Hadoop集群搭建,基于3.3.4hadoop和centos8【小白图文教程-从零开始搭建Hadoop集群】,常见问题解决
- Hadoop集群搭建,基于3.3.4hadoop
- 1.虚拟机的创建
- 1.1 第一台虚拟机的创建
- 1.2 第一台虚拟机的安装
- 1.3 第一台虚拟机的网络配置
- 1.3.1 主机名和IP映射配置
- 1.3.2 网络参数配置
- 1.4 第一台虚拟机的Java,Hadoop环境搭建
- 1.4.1 Java环境搭建
- 1.4.2 Hadoop环境搭建
- 1、修改core-site.xml
- 2、修改hdfs-site.xml,添加以下内容
- 3、修改mapred-site.xml
- 4、修改yarn-site.xml,添加以下内容
- 5、修改 slaves文件
- 2、克隆另外两台虚拟机及网络配置
- 2.1 克隆虚拟机
- 2.2 克隆虚拟机网络配置
- 3、设置node-01到其余两台虚拟机的SSH免密登录
- 3、格式化NameNode
- 5、启动hadoop
- 6、启动和关闭Hadoop集群
- 6、通过UI查看Hadoop运行状态
- 遇到的问题
Hadoop集群搭建,基于3.3.4hadoop
Hadoop集群搭建,我这里采用的是Hadoop3.3.4,Jdk1.8,centos8,vmware16版本的。
1.虚拟机的创建
首先我们需要创建三台虚拟机,先创建第一台虚拟机,然后对第一台虚拟机进行配置(网络配置,免密配置,jdk,hadoop环境的安装),然后进行克隆,将第一台虚拟机克隆两个虚拟机出来,最后开始搭建集群。
一些目录说明 :
/export/data/ :存放数据类的文件
/export/servers/ :存放服务类软件
/export/software/ :存放安装包文件
1.1 第一台虚拟机的创建
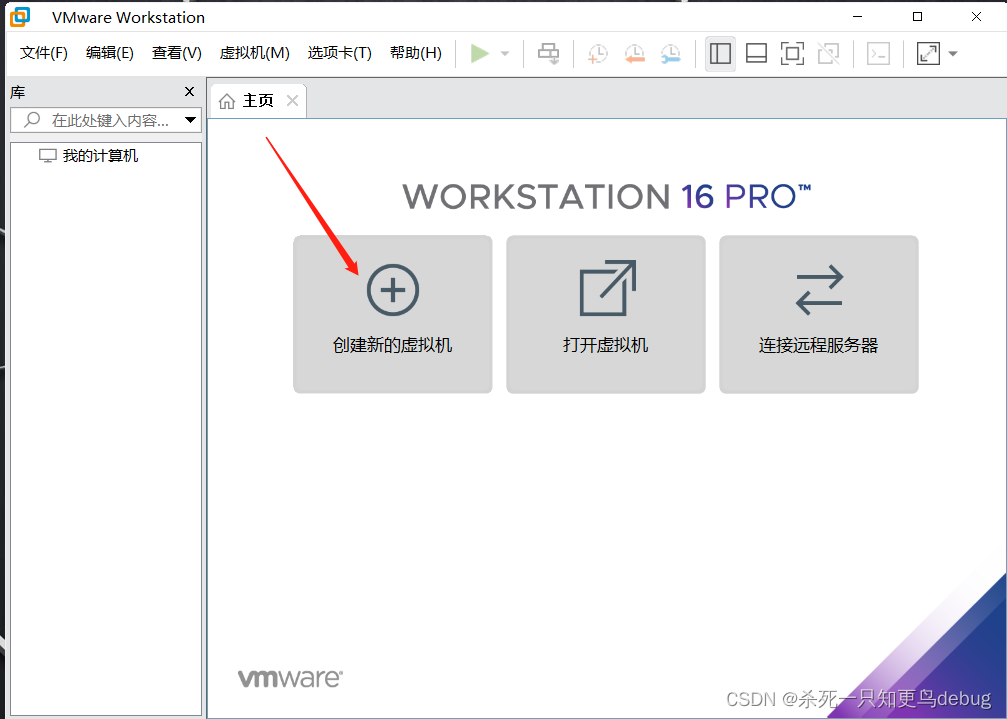
打开VMware进行第一台虚拟机的创建,点击新建虚拟机
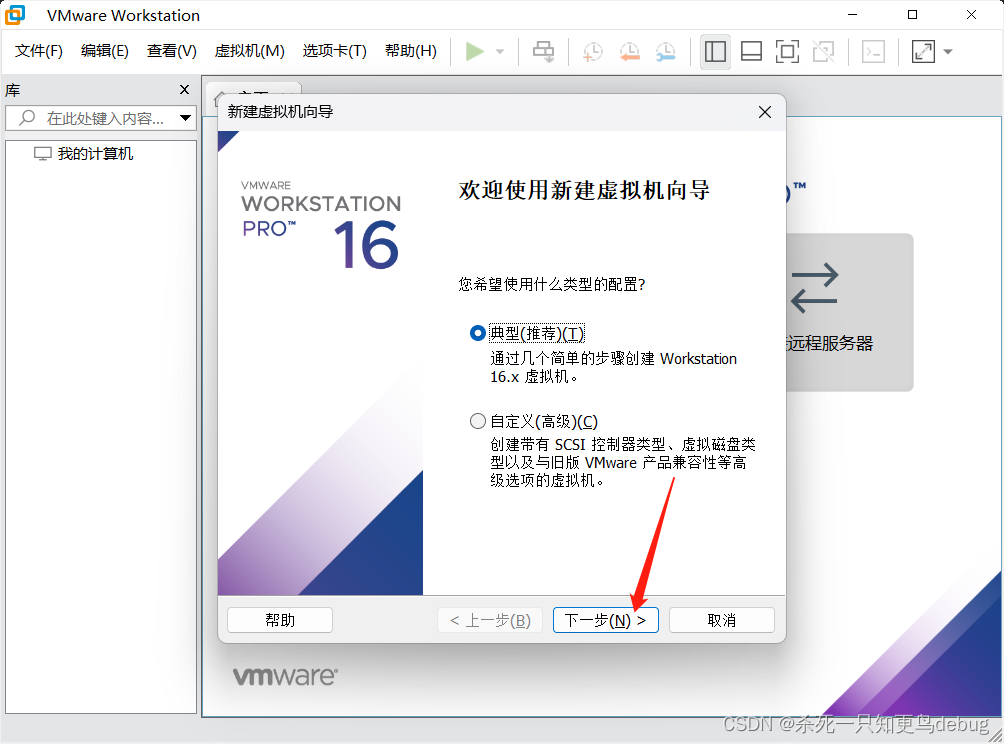
选择典型,下一步
我这里因为提前已经准备好了centos8的镜像资源,所以直接将光盘驱动文件选择了,然后点击下一步
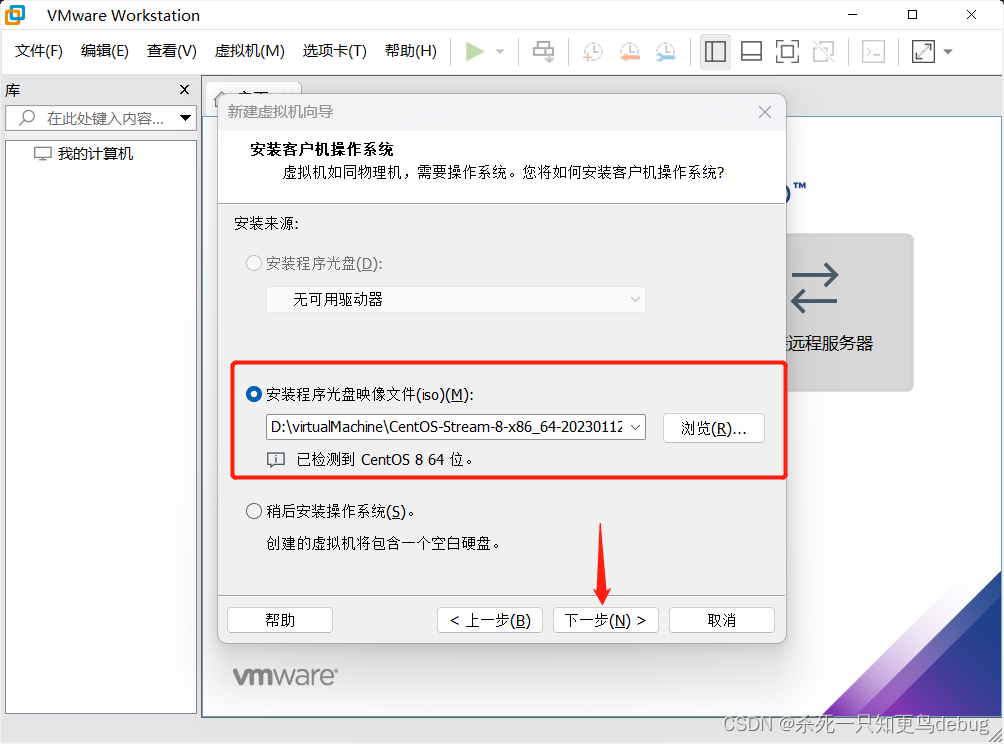
然后自定义虚拟机名称,已经安装的位置,我这里使用node-01(主虚拟机)作为第一台虚拟机的名称,然后点击下一步
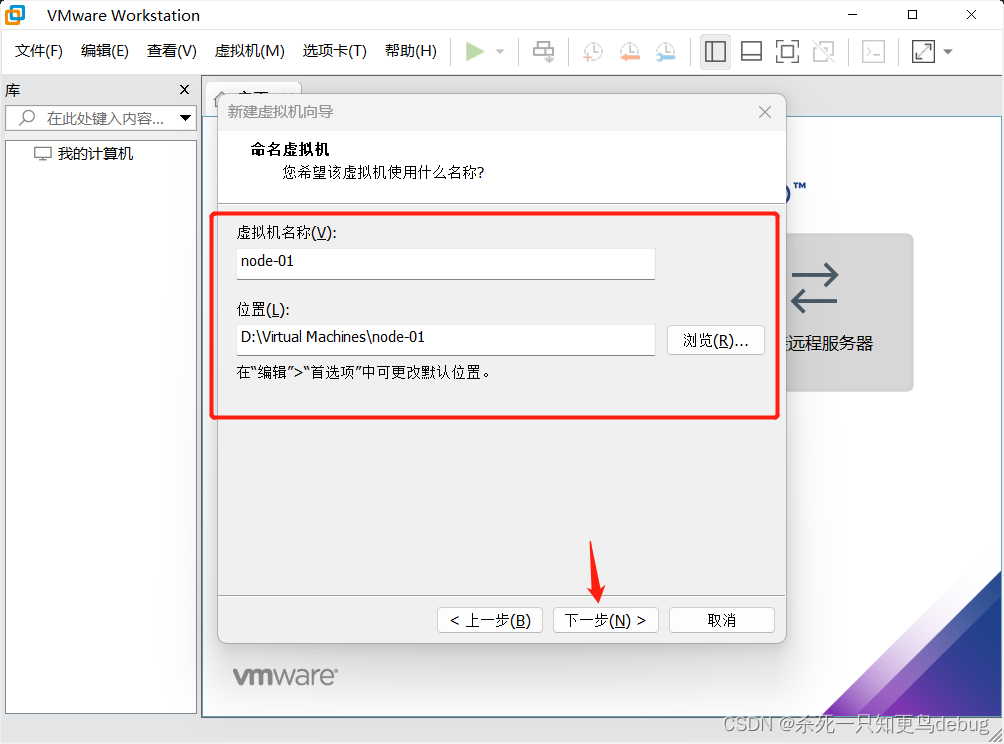
磁盘空间默认20GB即可,下一步
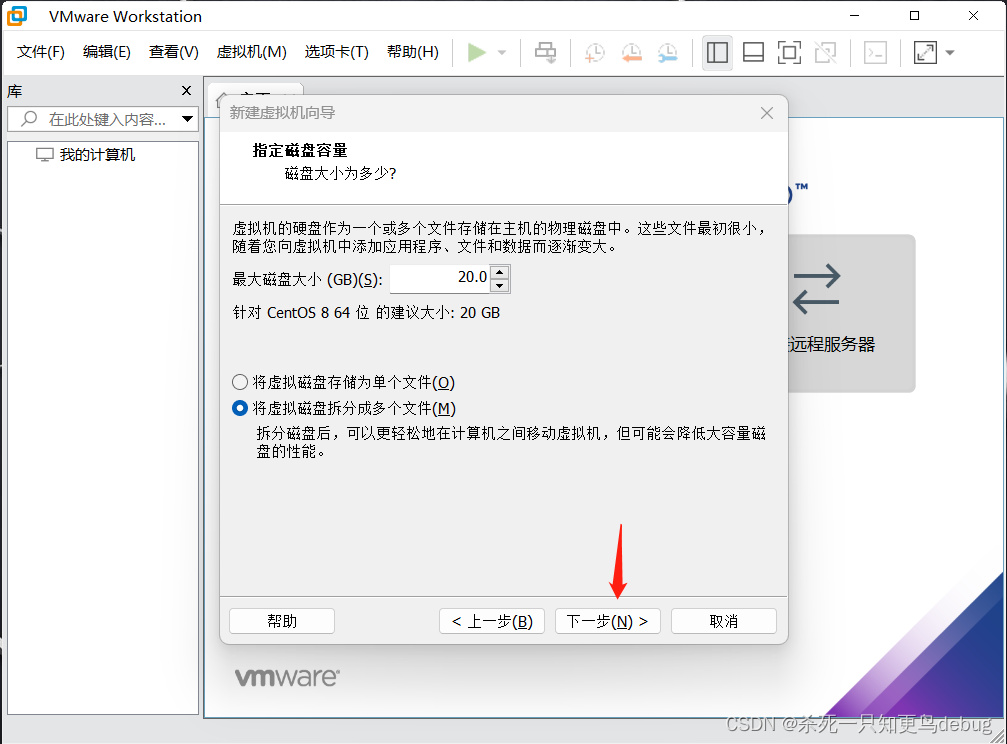
点击自定义硬件,对虚拟机的内存和cpu进行一定的配置
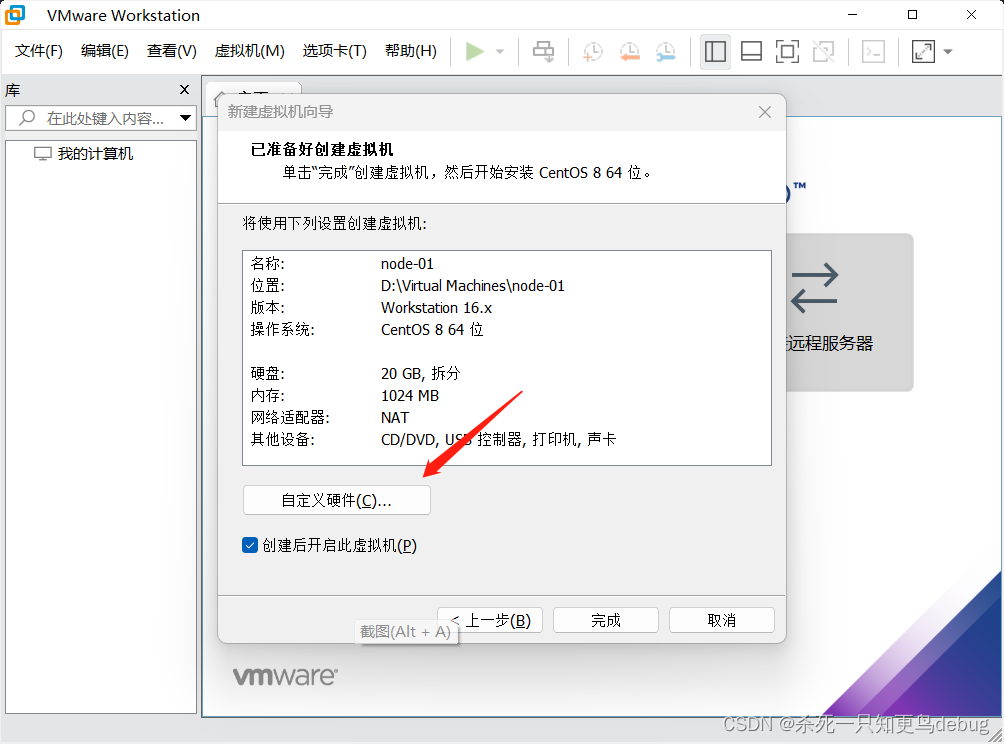
这里我只将虚拟机的内存进行了更改,由默认的1GB改到了2GB,然后点击关闭
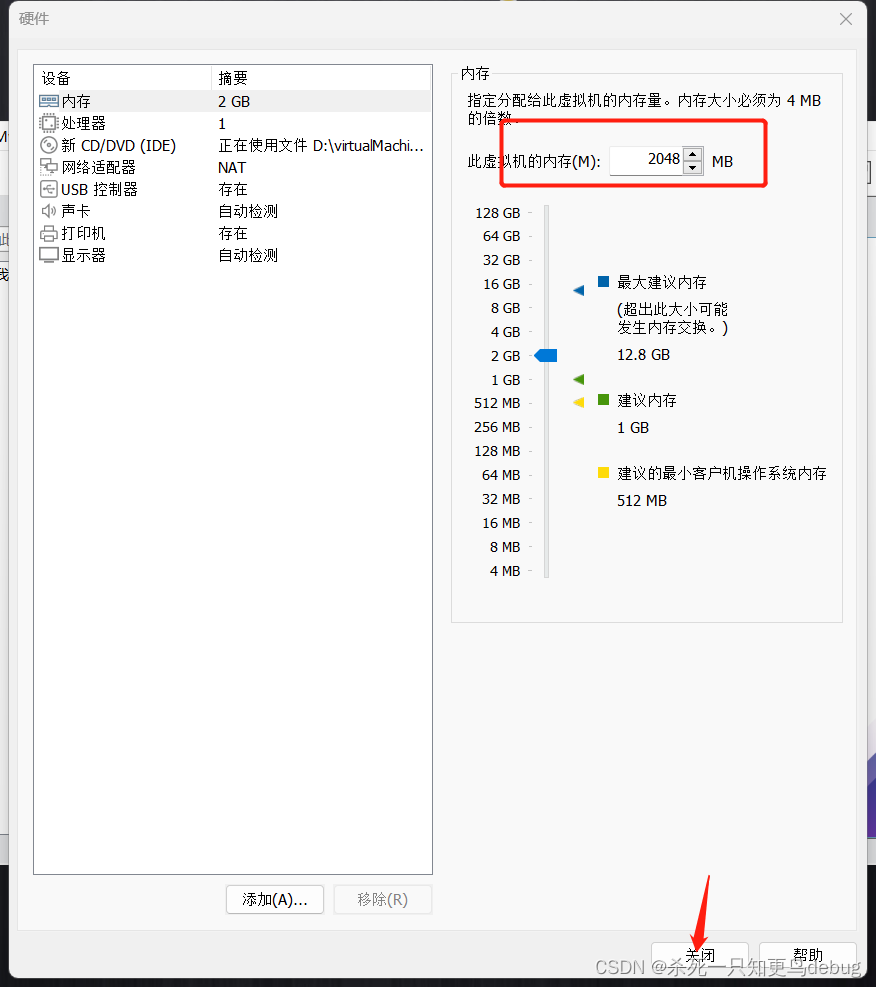
点击完成
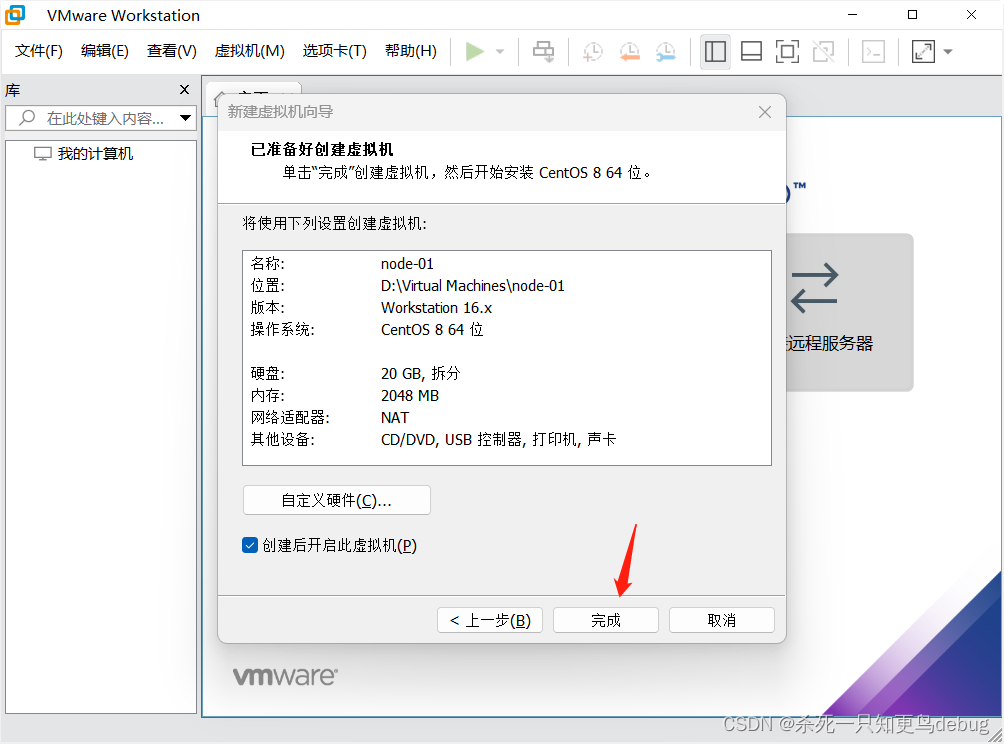
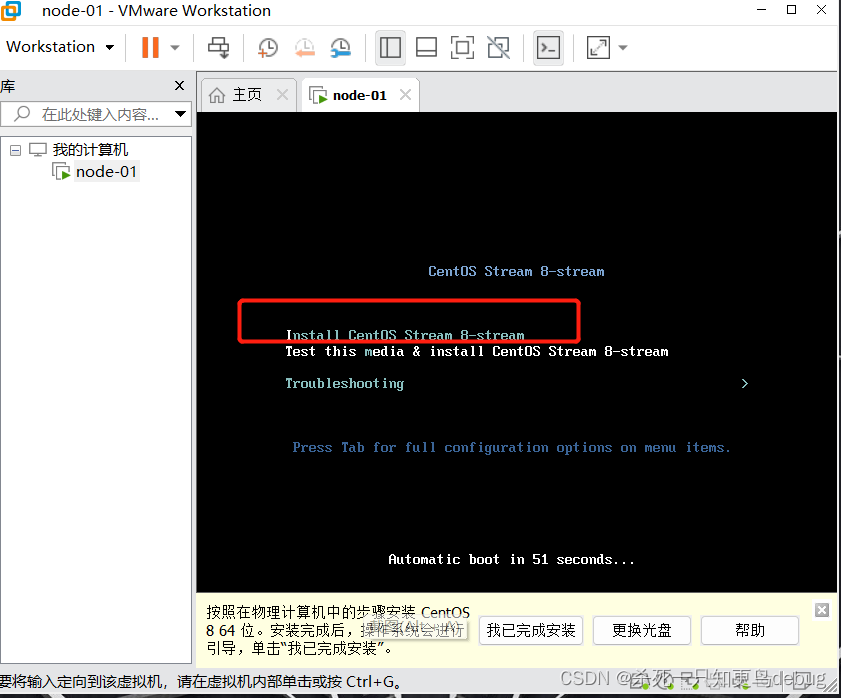
1.2 第一台虚拟机的安装
然后进入到虚拟机安装的环节,通过上下键切换,选择Install Centos stream 8-stream
选择语言,中文,然后点击继续
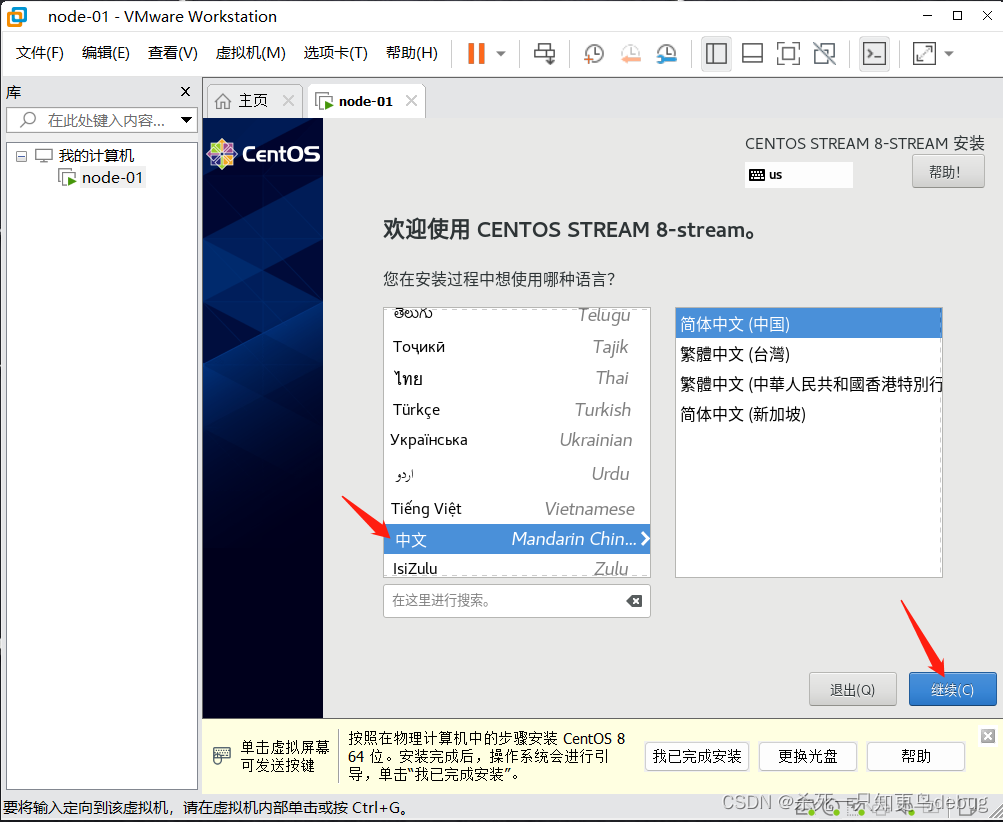
选择root密码,对root账户的密码进行初始化设定
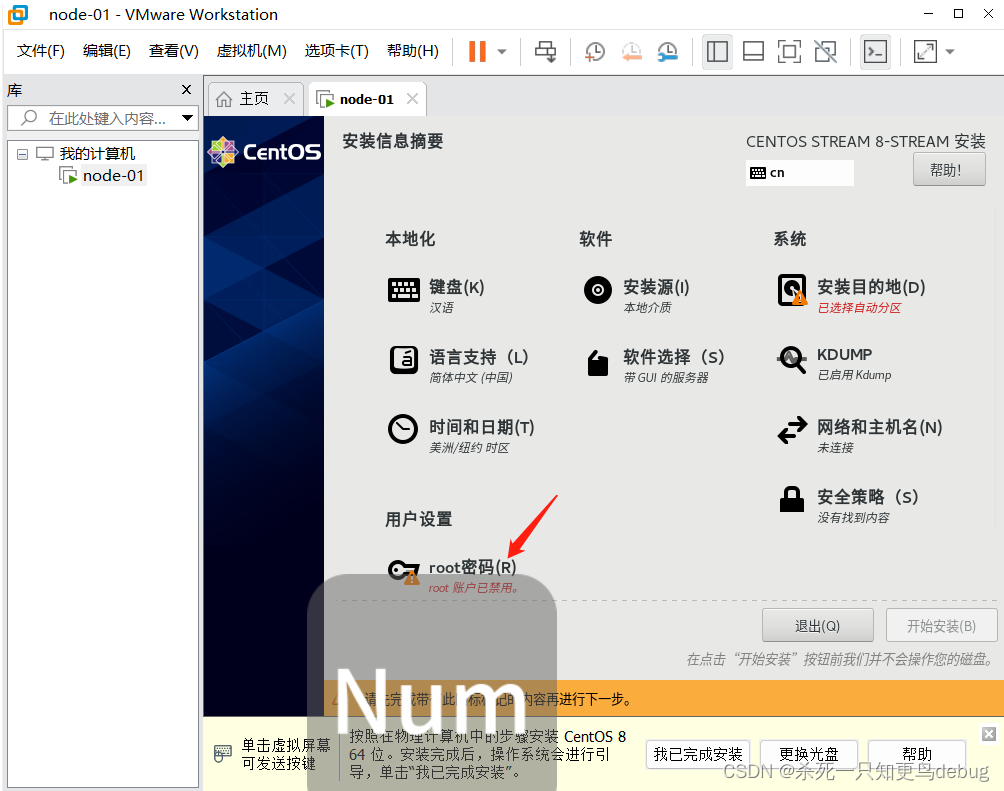
点击完成

接着我们再对网络进行配置,选择网络和主机名
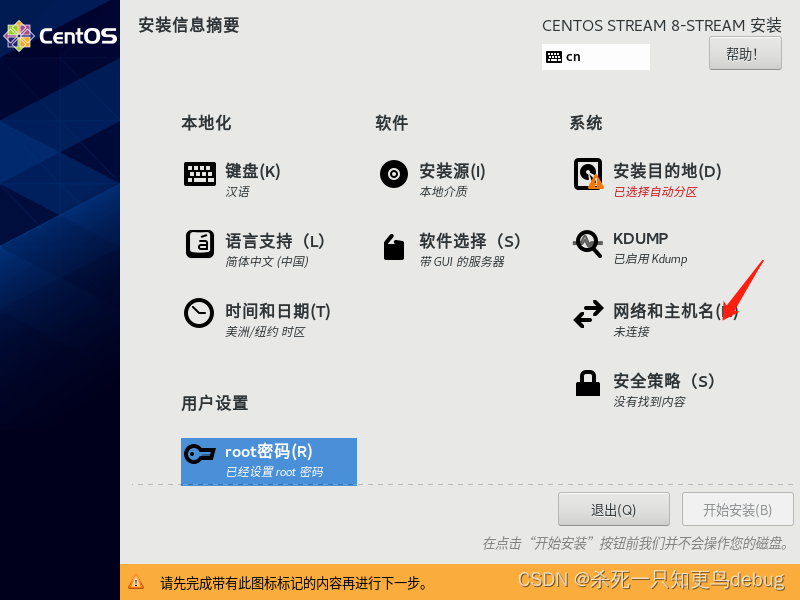
将网络开启,然后设定主机名,并且应用,然后点击完成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SCi6iw8q-1678112318718)(C:\Users\robin\AppData\Roaming\Typora\typora-user-images\image-20230306143654062.png)]](https://img-blog.csdnimg.cn/b304acc0c15c4fc8a9a339ff9cfd16a5.png)
然后选择时区,将时区设为ASia/Shanghai
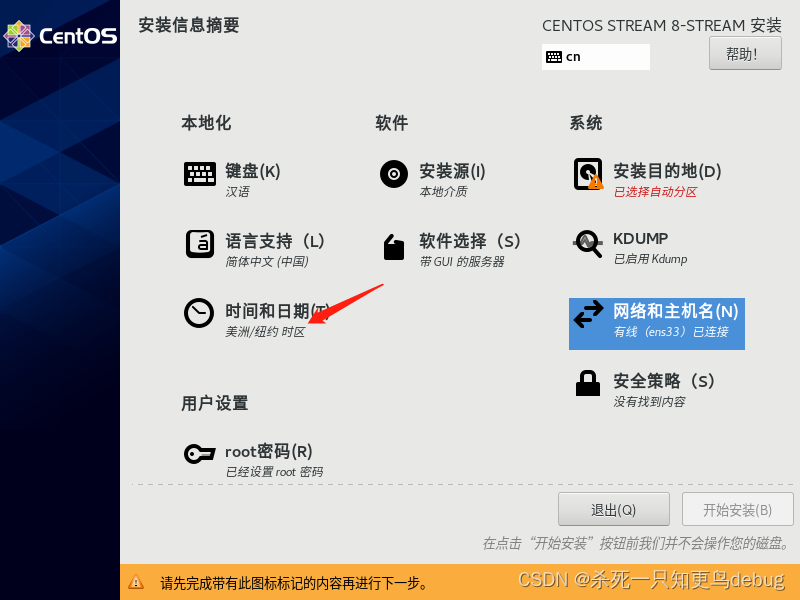
点击完成
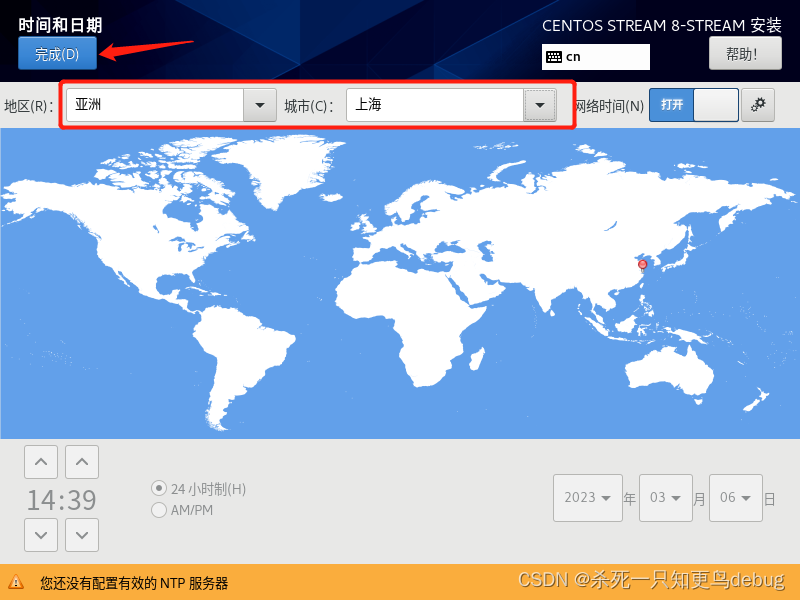
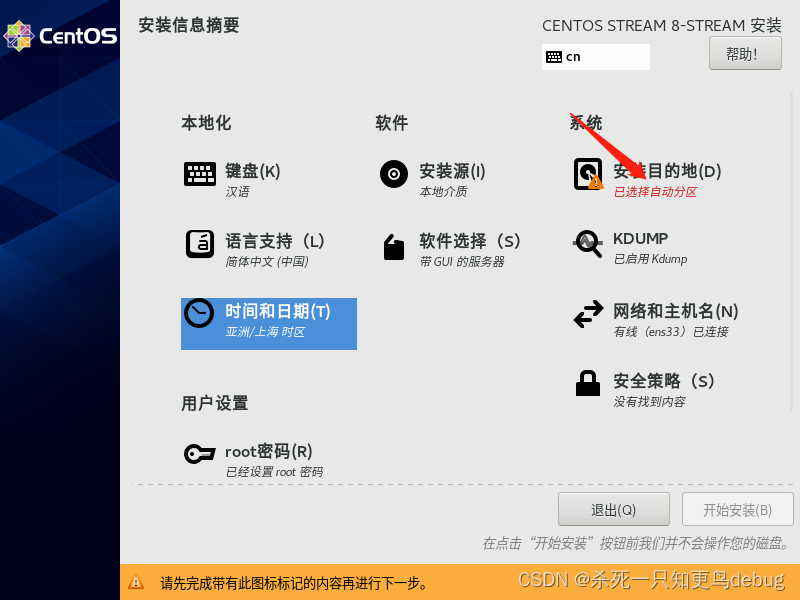
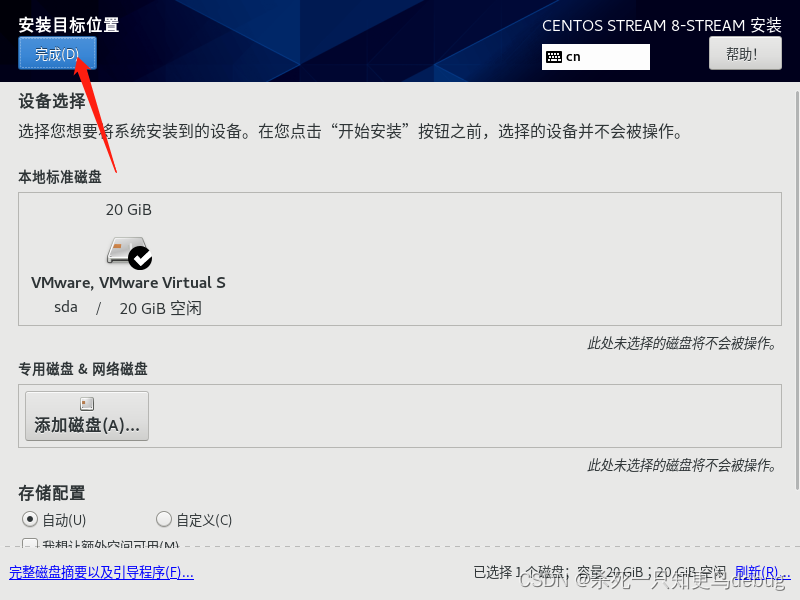
然后选择分区,默认分区也可以
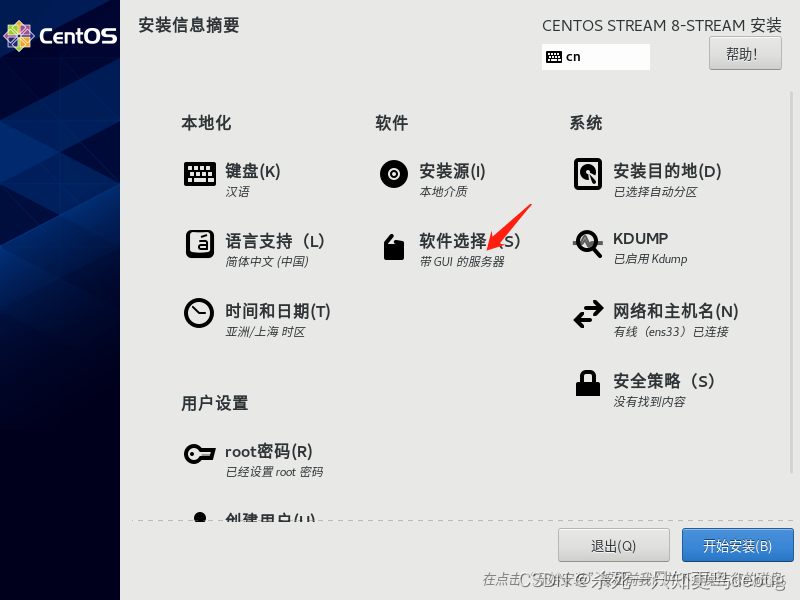
然后进行软件的选择
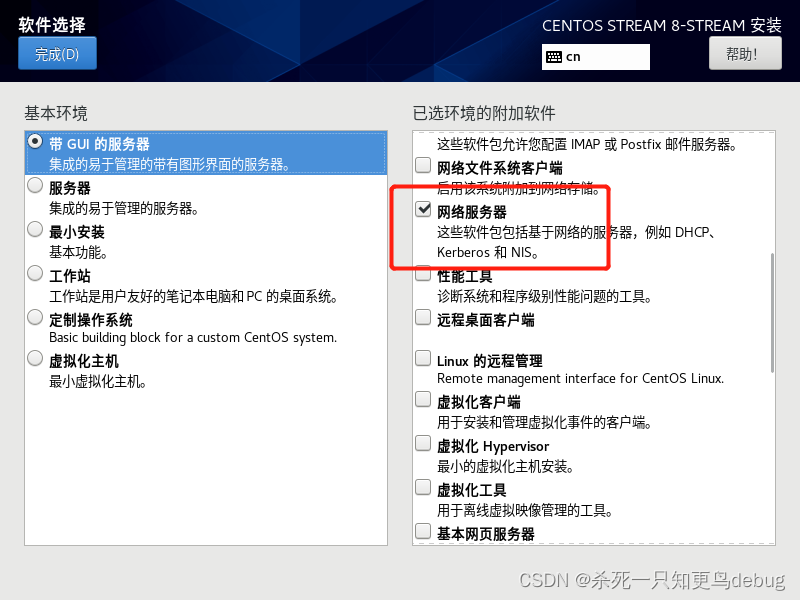
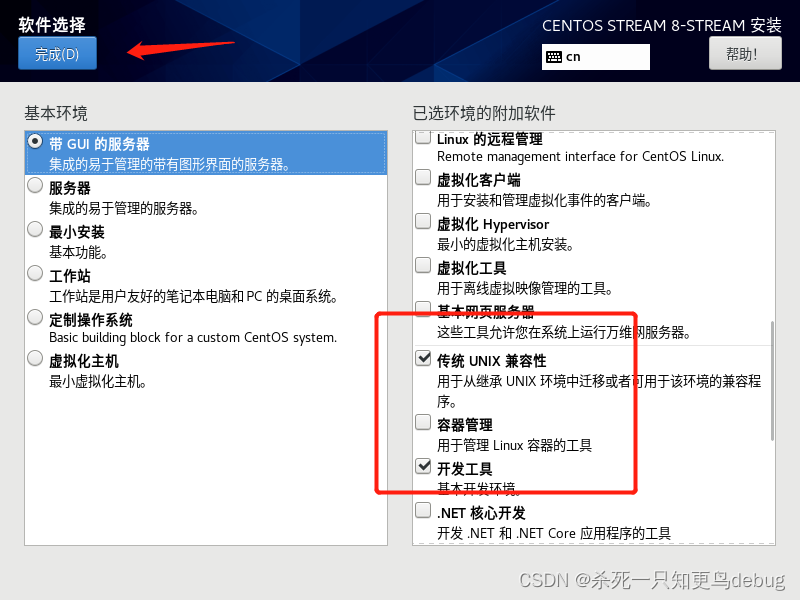
因为我是小白,所以还是选择了带GUI图形界面的,然后选择网络服务器,传统的UNIX兼容性和基本的开发工具即可
然后开始安装即可,大概几分钟左右
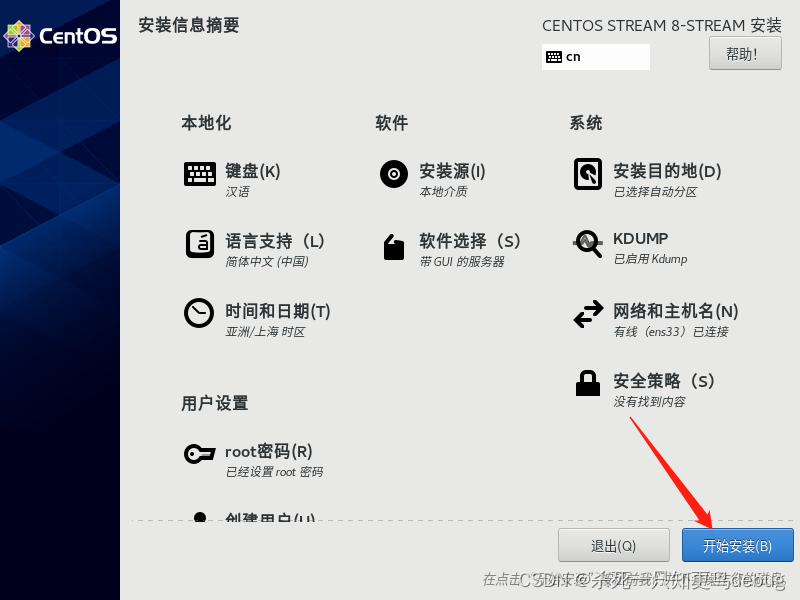
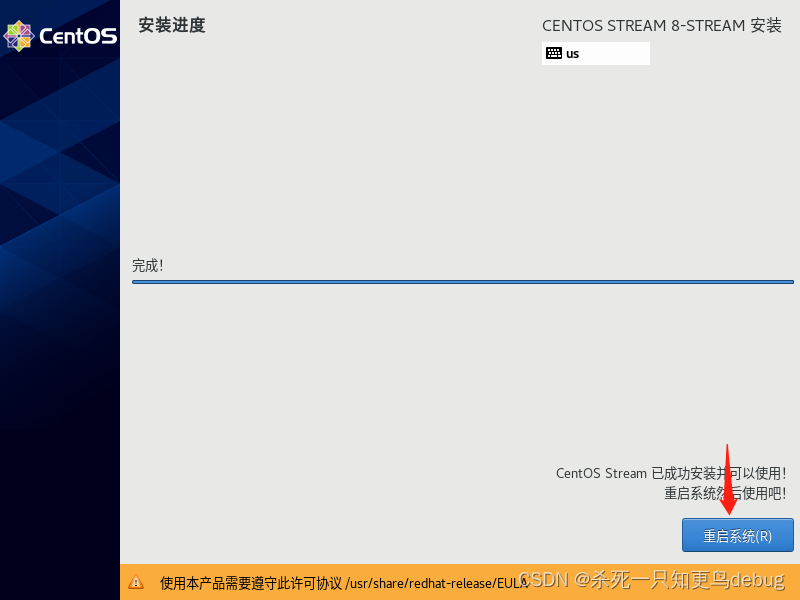
点击重启系统即可

重新启动后,它会让你确认是否接受服务,选择接受即可,然后创建用户这项根据个人需求我就暂时不创建了。
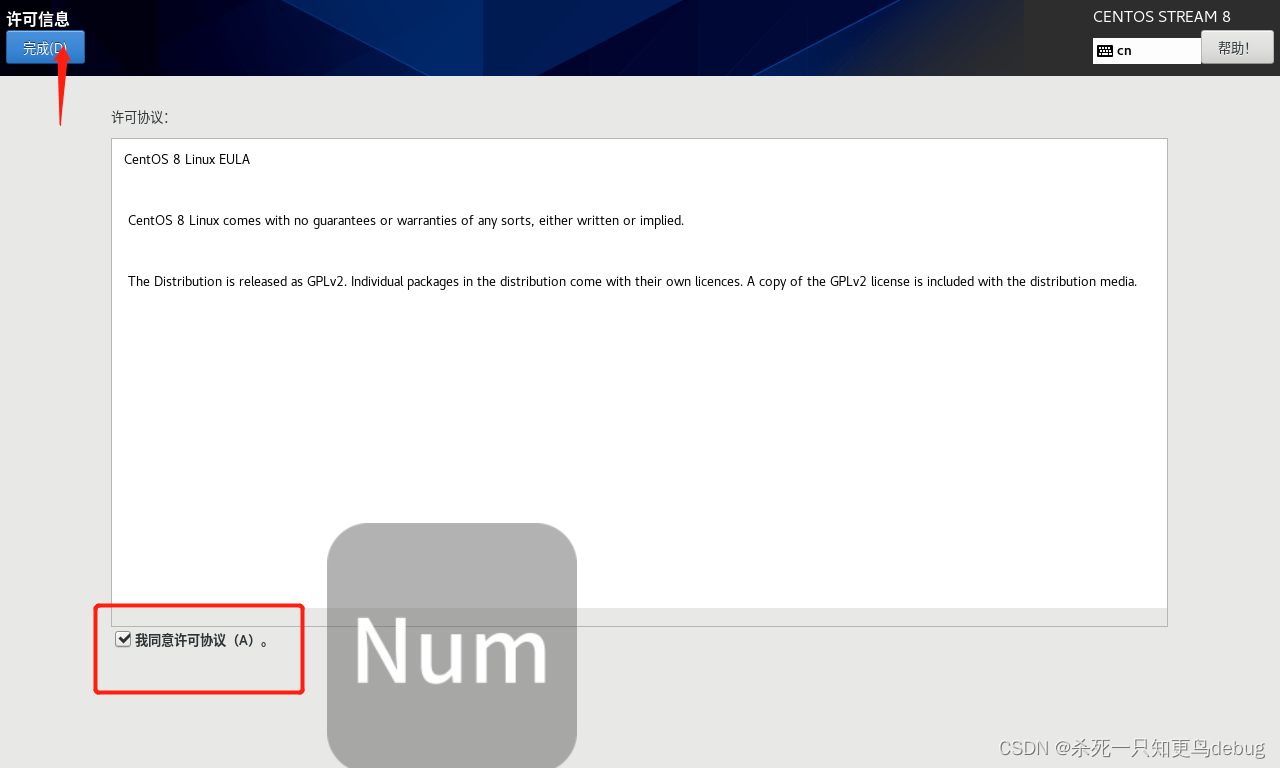

初始界面,如下,第一台虚拟机搭建完毕
1.3 第一台虚拟机的网络配置
我们可以使用XShell来进行远程登录,使用Xftp来进行文件的传输和下载,我这里就不过多赘述,在我的另外一篇文章中都有详细的介绍。
(1条消息) Xshell和Xftp的下载和在linux虚拟机中的使用_xshell和xftp下载_杀死一只知更鸟debug的博客-CSDN博客
1.3.1 主机名和IP映射配置
配置主机名
vi /etc/sysconfig/network
将虚拟机主机名称设为 node-01,node-02,node-03

配置IP映射
vi /etc/hosts
将IP地址与主机名,进行关联,对/etc/hosts文件进行下面的添加
192.168.197.133 node-01
192.168.197.134 node-02
192.168.197.135 node-03

1.3.2 网络参数配置
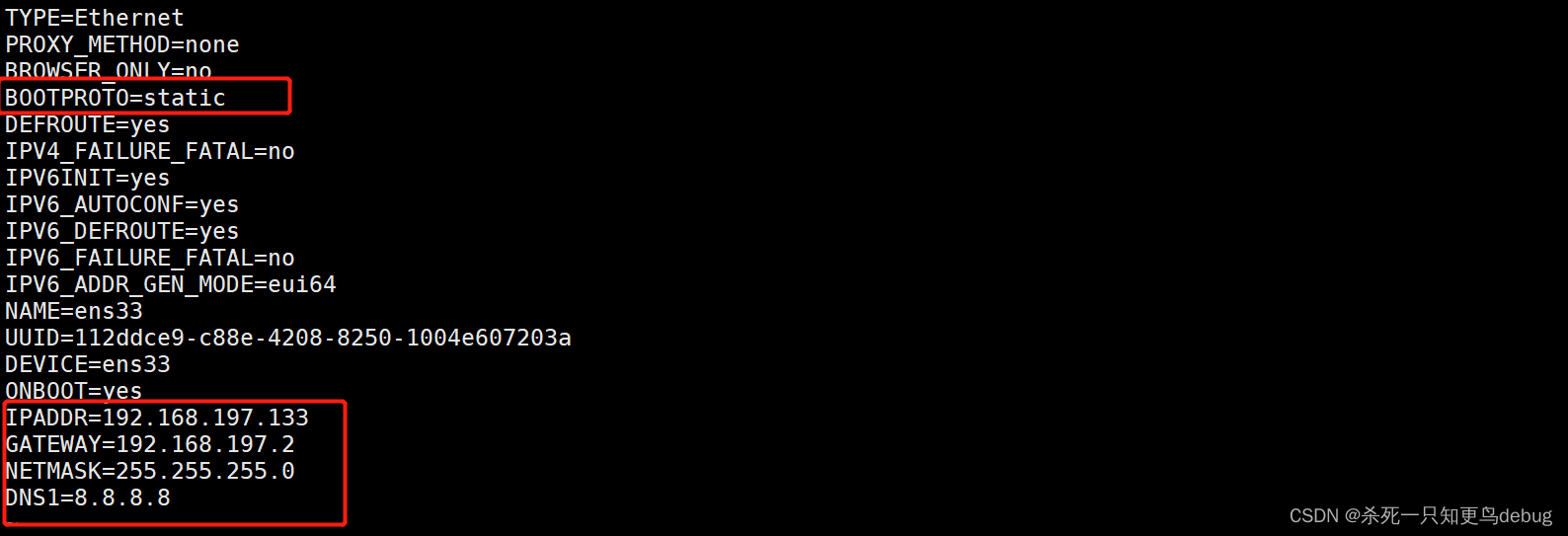
修改IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
默认配置如下图

将BOOTPROTO的值改为static,静态路由协议,保持IP的固定
BOOTPROTO=static
IPADDR=192.168.197.133
GATEWAY=192.168.197.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
重启网络配置使其生效
service network restart
然后可以使用 ifconfig指令查看网络是否配置成功。
1.4 第一台虚拟机的Java,Hadoop环境搭建
1.4.1 Java环境搭建
去到Java的官网,然后下载对应的Linux版本的Jdk

创建一个目录,用于存放java的环境,上面已经说过了,要将软件包存放到/export/software文件夹中
mkdir -p /export/data/ # 存放数据类的文件
mkdir -p /export/servers/ # 存放服务类软件
mkdir -p /export/software/ #存放安装包文件

将Jdk通过Xftp传入到Linux虚拟机上刚刚创建的目录下,然后进行解压安装及环境配置
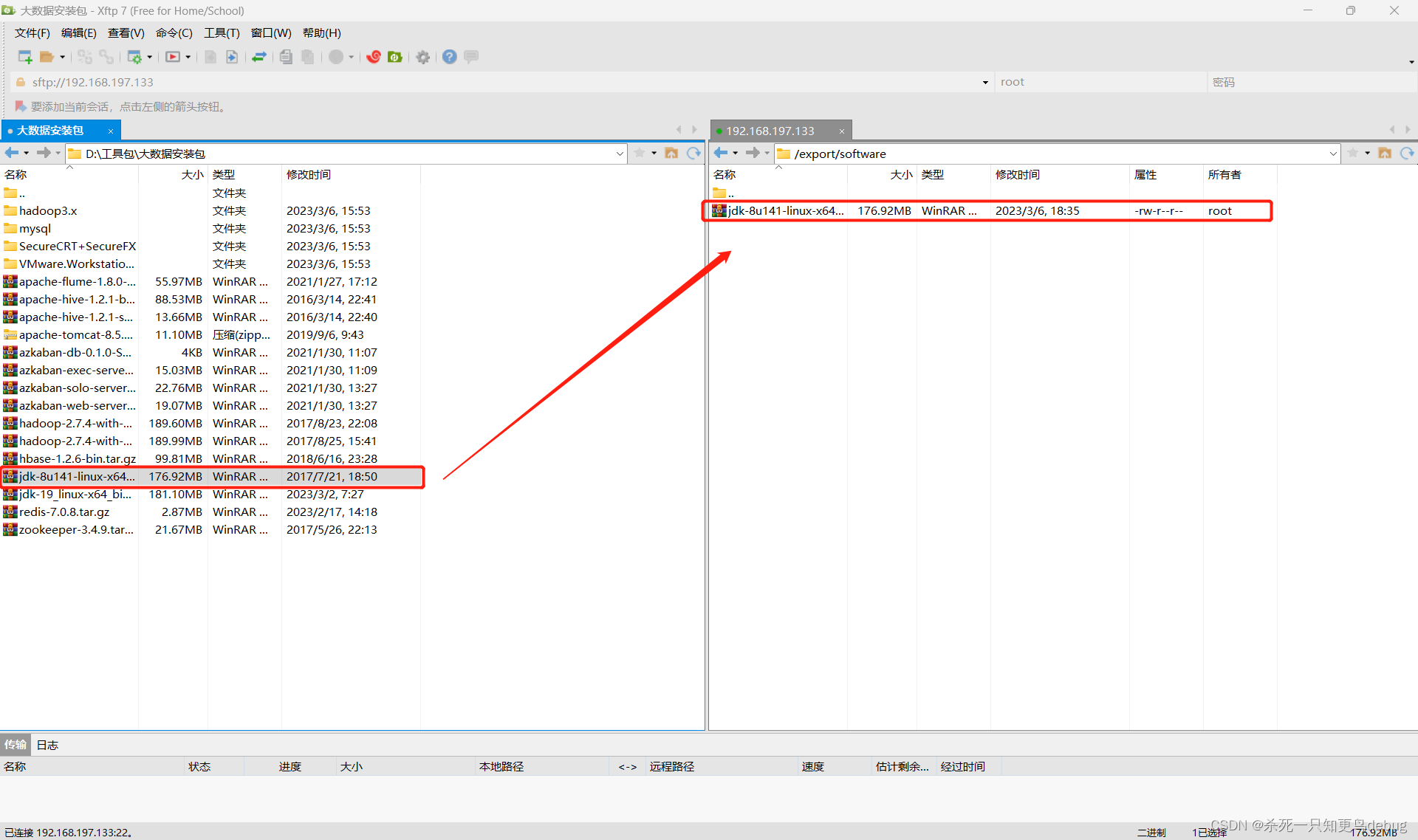
接着切换到java目录下,对压缩包进行解压
cd /export/software # 切换目录
tar -zxvf jdk-8u141-linux-x64.tar.gz -C/export/servers # 解压
配置Java的环境变量,用vi 打开/etc/profile 文件进行配置
vi /etc/profile
将下面的配置信息,写入到 /etc/profile目录中(注意你安装的Java版本及解压的名称)。
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
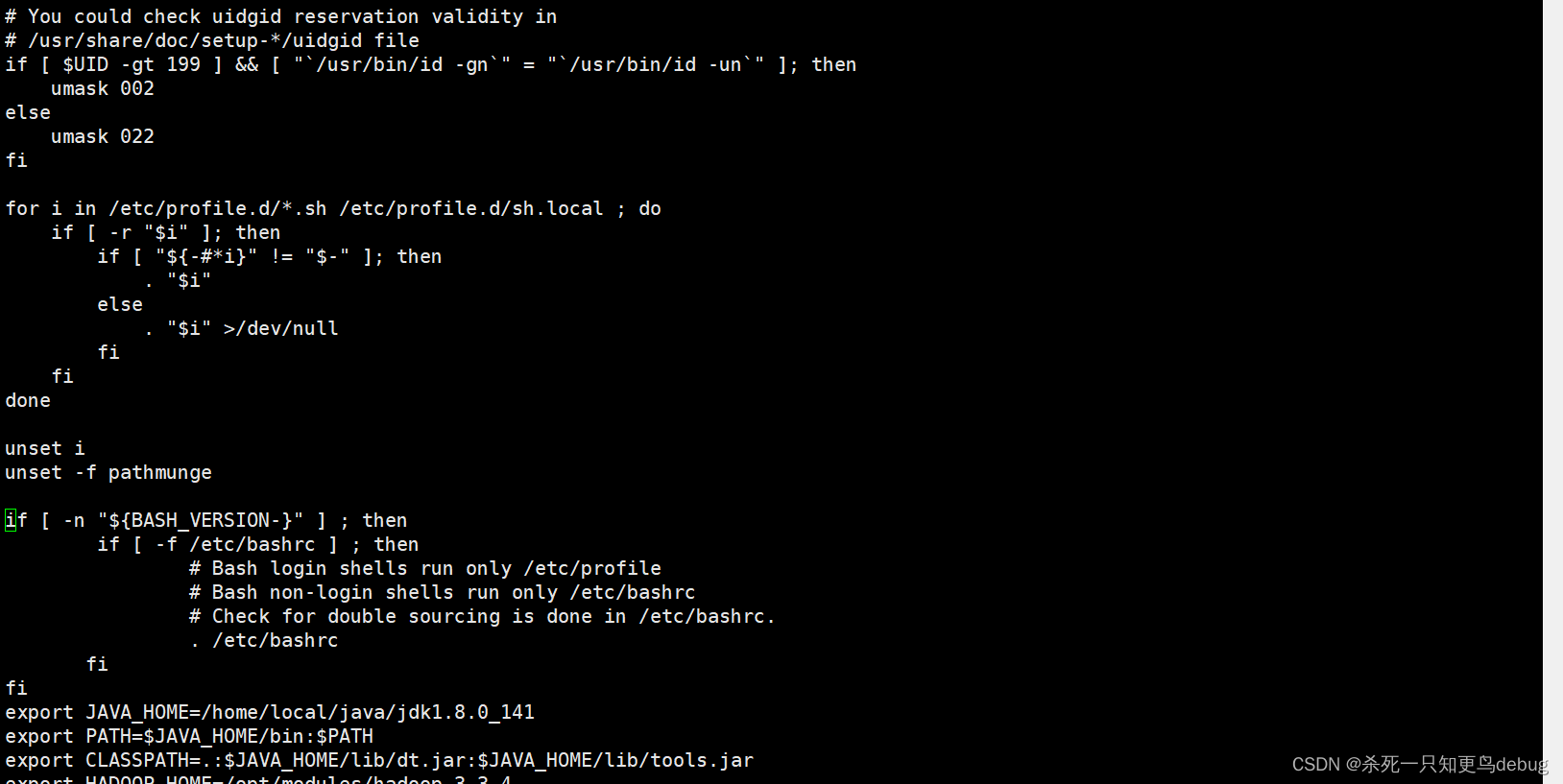
然后保存退出 Esc : wq
接着重新加载配置文件:
source /etc/profile
然后输入
java -version
此时就可以看到Java环境安装好啦

1.4.2 Hadoop环境搭建
同样,安装Linux中的Hadoop环境,先需要去其官网下载对应的Hadoop版本 Apache Hadoop
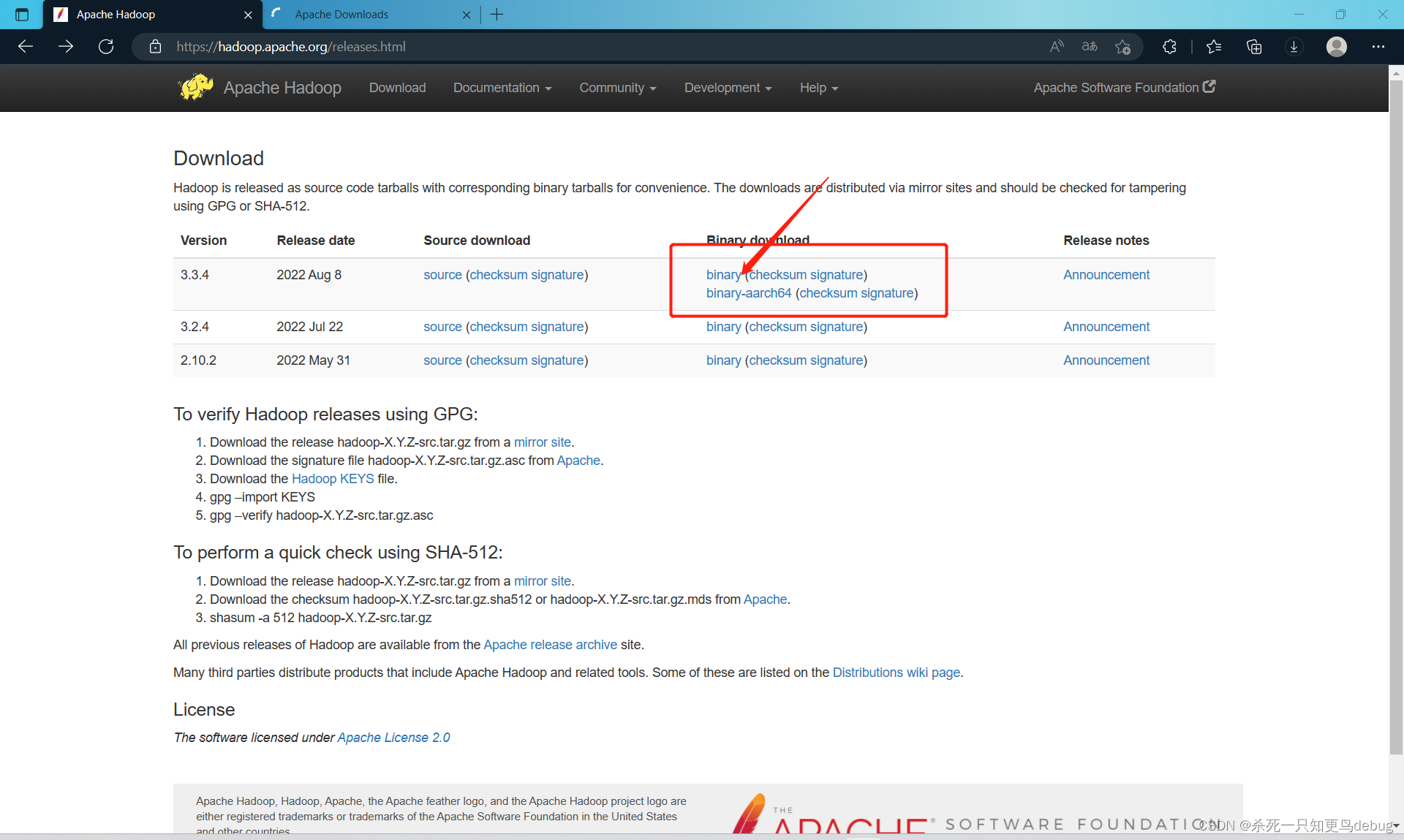
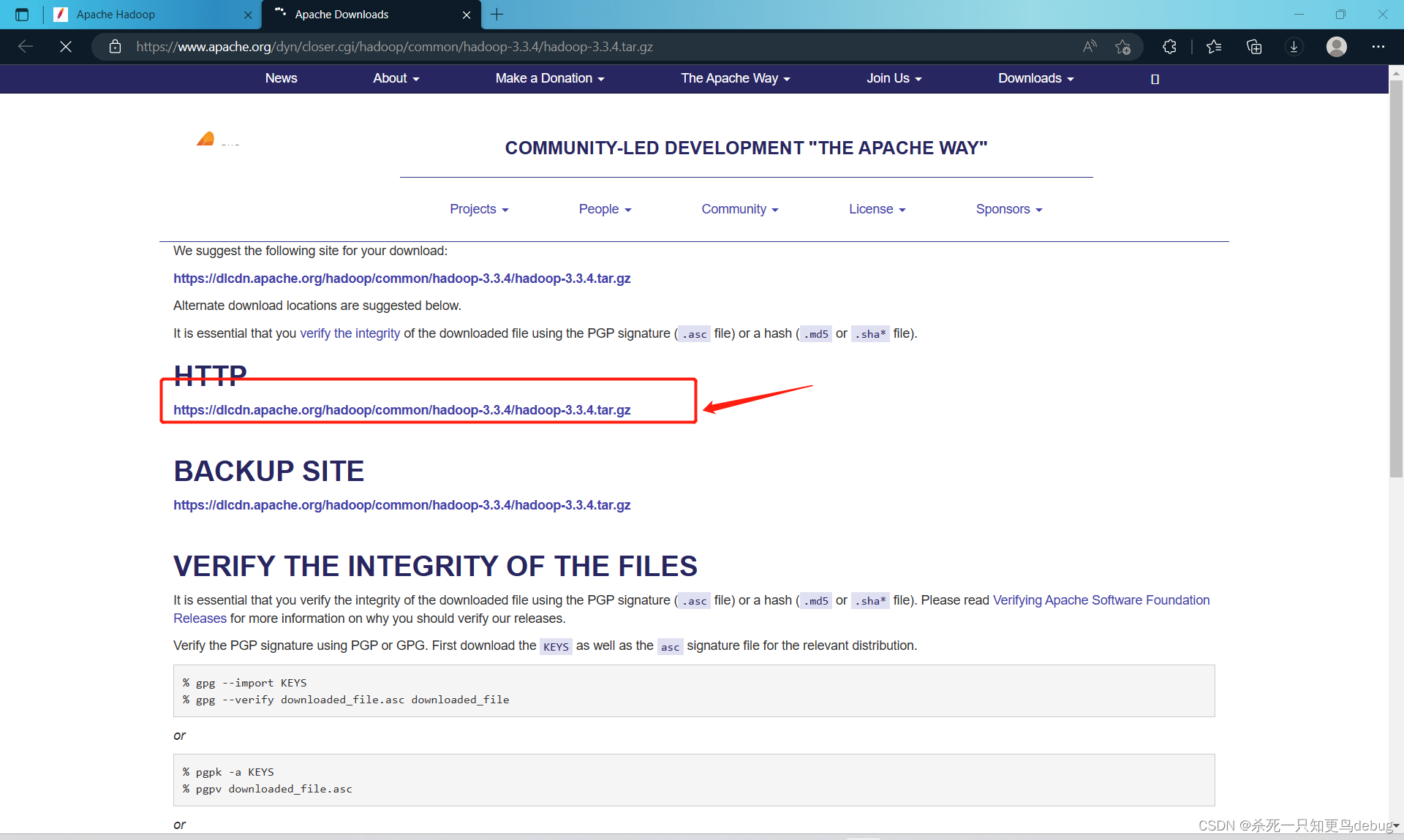
找到压缩包后,将其传输到Linux虚拟机中的 /export/software 目录下,我这里使用的是最新的hadoop3.3.4
Apache Downloads
然后解压该压缩包到 /export/servers 目录下
cd /export/software
#如果不存在 modules目录则进行创建 mkdir modules
tar -zxvf hadoop-3.3.4.tar.gz -C /export/servers
接着开始对 /etc/profile 开始配置hadoop系统环境
vi /etc/profile
将下面的内容插入到 /etc/profile 的底部
export HADOOP_HOME=/export/servers/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

然后保存退出 Esc : wq
同样需要重新加载一下配置文件使其生效
source /etc/profile
输入hadoop -version,查看其输出,可见此时hadoop已经安装完毕

配置环境变量:
hadoop所有配置文件都存在安装目录下的/etc/hadoop目录中(我这里是**/export/servers/hadoop-3.3.4/etc/hadoop**),在该目录下的hadoop-env.sh、mapred-env.sh、yarn-env.sh中添加JAVA_HOME环境变量:
export JAVA_HOME=/export/servers/jdk1.8.0_141
如下图:
进入到其安装目录下的/etc/hadoop的目录中,然后对hadoop-env.sh、mapred-env.sh、yarn-env.sh中添加JAVA_HOME环境变量
1. 修改hadoop-env.sh
vi hadoop-env.sh
找到 export JAVA_HOME 然后添加/export/servers/javajdk1.8.0_141(jdk目录位置)

然后保存退出 Esc :wq
yarn-env.sh
vi yarn-env.sh

保存退出
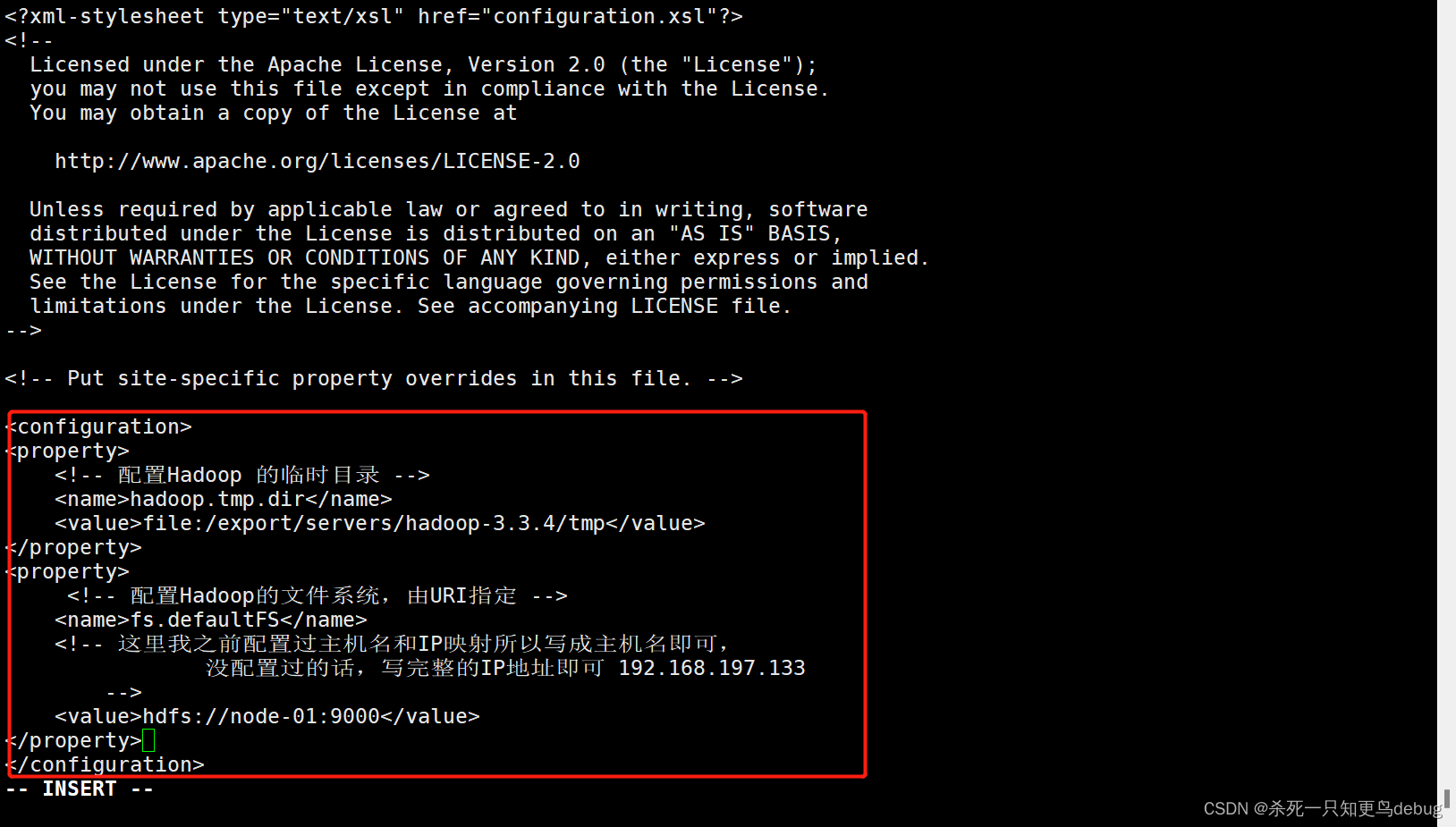
1、修改core-site.xml
Hadoop的核心配置文件,其目的是配置HdFS地址,端口号,以及临时文件目录
vi core-site.xml # 使用vi对其xml进行配置
添加以下内容
<property>
<!-- 配置Hadoop 的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>file:/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property>
<!-- 配置Hadoop的文件系统,由URI指定 -->
<name>fs.defaultFS</name>
<!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,
没配置过的话,写完整的IP地址即可 192.168.197.133
-->
<value>hdfs://node-01:9000</value>
</property>
参数说明:
- fs.defaultFS:默认文件系统,HDFS的客户端访问HDFS需要此参数
- hadoop.tmp.dir:指定Hadoop数据存储的临时目录,其它目录会基于此路径, 建议设置到一个足够空间的地方,而不是默认的/tmp下
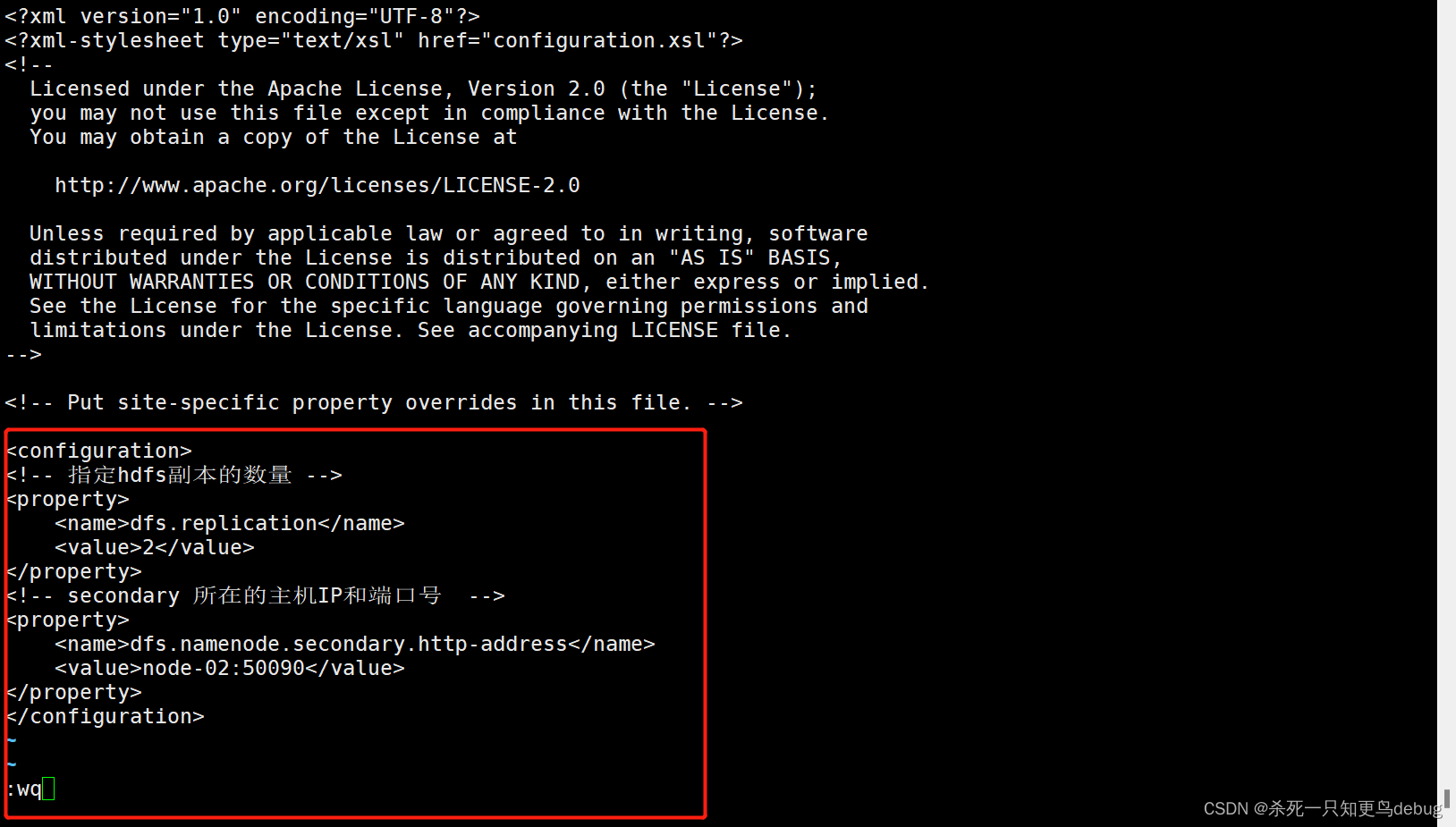
2、修改hdfs-site.xml,添加以下内容
vi hdfs-site.xml
hdfs-site.xml 用于设置HDFS的NameNode和DataNode两大进程
<!-- 指定hdfs副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- secondary 所在的主机IP和端口号 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-02:50090</value>
</property>
参数说明:
- dfs.replication:数据块副本数 - dfs.name.dir:指定namenode节点的文件存储目录
- dfs.data.dir:指定datanode节点的文件存储目录
3、修改mapred-site.xml
mapred-site.xml是MapReduce的核心配置文件,用于指定MapReduce运行时框架。
vi marped-site.xml
添加以下内容
<property>
<!-- 指定MapReduce运行时框架,指定yarn,默认是local -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
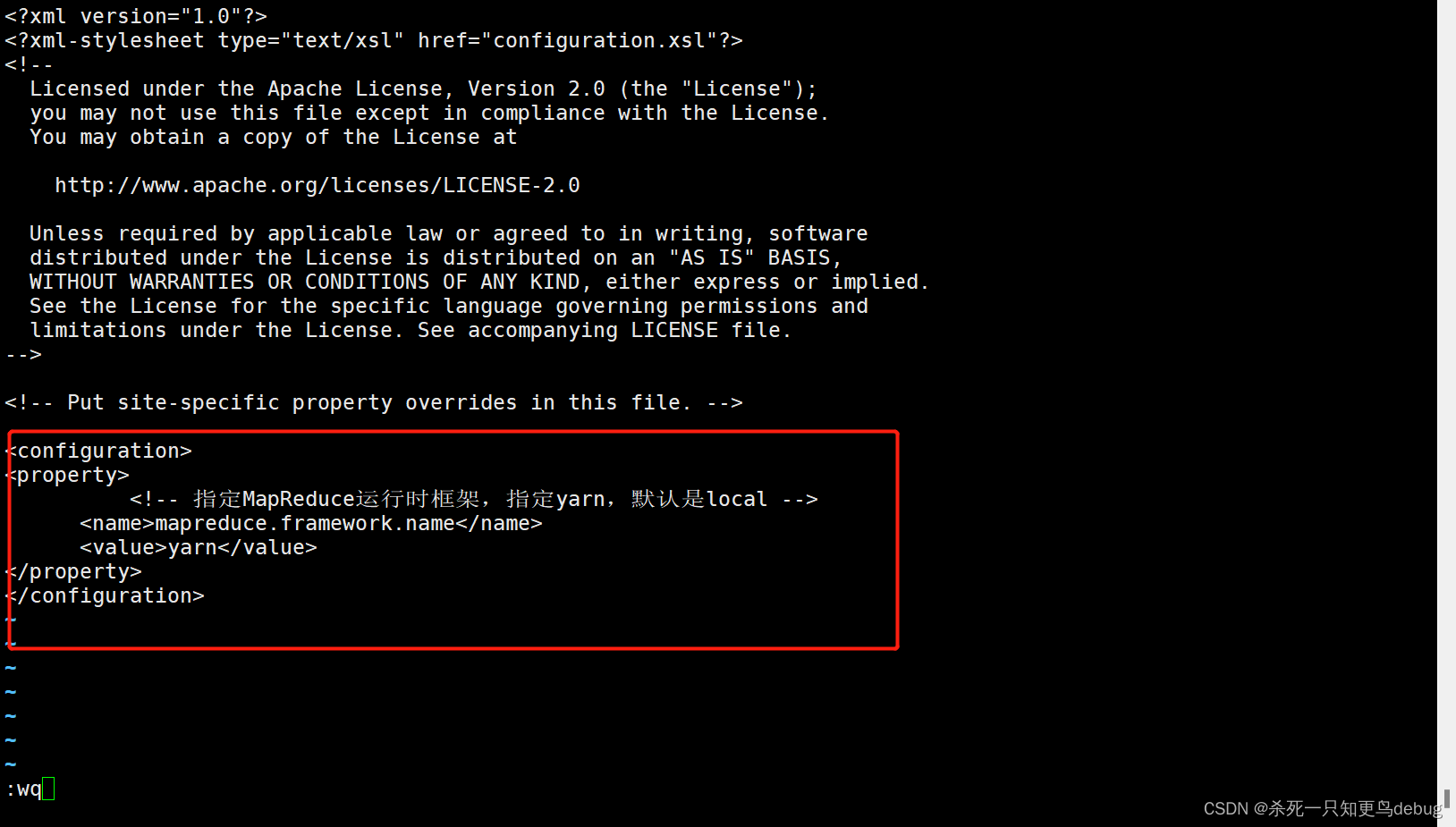
4、修改yarn-site.xml,添加以下内容
yarn-site.xml是YARN框架的核心配置文件,需要指定YARN集群的管理者。
vi yarn-site.xml
添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN集群的管理者Resoucemanage的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-01</value>
</property>
参数说明:
- yarn.nodemanager.aux-services:NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可以运行Mapreduce程序。yarn提供了该配置用于在nodemanager上扩展自定已服务,MapReduce的Shuffle功能正式一种扩展服务。
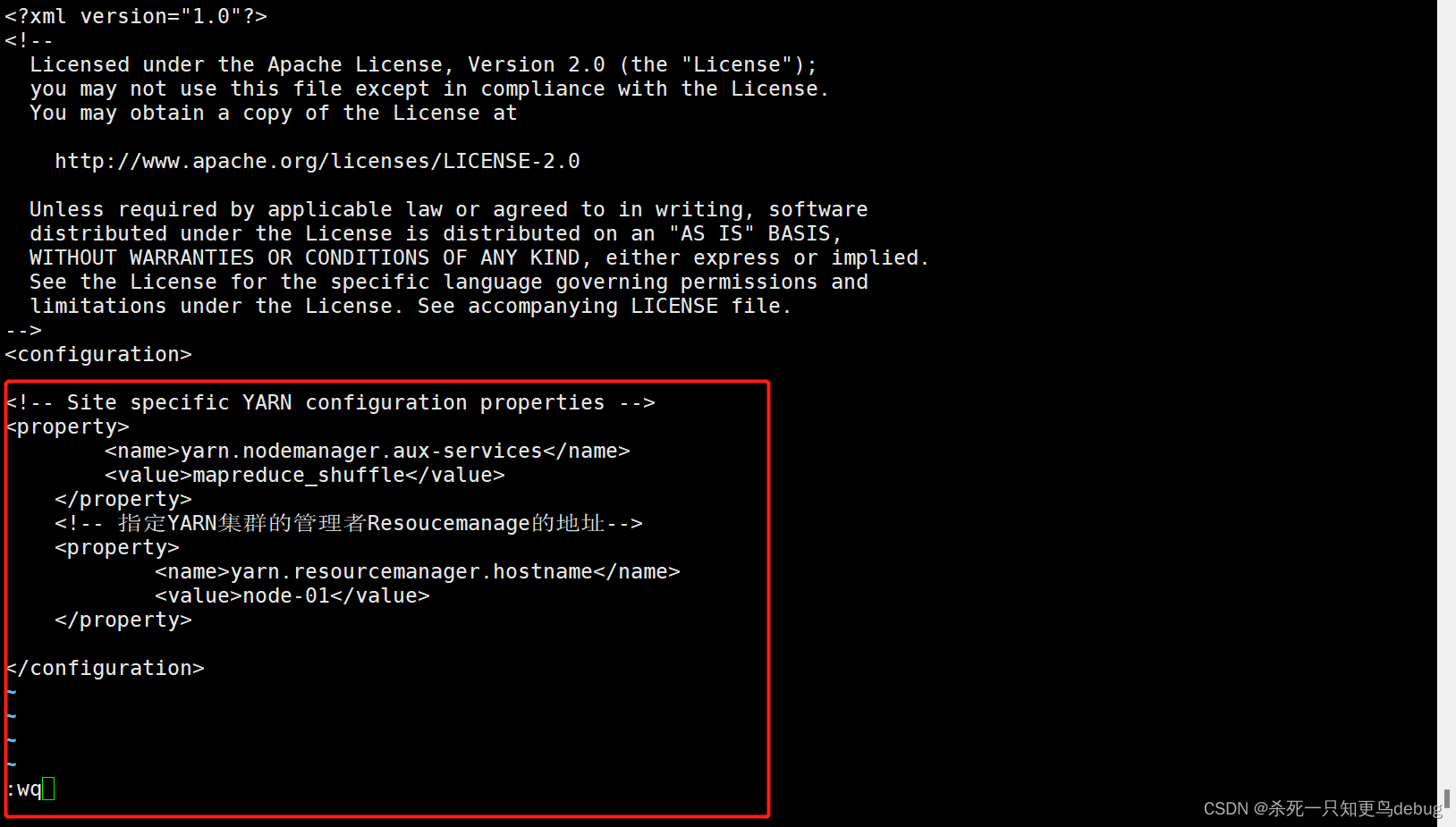
5、修改 slaves文件
slaves文件用于记录Hadoop集群的所有从节点(HDFSde DataNode 和 YARN 的 NodeManager所在主机)的主机名,用来配合一键启动脚本集群从节点(保证配置了SSH免密登录)。打开该配置文件,先删除里面的默认内容(localhost),然后配置如下内容
vi slaves
# 添加如下内容
node-01
node-02
node-03
2、克隆另外两台虚拟机及网络配置
2.1 克隆虚拟机
右键,选择管理,然后点击克隆
流程如下:
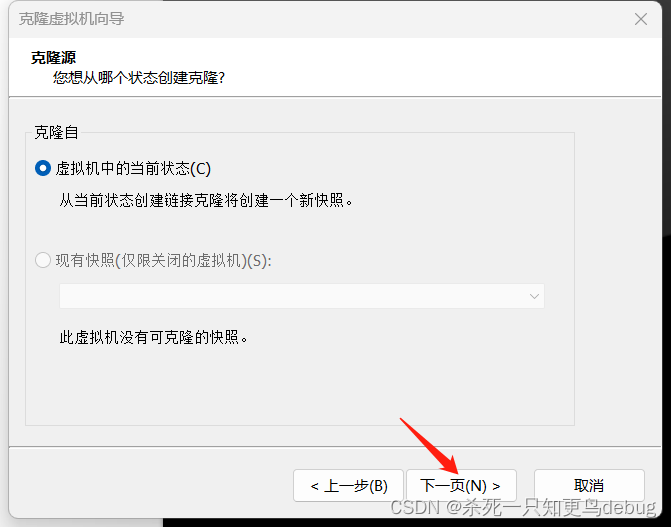
选择完整克隆,点击下一步
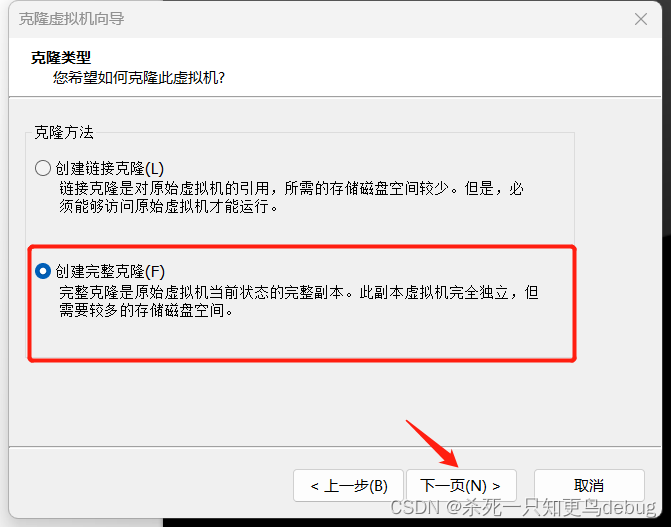
虚拟机名称和位置,自定义
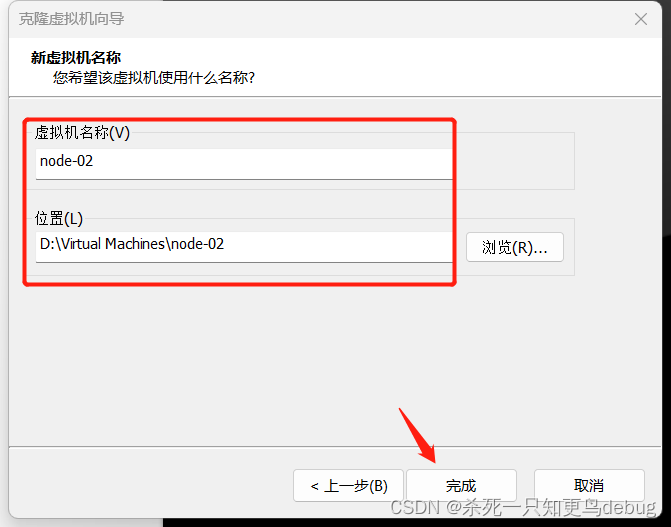
此时第二台虚拟机已经克隆完毕,接着我们再以相同的方式克隆第三台虚拟机node-03
2.2 克隆虚拟机网络配置
配置主机名
vi /etc/sysconfig/network
# 或者使用
hostnamectl set-hostname 主机名
主机名配置后,使用reboot指令进行重启才会生效
将新克隆的虚拟机主机名称分别设为 node-02,node-03
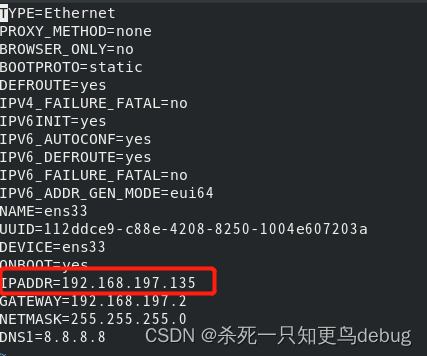
修改IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改IPADDR即可
node-02 对应 192.168.197.134
node-03 对应 192.168.197.135
3、设置node-01到其余两台虚拟机的SSH免密登录
1、在各个节点中生成密钥文件
$ cd ~/.ssh/ # 若没有该目录,执行ssh localhsot
$ ssh-keygen -t rsa # 生成密钥文件,提示输出加密信息,一直回车即可
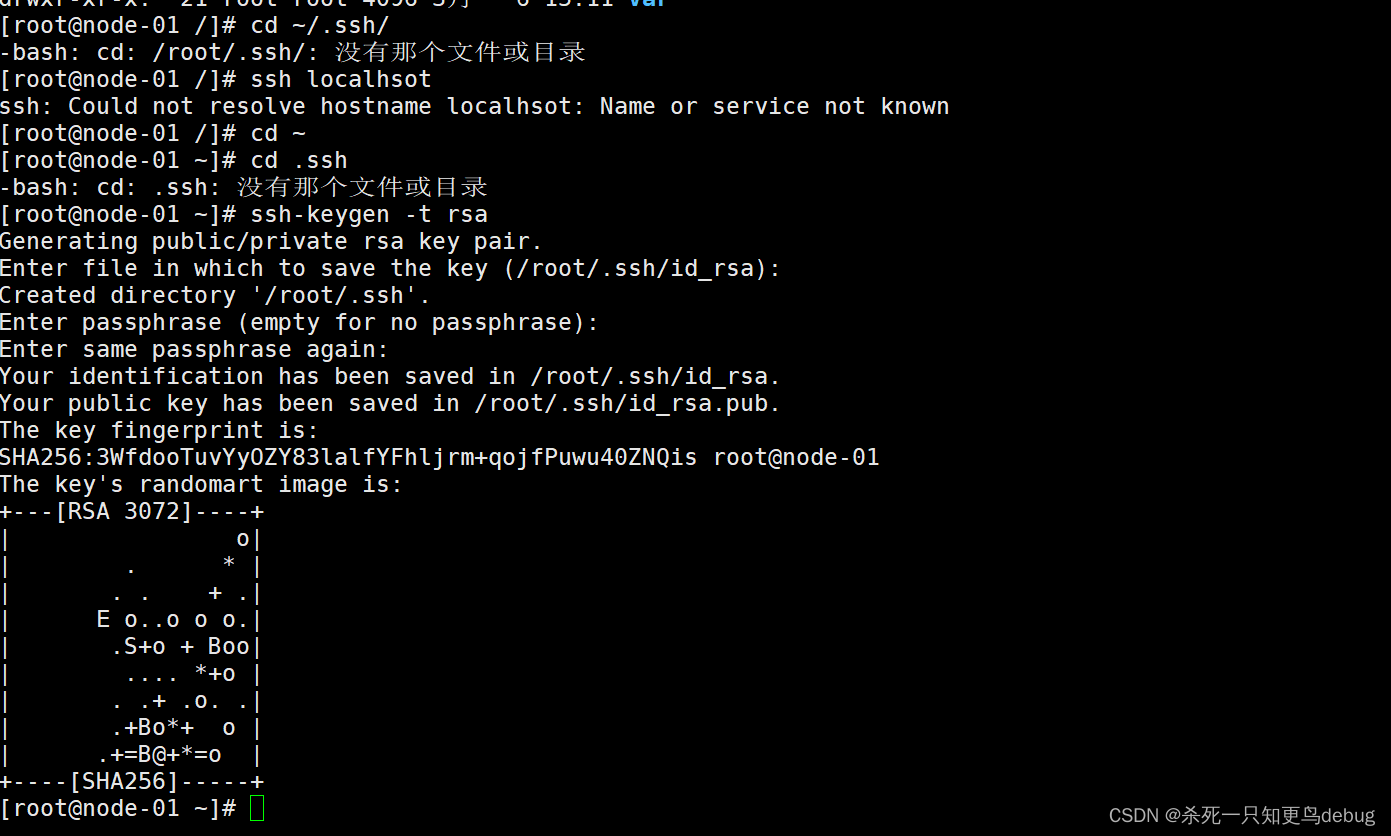
tip:如果提示说不存在ssh目录,直接执行 ssh-keygen -t rsa 即可
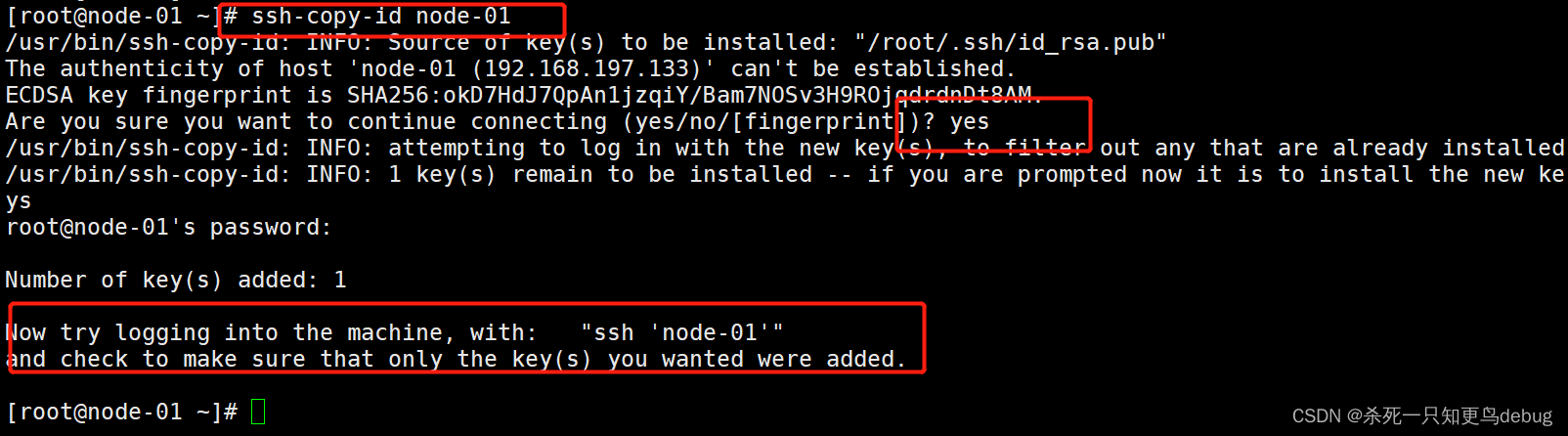
2、分别在三个节点中心以下命令,将公钥信息复制并追加到对方节点的授权文件authorized.key中
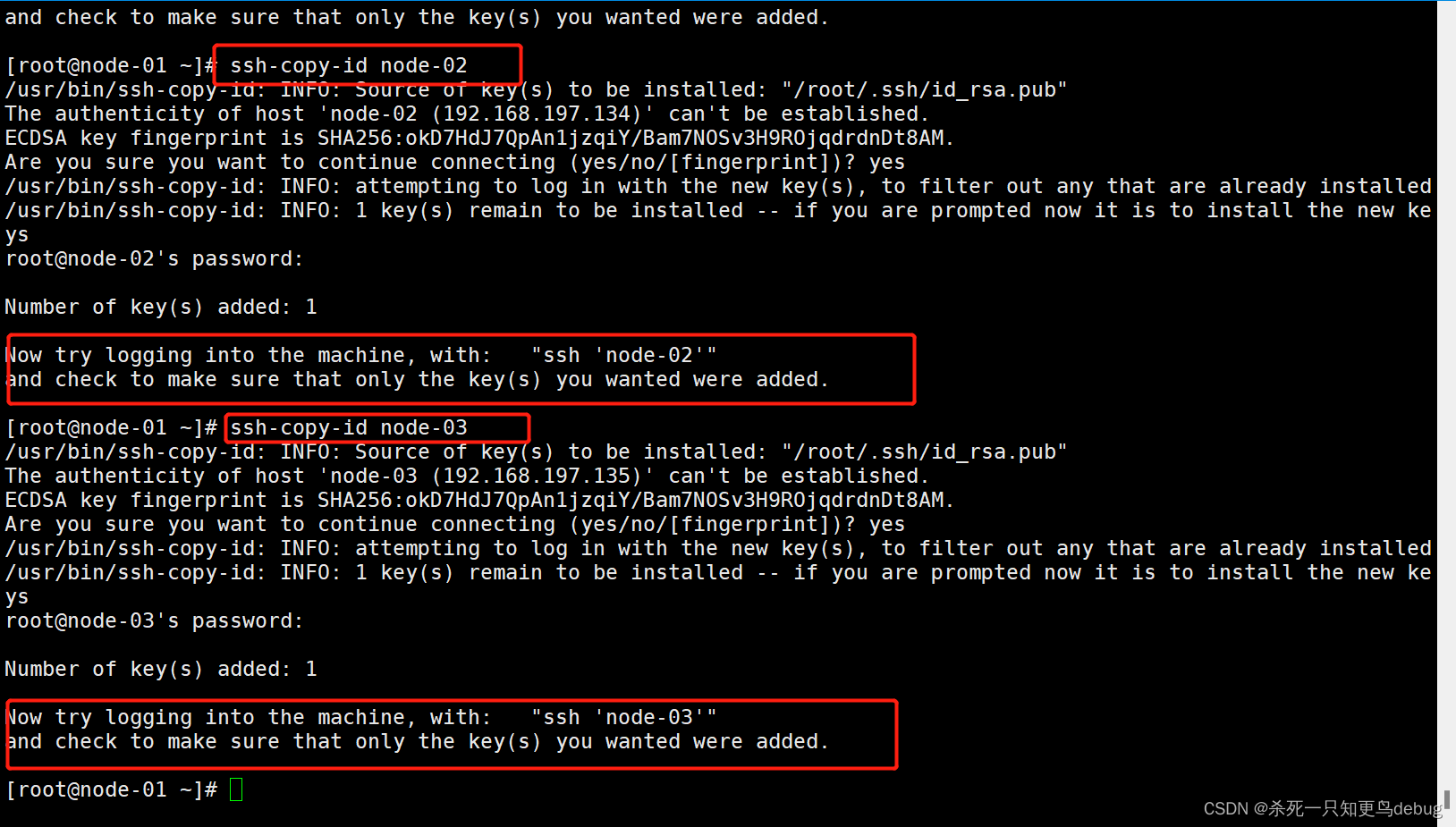
$ ssh-copy-id node-01
$ ssh-copy-id node-02
$ ssh-copy-id node-03
这里记得将每个虚拟机开启,然后在远程登录软件中进行免密配置
3、修改授权文件权限
$ chmod 700 ~/.ssh
$ chmod 600 ~/.ssh/authorized_keys
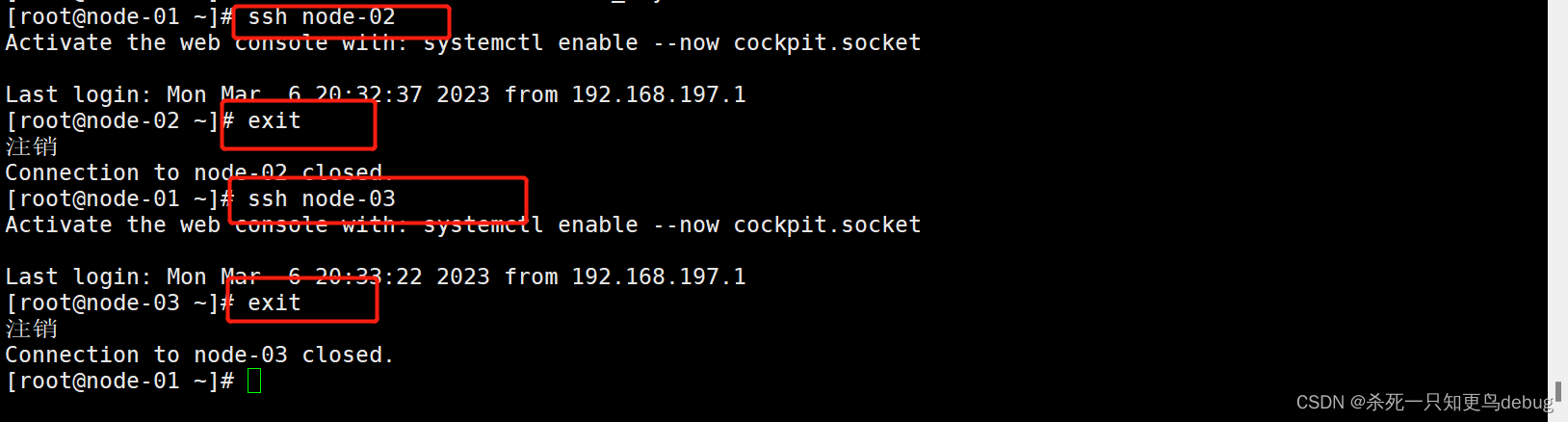
4、测试无密钥登陆
ssh node-02
exit
ssh node-03
exit
3、格式化NameNode
在主节点进行格式化即可(node-01),启动Hadoop之前需要格式化NameNode,格式化NameNode可以初始化HDFS文件系统的一些目录和文件,在node-01上执行:
# 必须在NameNode节点上进行format操作
$ hadoop namenode -format
5、启动hadoop
# 启动hadoop
$ start-all.sh
# 停止hadoop
$ stop-all.sh
# 查看节点角色
$ jps
启动 Hadoop 服务时权限异常,strat-all .sh
Starting namenodes on [node-01]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [node-02]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
如果出现没有定义HDFS_NAMENODE_USER
则在环境变量中在添加:
1.进入环境变量
vi ~/.bash_profile
2.添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

3.环境变量生效
source ~/.bash_profile
6、启动和关闭Hadoop集群
1.单节点逐个启动和关闭
主节点启动HDFS NameNode节点
hadoop-daemon.sh start namenode
从节点启动HDFS DataNode节点
hadoop-daemon.sh start datanode
主节点启动YARNResourceManager进程
yarn-daemon.sh start resourcemanager
从节点上启动YARN nodemanager进程
yarn-daemon.sh start nodemanager
规划节点node-02启动SecondaryNameNode进程
hadoop-daemon.sh start secondarynamenode
停止则使用stop替换掉start即可
2.脚本一键启动和关闭
start-dfs.sh
start-yarn.sh
这个需要在配置了slaves文件和SSH免密登录(双向的免密登录,即从节点的虚拟机也需要进行SSH免密配置)
6、通过UI查看Hadoop运行状态
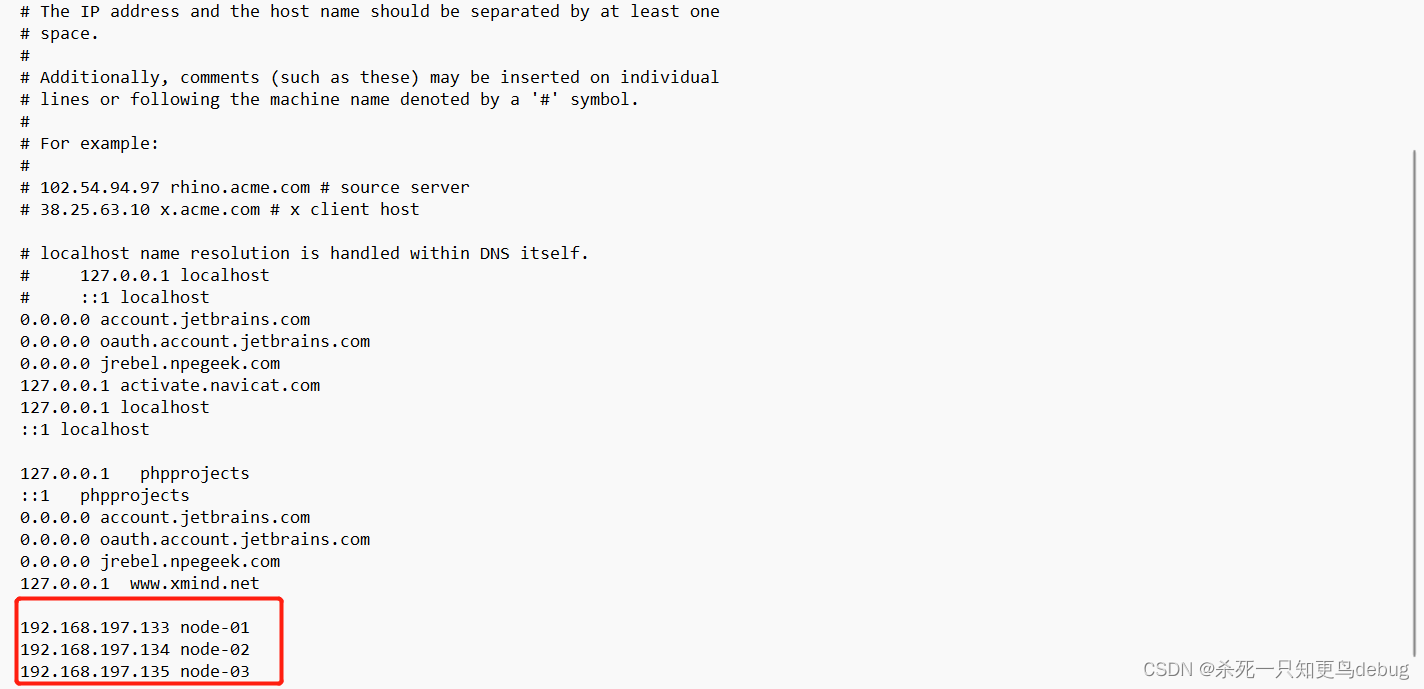
在windows下的C:\Windows\System32\drivers\etc中的hosts文件添加集群服务的IP映射
192.168.197.133 node-01
192.168.197.134 node-02
192.168.197.135 node-03
注意先关闭防火墙,然后再进行测试查看运行状态
一下指令需要对主从节点都进行更改:
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld
systemctl enable firewalld
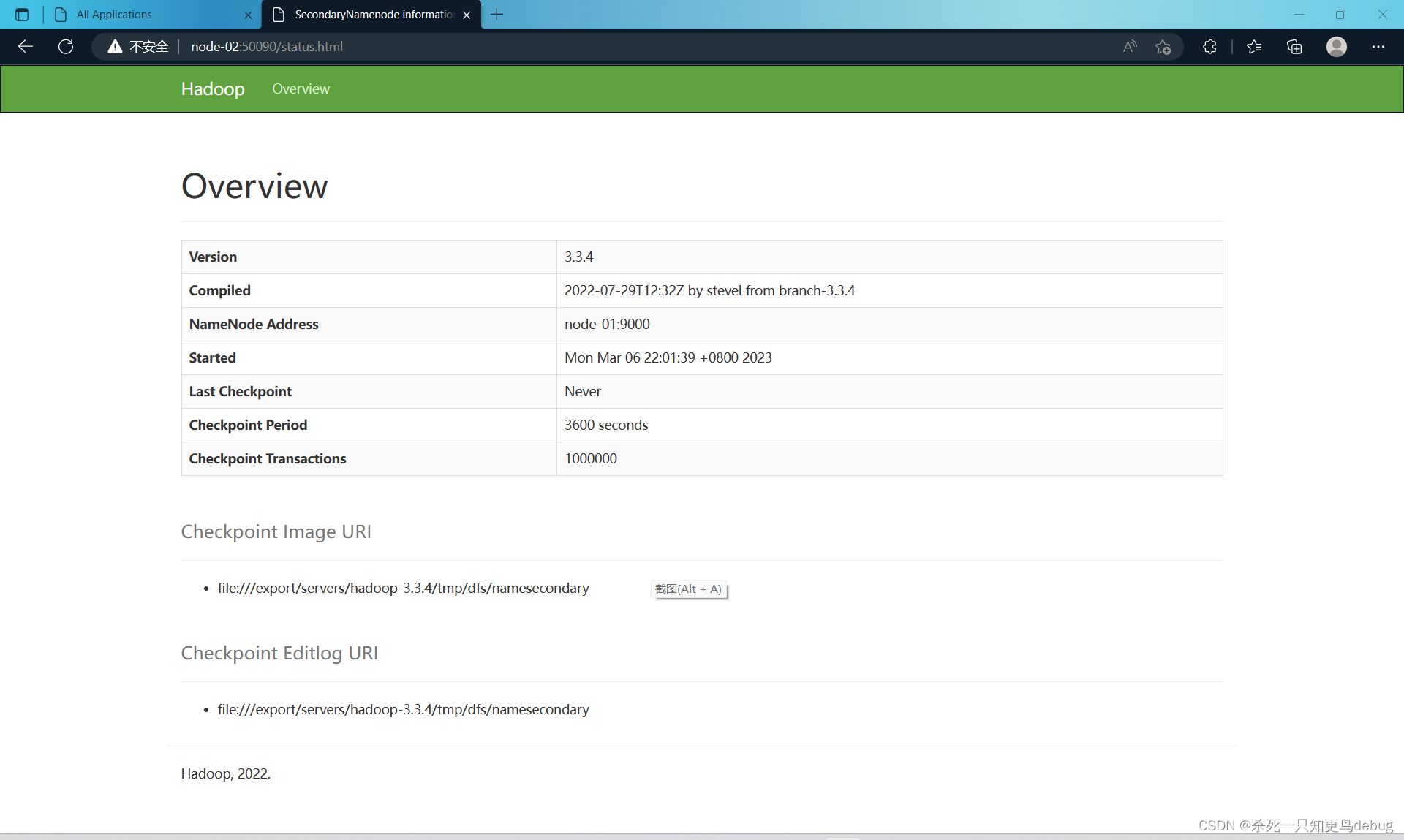
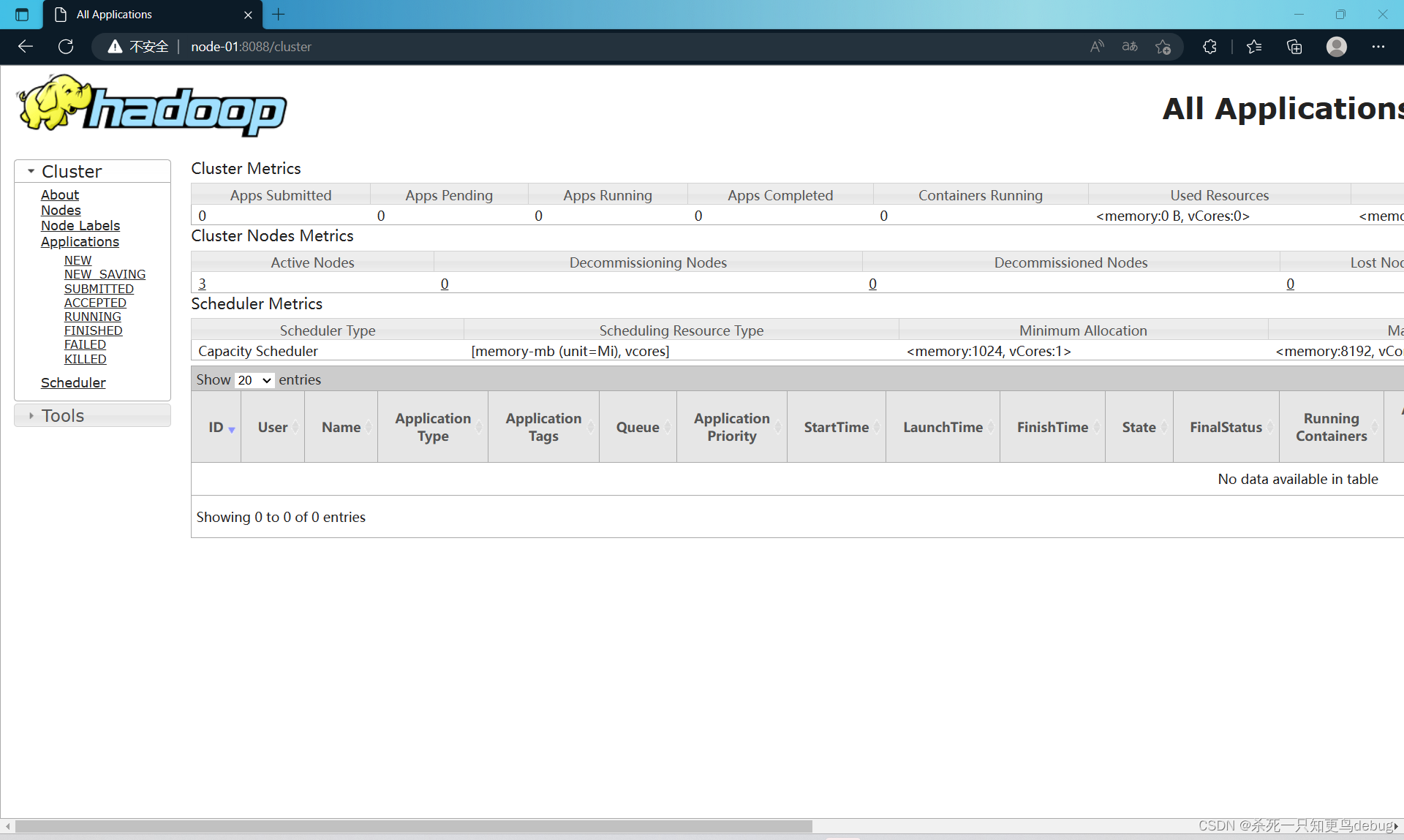
此时我们可以从windows的窗口进行查看了 http://node-01:50090(集群服务IP+端口号)和htpp://node-01:8088 查看YARN和HFDS的集群状态。
遇到的问题
以下纯属个人问题,已在文章中改了正确的配置:
这里我报错了
log4j:WARN No appenders could be found for logger (org.apache.hadoop.conf.Configuration).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "Thread-2" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Unexpected close tag </property>; expected </configuration>.
at [row,col,system-id]: [25,10,"file:/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml"]
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3092)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:3036)
at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2914)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2896)
at org.apache.hadoop.conf.Configuration.get(Configuration.java:1246)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1863)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1840)
at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183)
at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145)
at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)
Caused by: com.ctc.wstx.exc.WstxParsingException: Unexpected close tag </property>; expected </configuration>.
at [row,col,system-id]: [25,10,"file:/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml"]
at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:634)
at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:504)
at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:488)
at com.ctc.wstx.sr.BasicStreamReader.reportWrongEndElem(BasicStreamReader.java:3352)
at com.ctc.wstx.sr.BasicStreamReader.readEndElem(BasicStreamReader.java:3279)
at com.ctc.wstx.sr.BasicStreamReader.nextFromTree(BasicStreamReader.java:2900)
at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1121)
at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3396)
at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3182)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3075)
... 10 more
提示我说:
/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml 这里配置有问题去看看

多了一个poperty结束标记。。。
第二个问题 namenode格式化失败:java.lang.IllegalArgumentException: URI has an authority component:
java.lang.IllegalArgumentException: URI has an authority component
at java.io.File.<init>(File.java:423)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.getStorageDirectory(NNStorage.java:353)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournals(FSEditLog.java:293)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournalsForWrite(FSEditLog.java:264)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1257)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1726)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1834)
2023-03-06 20:47:32,697 INFO util.ExitUtil: Exiting with status 1: java.lang.IllegalArgumentException: URI has an authority component
解决方案,是core-site.xml中的一个配置好像不太一样,3.x和2.x不太一样
cd /export/servers/hadoop-3.3.4/etc/hadoop/
vi core-site.xml
我的配置是:
<configuration>
<property>
<!-- 配置Hadoop 的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>file:/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property>
<!-- 配置Hadoop的文件系统,由URI指定 -->
<name>fs.defaultFS</name>
<!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,
没配置过的话,写完整的IP地址即可 192.168.197.133
-->
<value>hdfs://node-01:9000</value>
</property>
</configuration>
正确的配置应为:
<configuration>
<property>
<!-- 配置Hadoop 的临时目录 -->
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property>
<!-- 配置Hadoop的文件系统,由URI指定 -->
<name>fs.defaultFS</name>
<!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,
没配置过的话,写完整的IP地址即可 192.168.197.133
-->
<value>hdfs://node-01:9000</value>
</property>
</configuration>