1.堆栈
JVM运行字节码时,所有的操作基本都是围绕两种数据结构,一种是堆栈(本质是栈结构),还有一种是队列,如果JVM执行某条指令时,该指令需要对数据进行操作,那么被操作的数据在指令执行前,必须要压到堆栈上,JVM会自动将栈顶数据作为操作数。如果堆栈上的数据需要暂时保持起来时,那么它就会被存储到局部变量队列上。
0: bipush 10 //0是程序偏移地址,然后是指令,最后是操作数
2: istore_1
这一步操作实际上就是使用bipush将10推向栈顶,接着使用istore_1将当前栈顶数据存放到第二个局部变量中,也就是a,所以这一步执行的是int a = 10操作。
3: bipush 20
5: istore_2
同上,这里执行的是int b = 20操作。
6: iload_1
7: iload_2
8: iadd
这里是将第二和第三个局部变量放到栈中,也就是取a和b的值到栈中,最后iadd操作将栈中的两个值相加,结果依然放在栈顶。
9: istore_3
10: iload_3
11: ireturn
将栈顶数据存放到第四个局部变量中,也就是c,执行的是int c = 30,最后取出c的值放入栈顶,使用ireturn返回栈顶值,也就是方法的返回值。至此,方法执行完毕。
实际上我们发现,JVM执行的命令基本都是入栈出栈等,而且大部分指令都是没有操作数的,传统的汇编指令有一操作数、二操作数甚至三操作数的指令,相比C编译出来的汇编指令,执行起来会更加复杂,实现某个功能的指令条数也会更多,所以Java的执行效率实际上是不如C/C++的,虽然能够很方便地实现跨平台,但是性能上大打折扣,所以在性能要求比较苛刻的Android上,采用的是定制版的JVM,并且是基于寄存器的指令集架构。在某些情况下,我们可以使用JNI机制来通过Java调用C/C++编写的程序以提升性能(也就是本地方法,使用到native关键字)
2.jvm启动流程:
配置JVM装载环境-> 解析虚拟机参数- >设置线程栈大小->执行JavaMain方法
1.首先进行初始化操作:
InitLauncher(javaw);
DumpState();
if (JLI_IsTraceLauncher()) {
int i;
printf("Command line args:\n");
for (i = 0; i < argc ; i++) {
printf("argv[%d] = %s\n", i, argv[i]);
}
AddOption("-Dsun.java.launcher.diag=true", NULL);
}
2.选择合适的jre版本
SelectVersion(argc, argv, &main_class);3.创建合适的jvm执行环境,例如需要确定模型数据,32位还是64位,以及jvm本身的一些配置在jvm.config文件中读取和解析。
4.jvm初始化,有所在的平台进行
return JVMInit(&ifn, threadStackSize, argc, argv, mode, what, ret);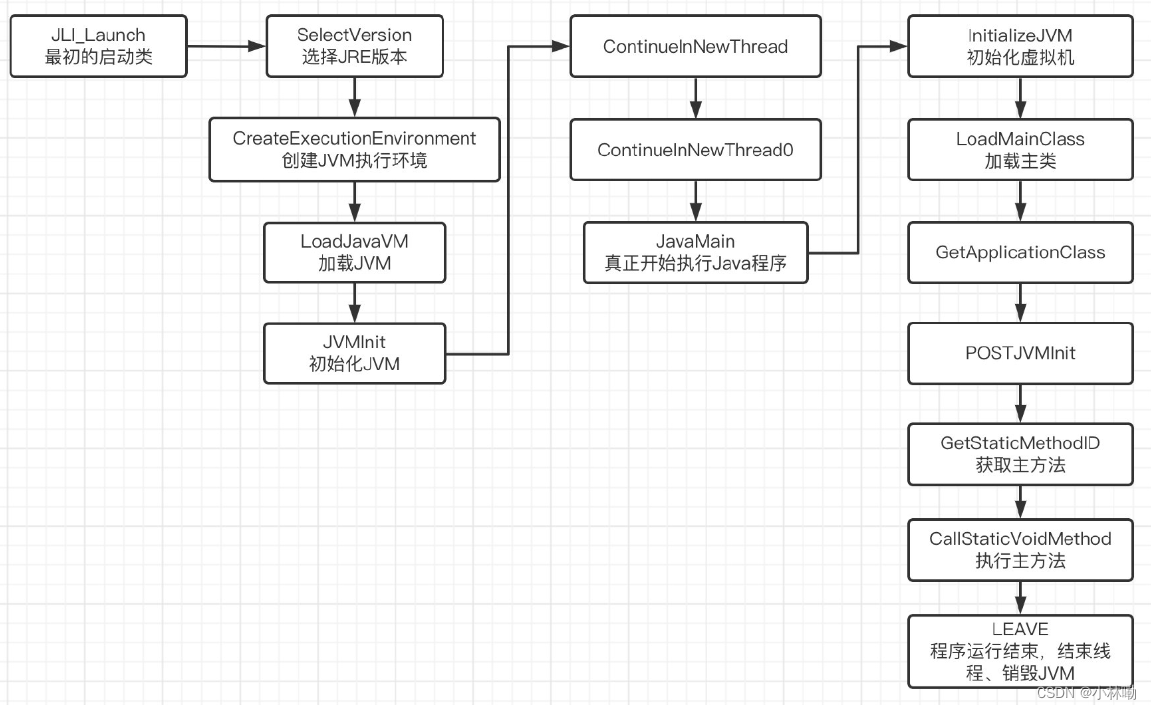
3.内存管理
Java只支持直接使用基本数据类型和对象类型,至于内存到底如何分配,并不是由我们来处理,而是JVM帮助我们进行控制,这样就帮助我们节省很多内存上的工作,虽然带来了很大的便利,但是,一旦出现内存问题,我们就无法像C/C++那样对所管理的内存进行合理地处理,因为所有的内存操作都是由JVM在进行,只有了解了JVM的内存管理机制,我们才能够在出现内存相关问题时找到解决方案。
3.1内存区域划分
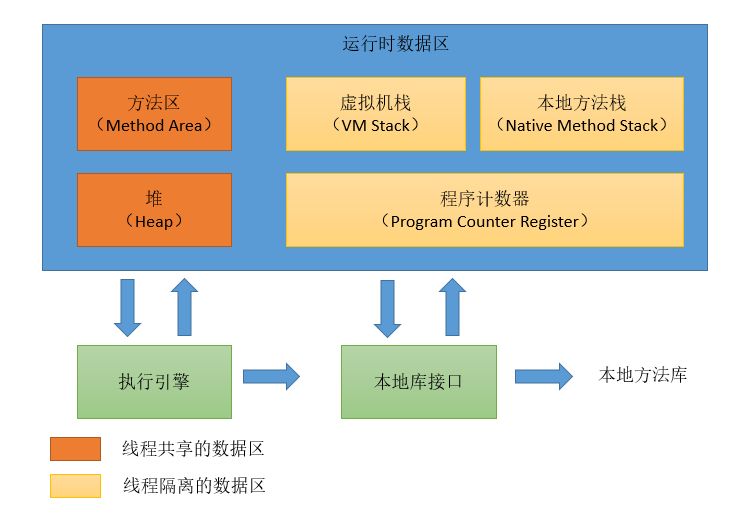
我们可以看到,内存区域一共分为5个区域,其中方法区和堆是所有线程共享的区域,随着虚拟机的创建而创建,虚拟机的结束而销毁,而虚拟机栈、本地方法栈、程序计数器都是线程之间相互隔离的,每个线程都有一个自己的区域,并且线程启动时会自动创建,结束之后会自动销毁。内存划分完成之后,我们的JVM执行引擎和本地库接口,也就是Java程序开始运行之后就会根据分区合理地使用对应区域的内存了。
程序计数器
首先我们来介绍一下程序计数器,它和我们的传统8086 CPU中PC寄存器的工作差不多,因为JVM虚拟机目的就是实现物理机那样的程序执行。在8086 CPU中,PC作为程序计数器,负责储存内存地址,该地址指向下一条即将执行的指令,每解释执行完一条指令,PC寄存器的值就会自动被更新为下一条指令的地址,进入下一个指令周期时,就会根据当前地址所指向的指令,进行执行。
而JVM中的程序计数器可以看做是当前线程所执行字节码的行号指示器,而行号正好就指的是某一条指令,字节码解释器在工作时也会改变这个值,来指定下一条即将执行的指令。
因为Java的多线程也是依靠时间片轮转算法进行的,因此一个CPU同一时间也只会处理一个线程,当某个线程的时间片消耗完成后,会自动切换到下一个线程继续执行,而当前线程的执行位置会被保存到当前线程的程序计数器中,当下次轮转到此线程时,又继续根据之前的执行位置继续向下执行。
程序计数器因为只需要记录很少的信息,所以只占用很少一部分内存。
虚拟机栈
虚拟机栈就是一个非常关键的部分,看名字就知道它是一个栈结构,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(其实就是栈里面的一个元素),栈帧中包括了当前方法的一些信息,比如局部变量表、操作数栈、动态链接、方法出口等。

其中局部变量表就是我们方法中的局部变量,实际上局部变量表在class文件中就已经定义好了,操作数栈就是我们之前字节码执行时使用到的栈结构; 每个栈帧还保存了一个可以指向当前方法所在类的运行时常量池,目的是:当前方法中如果需要调用其他方法的时候,能够从运行时常量池中找到对应的符号引用,然后将符号引用转换为直接引用,然后就能直接调用对应方法,这就是动态链接(我们还没讲到常量池,暂时记住即可,建议之后再回顾一下),最后是方法出口,也就是方法该如何结束,是抛出异常还是正常返回。
public class Main {
public static void main(String[] args) {
int res = a();
System.out.println(res);
}
public static int a(){
return b();
}
public static int b(){
return c();
}
public static int c(){
int a = 10;
int b = 20;
return a + b;
}
}
执行流程:
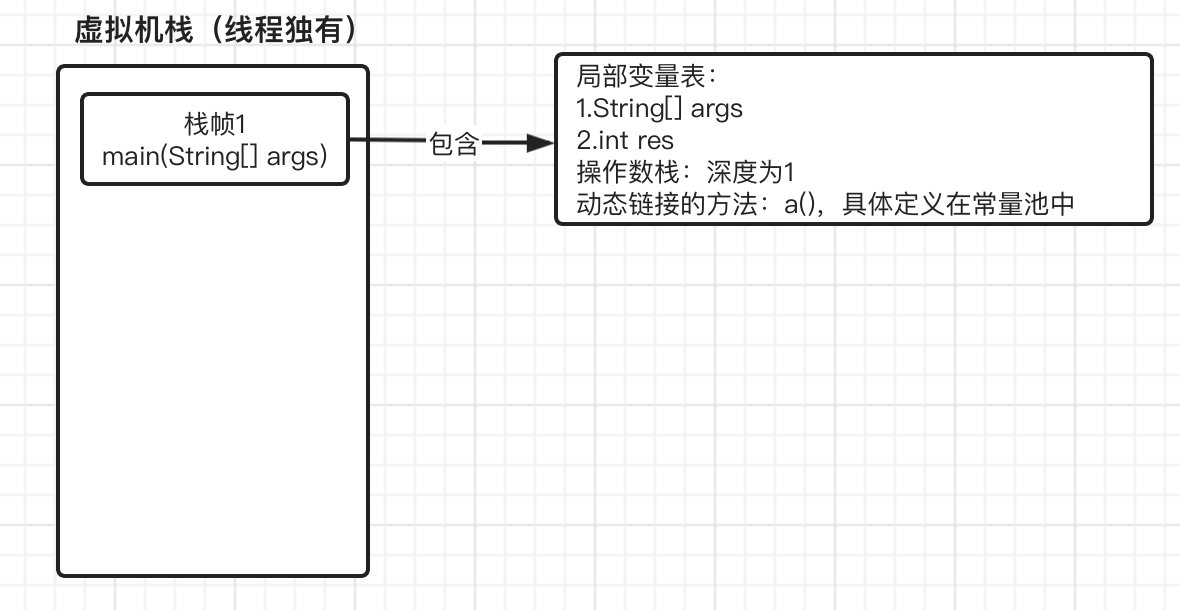
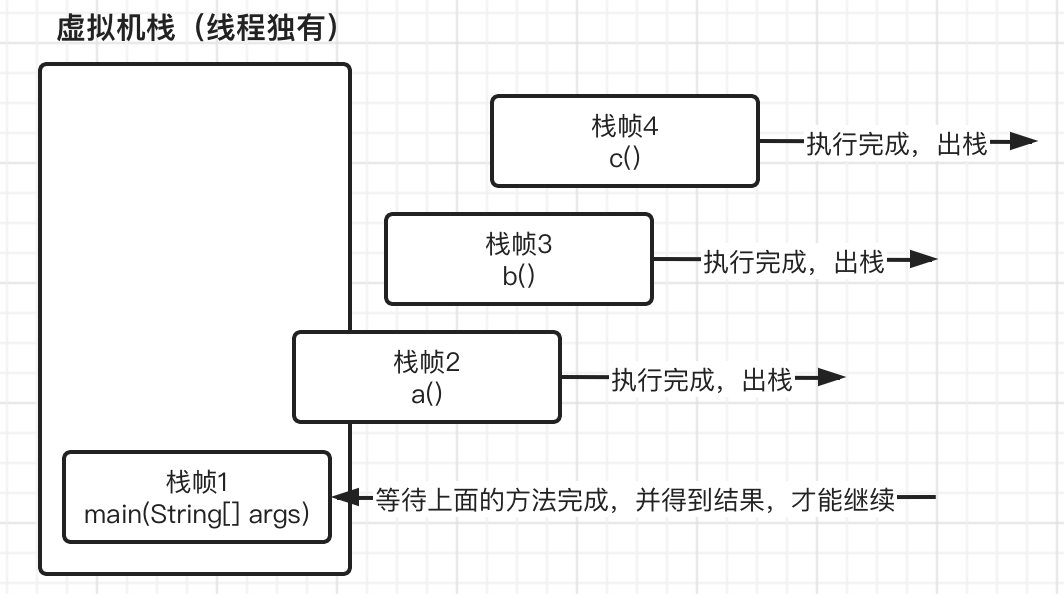
接着我们继续往下,到了0: invokestatic #2 // Method a:()I时,需要调用方法a(),这时当前方法就不会继续向下运行了,而是去执行方法a(),那么同样的,将此方法也入栈,注意是放入到栈顶位置,main方法的栈帧会被压下去:
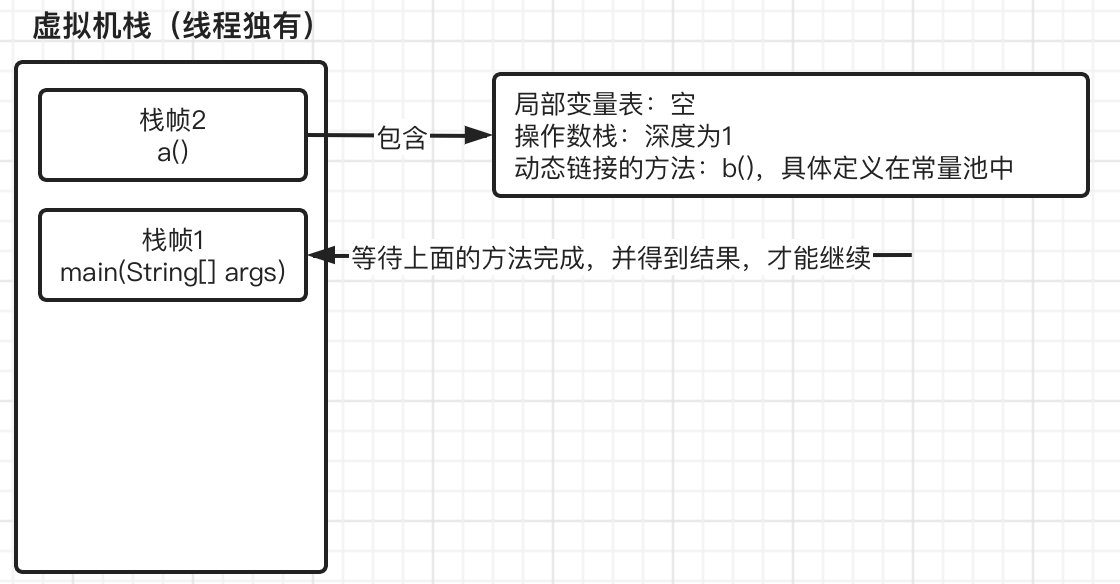
这时,进入方法a之后,又继而进入到方法b,最后在进入c,因此,到达方法c的时候,我们的虚拟机栈变成了:
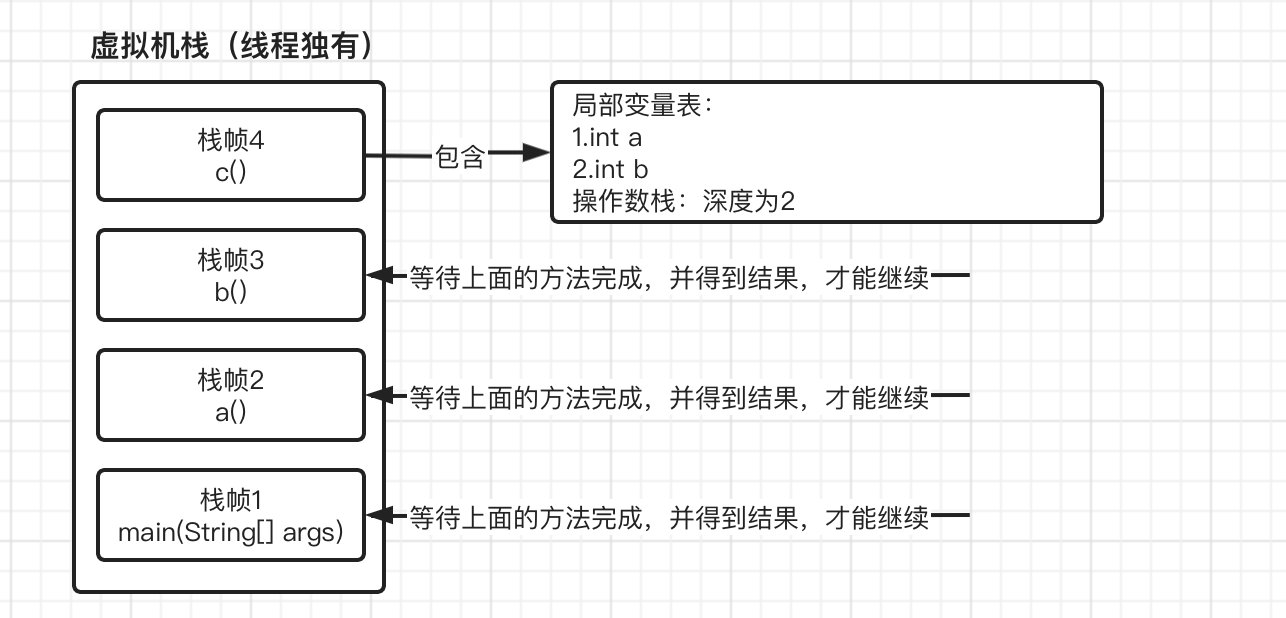
现在我们依次执行方法c中的指令,最后返回a+b的结果,在方法c返回之后,也就代表方法c已经执行结束了,栈帧4会自动出栈,这时栈帧3就得到了上一栈帧返回的结果,并继续执行,但是由于紧接着马上就返回,所以继续重复栈帧4的操作,此时栈帧3也出栈并继续将结果交给下一个栈帧2,最后栈帧2再将结果返回给栈帧1,然后栈帧1就可以继续向下运行了,最后输出结果。