案例一-线程安全的单例模式(面试)
是一种设计模式,设计模式针对写代码时的一些常见场景给出一些经典解决方案
单例模式的两种典型实现
饿汉模式
懒汉模式
饿汉的单例模式:比较着急去进行创建实例
懒汉的单例模式,是不太着急创建实例,,只是在用的时候,才真正创建


这个是类对象,也就是.class文件,被JVM加载到内存后,表现出的模样
类对象里就有.class文件中的一切信息
包括:类名是啥,类里有哪些属性,每个属性叫什么.....
有了这些信息才能实现反射
1.饿汉模式

针对唯一实例的初始化,比较着急,类加载阶段,就会直接创建实例
对于getinstance 仅仅是读取了变量的内容, 如果是多个线程只是读同一个变量
不修改,此时任然是线程安全的
class Singleton{ //饿汉模式 //使用static创建唯一实例,并且立即进行实例化.是这个类的唯一实例 private static Singleton instance=new Singleton(); //防止程序员一不小心创建,把构造方法设为private private Singleton(){} //创建一个方法.拿到唯一实例 public static Singleton getInstance(){ return instance; }}
2.懒汉模式
1)初始模板
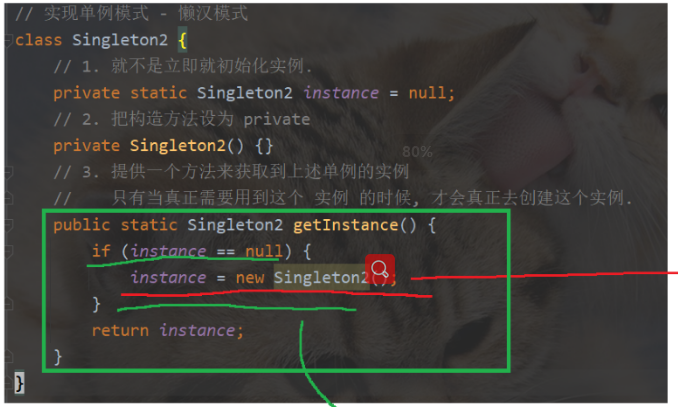
这个方法的好处就是在真正使用getInstacne的时候才会真的创建实例
这里既包含了读,也包含了修改
读和修改是分成两个步骤的,并不是原子性的
这样就很可能涉及到线程安全的问题

还是根之前的count++同样的原理
先是读取到cpu上,然后实例化,再存到对应的内存上
2)避免线程不安全
加锁,
不能随便加synchronized
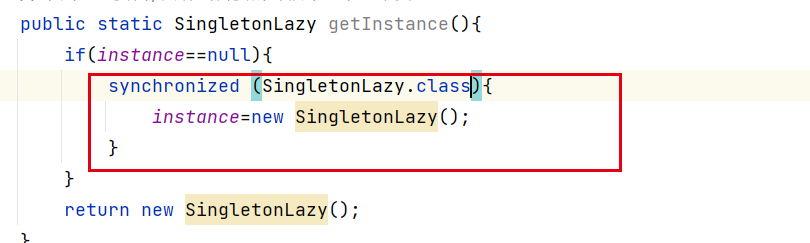
这里的读没加锁,写加锁,还是没用.还是没用把读和写放在一起
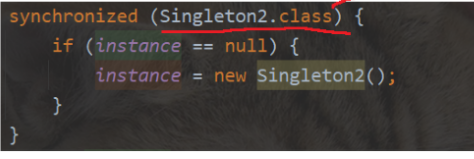
这里的类对象作为锁对象,类对象在一个程序中只有一份,能保证多个线程调用getinstance的时候都是针对同一个对象加锁
3)锁竞争问题
虽然初始化问题的线程安全搞定了
但是如果初始化后,if的条件就不成立了,getinsance就只剩下读操作,就线程安全 了,但是如果代码就这样,
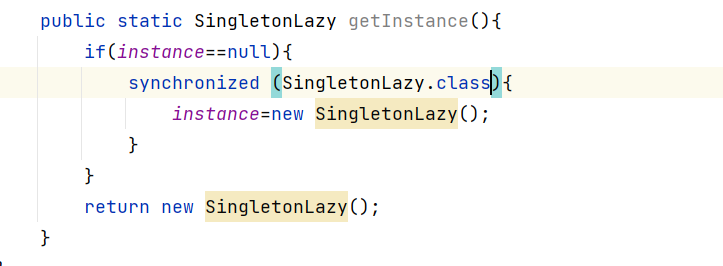
无论初始化前后每次进入都会加锁,也就存在大量锁竞争
这样速度就变慢了
解决方案
让初始化之前才进行加锁,初始化之后就不加锁了.
就再进行一条条件判定


加锁很有可能导致代码出现阻塞,

第一个if判定的是否要加锁
第二个if判定是否要创建实例
3)内存可见性问题
如果多个线程都去调用这里的getinsance.就会造成大量的读内存操作
很有可能会让编译器把读内存操作优化成读寄存器操作
如果这样的话,就算已经实例化第一层就会误认为是null
就会导致不该加锁的锁给加了
但是不会影响第二层的if->synchroized可以预防内存可见性
解决方法:
给instance加上volatile
保证insance不会被编译器优化

4)总结
①给正确的位置加锁
②双重if判定
③volatile内存可见性问题
案例二--------阻塞队列
阻塞队列符合先进先出规则的队列
0.功能
1.线程安全
2,产生阻塞效果
1)如果队列为空,尝试出队列,就会出现堵塞,阻塞到队列不为空为止
2)如果队列为满,尝试入队列,就会出现阻塞,阻塞到入列不为满为止
基于上述特性,就可以实现生产者-消费者模型
阻塞队列可以作为生产者消费者模型中的交易场所

生产者消费者模型.是服务器开发的场景常用
1.优点
优点1 可以让多个服务器程序之间充分的解耦合

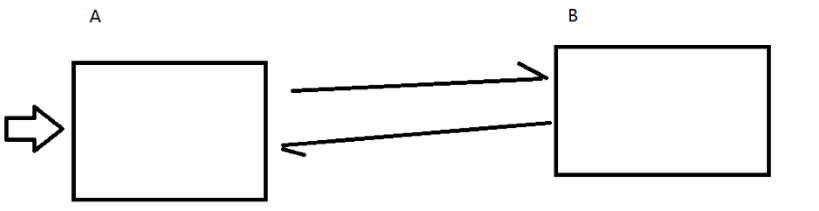
此时A和B的耦合性比较强
开发A代码的时候就得充分了解到B提供的一些接口
开发B代码的时候也得充分了解A是如何调用的
一旦B发生改动,A也要改动
使用生产者消费者模型,就可以降低这里的耦合

对于 请求:A是生产者,B是消费者
对于响应:A是消费者,B是生产者
阻塞队列都是作为交易场所的
A和B都只需要关注如何与队列交互
优点二:能够对请求进行"削峰填谷"
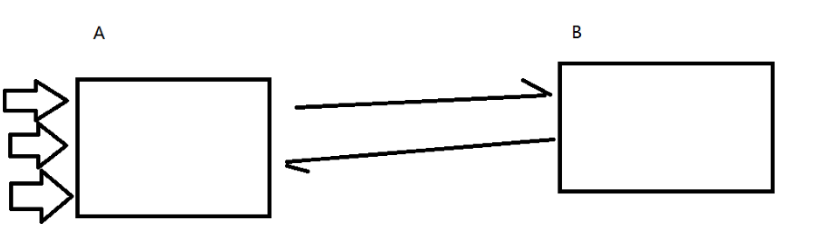
假设请求突然暴涨
A作为入口服务器,计算量轻,问题可能还好
但是B作为应用服务器,计算量大,需要的资源系统也多,如果请求更多了,需要资源进一步增加,如果主机的硬件不够,程序就挂了
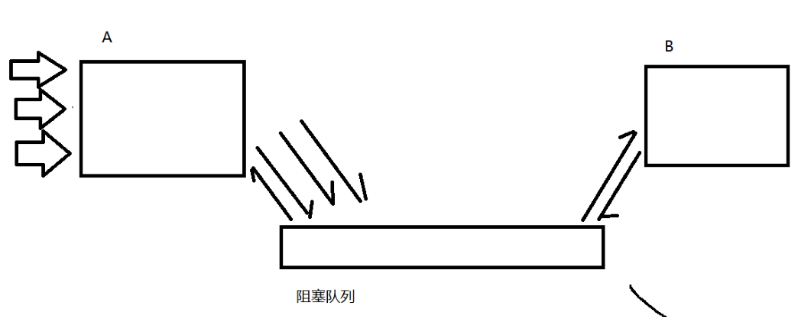
A请求暴涨=>阻塞队列的请求暴涨
由于阻塞队列本来计算量小,只是单纯存数据,所以能抗住更大压力
对于B来说,依然按照原来额度速度来消费数据,不会因为A的暴涨二暴涨

削峰:这种峰值不是持续的,过去了就恢复了
填谷:按照原来哦的频率处理之前挤压的数据
3.java标准库的阻塞队列


4.自身实现
1)实现一个循环队列->底层用数组实现->双指针

①.入队列
把新元素放到tail的位置上,并且tail++
②出队列
把head位置上上的元素返回回去,并且head++
③循环
当指针head/tail到达数组末尾的时候,就需要从头开始,重新循环
④判断空还是满
空和满都是head和tail重合
1)浪费一个格子,head==tail认为是空
head==tail+1认为是满
2)额外创建一个变量,size.记录元素额度个数
size==0 空
size==arr.length 满
class MyBlockingQueue{
//底层用数组实现
private int[] arr=new int[1000];
//初始化
private int size,head,tail;
//入队列
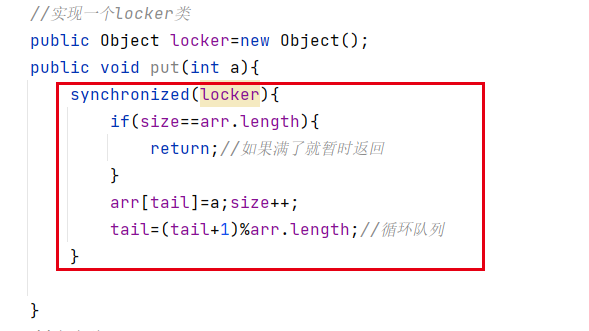
//实现一个locker类,拥有wait和notify方法
private Object locker=new Object();
public void put(int a) throws InterruptedException {
synchronized(locker){
if(size==arr.length){
// return;//如果满了就暂时返回
locker.wait();
}
arr[tail]=a;size++;
tail=(tail+1)%arr.length;//循环队列
locker.notify();
}
}
//出队列
public Integer take() throws InterruptedException {
synchronized (locker){
if(size==0){
//return null;//如果是空的就暂时返回,但是-1明显不高,就把int包装类
locker.wait();
}
int a=arr[head];
head=(head+1)% arr.length;size--;
locker.notify();
return a;
}
}
}注意:

2)让队列线程安全
保证多线程环境下,调用put和take都是线程安全的
但是put和take每一步都是操作公共变量
于是我们直接对整个方法加锁
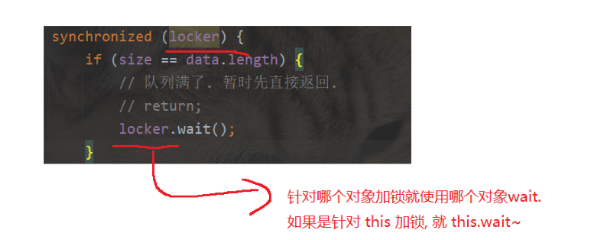
实现一个locker类,读写就是locker
3)实现阻塞效果
关键要点就是使用wait和notify机制
对于put来说:阻塞条件,就是队列为满
对于take来说:阻塞条件,就是队列为空
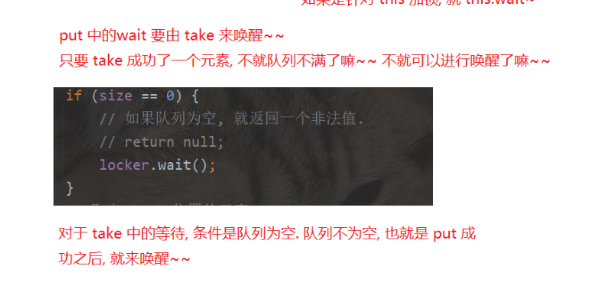
加锁以后.如果成功take了.就说明不再空了,就可以再take以后唤醒

5,实现一个简单的生产者-消费者模型
public static void main(String[] args) {
MyBlockingQueue queue=new MyBlockingQueue();
Thread producer=new Thread(()->{
int num=0;
while (true){
try {
queue.put(num);
System.out.println("生产了"+num);
num++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
Thread customer=new Thread(()->{
while(true){
try {
int tmp = queue.take();
System.out.println("消费了"+tmp);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
}案例三-定时器
像闹钟一样,进行定时,在一定时间之后,被唤醒并执行某个之前设定好的任务

1.标准库的的定时器
java.util.Timer
核心方法 就一个:schedule 参数有两个:任务是什么.多长时间之后执行
任务就是一段代码
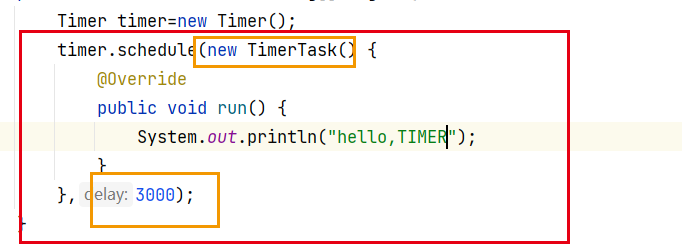
Timer有自己专门的线程,来负责执行注册的任务
2.实现一个定时器
1)描述任务
创建一个专们的类表示定时器的任务(TimerTask)

2)组织任务
使用一定的数据结构把这些任务放在一起

咱们的需求就是,当运行的时候,快速找到所有任务中最小的任务
那很明显就是用堆->用带有阻塞的队列

因为此处的队列需要考虑到线程安全问题,可能存在多个线程里进行注册任务.同时还有一个专门的任务来执行,所以需要考虑
3)执行时间到了的任务
需要执行时间最靠前的任务,就需要有个线程,不停地检查当前优先级队首元素看是不是到了

4)实现比较器
如果要实现自己的类,要接上比较器接口->堆如果是自己的类型,就一定要在自己类里实现自己比较器并接上比较器接口


5)解决忙等问题
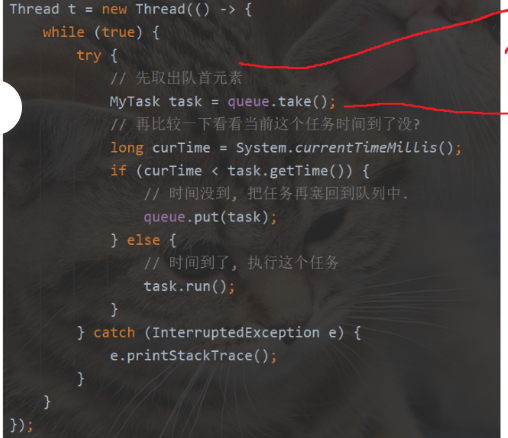
如果不加任何限制,这个循环会执行的非常快
如果队列是空的,就会阻塞,
如果没空,而且任务时间没到,就会不停地循环
这就叫忙等
浪费CPU
基于wait来实现
指定等待时间,计算出当前时间和任务的目标之间的时间差,就等待这么长时间即可
到了等待时间就会唤醒
问题:既然指定了一个等待时间,为什么不直接用sleep.而用wait呢
因为sleep不能被中途唤醒
而wait能够被中途唤醒
因为在等待过程中,可能要插入新的任务,新的任务很有可能在所有任务之前的
比如在schedule操作中,就需要假如一个notify操作
一旦有任务进来,就唤醒
class MyTask implements Comparable<MyTask>{
//1.描述一个任务
private Runnable runnable;
//2.描述一个时间
private long time;
//3.创建一个任务
public MyTask(Runnable runnable,long delay){
//描述的时间是一个时间jiange,而不是一个确切的时间
this.runnable=runnable;
this.time=System.currentTimeMillis()+delay;
}
public void run(){
runnable.run();
}
public long getTime() {
return time;
}
@Override
public int compareTo(MyTask o) {
return (int)(this.time-o.time);//小根堆
}
}
public class MyTimer {
private PriorityBlockingQueue<MyTask> queue=new PriorityBlockingQueue<>();
private Object locker=new Object();
public void schedule(Runnable runnable,long delay){
MyTask task=new MyTask(runnable,delay);
queue.put(task);
synchronized (locker){
locker.notify();
}
}
public MyTimer(){
//创建这个线程,看是不是时间到了,该执行任务了
Thread t=new Thread(()->{
while (true){
//先取出队首元素
try {
MyTask task=queue.take();
long curTime=System.currentTimeMillis();//看一下当前时间
if(curTime<task.getTime()){
queue.put(task);
long dec=task.getTime()-curTime;
synchronized (locker){
locker.wait(dec);
}
}else{
task.run();//时间到了,执行
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}3.总结
1.描述一个任务 runable+time
2.使用优先级队列来组织若干个任务PriorityBlockingQueue
3.实现schedule来注册任务到队列里
4.创建个扫描线程,让它不停地获取最小元素,并且判定时间是否到达
5.要注意自我创建的类要实现比较器 并且要注意解决这里的忙等问题
四.线程池
1.原因
进程频繁创建销毁,开销比较大,所以我们想到了进程池或者线程
线程,虽然比进程轻了.但是如果创建销毁的频率比较多,开销还是有的,解决方案:线程池或协程
线程池:把线程提前创建好,放在池子里.后面用到线程直接从池子里取,就不需要在系统申请
线程用完了.也不是还给系统.而是放回池子里,以备下次再用
这会创建销毁过程,就快很多
问题?线程放池子里就比系统申请释放来的快?
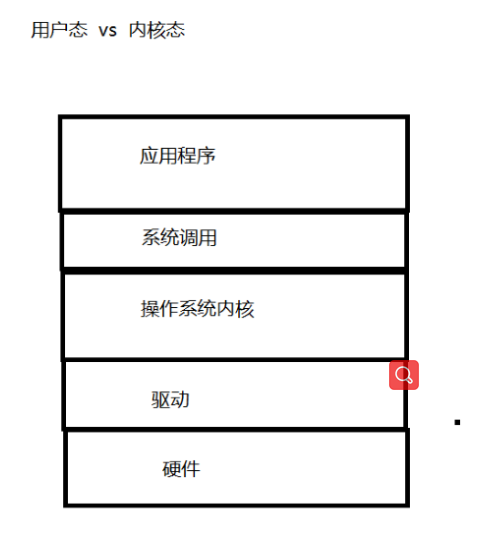
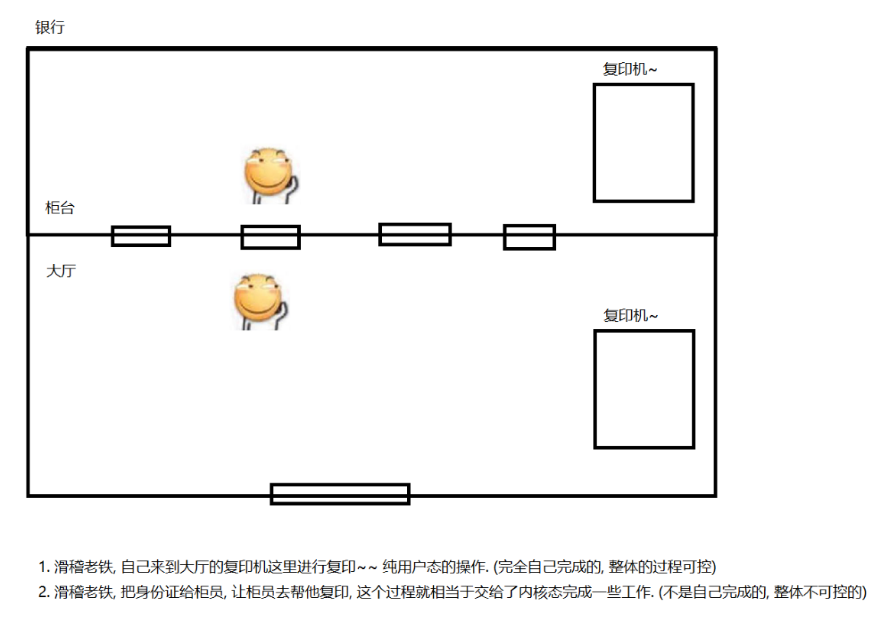
代码是最上面的应用程序来运行.这里的代码都称为"用户态运行的代码

创建线程,本身需要内核的支持
创建线程的本质就是在内核建立一个PCB(进程控制块)加到链表里
所以这是要进入内核态来运行
而把创建好玩的线程放到池子里,由于池子就是用户态实现的,这个放到池子/从池子里取的过程,不涉及到内核态,纯粹的用户态代码能够完成
一般情况下,纯用户态的操作效率高于经过内核态操作,

2.java标准库线程的使用

构造方法

① int corePoolSize 核心线程数->正式员工的数量
② int maximumPoolSize 最大线程数(正式员工+临时工)
③ long keepAliveTime 允许临时工摸鱼的时间
③TimeUnit unit 时间的单位
⑤ BlockingQueue workQueue 任务队列
线程池会提供一个submit方法,让程序员把任务注册到线程池中,加入到这个任务队列中
⑥ ThreadFactory threadFactory 线程工厂 线程是如何创建的
⑦RejectedExecutor handler 拒绝策略
当任务队列满了,该怎么做
1)直接忽略最新任务,2)阻塞等待,3)直接丢弃最老的任务
虽然线程池的参数很多,但是最重要的参数还是线程的个数


3.面试问题
程序要并发的多线程完成一些任务,如果使用线程池的话,这里的线程池设为多少合适?
正确做法:通过性能测试的方式 找到合适的值
例如,写一个服务器程序,服务器通过线程池,多线程的处理用户请求
就可以对这个服务器进行性能请求,构造一些请求发送给服务器,测试性能,这里的请求就需要构造很多,根据不同的线程池的线程数,来观察程序处理任务的速度和CPU的占用率

CPU占用率是很重要的,比如线上服务器,一定要留有一定的冗余,假如请求突然暴涨,如果CPU都快满了,这个时候服务器就会挂了
4.自用的线程池
Excutors
本质是针对ThreadPoolExecutor进行了封装,提供了一个默认参数
要知道线程池里面有什么
1)能够描述任务(用Runnable)
2)需要一个数据结构组织任务(直接使用BlockingQueue
3)能够描述工作线程
4)要组织线程
5)要能实现往线程池里添加任务
class MyThreadPool {
// 1. 描述一个任务. 直接使用 Runnable, 不需要额外创建类了.
// 2. 使用一个数据结构来组织若干个任务.
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
// 3. 描述一个线程, 工作线程的功能就是从任务队列中取任务并执行.
static class Worker extends Thread {
// 当前线程池中有若干个 Worker 线程~~ 这些 线程内部 都持有了上述的任务队列.
private BlockingQueue<Runnable> queue = null;
public Worker(BlockingQueue<Runnable> queue) {
this.queue = queue;
}
@Override
public void run() {
// 就需要能够拿到上面的队列!!
while (true) {
try {
// 循环的去获取任务队列中的任务.
// 这里如果队列为空, 就直接阻塞. 如果队列非空, 就获取到里面的内容~~
Runnable runnable = queue.take();
// 获取到之后, 就执行任务.
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 4. 创建一个数据结构来组织若干个线程.
private List<Thread> workers = new ArrayList<>();
public MyThreadPool(int n) {
// 在构造方法中, 创建出若干个线程, 放到上述的数组中.
for (int i = 0; i < n; i++) {
Worker worker = new Worker(queue);
worker.start();
workers.add(worker);
}
}
// 5. 创建一个方法, 能够允许程序猿来放任务到线程池中.
public void submit(Runnable runnable) {
try {
queue.put(runnable);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}