最近,ChatGPT横空出世。这款被马斯克形容为“强大到危险”的AI,不但能够与人聊天互动,还能写文章、改代码。于是,人们纷纷想让AI替自己做些什么,有人通过两分钟的提问便得到了一篇完美的论文,有人希望它能帮自己写情书、完成工作

我觉得Musk担心的应该是‘信息茧房’中的‘思考劫持’
大家可以查一下传播学中的这两个概念
几个测试案例

小学白念了,这是哪家不正经的小学教这个

你把柳传志往哪放...

这.....
总结,就这人工智障,还图灵测试...
ChatGPT基本原理
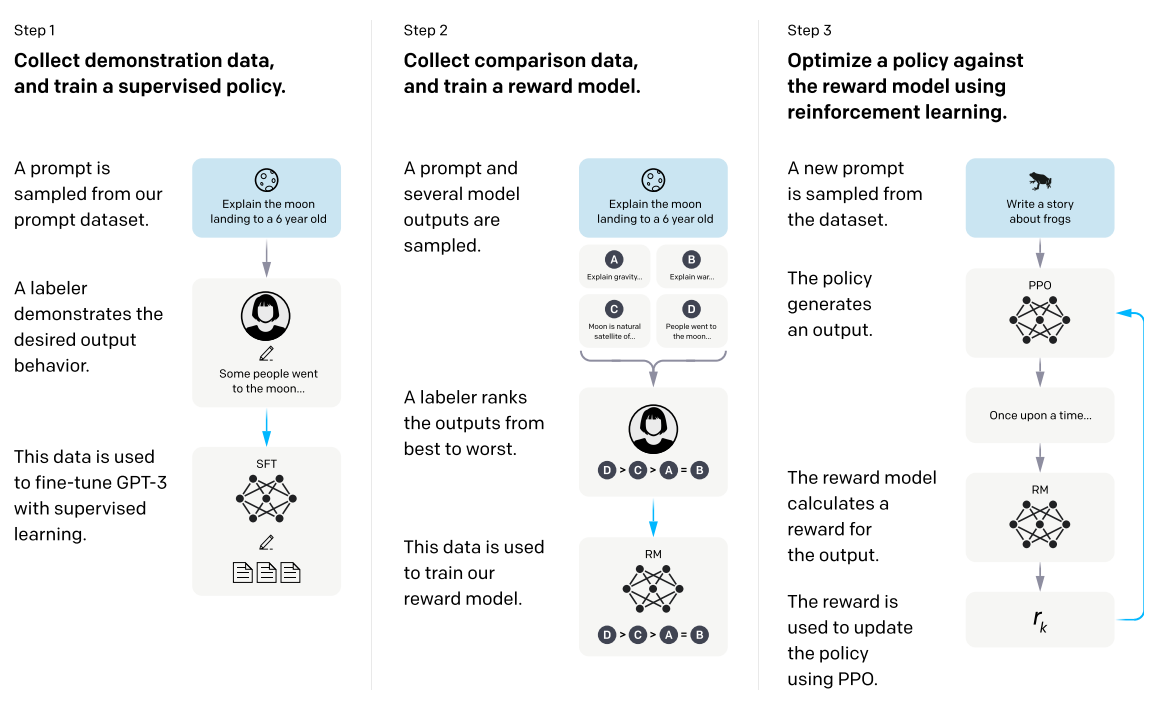
第一步 收集数据,训练有监督的策略模型
第二步 收集对比数据,训练回报模型
第三步 使用强化学习,增强回报模型优化策略
SFT:生成模型GPT的有监督精调 (supervised fine-tuning)
RM:奖励模型的训练(reward model training)
PPO:近端策略优化模型( reinforcement learning via proximal policy optimization)

找了一堆外包,可以看出人的干预有多重要
补充知识
prompt
Prompting指的是在文本上附加额外的提示(Prompt)信息作为输入,将下游的预测等任务转化为语言模型(Language Model)任务,并将语言模型的预测结果转化为原本下游任务的预测结果
对于传统的Fine-tuning范式,以BERT为例,我们会使用PLM提取[CLS]位置的特征,将其作为句子的特征,并对情感分类任务训练一个分类器,使用特征进行分类
对于Prompting,它的流程分为三步
在句子上添加Prompt。一般来说,Prompt分为两种形式,分别是完形填空(用于BERT等自编码PLM)与前缀(用于GPT等自回归PLM)
例如
I love this movie. It is a [MASK] movie. (完形填空模式)
I love this movie. The movie is (前缀模式)
2.根据Prompt的形式,在[MASK]位置或Prompt前缀的后面进行预测单词
3. 根据预先定义的Verbalizer(标签词映射)将单词转化为预测结果,若预测单词’Good’则情感倾向为正向,若预测结果为单词’Bad’则情感倾向为负向
SFT
GPT模型通过有监督的Prompt数据进行精调,其实就是做next token prediction任务。然后用精调后的模型对每个输入的[文本+prompt]进行generate,生成4~9个输出,并且进行解码操作
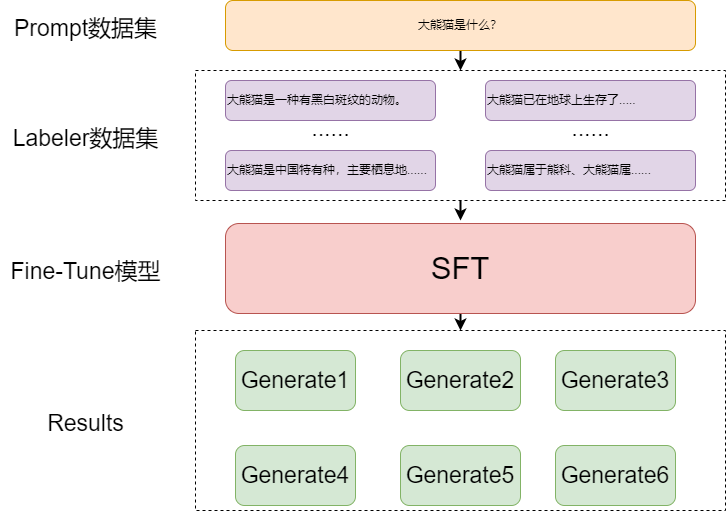
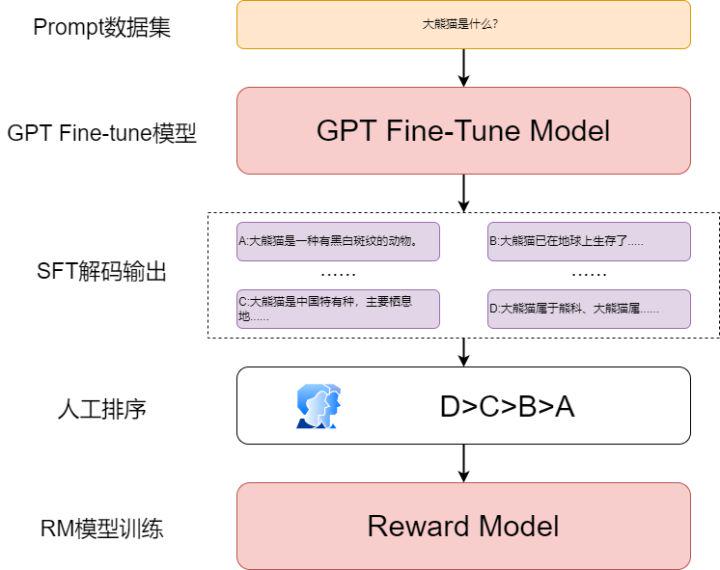
数据举例
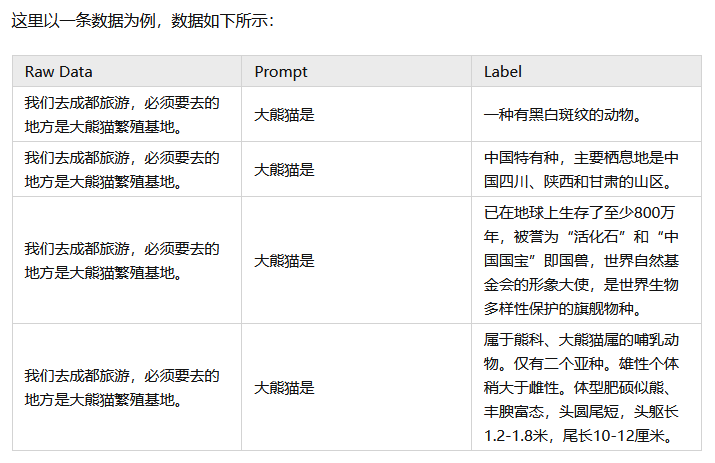
raw_data = "我们去成都旅游,必须要去的地方是大熊猫繁殖基地。"
prompt = "大熊猫是"
labels = ["一种有黑白斑纹的动物。","中国特有种,主要栖息地是中国四川、陕西和甘肃的山区。",
"已在地球上生存了至少800万年,被誉为“活化石”和“中国国宝”即国兽,世界自然基金会的形象大使,是世界生物多样性保护的旗舰物种。",
"属于熊科、大熊猫属的哺乳动物。仅有二个亚种。雄性个体稍大于雌性。体型肥硕似熊、丰腴富态,头圆尾短,头躯长1.2-1.8米,尾长10-12厘米。"]
combine_data = [raw_data+prompt+label for label in labels]RM
RM模型的作用是对生成的文本进行打分排序,让模型生成的结果更加符合人类的日常理解习惯,更加符合人们想要的答案
RM模型主要分为两个部分:训练数据获取、模型训练
在原论文中使用GPT的架构做了一个reward model,这里需要注意的是要将模型的输出映射成维度为1的打分向量,也就是增加一个linear结构
RM模型的主要点还是在于人工参与的训练数据构建部分,将训练好的SFT模型输入Prompt进行生成任务,每个Prompt生成4~9个文本,然后人为的对这些文本进行排序
将每个Prompt生成的文本构建为排序序列的形式进行训练,得到打分模型,以此模型用来评估SFT模型生成的文本是否符合人类的思维习惯
这里尝试两种方法,这两种方法为direct score和rank score:
Direct score:一个是直接对输出的文本进行打分,通过与自定义的label score计算loss,以此来更新模型参数;
Rank score:二是使用排序的方法,对每个Prompt输出的n个句子进行排序作为输入,通过计算排序在前面的句子与排序在后面的句子的差值累加作为最终loss。
Direct score方法
这个方法就是利用Bert模型对标注数据进行编码,用linear层映射到1维,然后利用Sigmoid函数输出每个句子的得分,与人工标记的得分进行loss计算,以此来更新模型参数

Rank score方法
这种方法与前一种方法的区别在于loss函数的设计
首先需要明白的是为什么在InstructGPT中不采用上面的方法,主要的原因在于给生成句子在打分时,不同标注人员的标准是不一样的,而且这个标准是很难进行统一的,这样会导致标注的数据评判标准不一样
即使每个标注人员的理解是一样的,但对于同一条文本给的分数也不一样的,因此在进行标注时需要把这个定量的问题转为一种更为简单的处理方法,采用排序来方法来进行数据标注可以在一定程度上解决这个问题
两种方法区别

明显的看出标注员在使用直接打分(Direct Score)时,会由于主观意识的不同,对同一个文本出现不同的分值;而使用等级排序(Rank Level)来进行数据标注时,可以统一标注结果
Rank Loss

PPO算法
邻近策略优化(Proximal Policy Optimization,PPO)算法的网络结构有两个。PPO算法解决的问题是 离散动作空间和连续动作空间 的强化学习问题,是 on-policy 的强化学习算法。
论文原文《Proximal Policy Optimization Algorithms》
涉及到强化学习的概念太多,就不在这里展开了
Reference
https://www.sohu.com/a/644391012_121124715
https://blog.csdn.net/Ntech2099/article/details/128263611
https://zhuanlan.zhihu.com/p/461825791
https://zhuanlan.zhihu.com/p/609795142



![Activty启动到显示的过程[二]](https://img-blog.csdnimg.cn/d3577b0f457f4a02b4c8d577733bab7b.jpeg#pic_center)