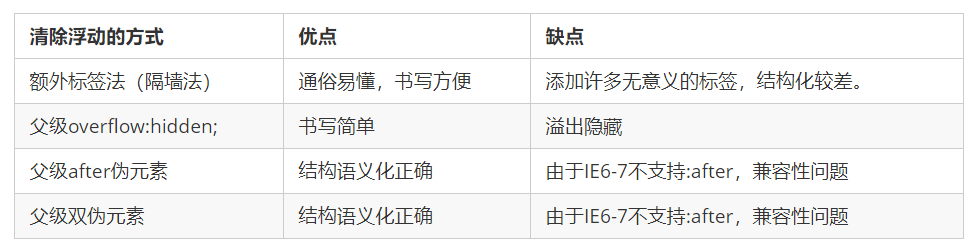
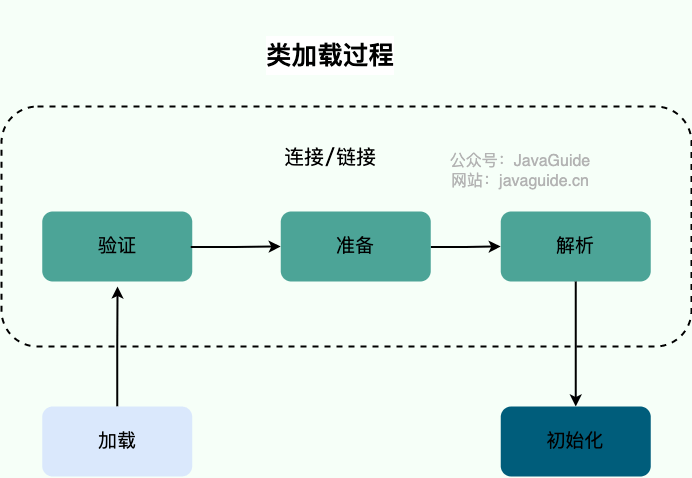
1、摘要与引言
以往的MIL算法遵循i.i.d假设:训练样本与测试样本都分别来自于同一分布中,而这一假设往往与现实应用中有所出入。研究人员通过计算训练样本与测试样本之间的密度比对训练样本进行加权,以解决分布变化带来的问题。
分布的变化发生的原因有许多,诸如:训练数据与测试数据是在不同的时间或不同的地点收集的。当分布发生变化时,由于无法区分因果实例与噪声实例,算法的性能会发生改变。当训练集与测试集分布不同时,噪音实例和标签之间的关联性将不一致。

如图所示,训练集中的数据在夏天收集的,因果实例是狗,噪声实例是草,并与因果实例高度相关。而测试集中的数据是在冬季收集的,背景大多是雪,而雪则成为了噪音实例。若不考虑分布变化,由于训练样本与测试样本的分布差异,标准有监督算法通常倾向于预测草中有狗的图像为正,而雪中有狗的图像为负。
本文提出了第一个解决MIL中分布变化问题的算法框架,并且此方法不需要无标签的测试数据集。将实例分为三类:因果实例(狗勾)、噪声实例(草)和负实例(其他背景实例),解决MIL中的分布变化问题。
2、Stable Multi-instance Learning Framework
因果实例:考虑将实例 x x x加入到包 X j X_{j} Xj中并观察包标签 Y Y Y,并通过观察标签是否发生变化来确定实例 x x x与标签 Y Y Y是否存在因果关系。换句话说,若实例 x x x与标签 Y Y Y存在因果关系,则将它添加到一个负包中时,该包的标签将从负变为正。若实例 x x x与标签 Y Y Y不存在因果关系,则标签不会发生改变。这种因果关系不会因训练数据或测试数据而发生改变。
噪音实例:噪音实例要么与因果实例和包标签中的其中一个有关联,要么与两者都有关联。如:草和雪都属于噪音实例。虽然草和雪都和因果实例以及标签存在关联,但它们的相关性在训练集与测试集中有所不同。
负实例:与标签无关联的实例,即与包标签无任何关联的随机背景对象。
由于因果实例与标签之间的关系不会因训练集与测试集之间的分布不同而改变,基于因果实例的MIL分类器将获得更加稳定的性能。
2.1、Learning Causal Instances from Experiment
我们只考虑从正包中找出因果实例。
∪
B
+
\cup \mathcal{B}^{+}
∪B+表示包含着来自正包中的所有实例组成的实例池,池中实例
x
∈
∪
B
+
x\in \cup \mathcal{B}^{+}
x∈∪B+。为了确定实例
x
x
x是否为因果实例,需要计算实例
x
x
x对包标签
Y
Y
Y的因果效应,通常定义为加入实例后的预期标签与加入实例前的预测标签之间的差异性:
T
(
x
)
=
E
[
Y
(
T
=
1
)
]
−
E
[
Y
(
T
=
0
)
]
.
(1)
\mathcal{T}\left ( x \right ) =\mathbb{E}\left [ Y\left ( T=1 \right ) \right ] -\mathbb{E}\left [ Y(T=0) \right ] .\tag{1}
T(x)=E[Y(T=1)]−E[Y(T=0)].(1)
其中,
Y
(
T
=
1
)
Y(T=1)
Y(T=1)表示预期标签,即:候选实例
x
x
x出现在包中;
Y
(
T
=
0
)
Y(T=0)
Y(T=0)表示预期标签,即:候选实例
x
x
x未出现在包中。
我们可以通过将候选实例
x
x
x添加到一个包中(若包内不存在候选实例)或从包中移出实例
x
x
x(若包内存在候选实例)来获得处理过或未处理过的包。因此,可以通过数据与oracle分类器提供的期望差异来评估因果效益:
T
(
x
)
=
E
[
Y
∗
(
T
=
1
)
]
−
E
[
Y
∗
(
T
=
0
)
]
.
(2)
\mathcal{T}\left ( x \right ) =\mathbb{E}\left [ Y^{*}\left ( T=1 \right ) \right ] -\mathbb{E}\left [ Y^{*}(T=0) \right ] .\tag{2}
T(x)=E[Y∗(T=1)]−E[Y∗(T=0)].(2)
其中,
Y
∗
Y^{*}
Y∗表示经处理后(将候选因果实例加入包中)的包标签。
由标准MIL假设知:向正包中添加任何实例或是从负包中移除任何实例都不会改变包的标签。因此 E [ Y ∗ ∣ Y = 0 , T = 0 ] = 0 , E [ Y ∗ ∣ Y = 1 , T = 1 ] = 1 \mathbb{E}\left [ Y^{*}|Y=0,T=0 \right ]=0,\mathbb{E}\left [ Y^{*}|Y=1,T=1 \right ]=1 E[Y∗∣Y=0,T=0]=0,E[Y∗∣Y=1,T=1]=1。同时,对正包进行处理时有两种可能性:
①预处理包中含有除
x
x
x以外的正实例;
②预处理包中只含有
x
x
x作为其正实例。
2.2、Learning Stable Instances from Data
为了获得稳定实例,首先使用训练集数据训练一个多示例分类算法
A
\mathcal{A}
A,并使用
A
A
A表示
A
\mathcal{A}
A返回的分类器。对于每一个候选实例
x
x
x,我们构建一组包集合,其中包含了
m
−
m^{-}
m−个treated bags。每个treated bag都是通过向负包
X
i
−
X_{i}^{-}
Xi−中添加候选实例
x
x
x构建的。
对于每个treated bag,我们再使用之前训练得到的分类器
A
A
A来预测其标签。最后,我们使用treated bag的预测标签均值来估计预期:
T
^
(
x
)
=
1
m
−
∑
i
=
1
m
−
A
(
X
i
x
)
\hat{\mathcal{T}}(x)=\frac{1}{m^{-}}\sum_{i=1}^{m^{-}}A(X_{i}^{x})
T^(x)=m−1i=1∑m−A(Xix)
估计后,选择得分
s
s
s高于
T
\mathcal{T}
T的候选实例作为稳定实例。




![[MySQL核心]1.表操作](https://img-blog.csdnimg.cn/3d5e271bafdd469c98c072727c6188b4.png)