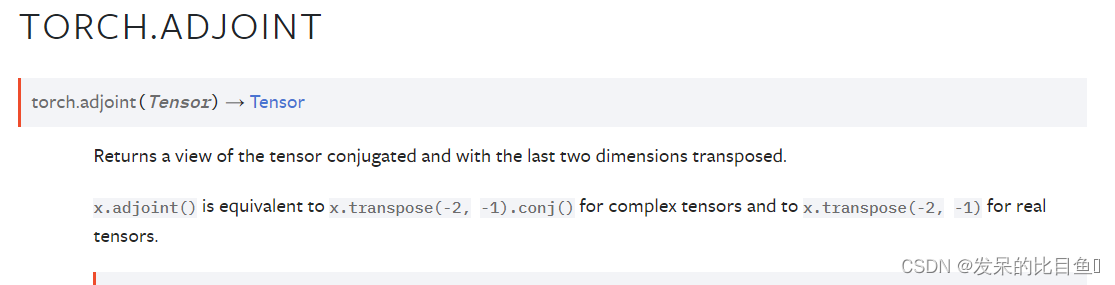
TORCH.ADJOINT
返回张量共轭的视图,并返回最后两个维度。
x.adjoint() 等同于 x.transpose(-2, -1).conj() 对于复张量和 x.transpose(-2, -1) 对于实张量。
x = torch.arange(4, dtype=torch.float)
A = torch.complex(x, x).reshape(2, 2)
A
A.adjoint()
(A.adjoint() == A.mH).all()
TORCH.ARGWHERE
返回包含输入的所有非零元素的索引的张量。 结果中的每一行都包含输入中非零元素的索引。 结果按字典顺序排序,最后一个索引变化最快(C - style)。
如果输入有 n 维,则结果索引张量的大小为
(
z
×
n
)
(z×n)
(z×n),其中 z 是输入张量中非零元素的总数。
这个函数类似于NumPy的argwhere。
当输入在CUDA上时,该功能将导致主机设备同步。
t = torch.tensor([1, 0, 1])
torch.argwhere(t)
t = torch.tensor([[1, 0, 1], [0, 1, 1]])
torch.argwhere(t)
TORCH.CAT
在给定维度中连接给定序列的seq张量。所有张量必须要么具有相同的形状(除了在连接维度中),要么为空。
Torch.cat()可以看作torch.split()和torch.chunk()的逆操作。
Torch.cat()可以通过示例更好地理解。
x = torch.randn(2, 3)
x
torch.cat((x, x, x), 0)
torch.cat((x, x, x), 1)
TORCH.CONCATENATE
torch.cat()的别名。
TORCH.CONJ
返回带有翻转共轭位的输入视图。如果input有一个非复杂的dtype,这个函数只返回input。
torch.conj()执行惰性共轭,但实际的共轭张量可以在任何时候使用torch.resolve_conj().
x = torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j])
x.is_conj()
y = torch.conj(x)
print(y)
y.is_conj()
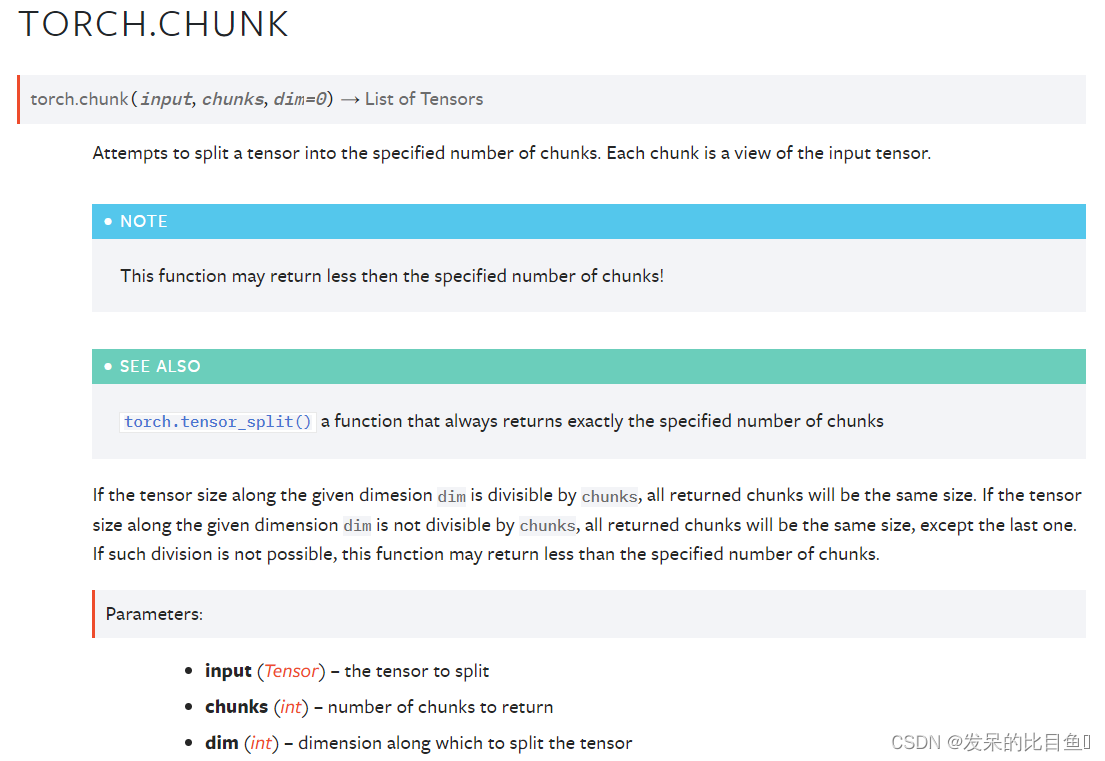
TORCH.CHUNK
尝试将一个张量分割为指定数量的块。每个块都是输入张量的一个视图。
此函数返回的块数可能小于指定的块数
torch.tensor_split() 是返回指定数量的块的函数
torch.arange(11).chunk(6)
torch.arange(12).chunk(6)
torch.arange(13).chunk(6)
TORCH.COLUMN_STACK
通过水平叠加张量来创建一个新的张量。
等效于torch.hstack(tensor),不同之处是张量中的每个零或一维张量t在水平堆叠之前首先被重塑为(t.numel(), 1)列。

a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
torch.column_stack((a, b))
a = torch.arange(5)
b = torch.arange(10).reshape(5, 2)
torch.column_stack((a, b, b))
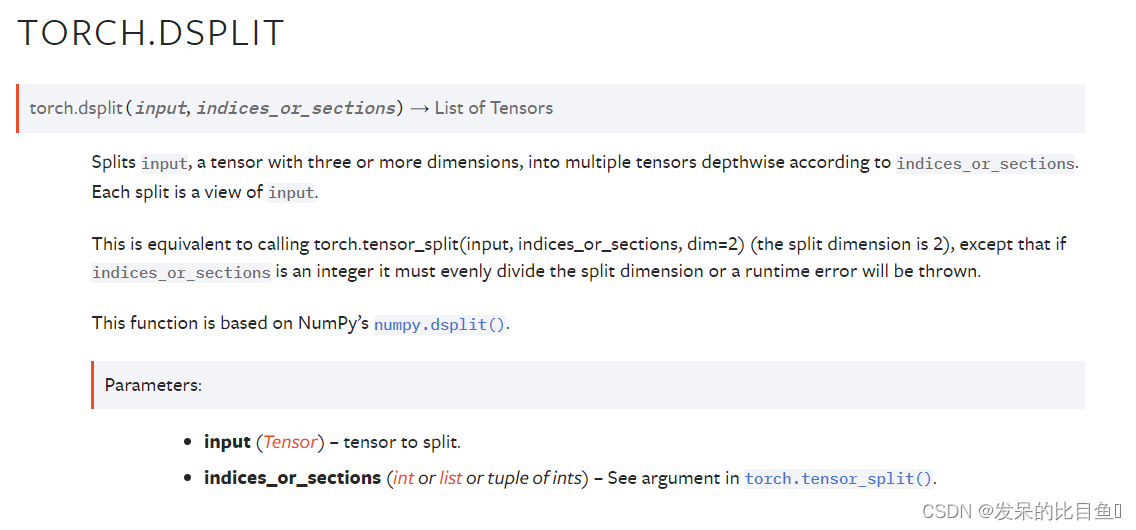
TORCH.DSTACK
根据 indices_or_sections 将输入(具有三个或更多维度的张量)拆分为多个深度张量。 每个拆分都是一个输入视图。
这相当于调用 torch.tensor_split(input, indices_or_sections, dim=2) (分割维度为 2),只是如果 indices_or_sections 是一个整数,它必须平均分割分割维度,否则会抛出运行时错误。
t = torch.arange(16.0).reshape(2, 2, 4)
t
torch.dsplit(t, 2)
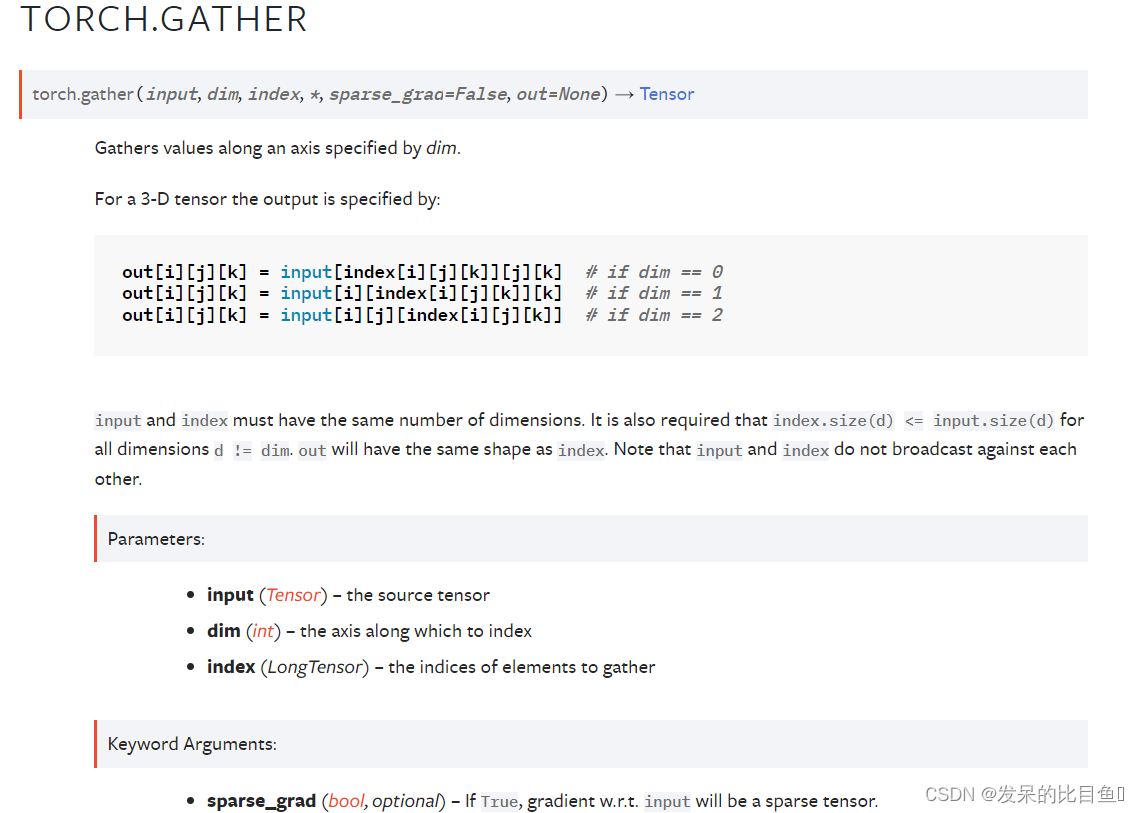
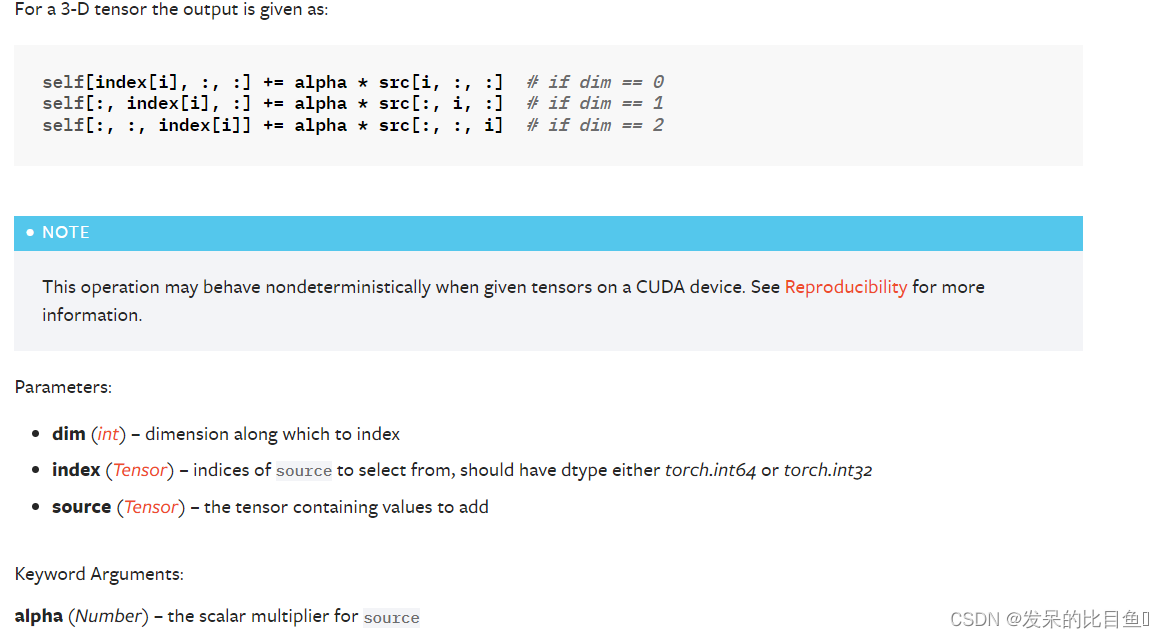
TORCH.GATHER
沿 dim 指定的轴收集值。
对于 3-D 张量,输出指定为:
输入和索引必须具有相同的维数。 还要求index.size(d) <= input.size(d)对于所有维度 d != dim。 out 将具有与 index 相同的形状。 请注意,输入和索引不会相互广播。
t = torch.tensor([[1, 2], [3, 4]])
torch.gather(t, 1, torch.tensor([[0, 0], [1, 0]]))
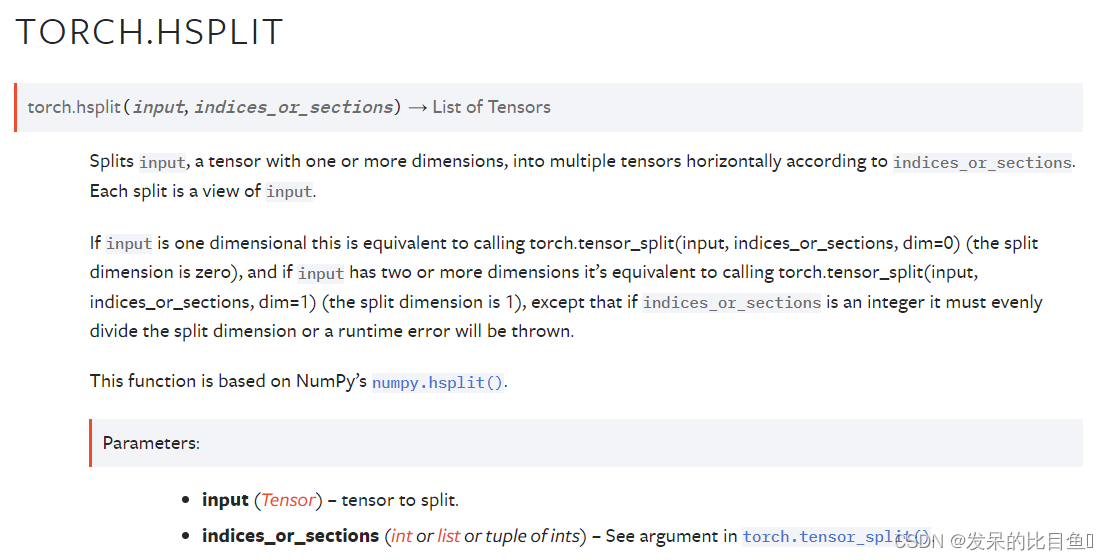
TORCH.HSPLIT
将一个一维或多维的张量,按指标或分段水平分割成多个张量。每个分割都是一个输入视图。
如果输入是一维的,这相当于调用 torch.tensor_split(input, indices_or_sections, dim=0) (分割维度为零),如果输入有两个或更多维度,则相当于调用 torch.tensor_split(input, indices_or_sections, dim=1)(分割维度为 1),除了如果 indices_or_sections 是一个整数,它必须平均分割分割维度,否则将抛出运行时错误。
这个函数基于NumPy的NumPy.hsplit()。
t = torch.arange(16.0).reshape(4,4)
t
torch.hsplit(t, 2)
torch.hsplit(t, [3, 6])
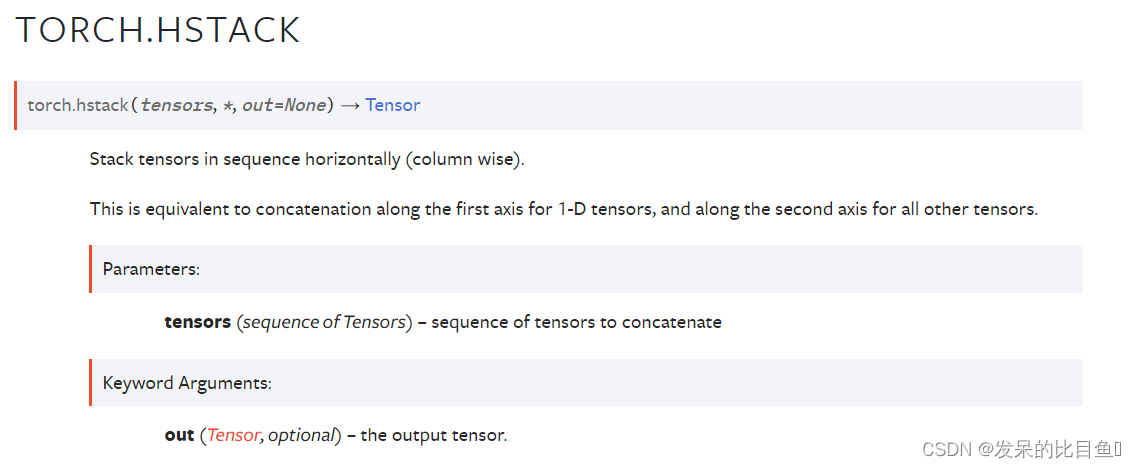
TORCH.HSTACK
按水平顺序(按列)堆叠张量。
对于一维张量,这等价于沿着第一个轴的拼接,对于所有其他张量,这等价于沿着第二个轴的拼接。
import torch
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
torch.hstack((a,b))
a = torch.tensor([[1],[2],[3]])
b = torch.tensor([[4],[5],[6]])
torch.hstack((a,b))
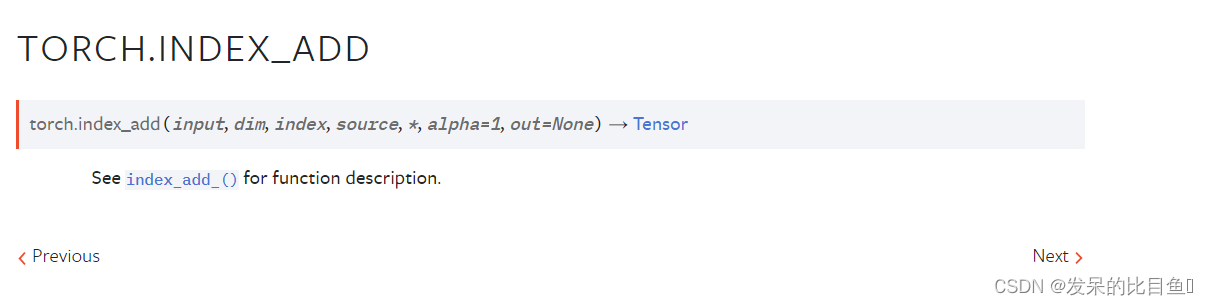
TORCH.INDEX_ADD
x = torch.ones(5, 3)
t = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=torch.float)
index = torch.tensor([0, 4, 2])
x.index_add_(0, index, t)
x.index_add_(0, index, t, alpha=-1)
TORCH.INDEX_COPY
函数描述请参见index_add_()。
将乘以源的元素累加到自张量中,方法是按照index中给出的顺序对指标相加。例如,如果dim == 0, index[i] == j,并且alpha=-1,则source的第i行将从self的第j行中减去。
source的dimth维必须与index的长度(必须是一个向量)相同,并且所有其他维必须匹配self,否则将引发错误。
x = torch.ones(5, 3)
t = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]], dtype=torch.float)
index = torch.tensor([0, 4, 2])
x.index_add_(0, index, t)
x.index_add_(0, index, t, alpha=-1)
TORCH.INDEX_REDUCE
将源的元素累加到自张量中,方法是按照下标中给出的顺序累加到下标中,使用reduce参数给出的约简。例如,如果dim == 0, index[i] == j, reduce == prod, include_self == True,则source的第i行乘以self的第j行。如果include_self="True",则self张量中的值被包含在约简中,否则,累积到的self张量中的行被视为被约简单位填充。


x = torch.empty(5, 3).fill_(2)
t = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]], dtype=torch.float)
index = torch.tensor([0, 4, 2, 0])
x.index_reduce_(0, index, t, 'prod')
x = torch.empty(5, 3).fill_(2)
x.index_reduce_(0, index, t, 'prod', include_self=False)
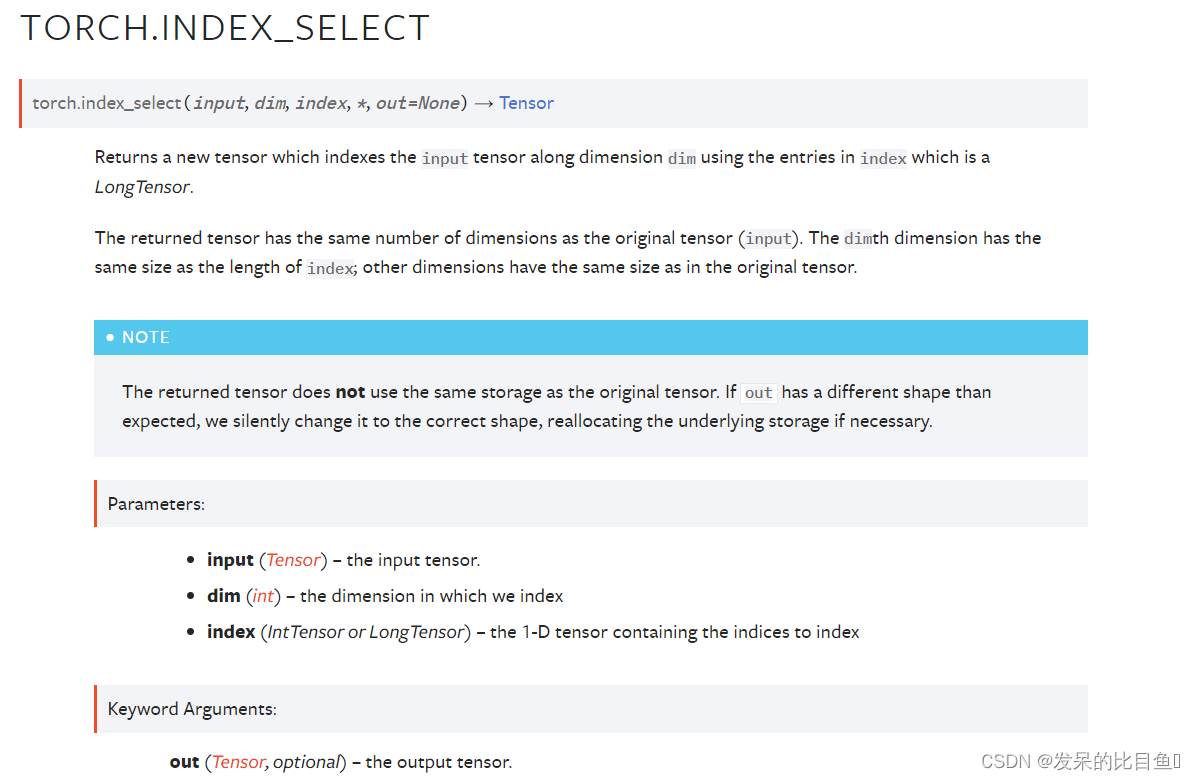
TORCH.INDEX_SELECT
返回一个新的张量,该张量使用索引中的项(LongTensor)沿dim维度索引输入张量。
返回的张量具有与原始张量(输入)相同的维数。dimth维与index的长度相同;其他维度的大小与原始张量相同。
返回的张量不使用与原始张量相同的存储空间。如果out的形状与预期的不同,则将其无声地更改为正确的形状,并在必要时重新分配底层存储。
x = torch.randn(3, 4)
x
indices = torch.tensor([0, 2])
torch.index_select(x, 0, indices)
torch.index_select(x, 1, indices)
TORCH.MASKED_SELECT
返回一个新的一维张量,根据布尔掩码mask (boolean tensor)对输入张量进行索引。
掩模张量和输入张量的形状不需要匹配,但它们必须是可广播的。
x = torch.randn(3, 4)
x
mask = x.ge(0.5)
mask
torch.masked_select(x, mask)
TORCH.MOVEDIM
将输入的维度从源的位置移动到目标的位置。
没有显式移动的其他输入维度保持原始顺序,并出现在目标中未指定的位置。
t = torch.randn(3,2,1)
t
torch.movedim(t, 1, 0).shape
torch.movedim(t, 1, 0)
torch.movedim(t, (1, 2), (0, 1)).shape
torch.movedim(t, (1, 2), (0, 1))
TORCH.MOVEAXIS
torch.movedim()的别名。
这个函数相当于NumPy的moveaxis函数。
t = torch.randn(3,2,1)
t
torch.moveaxis(t, 1, 0).shape
torch.moveaxis(t, 1, 0)
torch.moveaxis(t, (1, 2), (0, 1)).shape
torch.moveaxis(t, (1, 2), (0, 1))
TORCH.NARROW
返回一个新的张量,它是输入张量的缩小版本。尺寸dim是从开始到开始的输入+长度。返回的张量和输入张量共享相同的底层存储空间。

x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
torch.narrow(x, 0, 0, 2)
torch.narrow(x, 1, 1, 2)
TORCH.NONZERO
当as_tuple为False时(默认)
返回一个张量,包含输入中所有非零元素的下标。结果中的每一行都包含输入中非零元素的索引。结果按字典顺序排序,最后一个索引变化最快(C-style)。
如果输入有
n
n
n维,那么输出的指标张量的大小为(
z
×
n
z \times n
z×n),其中
z
z
z是输入张量中非零元素的总数。
当as_tuple为True时
返回一个一维张量元组,每个维度对应输入,每个维度包含输入中所有非零元素的索引(在该维度中)。
如果输入有n个维度,那么得到的元组包含n个大小为z的张量,其中z是输入张量中非零元素的总数。
作为一种特殊情况,当输入具有零维和非零标量值时,它被视为具有一个元素的一维张量。

torch.nonzero(…, as tuple=False)(默认)返回一个二维张量,其中每一行都是一个非零值的下标。
torch.nonzero(…, as tuple=True)返回一个一维索引张量的元组,允许高级索引,因此x[x.]nonzero(as tuple=True)]给出了张量x的所有非零值。在返回的元组中,每个索引张量包含某维的非零索引。
有关这两种行为的更多细节,请参见下面。
当输入在CUDA上时,torch.nonzero()会导致主机设备同步。
torch.nonzero(torch.tensor([1, 1, 1, 0, 1]))
torch.nonzero(torch.tensor([[0.6, 0.0, 0.0, 0.0],
[0.0, 0.4, 0.0, 0.0],
[0.0, 0.0, 1.2, 0.0],
[0.0, 0.0, 0.0,-0.4]]))
torch.nonzero(torch.tensor([1, 1, 1, 0, 1]), as_tuple=True)
torch.nonzero(torch.tensor([[0.6, 0.0, 0.0, 0.0],
[0.0, 0.4, 0.0, 0.0],
[0.0, 0.0, 1.2, 0.0],
[0.0, 0.0, 0.0,-0.4]]), as_tuple=True)
torch.nonzero(torch.tensor(5), as_tuple=True)
TORCH.PERMUTE
返回原始张量输入的视图,其维度被打乱。

x = torch.randn(2, 3, 5)
x.size()
torch.permute(x, (2, 0, 1)).size()
TORCH.RESHAPE
返回一个张量,其数据和元素数量与输入相同,但具有指定的形状。如果可能的话,返回的张量将是输入的视图。否则,它将是一个副本。连续的输入和具有兼容步长的输入可以在不复制的情况下进行重塑,但是不应该依赖于复制与查看行为。
a = torch.arange(4.)
torch.reshape(a, (2, 2))
b = torch.tensor([[0, 1], [2, 3]])
torch.reshape(b, (-1,))
TORCH.ROW_STACK

torch.vstack()别名
TORCH.SELECT
在给定的索引处沿选定的维度对输入张量进行切片。这个函数返回去掉给定维度后原始张量的视图。
import torch
a = torch.rand((3, 4))
print(a)
>>> tensor([[0.8664, 0.9759, 0.3063, 0.0686],
[0.6778, 0.0574, 0.3194, 0.4253],
[0.5045, 0.8318, 0.1745, 0.3150]])
print(a.select(dim=1, index=1)) # 取第1个维度中索引为1的值
>>> tensor([0.9759, 0.0574, 0.8318])
import torch
a = torch.rand((3, 4)
print(a)
>>> tensor([[0.6115, 0.2551, 0.8714, 0.3236],
[0.3369, 0.4372, 0.2083, 0.4733],
[0.0046, 0.0981, 0.9148, 0.7852]])
y = torch.tensor([3, 2, 1])
a.select(1, 1).copy_(y.data) # 将第1个维度中索引为1的张量替换为y
print(a)
>>> tensor([[0.6115, 3.0000, 0.8714, 0.3236],
[0.3369, 2.0000, 0.2083, 0.4733],
[0.0046, 1.0000, 0.9148, 0.7852]])
TORCH.SCATTER
用途:将src上元素按顺序散布在input的给定维度的给定index上
src = torch.arange(1, 11).reshape((2, 5))
print(src)
index = torch.tensor([[0, 1, 2, 0]])
a = torch.zeros(3, 5, dtype=src.dtype).scatter_(0, index, src)
print(a)
TORCH.DIAGONAL_SCATTER
将 src 张量的值沿输入的对角线元素嵌入到输入中,相对于 dim1 和 dim2。
该函数返回一个带有新存储的张量; 它不返回视图。
参数 offset 控制要考虑的对角线:
参数
input (Tensor)– 输入张量。 必须至少是二维的。src (Tensor)– 要嵌入到输入中的张量。offset (int, optional)– 要考虑哪个对角线。 默认值:0(主对角线)。dim1 (int, optional)– 取对角线的第一个维度。 默认值:0。dim2 (int, optional)– 相对于其采取对角线的第二个维度。 默认值:1。
a = torch.zeros(3, 3)
a
torch.diagonal_scatter(a, torch.ones(3), 0)
torch.diagonal_scatter(a, torch.ones(2), 1)
TORCH.SELECT_SCATTER
将src张量的值嵌入到给定索引处的输入中。这个函数返回一个有新存储空间的张量;它不创建视图。

a = torch.zeros(2, 2)
b = torch.ones(2)
a.select_scatter(b, 0, 0)
TORCH.SLICE_SCATTER
将src张量的值嵌入到给定维度的输入中。这个函数返回一个有新存储空间的张量;它不创建视图。
a = torch.zeros(8, 8)
b = torch.ones(8)
a.slice_scatter(b, start=6)
b = torch.ones(2)
a.slice_scatter(b, dim=1, start=2, end=6, step=2)
TORCH.SCATTER_ADD
src = torch.ones((2, 5))
index = torch.tensor([[0, 1, 2, 0, 0]])
print(torch.zeros(3, 5, dtype=src.dtype).scatter_add_(0, index, src))
index = torch.tensor([[0, 1, 2, 0, 0], [0, 1, 2, 2, 2]])
print(torch.zeros(3, 5, dtype=src.dtype).scatter_add_(0, index, src))
TORCH.SCATTER_REDUCE
聚合函数
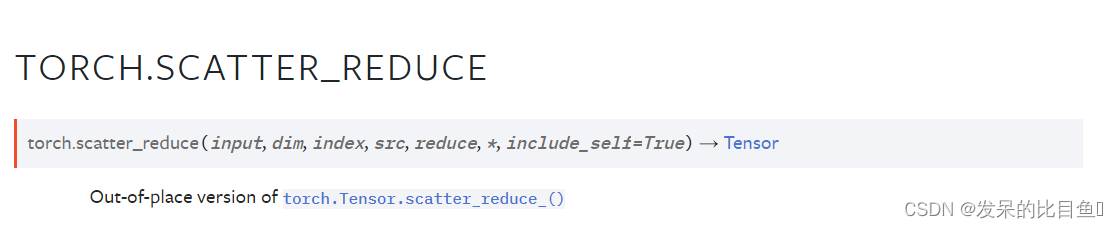
input = torch.tensor([1, 2, 3, 4, 5, 6])
index = torch.tensor([0, 1, 0, 1, 2, 1])
print(torch.scatter_reduce(input, 0, index, reduce="sum", output_size=3)) # sum, prod, mean, amax, amin
TORCH.SPLIT
把张量分成若干块。每个块都是原始张量的一个视图。
如果 split_size_or_sections 是整数类型,则张量将被拆分成大小相等的块(如果可能)。 如果沿给定维度 dim 的张量大小不能被 split_size 整除,则最后一个块将更小。
如果 split_size_or_sections 是一个列表,那么张量将根据 split_size_or_sections 被分成 len(split_size_or_sections) 个大小为 dim 的块。
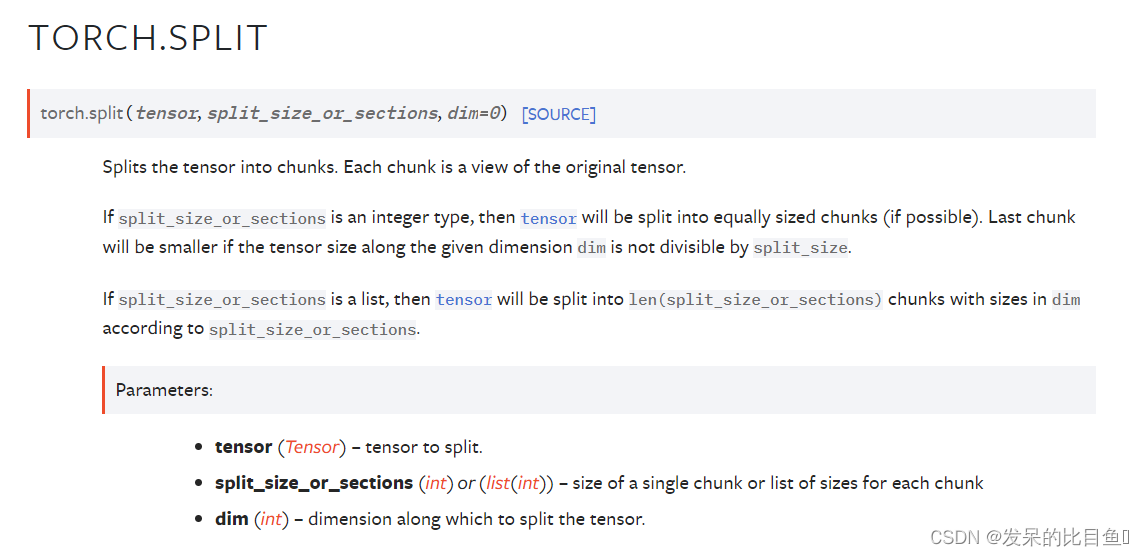
a = torch.arange(10).reshape(5,2)
a
torch.split(a, 2)
torch.split(a, [1,4])
TORCH.SQUEEZE
返回一个删除了所有大小为1的输入维度的张量。
例如,如果输入是形状的:
(
A
×
1
×
B
×
C
×
1
×
D
)
(A \times 1 \times B \times C \times 1 \times D)
(A×1×B×C×1×D) 那么输出张量就是有形状:
(
A
×
B
×
C
×
D
)
(A \times B \times C \times D)
(A×B×C×D)
当给出dim时,只在给定的维度上进行挤压操作。如果输入是形状
(
A
×
1
×
B
)
(A \times 1 \times B)
(A×1×B) Squeeze (input, 0)保持张量不变,但是squeeze(input, 1)会把张量压缩到形状
(
A
×
B
)
(A \times B)
(A×B)
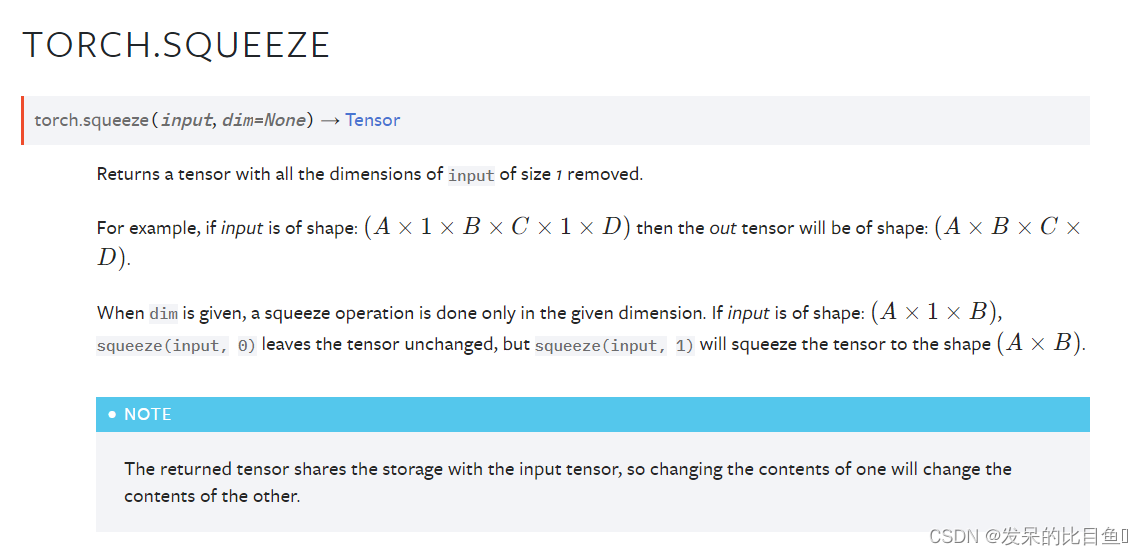
x = torch.zeros(2, 1, 2, 1, 2)
x.size()
y = torch.squeeze(x)
y.size()
y = torch.squeeze(x, 0)
y.size()
y = torch.squeeze(x, 1)
y.size()
TORCH.STACK
沿着一个新的维度连接一个张量序列。
所有张量的大小必须相同。
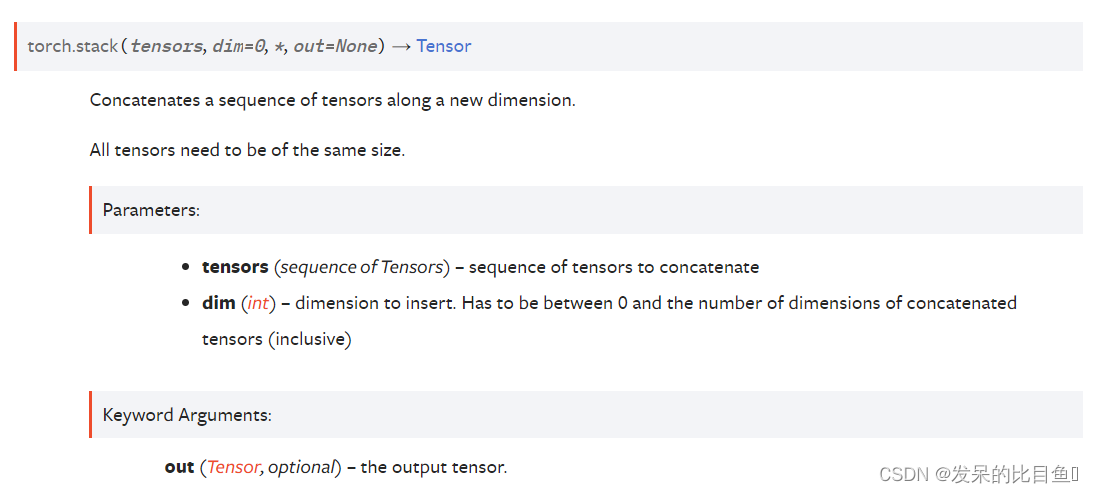
# 假设是时间步T1的输出
T1 = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 假设是时间步T2的输出
T2 = torch.tensor([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
print(torch.stack((T1,T2),dim=0).shape)
print(torch.stack((T1,T2),dim=1).shape)
print(torch.stack((T1,T2),dim=2).shape)
print(torch.stack((T1,T2),dim=3).shape)
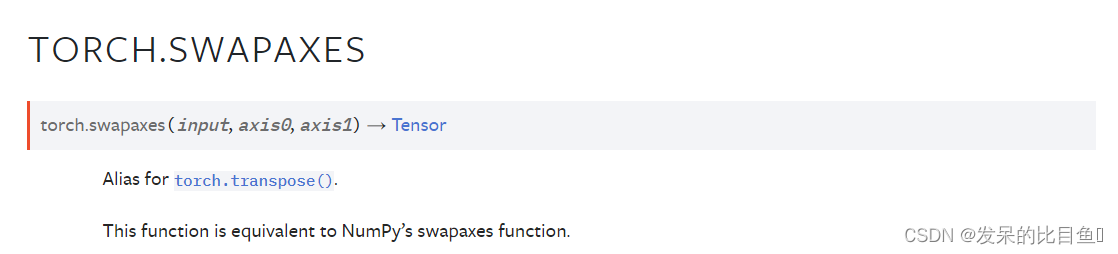
TORCH.SWAPAXES
torch.transpose()别名
这个函数等价于NumPy的swapaxes函数。
x = torch.tensor([[[0,1],[2,3]],[[4,5],[6,7]]])
x
torch.swapaxes(x, 0, 1)
torch.swapaxes(x, 0, 2)
TORCH.SWAPDIMS
Torch.transpose() 的别名
这个函数等价于NumPy的swapaxes函数。

x = torch.tensor([[[0,1],[2,3]],[[4,5],[6,7]]])
x
torch.swapdims(x, 0, 1)
torch.swapdims(x, 0, 2)
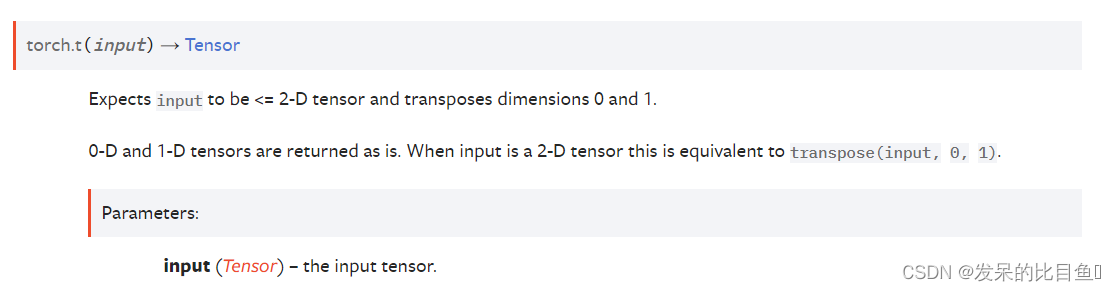
TORCH.T
期望输入为<= 2-D张量,转置维度为0和1。
0-D和1-D张量原样返回。当输入是2-D张量时,这等价于transpose(输入,0,1)
x = torch.randn(())
x
torch.t(x)
x = torch.randn(3)
x
torch.t(x)
x = torch.randn(2, 3)
x
torch.t(x)
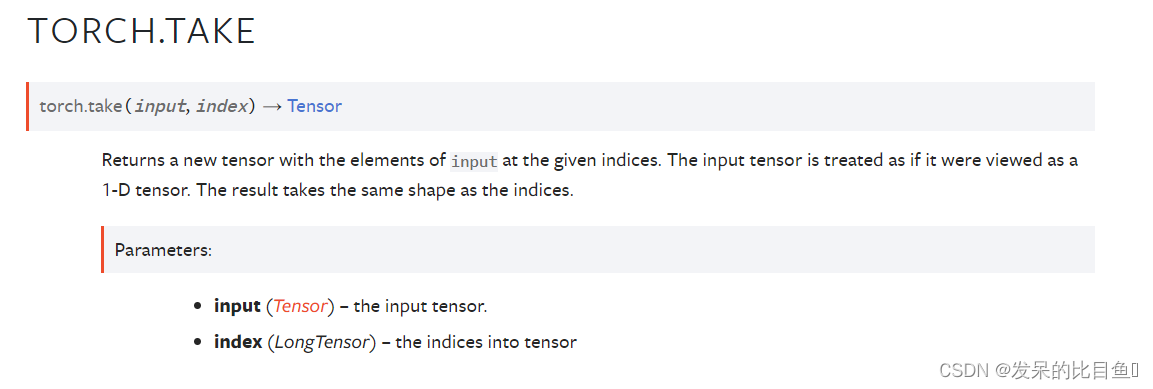
TORCH.TAKE
返回一个新的张量,其中包含给定下标处的输入元素。输入张量被看作是一个一维张量。结果与指数的形状相同。
src = torch.tensor([[4, 3, 5], [6, 7, 8]])
torch.take(src, torch.tensor([0, 2, 5]))
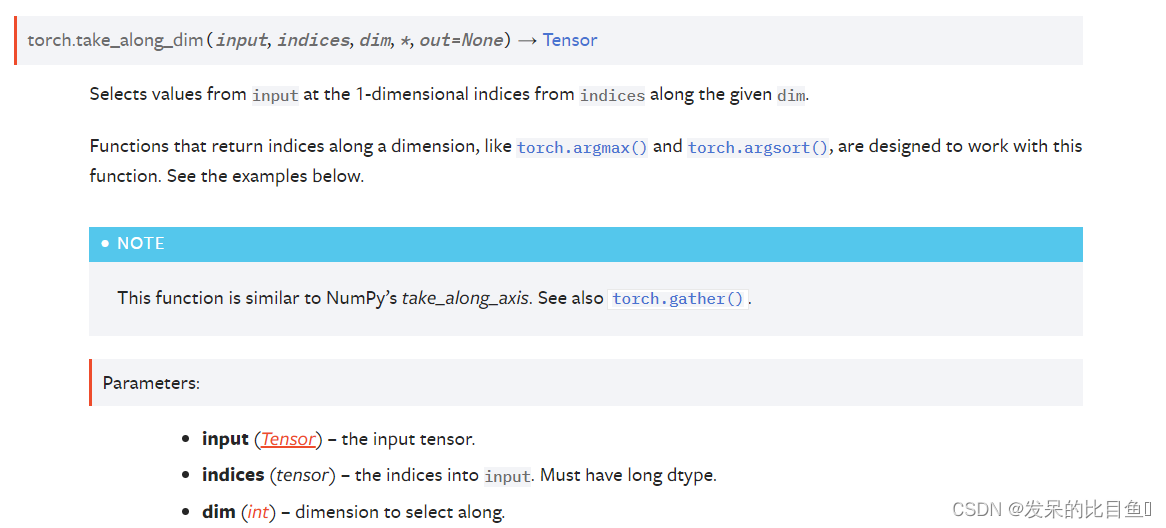
TORCH.TAKE_ALONG_DIM
从给定dim沿线的索引中选择1维索引处的输入值。
沿着一个维度返回索引的函数,如torch.argmax()和torch.argsort(),被设计用来处理这个函数。请看下面的例子。
这个函数类似于NumPy的沿轴函数。请参见torch.gather()。
t = torch.tensor([[10, 30, 20], [60, 40, 50]])
max_idx = torch.argmax(t)
torch.take_along_dim(t, max_idx)
sorted_idx = torch.argsort(t, dim=1)
torch.take_along_dim(t, sorted_idx, dim=1)
TORCH.TENSOR_SPLIT
将一个张量拆分为多个子张量,所有的子张量都是输入的视图,根据indices_or_sections指定的索引或节的数量,沿着dim的维度。这个函数基于NumPy的NumPy.arraysplit()。
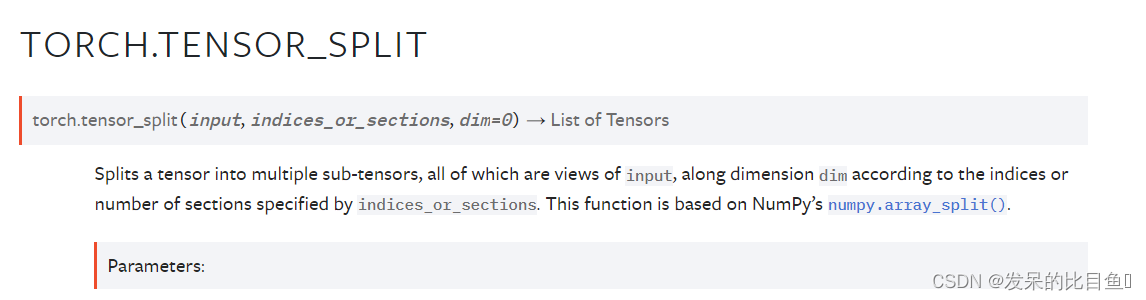
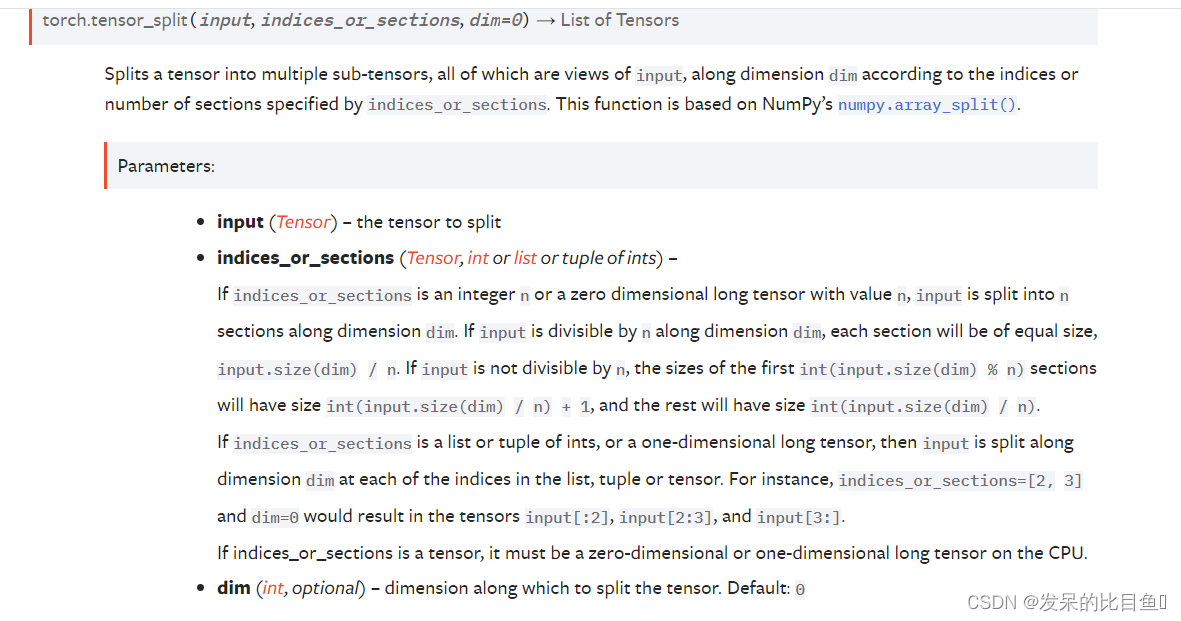
input (Tensor)– 输入indices_or_sections (Tensor, int or list or tuple of ints)– 如果 indices_or_sections 是整数 n 或值为 n 的零维长张量,则输入沿维度 dim 分为 n 个部分。 如果输入沿维度 dim 可被 n 整除,则每个部分的大小将相等,input.size(dim) / n。 如果输入不能被 n 整除,则第一个 int(input.size(dim) % n) 部分的大小将为 int(input.size(dim) / n) + 1,其余部分的大小将为 int( input.size(dim) / n).
如果 indices_or_sections 是整数的列表或元组,或一维长张量,则输入在列表、元组或张量中的每个索引处沿维度 dim 拆分。 例如,indices_or_sections=[2, 3] 和 dim=0 将导致张量 input[:2]、input[2:3] 和 input[3:]。dim (int, optional)– 用来分割张量的维数。默认值:0
x = torch.arange(8)
print(x.shape)
a = torch.tensor_split(x, 3)
print(a)
x = torch.arange(7)
c = torch.tensor_split(x, 3)
print(c)
d = torch.tensor_split(x, (1, 6))
print(d)
x = torch.arange(14).reshape(2, 7)
e = torch.tensor_split(x, 3, dim=1)
f = torch.tensor_split(x, (1, 6), dim=1)
print(e)
print(f)
TORCH.TILE
通过重复输入元素来构造一个张量。参数dims指定每个维度中的重复次数。
如果dims指定的维度比输入的维度少,则在dims之前添加1,直到指定所有维度。例如,如果输入的形状为(8,6,4,2),而dims为(2,2),则dims被视为(1,1,2,2)。
类似地,如果输入的维数少于dims指定的维数,则将输入视为在0维数处解压缩,直到它具有与dims指定的维数相同的维数。例如,如果输入的形状为(4,2),而dims为(3,3,2,2),则输入的形状将被视为(1,1,4,2)。

x = torch.tensor([1, 2, 3])
a = x.tile((2,))
y = torch.tensor([[1, 2], [3, 4]])
b = torch.tile(y, (2, 2))
s = torch.tensor([[[1,2,3],[4,5,6]],[[7,8,9], [10,11,12]]])
print(s.shape)
print(s)
d = torch.tile(s, (2, 2))
print(d)
print(d.shape)
w = torch.randn((2,2))
print(w)
c = torch.tile(w, (3, 3, 2, 2))
print(c)
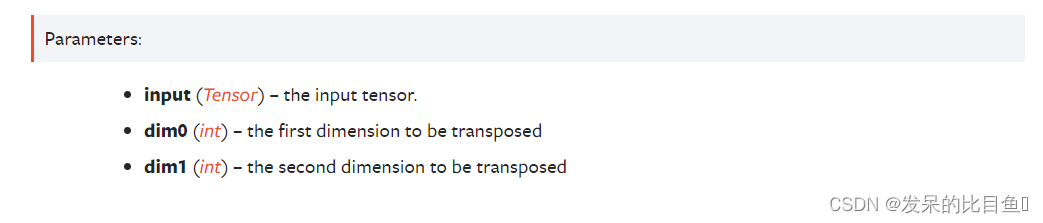
TORCH.TRANSPOSE
- 返回一个张量,它是输入的转置版本。给定的维度dim0和dim1被交换。
- 如果输入是稀疏张量,那么输出张量不与输入张量共享底层存储。
- 如果输入是一个具有压缩布局的稀疏张量(SparseCSR, SparseBSR, SparseCSC或SparseBSC),参数dim0和dim1必须都是批处理维,或者都必须是稀疏维。稀疏张量的批维是在稀疏维之前的维。
交换SparseCSR或SparseCSC布局张量的稀疏维度的转置将导致两个选项之间的布局变化。’ SparseBSR '或SparseBSC布局张量的稀疏维度的转置同样会生成相反布局的结果。
x = torch.randn(2, 3)
x
torch.transpose(x, 0, 1)
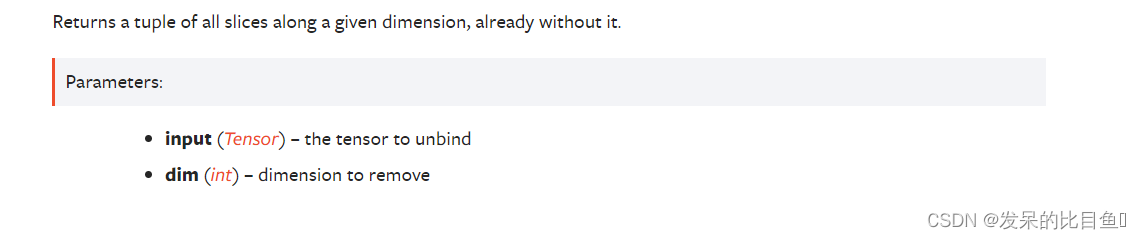
TORCH.UNBIND
删除张量维数。
返回给定维度上的所有切片的元组,已经没有它了。
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
aa = torch.unbind(a)
bb = torch.unbind(a, dim=1)
TORCH.UNSQUEEZE
返回一个插入到指定位置的新张量,其维数为1。
返回的张量与这个张量共享相同的底层数据。
可以使用范围为[-input.dim() - 1, input.dim() + 1)的dim值。负dim将对应于应用于dim = dim + input.dim() + 1的unsqueeze()。

x = torch.tensor([1, 2, 3, 4])
a = torch.unsqueeze(x, 0)
b = torch.unsqueeze(x, 1)
print(a.shape)
print(b.shape)
TORCH.VSPLIT
将输入的二维或多维张量根据指标或分段垂直分割为多个张量。每个分割都是一个输入视图。
这相当于调用torch.tensor_split(input, indices_or_sections, dim=0)(分割维数为0),不同的是,如果indices_or_sections是整数,它必须平均分割维数,否则将抛出运行时错误。
该函数基于NumPy的NumPy.vsplit()。

t = torch.arange(16.0).reshape(4,4)
t
torch.vsplit(t, 2)
torch.vsplit(t, [3, 6])
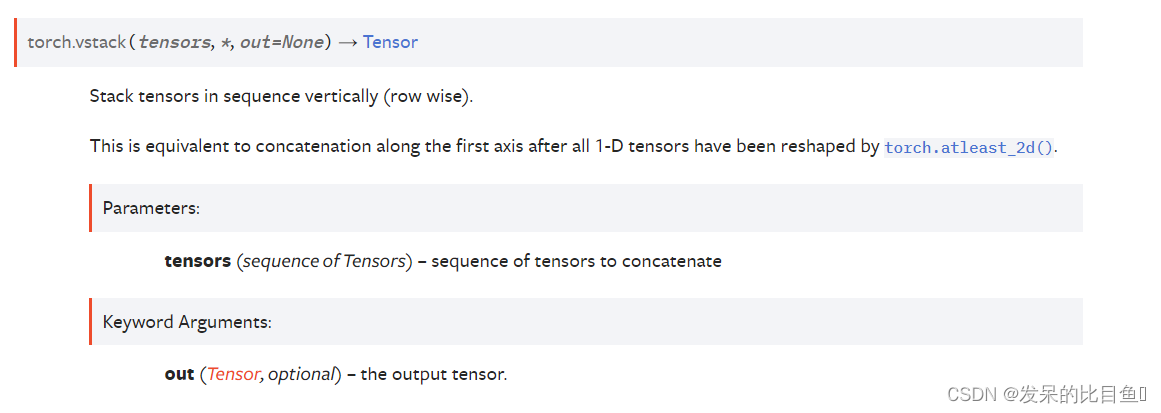
TORCH.VSTACK
按竖直顺序(按行)堆叠张量。这相当于在所有1-D张量被torch.atleast_2d()重塑后,沿着第一个轴进行拼接。
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
torch.vstack((a,b))
a = torch.tensor([[[1],[2],[3]]])
b = torch.tensor([[[4],[5],[3]]])
c = torch.vstack((a,b))
print(a.shape)
print(c.shape)
TORCH.WHERE
返回从x或y中选择的元素的张量,这取决于条件。

参数
condition (BoolTensor)- 当True(非零)时,产生x,否则产生yx (Tensor or Scalar)- 值(如果x是标量)或在条件为True的索引处选择的值y (Tensor or Scalar)- 值(如果y是标量)或在条件为False的下标处选择的值
x = torch.randn(3, 2)
y = torch.ones(3, 2)
x
torch.where(x > 0, x, y)
x = torch.randn(2, 2, dtype=torch.double)
x
torch.where(x > 0, x, 0.)