官网: 点击直达官网
文档: 点击查看官网文档
以下内容部分来自官网或官网文档。文章比较长,请准备好瓜子和小板凳~~~
TIP:
- 文中用到的网站地址仅为了说明功能,如有侵犯,请告知,会及时删除或者修改
- 本文仅供学习参考,请勿用于非法用途
一、介绍
简介
spider-flow 是一个基于springboot+layui开发的前后端不分离的爬虫平台,以图形化方式定义爬虫流程,无需代码即可实现一个爬虫。
特性
- 支持css选择器、正则提取
- 支持JSON/XML格式
- 支持Xpath/JsonPath提取
- 支持多数据源、SQL select/insert/update/delete
- 支持爬取JS动态渲染的页面
- 支持代理
- 支持二进制格式
- 支持保存/读取文件(csv、xls、jpg等)
- 常用字符串、日期、文件、加解密、随机等函数
- 支持流程嵌套
- 支持插件扩展(自定义执行器,自定义函数、自定义Controller、类型扩展等)
- 支持HTTP接口
- 支持数据源配置
- 支持任务的定时执行
插件
- redis插件
- mongodb插件
- IP代理池插件
- OSS插件
- OCR插件
- Selenium插件
二、部署
代码仓库地址: https://gitee.com/ssssssss-team/spider-flow
部署及验证
spiderflow是基于springboot的单体项目,可以采用多种方式实现部署:
-
Dockerfile
-
docker-compose
-
java -jar …
也可以参考官网文档里面的安装部署模块进行部署。
默认端口是8088, 部署完成后访问http://localhost:8088即可,页面如下图所示:
三、编辑器组件介绍及常用语法
部署完成后打开页面会看到有4个内置的爬虫示例,随便点开一个我们看下编辑器布局和提供的组件。

组件介绍

爬取节点
该节点用于请求HTTP/HTTPS页面或接口
- 请求方法:GET、POST、PUT、DELETE等方法
- URL: 请求地址
- 延迟时间:单位是毫秒,意思是爬取之前延迟一段时间在执行抓取
- 超时时间:网络请求的超时时间,单位也是毫秒
- 代理:请求时设置的代理,格式为
host:port如192.168.1.26:8888 - 编码格式:用来设置页面的编码格式默认为UTF-8,当解析出现乱码时,可以修改此值
- 跟随重定向:默认是跟随30x重定向,当不需要此功能时,可以取消勾选
- TLS证书验证:此项默认是勾选的,当出现证书一类的异常可以取消勾选此项尝试
- 自动管理Cookie:请求时自动设置Cookie(自己手动设置的与之前请求的Cookie都会设置进去)
- 自动去重:勾选时会对url进行去重处理,如果重复则跳过。
- 重试次数:当请求发生异常或状态码不为200时会进行重试
- 重试间隔:重试期间的间隔时间(单位为毫秒)
- 参数:用来设置GET、POST等方法的参数设置
- 参数名:参数key值
- 参数值:参数value值
- 参数描述:仅仅用来描述该项参数(相当于备注/注释)无实际意义
- Cookie:用来设置请求Cookie
- Cookie名:Cookie key值
- Cookie值:Cookie value值
- 描述:仅仅用来描述该项Cookie(相当于备注/注释)无实际意义
- Header:用来设置请求头
- Header名:Header key值
- Header值:Header value值
- 描述:仅仅用来描述该项Header(相当于备注/注释)无实际意义
- Body:请求类型(默认是none)
- form-data(Body项设置为form-data)
- 参数名:请求参数名
- 参数值:请求参数值
- 参数类型:text/file
- 文件名:上传二进制数据时需要填的文件名
- raw(Body项设置为raw)
- Content-Type:text/plain,application/json
- 内容:请求体内容(String类型)
TIP
此图形会返回一个HttpResponse对象,以
resp存入变量中
定义变量
该节点用于定义变量之后,可以与表达式配套使用,实现动态设置各项参数(如动态请求分页地址)
- 变量名:变量的名字,当变量名重复时,会覆盖前一个变量
- 变量值:变量的值,可以是常量,可以是表达式
输出节点
该节点主要用于调试,测试时会把输出打印到页面中,另外也可以用来自动保存到数据库或文件
- 输出到数据库:勾选时需要填写数据源、表名称,且
<font color="blue">输出项</font>要与列名对应 - 输出到CSV文件:勾选时需要填写CSV文件路径,
<font color="blue">输出项</font>会作为表头 - 输出全部参数:一般用来调试,可以输出所有变量到界面上
- 输出项:输出项的名字
- 输出值:输出的值,可以是常量,可以是表达式
循环节点
- 次数或集合:当此项有值(值为集合或数字)时,后续节点(包括本节点)会循环执行
- 循环变量:默认为
item,与for(Object item : collections)中的item意义相同 - 循环下标:当循环时,会产生下标(从0开始)以该值存入变量中,与
for(int i =0; i < array.length;i++)中的i意义相同 - 开始位置:从该位置开始循环(从0开始)
- 结束位置:到该位置结束(-1为最后一项,-2为倒数第二项,以此类推)
TIP
使用循环时需注意当有多个循环时会形成嵌套循环,必要时应与
等待结束节点配套使用
执行SQL
主要用于与数据库交互(查询/修改/插入/删除等等)
- 数据源:需要选择配置好的数据源
- 语句类型:select/selectInt/selectOne/insert/insertofPk/update/delete
- SQL: 要执行SQL语句,需要动态注入的参数用
##包裹起来如:#${item[index].id}#
TIP
该节点执行完毕时会产生
rs变量,selectInt/insert/update/delete会返回int类型,select会返回List<Map<String,Object>>,selectOne返回Map<String,Object>,insertofPk返回主键值
内置变量
爬取结果
当爬取节点执行后产生类型为HttpResponse的resp变量
| 字段名称 | 字段类型 | 字段描述 | 用法示例 |
|---|---|---|---|
| html | String | 页面HTML | ${resp.html} |
| json | JSONObject/JSONArray | 内容转json结果 | ${resp.json} |
| bytes | byte[] | 二进制结果 | ${resp.bytes} |
| cookies | Map<String,String> | cookies | ${resp.cookies} |
| headers | Map<String,String> | headers | ${resp.headers} |
| statusCode | int | HTTP状态码 | ${resp.statusCode} |
| url | String | 当前页面的URL | ${resp.url} |
| title | String | 当前页面的标题 | ${resp.title} |
| stream | InputStream | 二进制流(可用于下载) | ${resp.stream} |
异常信息
当节点发生异常时,会产生ex变量,需要注意的是,ex变量不会向下传递
sql执行结果
执行sql后产生变量rs
- 当是select语句时,类型为
List<Map<String,Object>> - 当是selectInt语句时,变量类型为
int - 当是selectOne语句时,变量类型为
Map<String,Object> - 当是insert/update/delete语句时,变量类型为
int - 当是insertofpk语句时,返回的是主键,变量类型为
int
表达式语法
基本用法
本项目中表达式引擎也支持模板的方式,例如动态拼接url
https://www.xxx.com/${path}/q?=keyword=${keyword}
运算符
模板语言支持大多数Java运算符。这些运算符的优先级也与Java中的相同。
类型
byte ${123b}
short ${123s}
int ${123}
long ${123l}
float ${123f}
double ${123d}
string ${'hello'}
string ${"hello"}
同时也支持定义Map和List
${{key : "value"}}
${[1,2,3,4,5]}
${{$key : "value"}}//$key表示动态从变量中获取key值
一元运算符
您可以通过一元运算-符将数字取反,例如${-234}。要取反布尔表达式,可以使用!运算符,例如${!true}。
算术运算符
支持常见的算术运算符,例如${1 + 2 * 3 / 4 % 2}
比较运算符
${23 < 34}`,`${23 <= 34}`,`${23 > 34}`,`${23 >= 34}`,`${ true != false }`,`${23 == 34}
比较运算符结果为boolean类型
逻辑运算符
除了一元运算!符,您还可以使用&&和||。就像Java中一样,运算符也是一种短路运算符。如果&&左边计算为false,则不会计算右边。如果||左侧为true,则不会计算右边
三元运算符
三元运算符是if语句的简写形式,其工作方式类似于Java中,例如${true ? "yes" : "no"}
变量
${var}
通过${变量名}调用
调用方法
${extract.xpath(resp.html,'//div[@id=abc]').regx('/\\d/').toInt()}
通过${变量.方法名(参数1,参数2,....)}进行调用
数组和Map
${myArray[2]} ${myArray[indexVar]} ${myMap.get("key")} ${myMap["key"]} ${myMap.get(keyVar)} ${myMap[keyVar]}
链式调用
与Java中一样,您可以无限嵌套成员,数组元素和映射访问
${myObject.aField[12]["key"].someMethod(1, 2).anotherMethod()}
${extract.xpath(resp.html,'//div[@id=abc]').regx('/\\d/').toInt()}
抽取函数
selector
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| html | html内容如resp.html | 否 |
| css | css选择器 | 否 |
| 类型 | text/attr/outerhtml | 是 |
| 属性名 | 当类型为attr时,填写此项 | 是 |
TIP
返回值类型:String
采用css选择器方法抽取一条数据
-
获取第一个a标签的html
${extract.selector(resp.html,'a')} -
获取第一个a标签的text(文本)
${extract.selector(resp.html,'a','text')} -
获取第一个a标签的outerhtml
${extract.selector(resp.html,'a','outerhtml')} -
获取第一个a标签的href属性
${extract.selector(resp.html,'a','attr','href')}
selectors
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| html | html内容如resp.html | 否 |
| css | css选择器 | 否 |
| 类型 | text/attr/outerhtml | 是 |
| 属性名 | 当类型为attr时,填写此项 | 是 |
TIP
返回值类型:List
采用css选择器方法抽取一组数据
-
获取所有a标签的html
${extract.selectors(resp.html,'a')} -
获取所有a标签的text(文本)
${extract.selectors(resp.html,'a','text')} -
获取所有a标签的outerhtml
${extract.selectors(resp.html,'a','outerhtml')} -
获取所有a标签的href属性
${extract.selectors(resp.html,'a','attr','href')}
xpath
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| html | html内容如resp.html | 否 |
| xpath | xpath表达式 | 否 |
TIP
返回值类型:String
采用xpath方法抽取一条数据
-
获取第一个a标签的html
${extract.xpath(resp.html,'//a')} -
获取第一个a标签的href属性
${extract.xpath(resp.html,'//a/@href')}
xpaths
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| html | html内容如resp.html | 否 |
| xpath | xpath表达式 | 否 |
TIP
返回值类型:List
采用xpath方法抽取一组数据
-
获取所有a标签
${extract.xpaths(resp.html,'//a')} -
获取所有a标签的href属性
${extract.xpaths(resp.html,'//a/@href')}
regx
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| string | 字符串,如resp.html | 否 |
| regx | 正则表达式 | 否 |
| groups | 捕获组序号int或List(多个) | 是 |
TIP
返回值类型:String/List
采用正则方法抽取一条数据
-
获取网页title
${extract.regx(resp.html,'<title>(.*?)</title>')}
regxs
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| string | 字符串,如resp.html | 否 |
| regx | 正则表达式 | 否 |
| groups | 捕获组序号int或List(多个) | 是 |
TIP
返回值类型:List/List<List
采用正则方法抽取一组数据
-
获取所有h2标签内容
${extract.regxs(resp.html,'<h2>(.*?)</h2>')}
jsonpath
| 参数名 | 描述 | 可否为空 |
|---|---|---|
| object | json对象 | 否 |
| jsonpath | jsonpath表达式 | 否 |
TIP
返回值类型:Object
根据jsonpath抽取数据
-
获取json根节点下的code属性
${extract.jsonpath(resp.json,'$.code')}
四、实战新闻爬取
背景
小程序中使用到了延安大学官网-延大要闻(地址: 延大要闻-延安大学 (yau.edu.cn) )模块的新闻数据及详情数据,借此机会试了下spiderflow的实现过程,特此记录,以备参考。
需要注意的地方:
- 延大官网的延大要闻的网络请求到的htm和实际页面元素看到的页面不一样,它在htm数据获取后通过js对页面做了一定的处理,这个我们也要做特殊处理(数据是重复的,也可以在入库的时候处理)。
- 延大官网第一页和后续页的页面布局和取数据逻辑是有去别的,我们也要区别对待下。
其他说明:
- 本文介绍的是spiderflow实现新闻爬取的过程并不代表spiderflow是最简单或者最简洁的实现方式,并不否认其他更好的实现方式的优点。
- 文中提到的取数据的逻辑只是一种思路和参考,并不一定是最优的方式,如果大家有更好的方式,欢迎留言评论~
思路分析
浏览器里输入延大要闻首页可以看到如下页面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zTQYB5yZ-1678113371762)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230305203057901.png)]
点击某一条进入详情,看到如下页面:

我们需要爬取的数据就是图中红框框起来的这部分,可以看到总共有742页,共11127条,我们权且爬取200页,每页15条。
按照正常思维分析,我们需要做的有如下几步:
- 取指定页(第一次是首页)的数据,并循环解析出标题、时间、详情地址
- 根据1获取到的详情地址循环爬取详细内容
- 获取下一页的链接,并重新执行步骤1、2、3
实现过程
1. 取首页和第二页的数据,并解析出所有的标题、时间、详情地址
浏览器打开首页,按F12,可以看到请求的htm的返回结果,如下:

可以看到首页的数据还是相对来说比较容易取到的,首先取到class=''的table,然后取下面height=‘20’的所有tr,解析其中的td对应的属性即可,我们在页面上画流程图实现下这个过程。
打开spiderflow管理页面(如果本地部署的话一般就是localhost:8088), 在爬虫列表页面点击添加爬虫
在爬虫编辑页面,我们拖入一个爬虫组件和一个输出组件方便调试,并做如下配置:
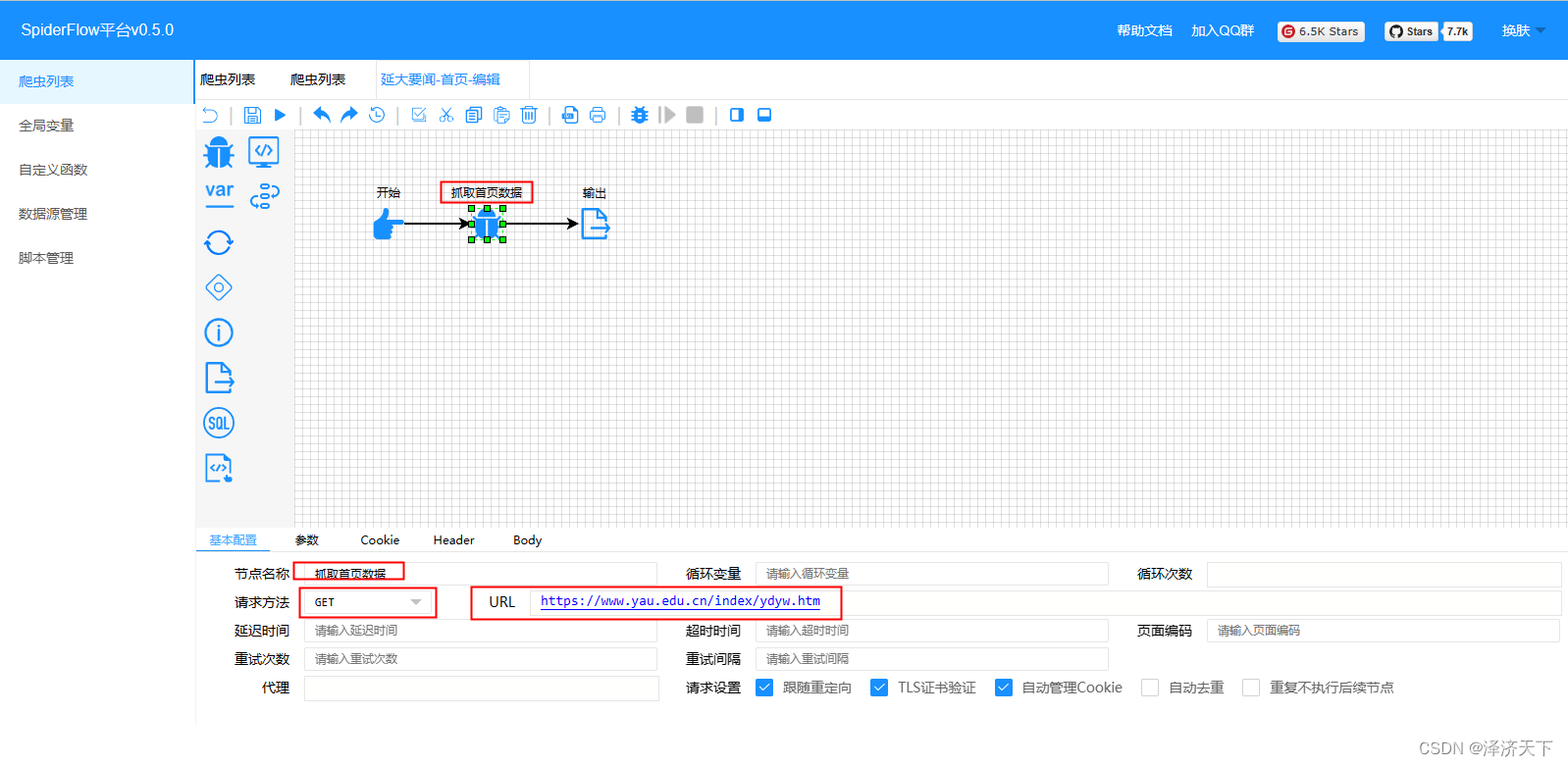
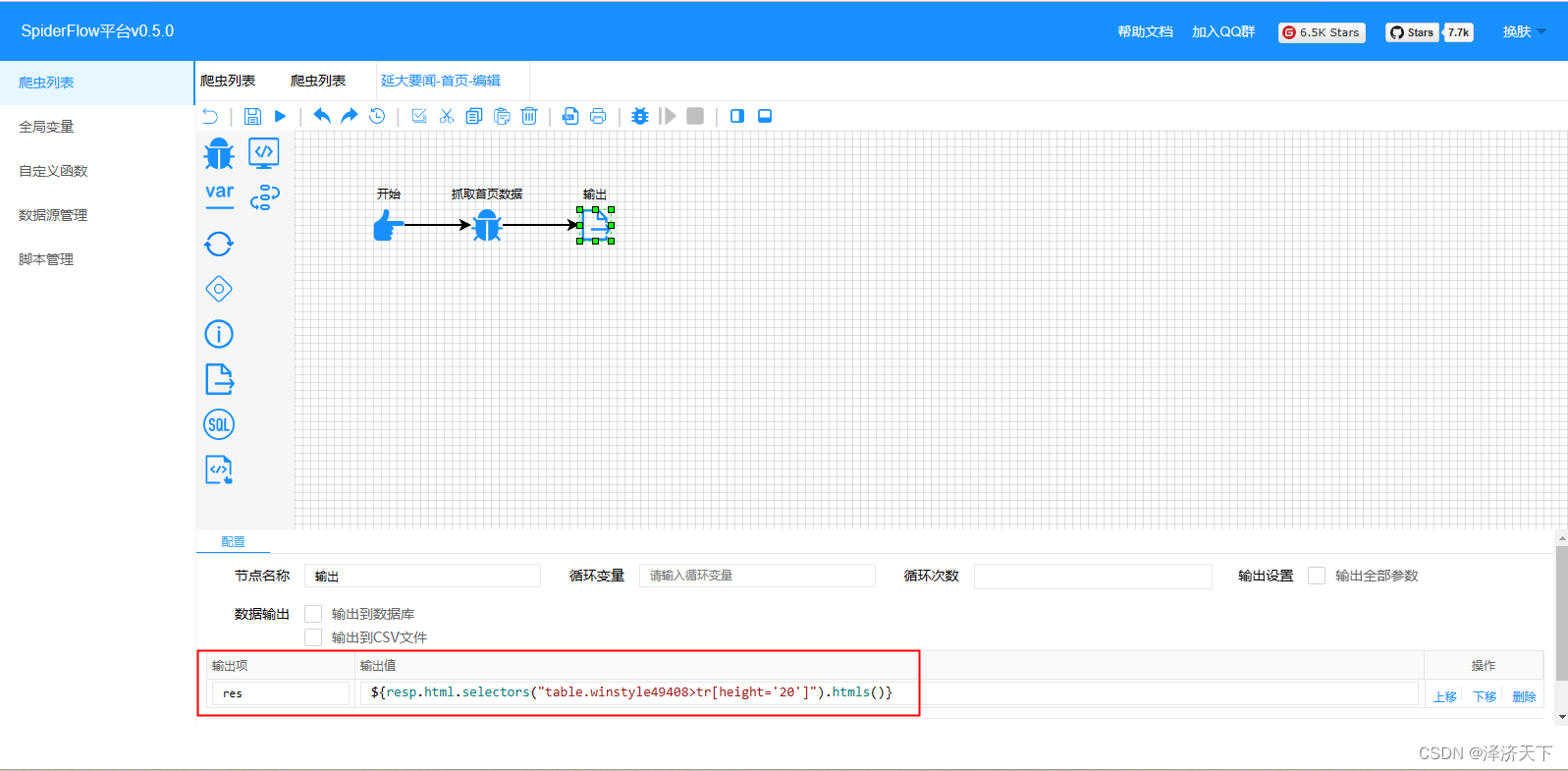
爬虫组件比较重要的配置就是请求方式和URL以及参数,输出组件的res变量表达式含义就是取到class=''的table,然后取下面height=‘20’的所有tr的所有子节点,点击操作栏的运行按钮,可以看到输出如下图:
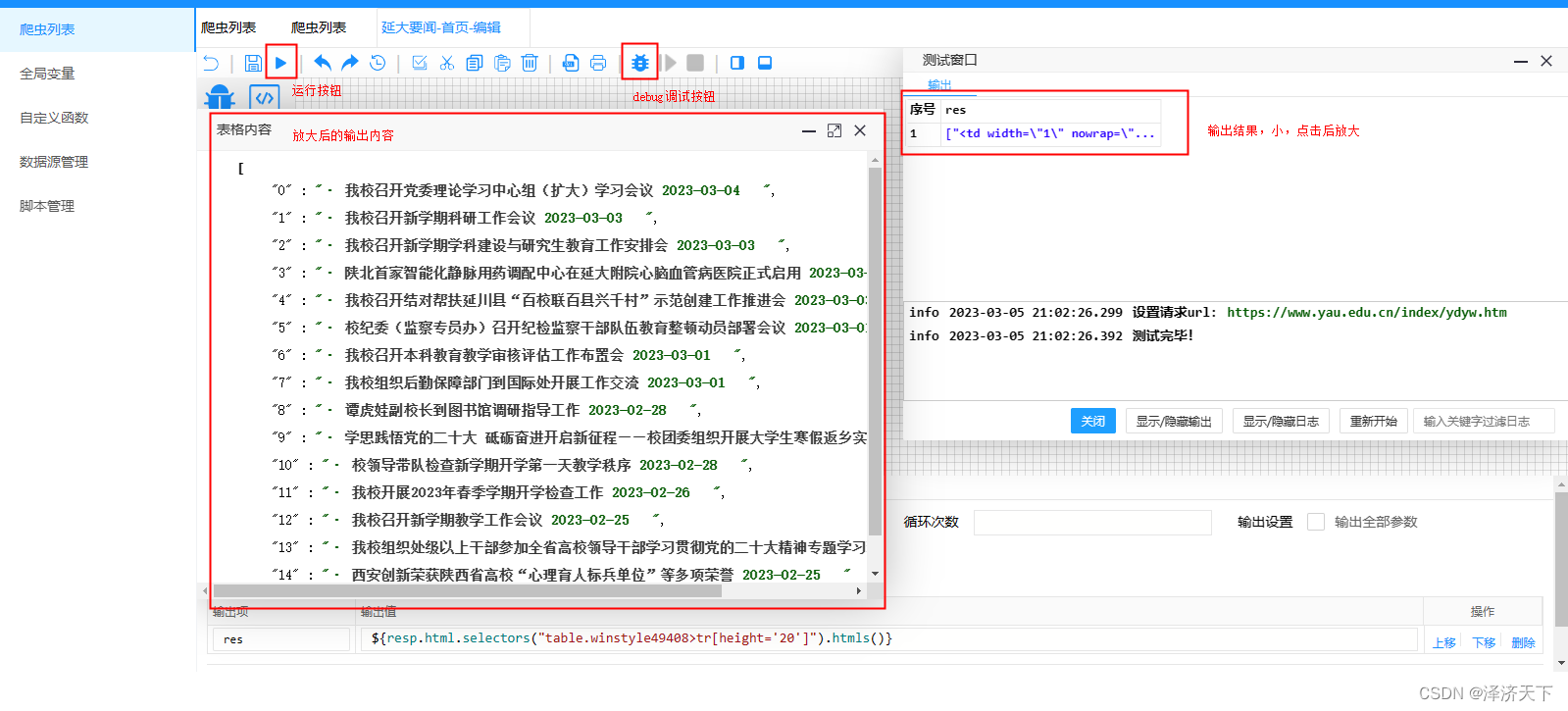
可以看到,输出结果是个数组,也确实是我们需要的数据,但是打印出来的缺少了详情页面的跳转链接,我们做个变量通过循环的方式打印一下完整的数据。
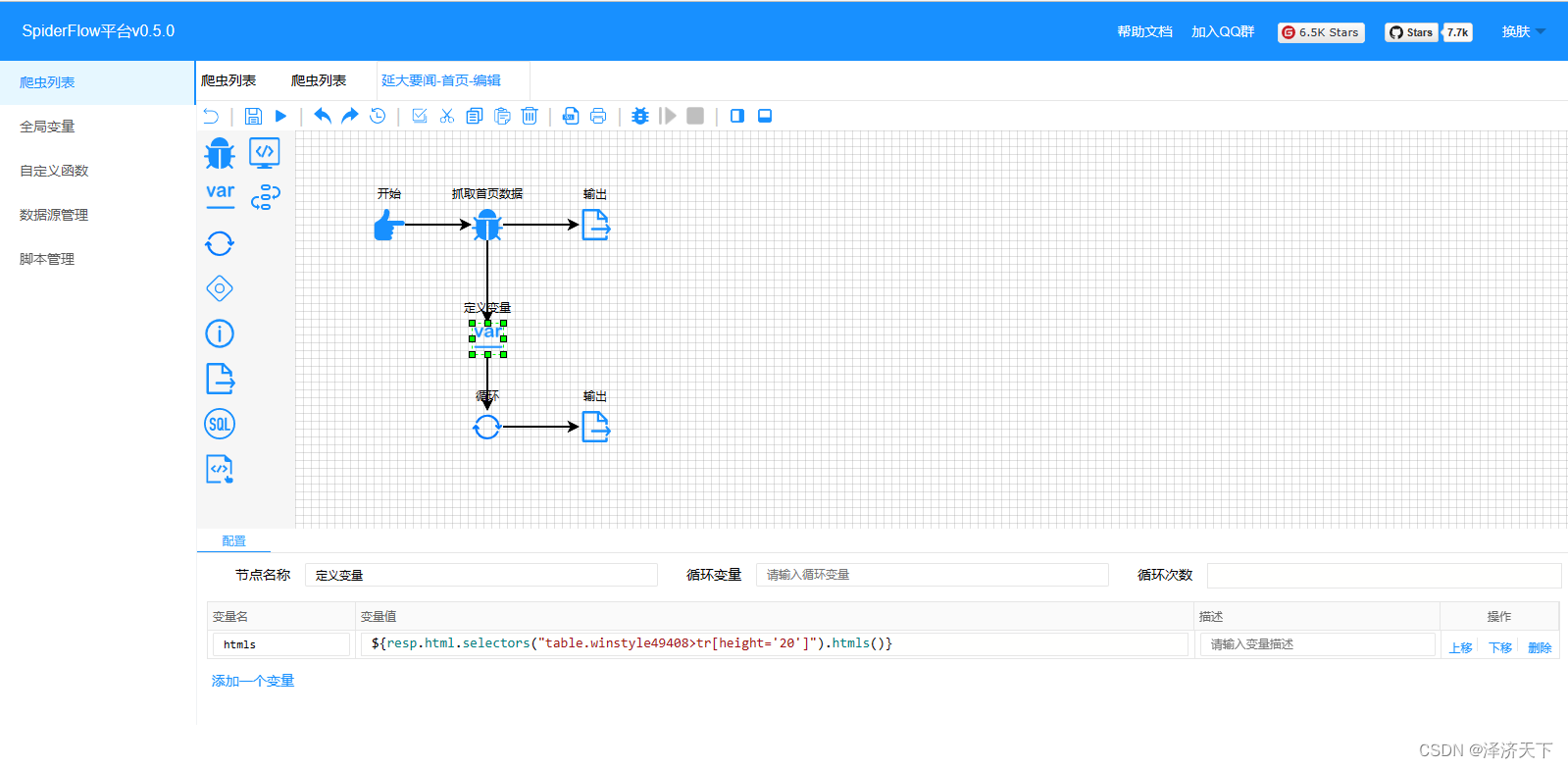
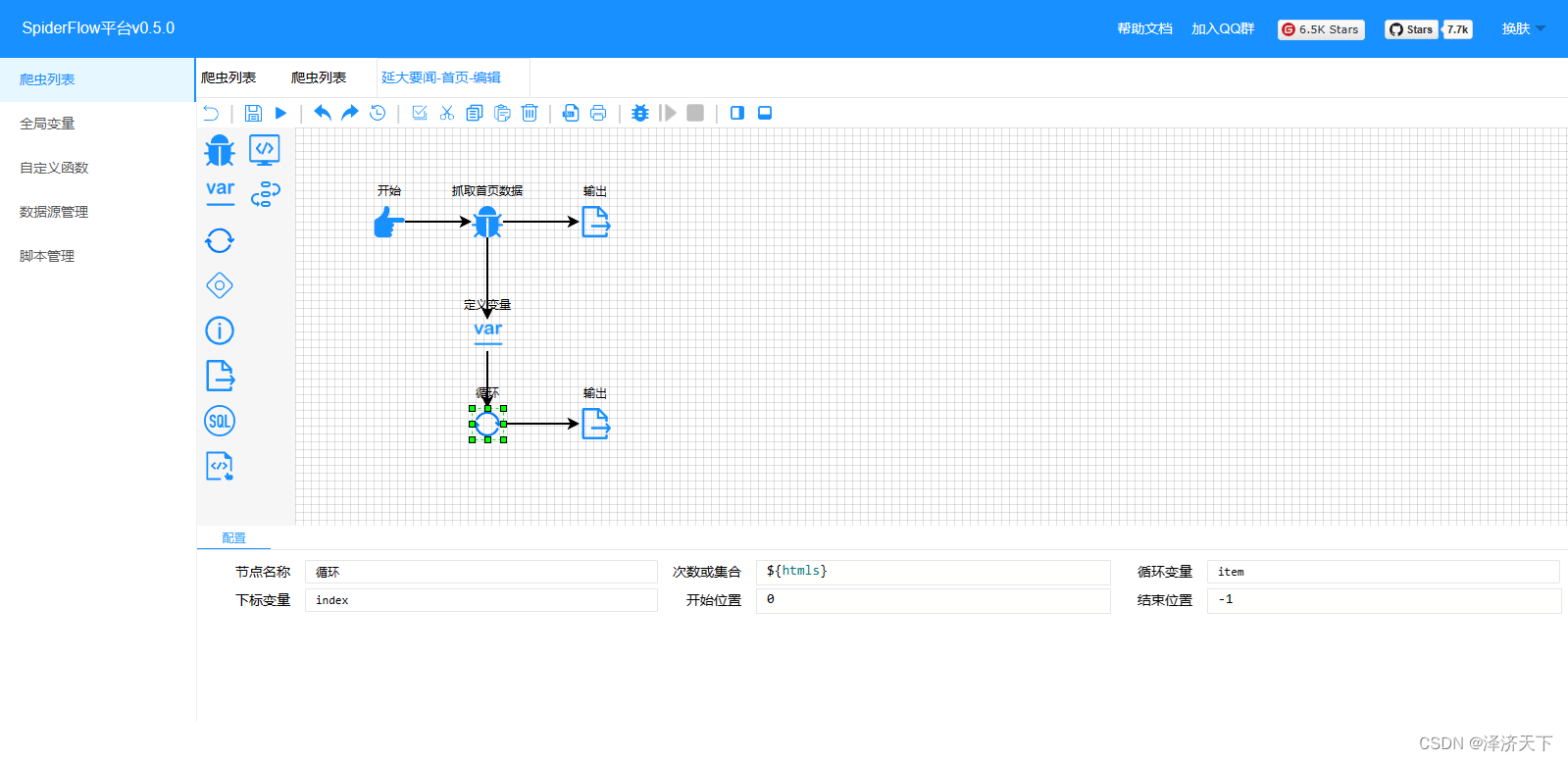
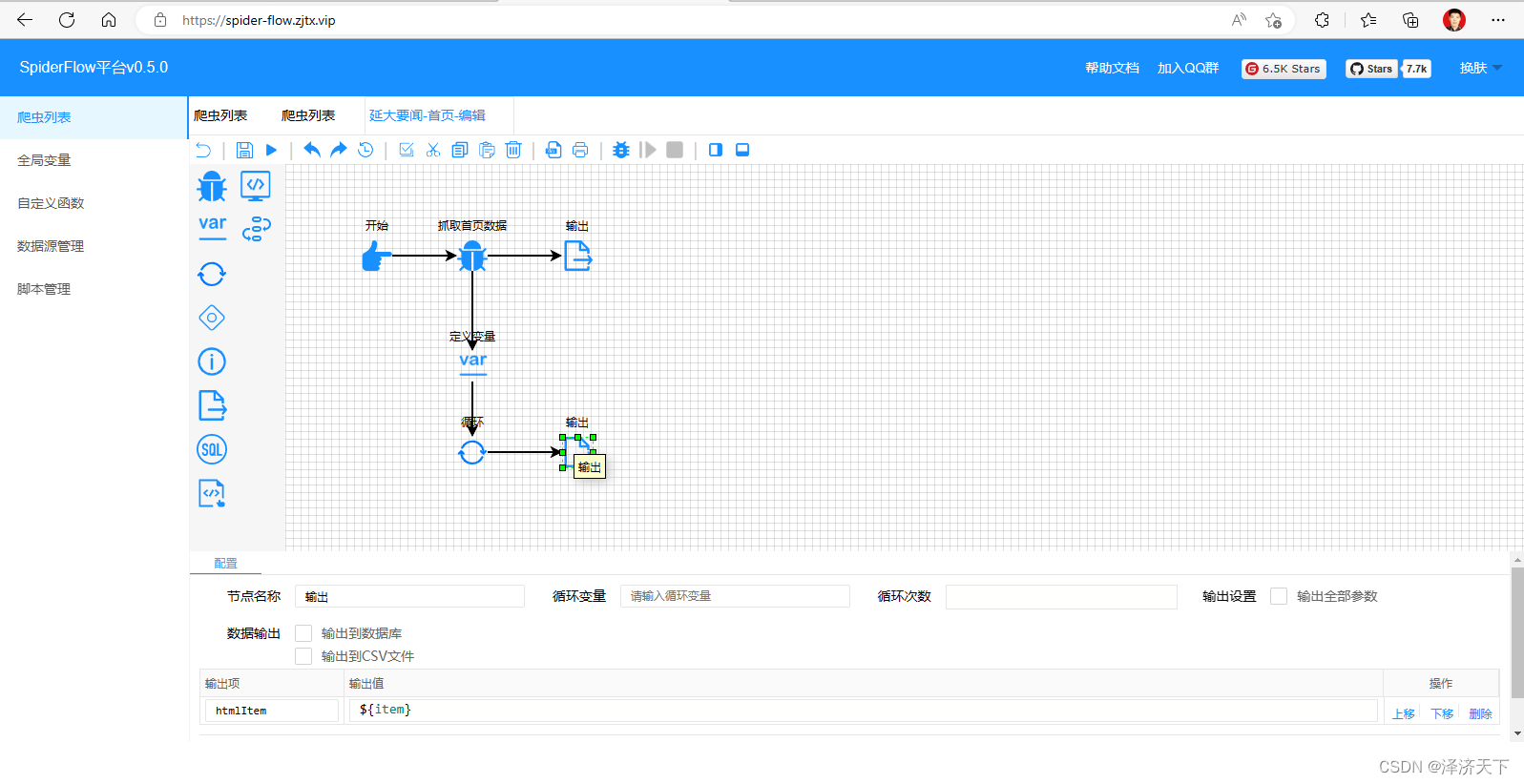
继续点击运行,可以看到如下结果:
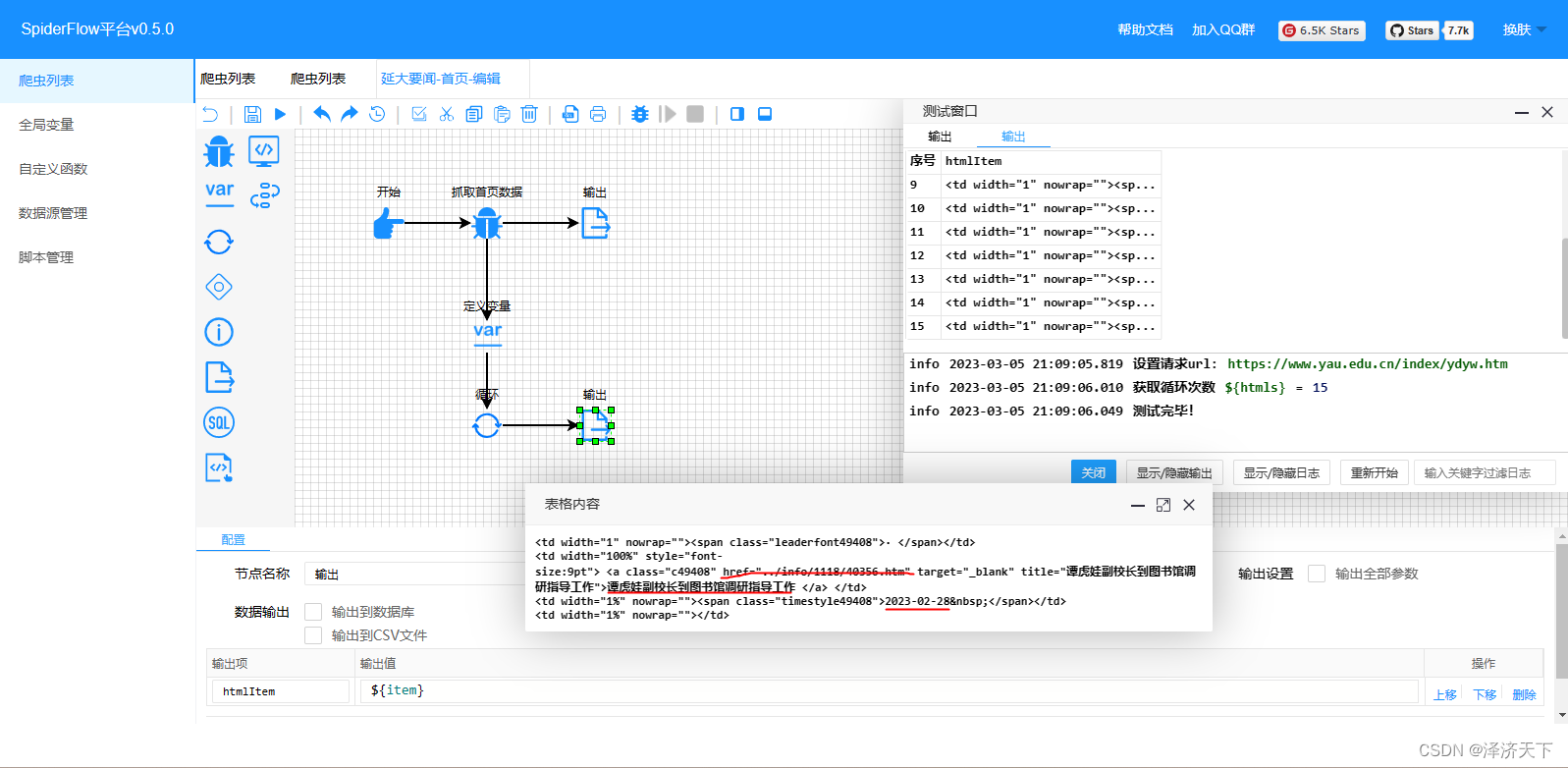
OK,在输出结果我们看到了详情地址,但是个相对地址我们需要做个处理,拼接上域名前缀。定义变量并修改配置如下:
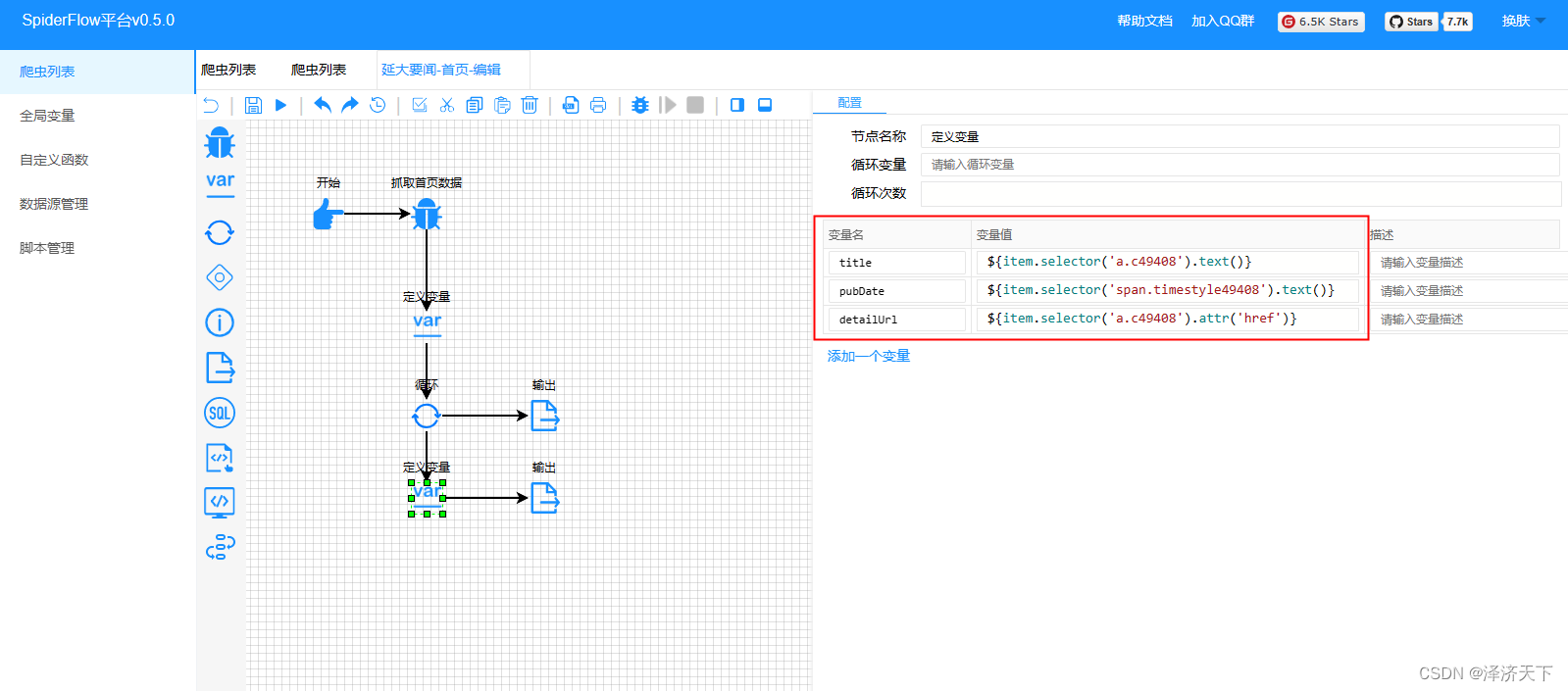
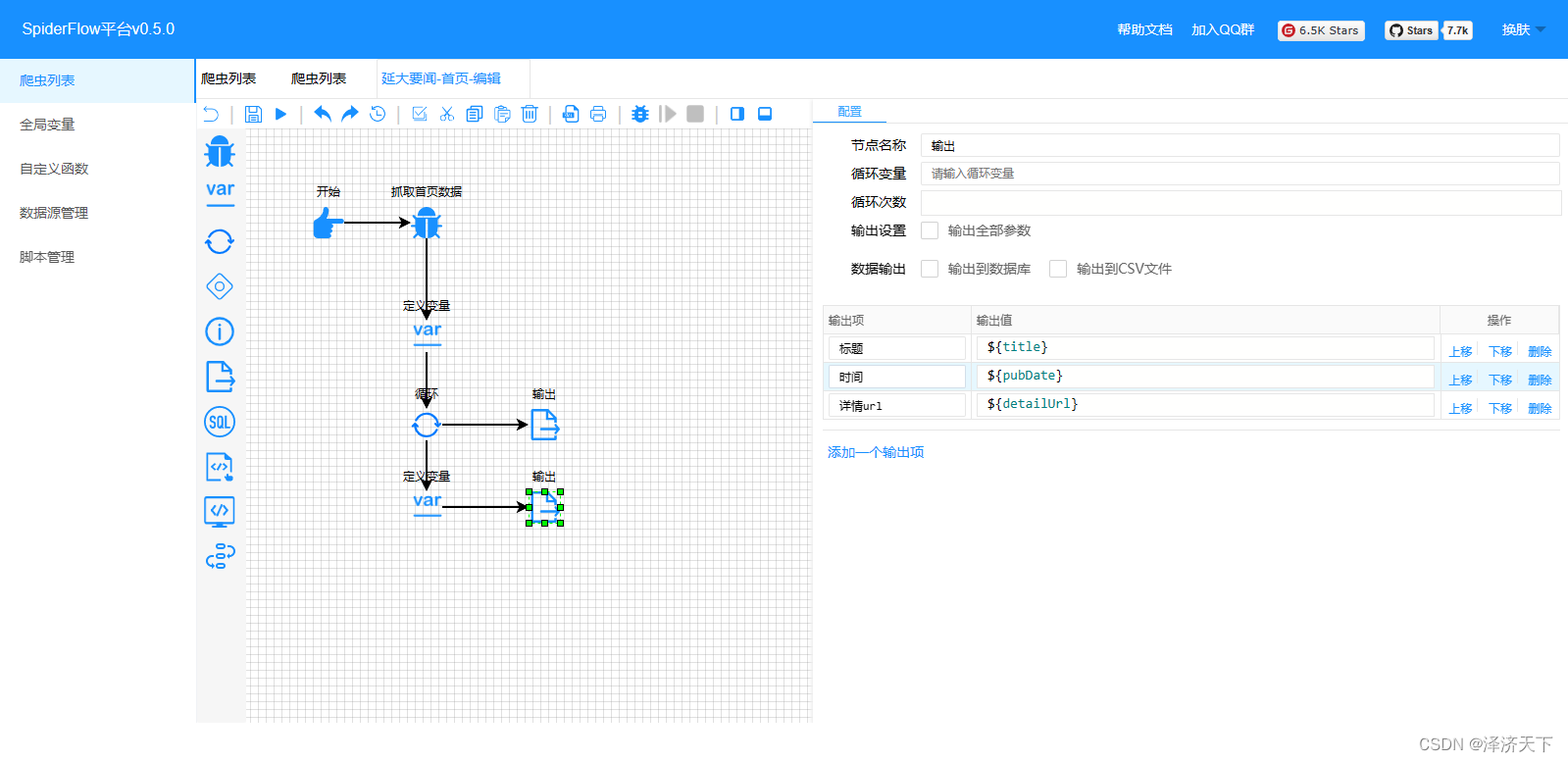
变量中我们分别定义了标题、时间、详情的取数据逻辑,相对来说比较简单,就是通过selector选择器配置attr或者text()方法,相信都是可以理解的。再次运行看到如下结果:
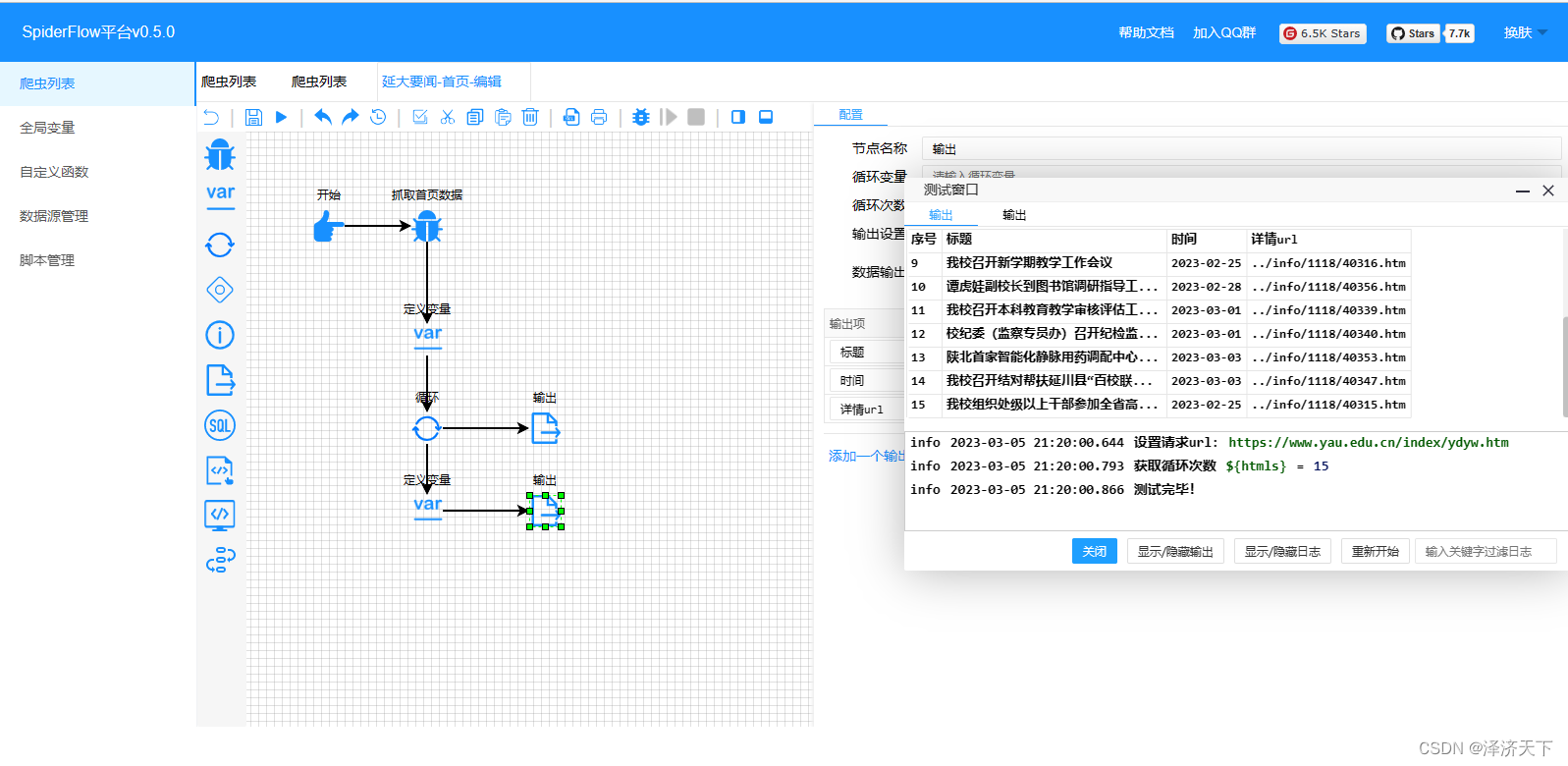
修改detailUrl变量的取数据逻辑,如下:
${'https://www.yau.edu.cn/'+item.selector('a.c49408').attr('href').replace('../', '')}
得到最终的结果:

到此,我们就取到了首页列表里面每条数据的详情页面地址。
2. 根据详情地址获取详细内容
接上一步,我们获取到了detailUrl这个地址用于获取新闻详情。
在编辑器中继续添加爬虫链接,地址是${detailUrl},如下图:
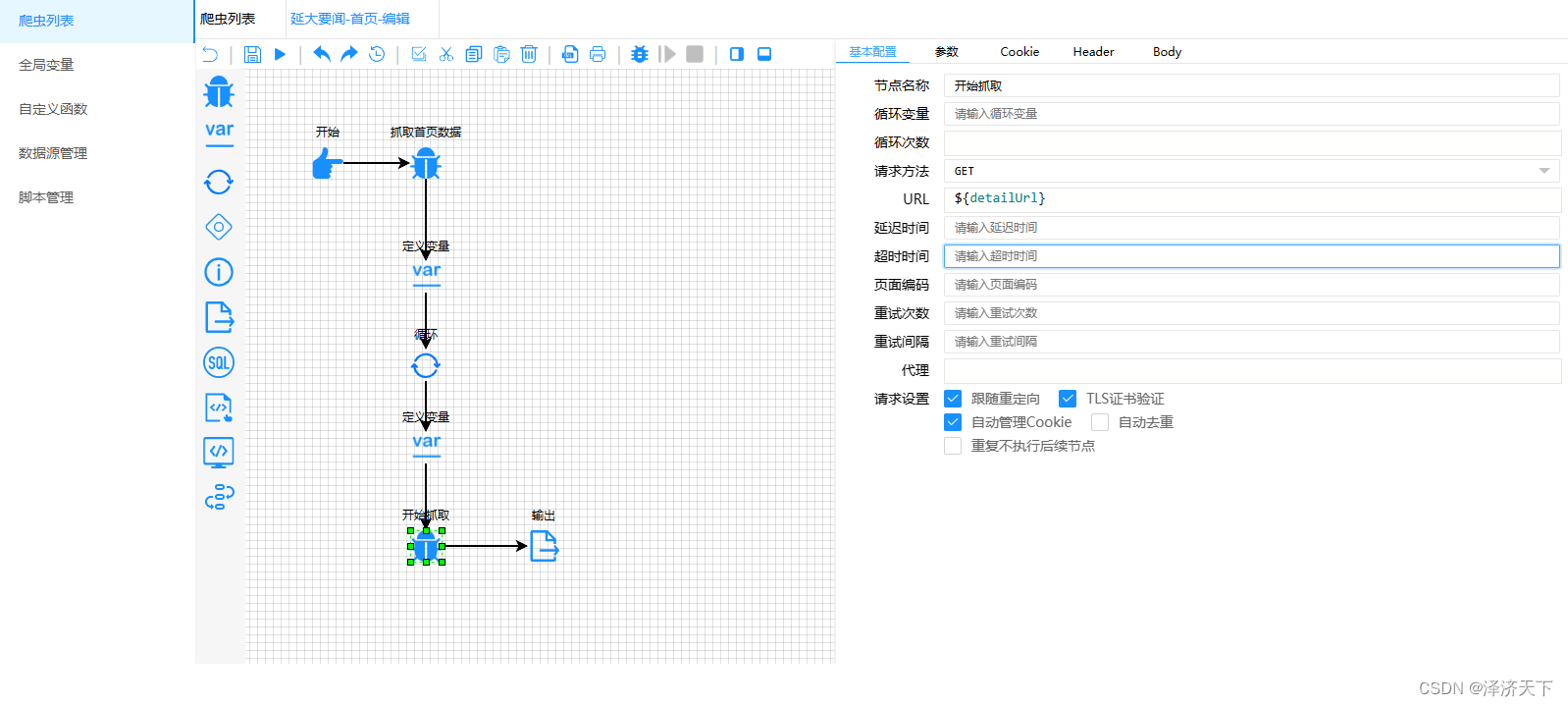
点击操作栏的运行,得到如下图的结果,可以看到数据都是正确的。
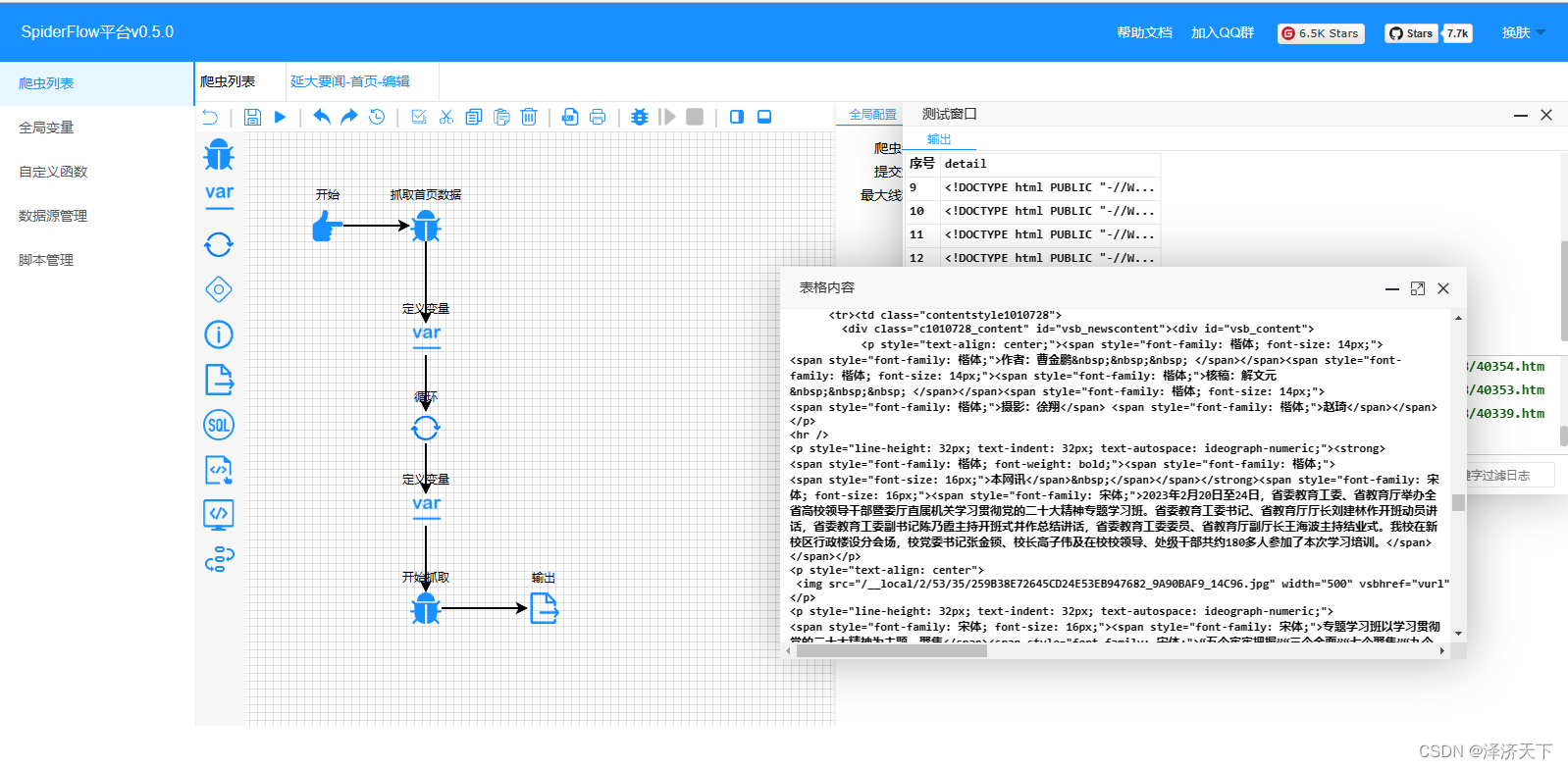
我们看下详情页面的htm结构,找到我们需要解析的数据

编写取数据逻辑,如下图:
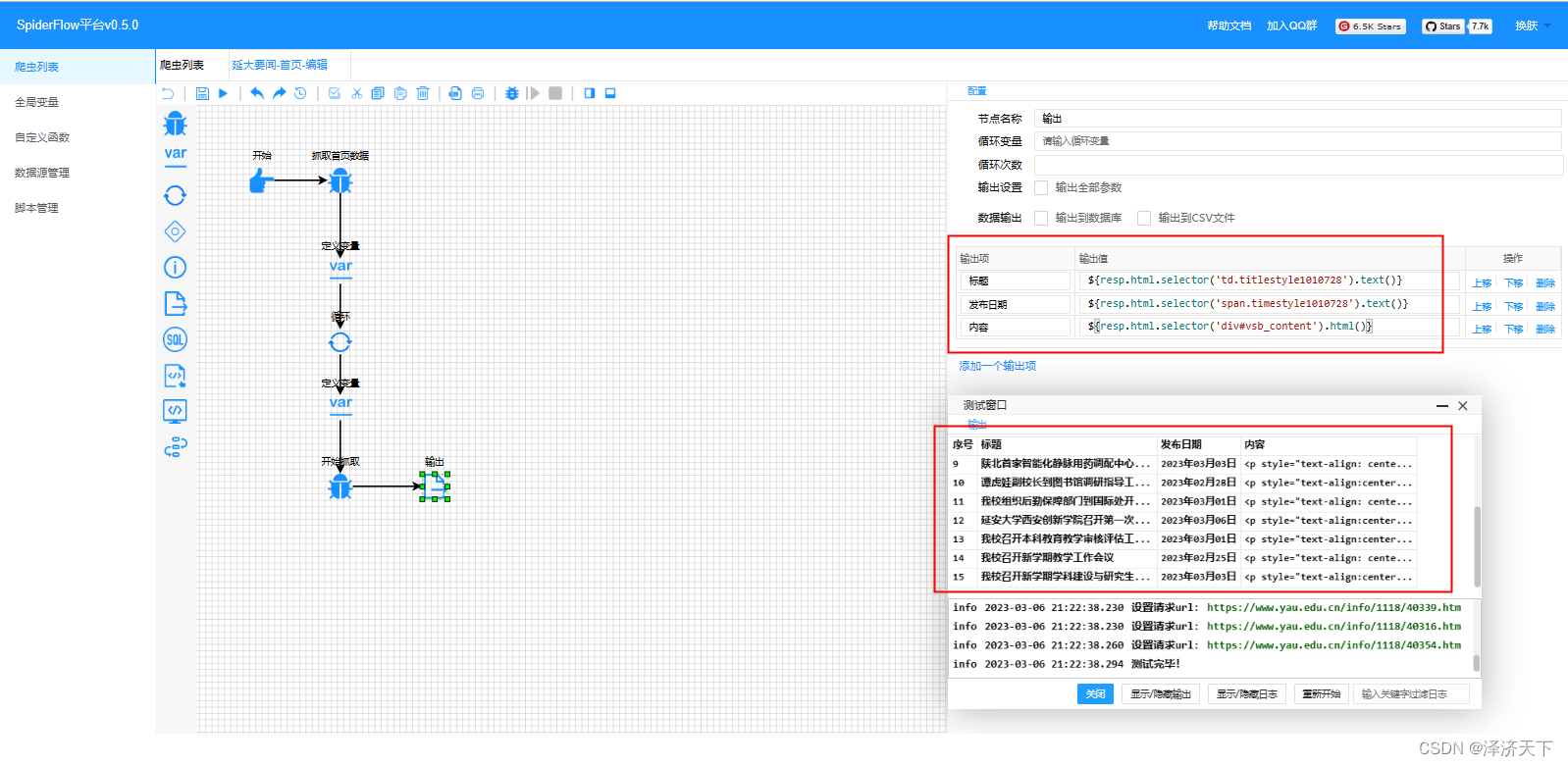
可以看到运行后结果征程输出,我们定义三个变量,和输出组件使用一样的取数据逻辑,方便后续使用。
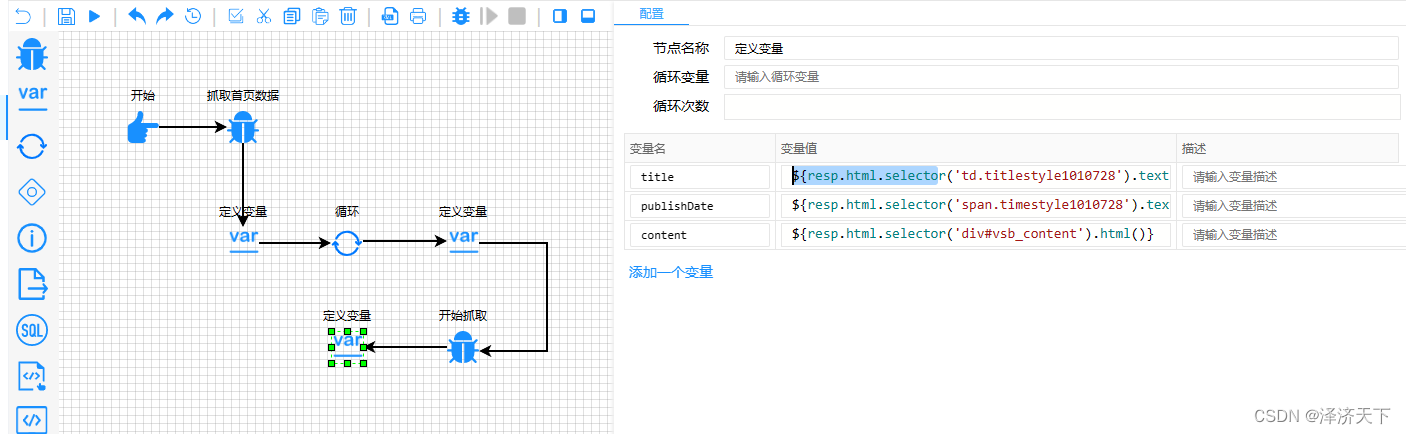
到此详情页面的数据获取就完成了。
3. 数据入库
接下来我们把取到的数据保存到数据库。
我们先连接上目标数据库,执行下面的建表语句。
create table `news`(id int(11) not null primary key, title varchar(200) not null default '', content text not null default '', pub_date varchar(20) not null default '');
在爬虫控制台页面点击数据源管理,添加对应的数据源信息并测试链接通过。
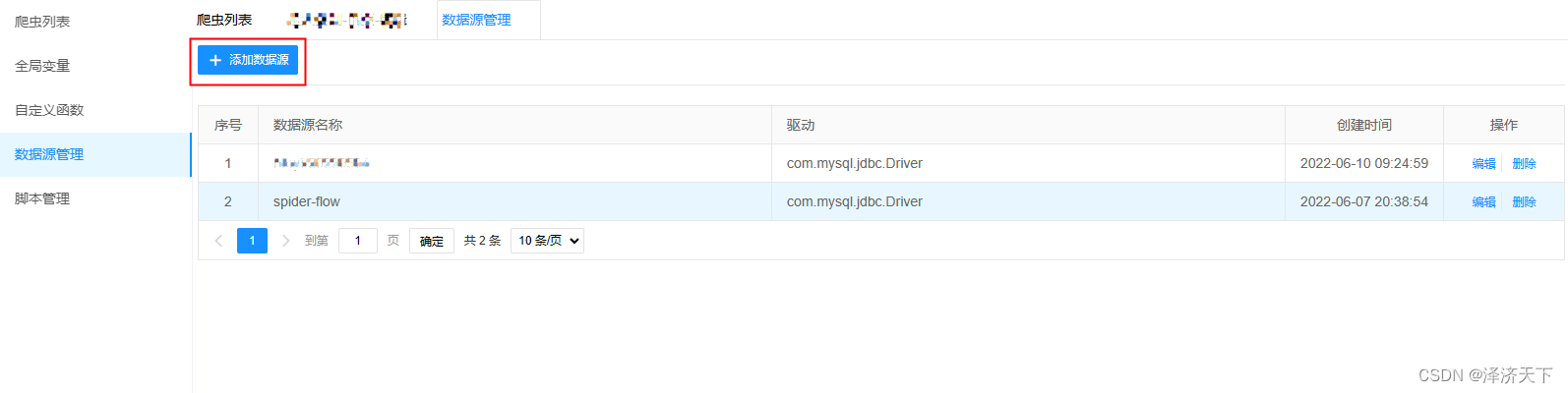
信息输入页面上填入完整信息后,点击测试连接,测试通过后点击保存即可。
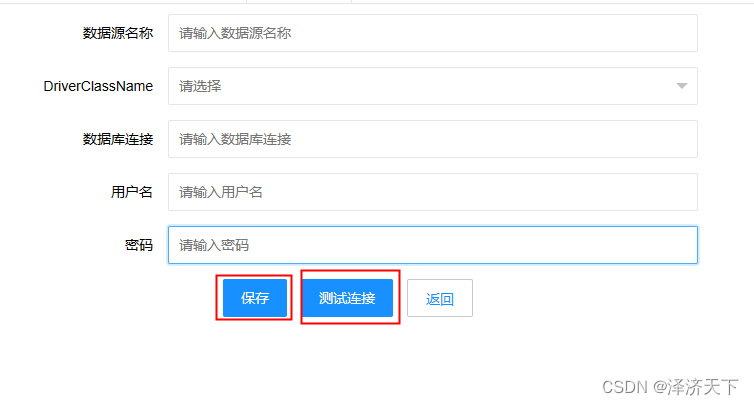
回到爬虫编辑器页面,我们拖入一个SQL组件,配置中选择刚新建的数据源,类型选择insert,sql填入如下内容:
insert ignore into news(id, title, content, pub_date)
values(#${id}#, #${title}#, #${content}#, #${publishDate}#)
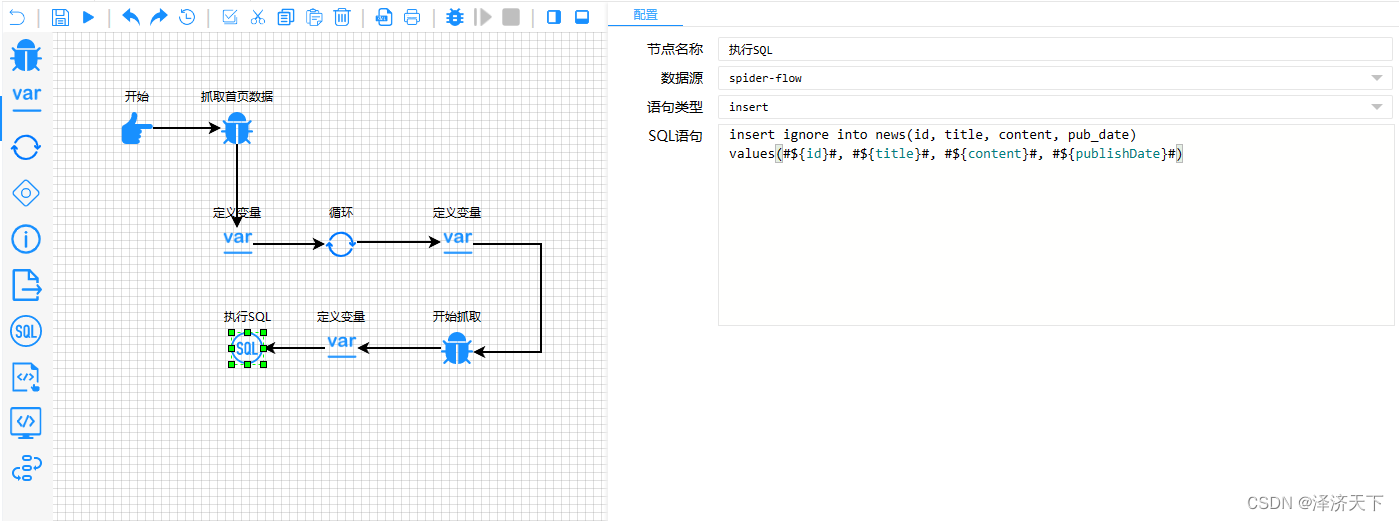
再次点击操作栏的运行按钮,不报错的话就可以去数据库看结果了。
3. 获取下一页的链接
上面我们爬取了首页的数据列表及详情信息,接下来要做的就是取到下一页数据的链接然后循环执行上面的流程。
继续回到首页列表页面的htm文件中,可以看到我们需要的下一页的数据链接:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GxCJvNAd-1678113371778)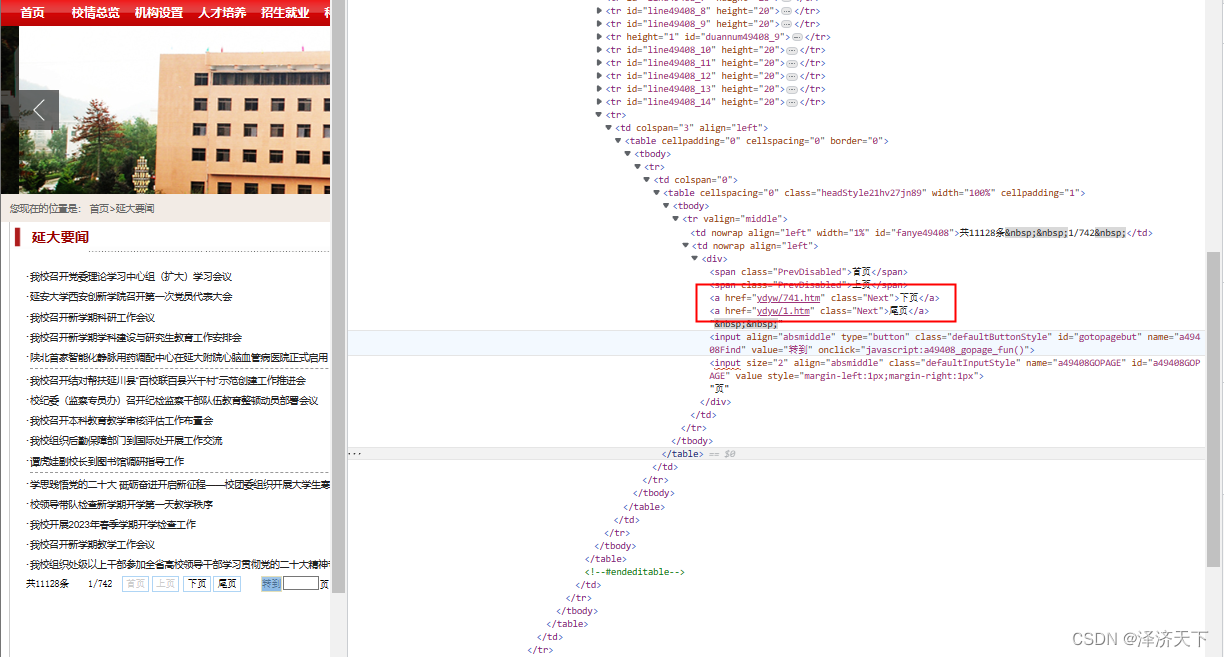
我们再看下第二页的下页链接,看看一样不,
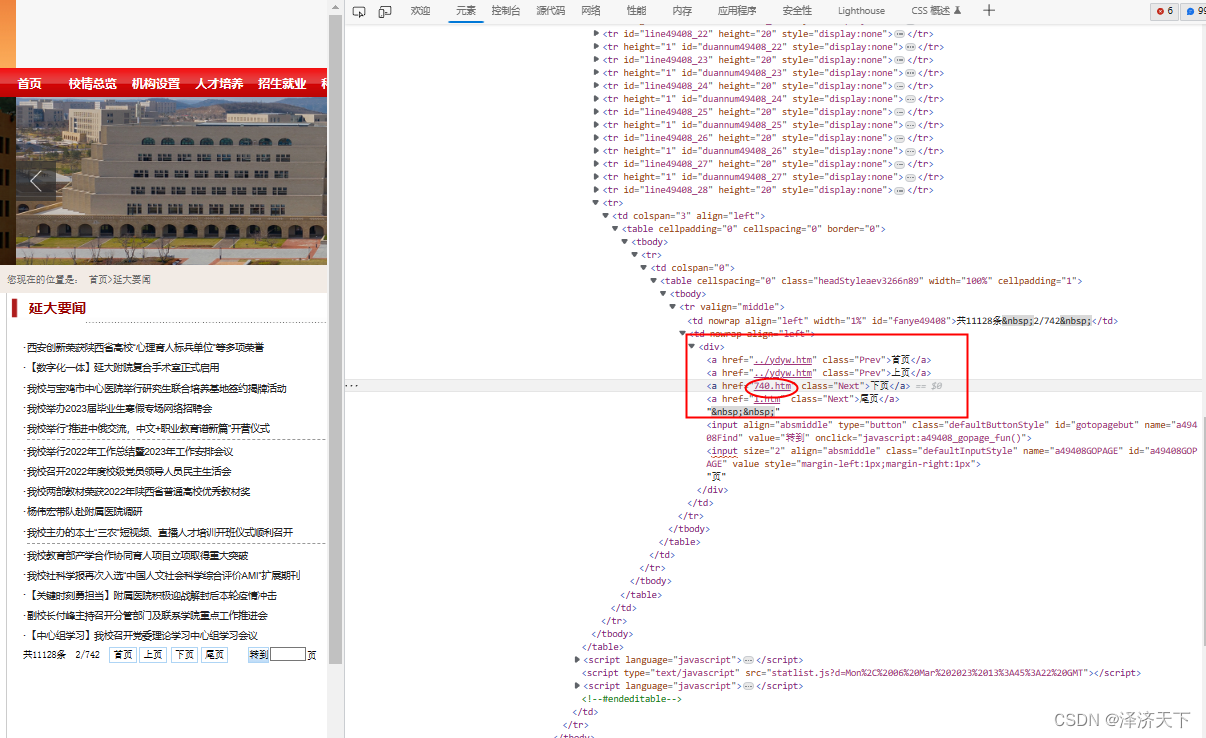
巧了,还真是不一样,看来得做个处理了。
页面上定义下一页url的变量,如下图:
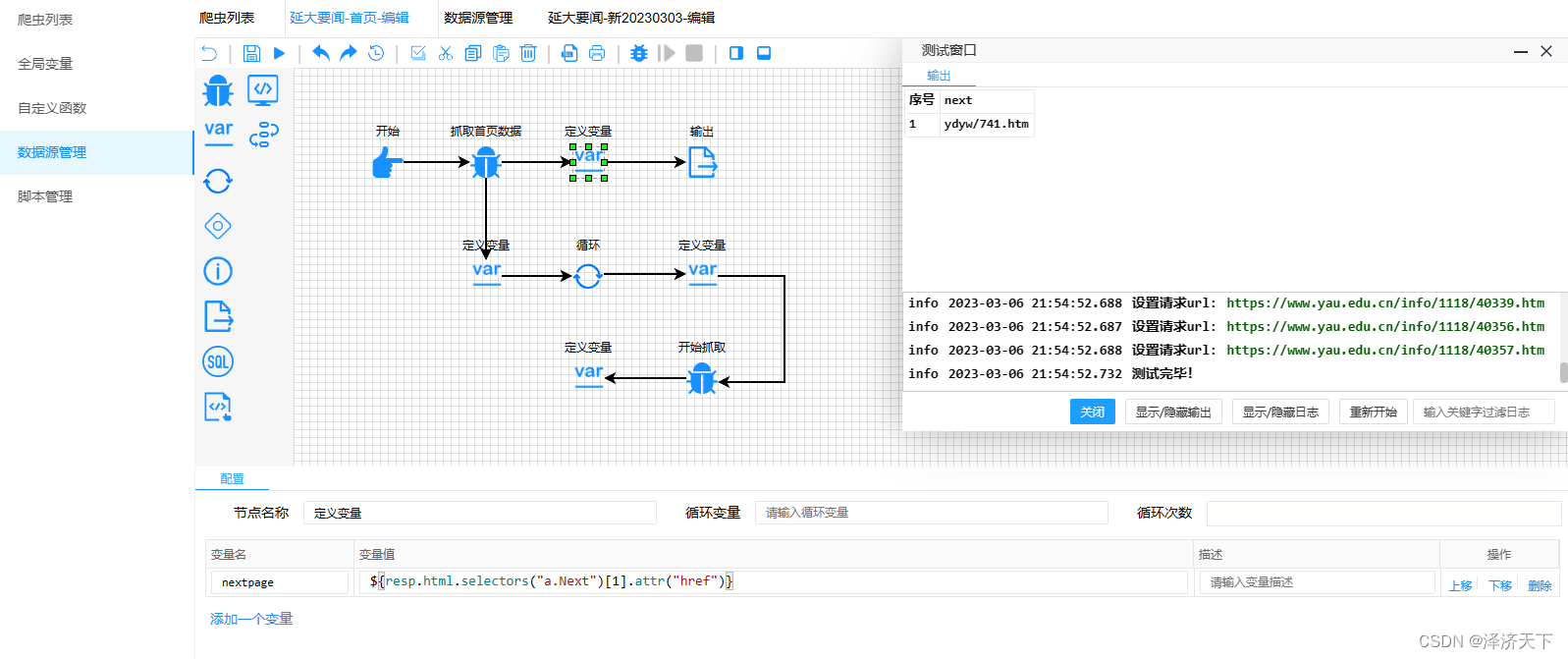
这里输出的是个相对路径,我们修改下变量,拼接上前缀即可。
修改后的nextpage变量:
${'https://www.yau.edu.cn/index/ydyw/'+resp.html.selectors("a.Next")[1].attr("href").replace('ydyw/', '')}
有了下一页的链接,我们让变量定义完成后返回到抓取首页数据的流程中,同时修改首页爬虫组件的url逻辑,如下图:
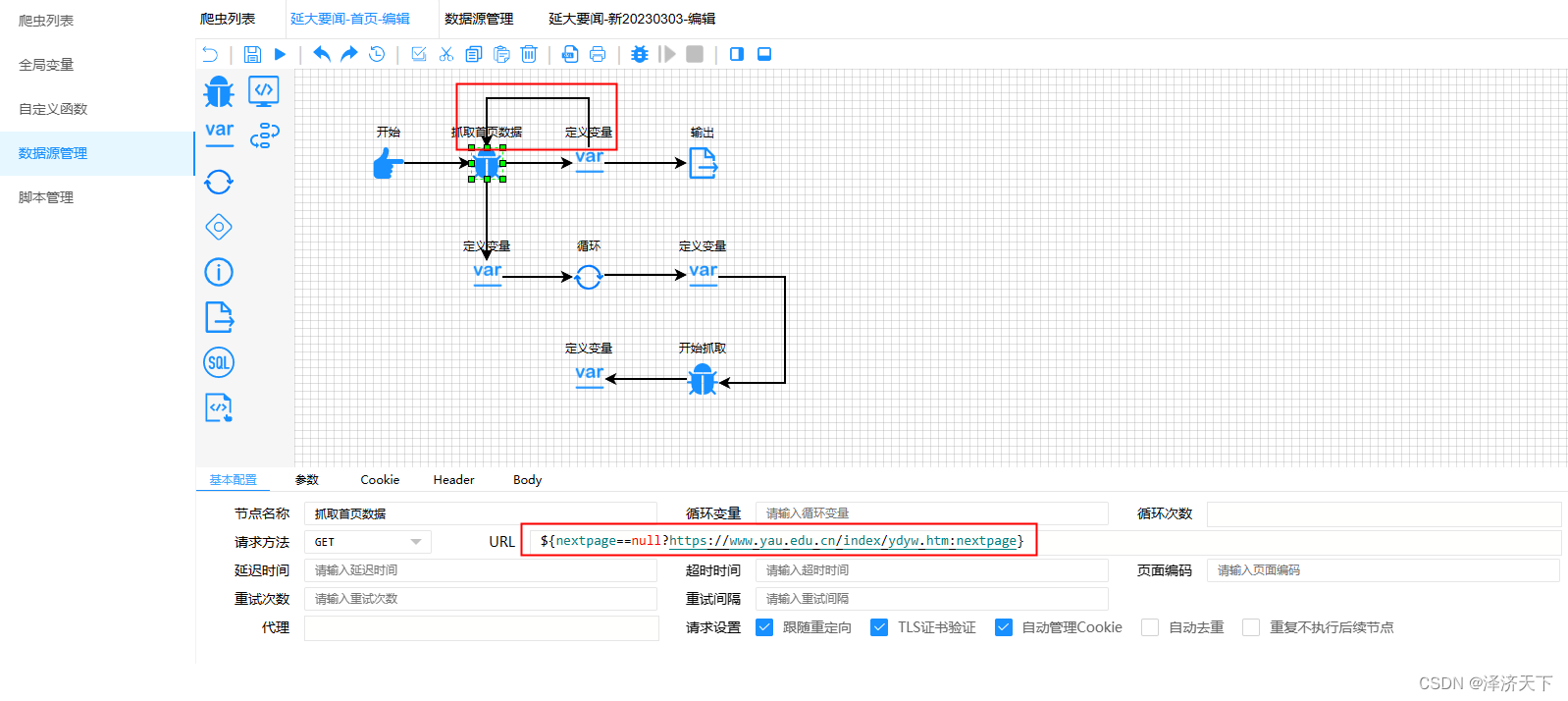
使用了三目运算符,表达的是如果nextpage不为空,则取nextpage否则取首页的url的数据。
至此我们的整个流程就串起来了。
- 取指定页(第一次是默认的首页)数据,解析入库
- 根据首页列表页面的htm解析出下一页的地址,将该地址作为请求地址继续循环上一步。
4. 问题及处理方式
-
前面提到每页的列表里可能和之前的列表数据有重复,需要一个标识来去重,上面的sql使用到的id即唯一标识,文中尚未提到该字段的逻辑。
解决方式: 通过详情url取到唯一标识
我们可以看到详情页面的url是包含一个唯一标识的,例如: /ydyw/21043.htm
通过计算取到21043这个值保存为id即可,取数方式有多重,如正则或者字符串截取。
字符串截取的表达式如下:
${item.selector("td>a").attr("href").toString().split('.htm')[0].split('/')}
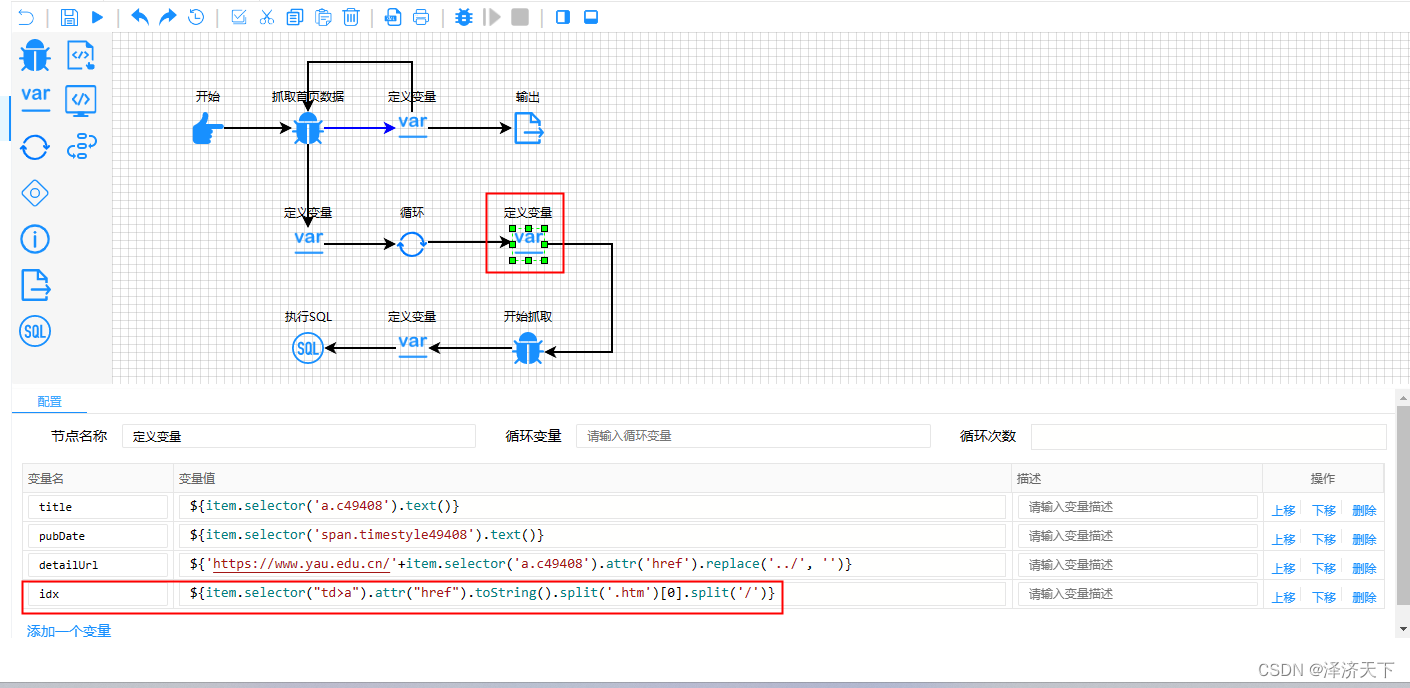
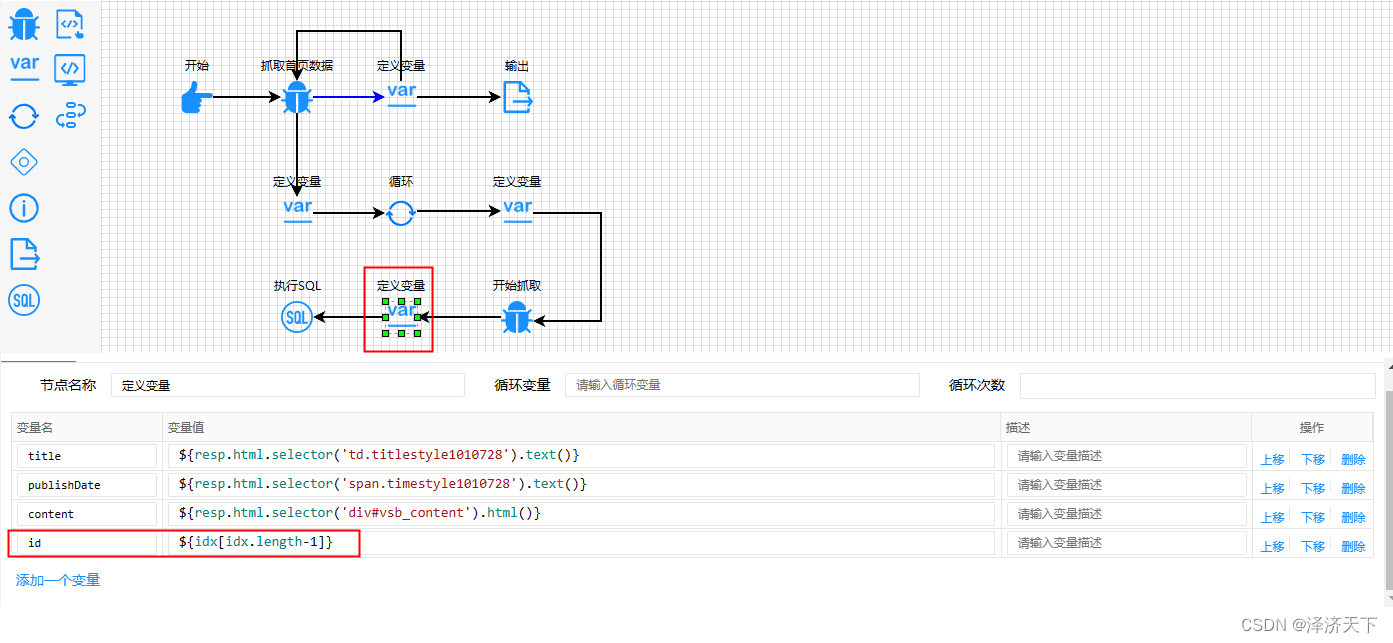
-
取到的content字段里面包含图片地址的src属性是相对路径并没有做替换处理,这样得到的结果里图片是不能正常展示的。
解决方式: 使用字符串的replaceAll全部替换即可。
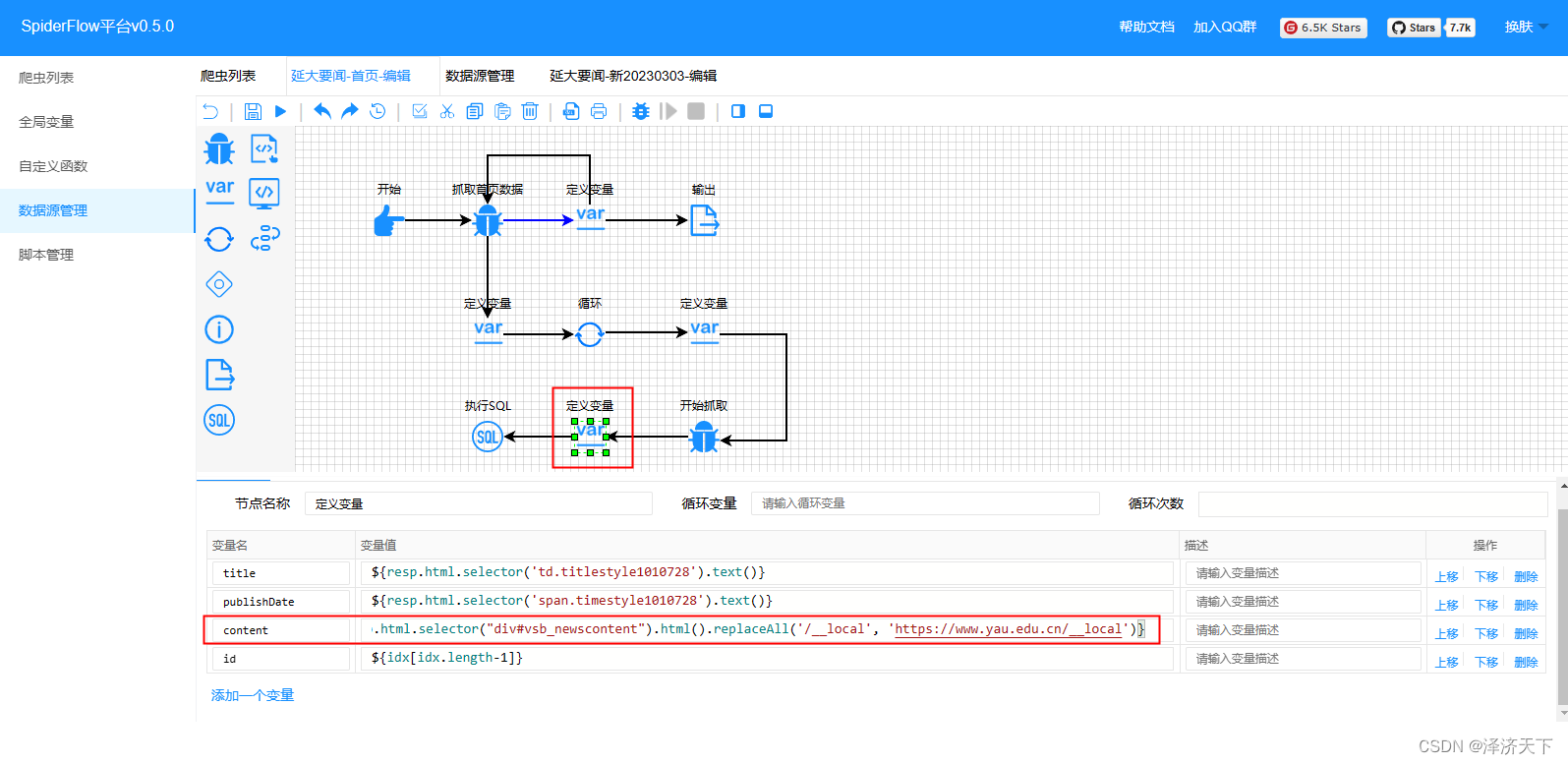
-
我们取下一页数据的时候使用到了resp.html.selectors(“a.Next”)[1]这段代码,那么就要求htm里面class=Next的a标签个数大于1,否则会报越界异常。
解决方式: 添加流转条件

-
如果我们想控制爬取多少页或者爬取多少条数据该如何处理呢?
解决方式: 通过定义变量并递增的方式记录当前爬取了多少页,在流转条件里就可以根据这个字段做判断了。
-
演示网站有742页的数据,如果全部爬完的话可能会触发spiderflow的死循环校验,如有必要需要调整死循环校验次数。
解决方式: 修改后端死循环检测次数或者关闭死循环监测机制。
5. 结果验证
运行后我们观察数据库的数据,如果4的相关问题未解决的话可以在运行过程中点击对话框页面上的停止按钮来终止进程。
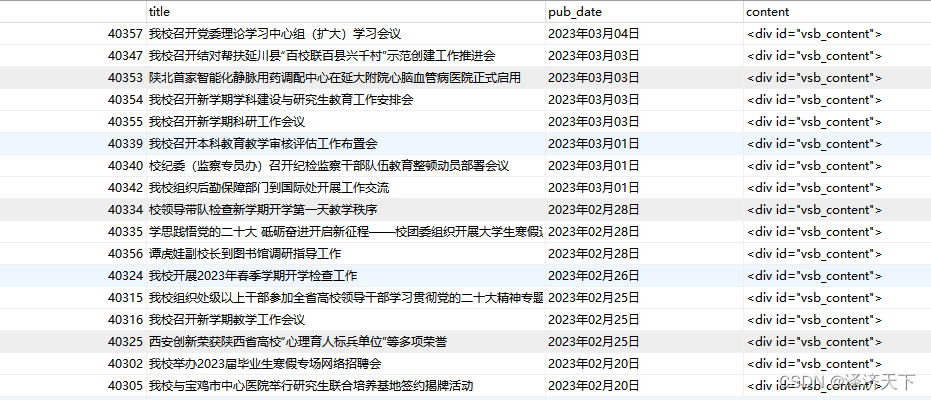
至此新闻页面爬取的功能就开发完成了,也正常入库了。
本文针对spiderflow的用法做了简单介绍和记录,并通过案例完成了数据爬取及入库过程,希望能对大家有所帮助。
后续会继续补充源码分析模块和插件开发模块。
针对以上内容,有疑问或者有更优方案的话欢迎评论区指出~
创作不易,欢迎一键三连~~~~