RoBERTa是的BERT的常用变体,出自Facebook的RoBERTa: A Robustly Optimized BERT Pretraining Approach。来自Facebook的作者根据BERT训练不足的缺点提出了更有效的预训练方法,并发布了具有更强鲁棒性的BERT:RoBERTa。
RoBERTa通过以下四个方面改变来改善BERT的预训练:在MLM任务中使用动态掩码而不是静态掩码;移除NSP任务,仅使用MLM任务;通过更大的批数据进行训练;使用BBPE作为分词器。
1 动态掩码
RoBERTa使用动态掩码。BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,也就是静态mask的方式。RoBERTa的训练过程中使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新随机mask,其中每个句子被mask的token不同:即拥有不同的masked tokens。
![]()
MASK结果如下所示:
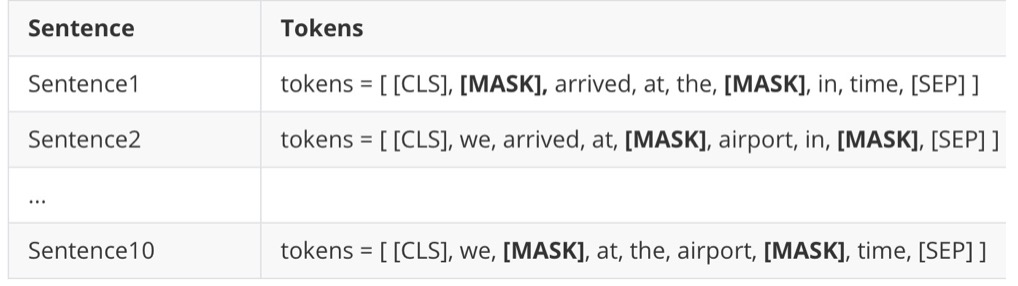
在模型训练时,对于每个epoch,使用不同标记被[MASK]的句子喂给模型。这样模型只会在训练10个epoch之后看到具有同样掩码标记的句子。比如,句子1会被epoch1,epoch11,epoch21和epoch31看到。这样,我们使用动态掩码而不是静态掩码去训练RoBERTa模型。
2 移除NSP任务
为了证明可以移除NSP任务,论文进行了以下对比实验:
1.SEGMENT-PAIR+NSP: NSP任务保留。每个输入是段落(segment),每个片段由多个自然句子组成,最大长度为512;
2.SENTENCE-PAIR+NSP:NSP任务保留。每个输入是一对自然句子,每个自然句子可是一个文本的连续部分,也可以是不同文本。因为这些输入显然少于512,因此增加了批大小,让一个批次总的单词数和SEGMENT-PAIR+NSP差不多。同时保留NSP loss;
3.FULL-SENTENCES: 每个输入都包含从一个或多个文档中连续采样的完整句子,因此总长度差不多512个单词。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界标记。移除NSP loss;
4.DOC-SENTENCES: 每个输入都包含从一个连续采样的完整句子,输入格式和FULL-SENTENCES类似,除了它们不会跨域文档边界。在文档末尾附近采样的输入可能短于 512 个单词,所以动态增加了批大小让单词总数和FULL-SENTENCES类似。移除NSP loss;
实验结果如下图所示:

从实验结果看,BERT在FULL-SENTENCES和DOC-SENTENCES设定中表现的更好,这两者都剔除了NSP任务。对比FULL-SENTENCES和DOC-SENTENCES,DOC-SENTENCES只从一篇文档中采样,此种设定的表现比FULL-SENTENCES在多篇文档中采样要好。但在RoBERTa中,作者使用了FULL-SENTENCES,因为DOC-SENTENCES导致批大小变化很大。
3 更大规模训练数据
3-3-1 训练语料
BERT的预训练语料是 BOOKCORPUS+English WIKIPEDIA的16GB语料。RoBERT除了在Toronto BookCorpus和英文维基百科上进行训练,还在CC-News(Common Crawl-News)数据集、Open WebText和Stories(Common Crawl的子集)上进行训练。RoBERT模型在5个数据集上进行预训练,这5个数据集总大小为160G。
3-3-2 batch size
BERT预训练的batch size为256,训练了1M步。而RoBERTa则使用了更大的batch size,训练RoBERTa时采样了更大的批大小,达到了8000,训练了300000步。在同样的批大小上,也训练了一个更长训练步的版本,有500000步。训练一个更大的批大小可以增加训练速度同时也可以优化模型的表现。
4 BBPE作为分词器
BERT使用WordPiece分词器。WordPicce分词器类似于BPE分词器,它基于符号对的概率还不是频率来合并符号对。
而RoBERTa使用BBPE作为分词器。BBPE基于字节级序列,先将文本转换为字节级序列,然后应用BPE算法根据字节级符号对构建词表,BERT使用30000大小的词表,RoBERTa使用大约50000大小的词表。
5 Roberta使用
#导入模块
from transformers import RobertaConfig, RobertaModel, RobertaTokenizer
#加载模型
Robert_model = model = RobertaModel.from_pretrained('roberta-base')
#加载分词器
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
RobertaConfig {
"_name_or_path": "roberta-base",
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.10.3",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 50265
}Reference:
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2