背景
需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。 数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
2.数据库分表
概念:将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务, 但是随着业务的不断发展,同一个业务如果达到瓶颈,比如淘宝。如果全部都放在一张表中那么运算速度就会很慢,所以需要拆分
单表数据拆分的方式
垂直分表
水平分表
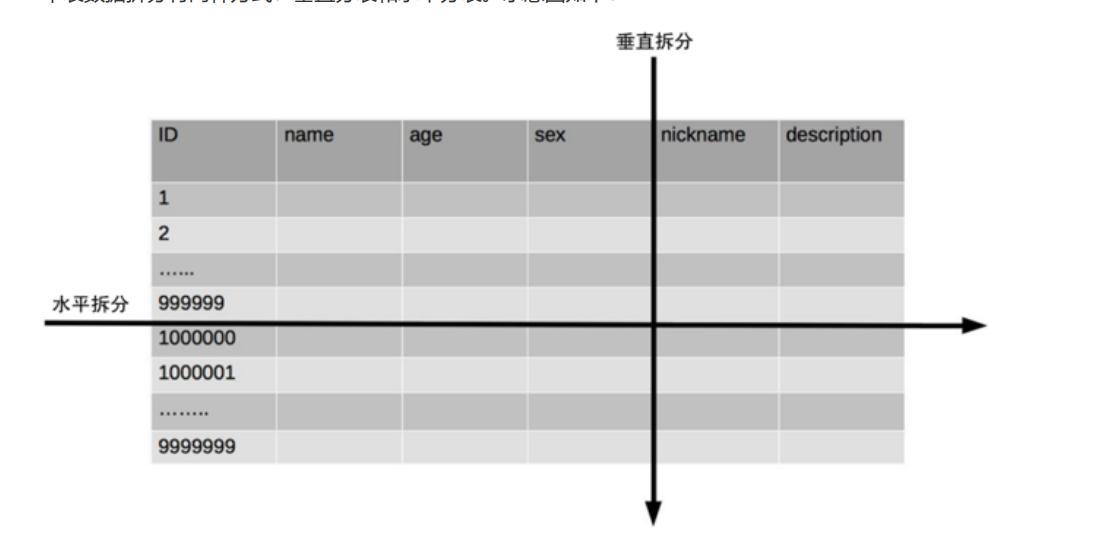
2.1垂直分表
概念:垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。意思就是将那些不经常用的字段,例如(描述,个性签名,留言,星座等等)分成出去,将少部分经常用的数据保留,以便提高性能
水平分表
2.2水平分表
方式一:根据ID的范围来分段
例如按照1-1000000的范围大小进行分段,1-999999为表1,1000000-1999999为表2,依次类推
复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会 导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适 的分段大小。 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万, 只需要增加新的表就可以了,原有的数据不需要动。 缺点:分布不均匀。假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1 条,而 另外一个分段实际存储的数据量有 1000 万条。
方式二:取模分表
按照X%10来进行划分数据的分类,例如x%10==1;为表1,x%10==2;为表二,依次类推
复杂点:初始表数量的确定。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。 优点:表分布比较均匀。 缺点:扩充新的表很麻烦,所有数据都要重分布。
3.雪花算法
背景
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的 主键的有序性。
结构图
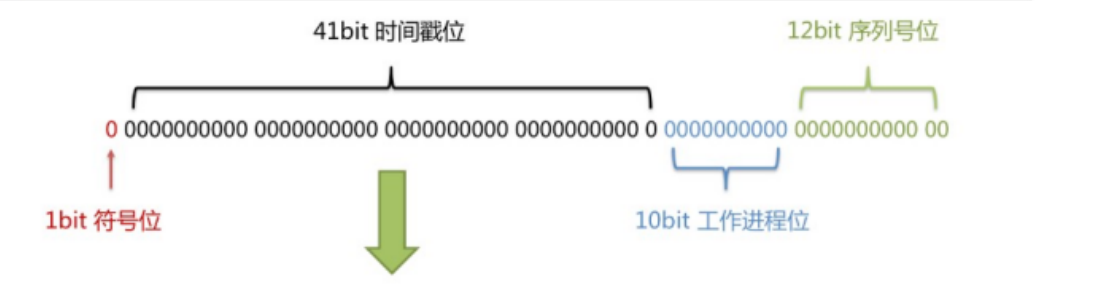
核心思想
长度共64位(long类型)。
第一位为符号位(正数是0,负数是1)
1-42位位时间差,时间戳的概念,相当于69.73年
13-53位(5个数据中心,5个机器ID,可以部署在1024个节点)
64-76位为该区域的流水号
优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
总结:
随着用户量的增加,数据信息的迭代,导致空间不足的,所以我必须想办法解决
水平和垂直分表可以解决问题,但都有缺点
雪花算法可以更好解决分表带来的问题,并且有规律的展现
大厂现在都用雪花算法生成ID