目录
1.1张量的数据类型
1.2 张量的生成
1.3 张量操作
1.4 张量的计算
一、张量
在高等数学中,单独的一个数是标量,而有序排列的一组数字是一个向量(例如一个数组),向量组可以构成矩阵。向量是一维的,而矩阵是二维的,一个二维数组可以构成一个矩阵,但是如果该数组的维数超过2维,该数组可以构成张量(Tensor)。
但是在pytorch中,张量被封装成一种数据结构,并且一个标量、一个向量、一个数组,甚至更高维的数组在Pytorch中都被封装成张量Tensor进行运算。pytorch中的张量和Numpy库中的数组非常相似,在使用时会将两者相互转换。在深度学习中,基于pytorch的相关计算和优化都是在tensor的基础之上完成的。因此,我们很有必要掌握Pytorch中的Tesor运算。
1.1张量的数据类型
在pytorch中,可以用cpu对张量进行运算,也可以用GPU对张量进行运算,但两者的运算方式不同,速度也有差异,因此分为cpu张量与gpu张量。它们的数据类型如下表所示:
| 数据类型 | dtype | CPU | GPU |
| 32位浮点型 | torch.float32或者 torch.float | torch.FloatTensor | torch.cuda.FloatTensor |
| 64位浮点型 | torch.float64或者torch.double | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16位浮点型 | torch.float16或者torch.half | torch.HalfTensor | torch.cuda.HalfTensor |
| 8位无符号整型 | torch.uint8 | torch.ByteTensor | torch.cuda.ByteTensor |
| 8位有符号整型 | torch.int8 | torch.CharTensor | torch.cuda.CharTensor |
| 16位有符号整型 | torch.int16或者torch.short | torch.ShortTensor | torch.cuda.ShortTensor |
| 32位有符号整型 | torch.int32或者torch.int | torch.IntTensor | torch.cuda.IntTensor |
| 64位有符号整型 | torch.int64或者torch.long | torch.LongTensor | torch.cuda.LongTensor |
值得注意的是在pytorch中,Tensor默认的数据类型是32位浮点型(torch.FloatTensor),但是可以通过
torch.set_default_tensor_type()#该函数仅支持设置浮点型的数据类型设置张量默认的数据类型,并通过
torch.get_default_dtype()查看当前默认的数据类型
我们看下面一个简单的例子
import torch;
print(torch.cuda.is_available())
print(torch.get_default_dtype())#查看当前数据类型
torch.set_default_tensor_type(torch.HalfTensor)#修改数据类型为16位浮点型
print(torch.get_default_dtype())#再次查看当前数据类型

在上面的例子中,我们演示了如何调用pytorch中的函数查看、修改默认数据类型,但是这种修改是全局的,如何我们想要把一个张量a(32位浮点型)转换为16位有符号整型但是又不影响其他张量的数据类型怎么办呢?我们接着看下面一个例子
import torch;
torch.set_default_tensor_type(torch.FloatTensor);
a=torch.tensor([[1.2,2],[2,3]])
print(a.dtype)# .dtype获取张量数据类型
print(a.int().dtype)#a.int() 将张量a的数据类型修改为32位有符号整型
类似的张量数据类型修改方法还有
a.long() ---转换为64位有符号整型
a.float()---转换为32位浮点型
1.2 张量的生成
在pytorch中有多种方式生成一个张量,下面通过例子学习:
(1)使用 torch.tensor()生成张量
import torch;
a=torch.Tensor([[1.2,4,5,6],[1,4,2,4]])
print(a)
print(a.shape)#张量的维度可以通过 .shape查看
print(a.size()) #张量的形状大小可以通过调用size()方法查看
print(a.numel())#张量中包含的元素个数通过调用numel()方法查看 而且使用torch.tensor()函数时,可以使用参数dtype来指定张量的数据类型,使用参数requires_grad来指定张量是否需要计算梯度。
而且使用torch.tensor()函数时,可以使用参数dtype来指定张量的数据类型,使用参数requires_grad来指定张量是否需要计算梯度。
import torch;
a=torch.tensor((1,2,4),dtype=torch.float64,requires_grad=True)
print(a)
b=a.pow(3).sum()#对张量a计算sum(a^3)在每个元素上的梯度大小
b.backward()
print(a.grad)
注意:只有浮点型才可以计算梯度,其他类型的数据不可计算梯度。
(2)使用 torch.Tensor()生成张量
在pytorch中也可以使用torch.Tensor()生成张量,并且还可以指定张量的形状。
import torch;
a=torch.Tensor((1,2,4))#根据具体数据生成张量
b=torch.Tensor(2,2)#生成指定形状的张量
c=torch.ones_like(a)#生成与张量a维度相同、性质相似、值全是1的张量
d=torch.zeros_like(a)#生成与张量a维度相同,值全是0的张量
e=torch.rand_like(a)#生成与张量a维度相同,值为随机数的张量
print(a)
print(b)
print(c)
print(d)
print(e)

针对已经生成的张量还可以使用torch.new_**()系列函数生成新的张量,具体看下面的例子
import torch;
a=torch.Tensor((1,2,4))#根据具体数据生成张量
data=[[1,3,5],[3,4,6]]
b=a.new_tensor(data)#创建一个类型相似但尺寸不同的张量
print(b)
c=a.new_full((3,2),fill_value=1)#创建一个新的张量:3*3 使用1填充的张量
print(c)
d=a.new_zeros((3,3))#创建一个新的张量:3*3 值全是0
print(d)
e=a.new_empty((3,3))#创建一个新的张量:3*3 空张量
print(e)
f=a.new_ones((3,3))#创建一个新的张量:3*3 全是1
print(f)

(3)Numpy数组与pytorch相互转化
import torch
import numpy as np
a=np.ones((3,4))
b=torch.as_tensor(a)#该函数可以将numpy数组转换为张量,并且转换后的默认数据类型为64位浮点型
print(b)
c=torch.from_numpy(a)#该函数可以将numpy数组转换为张量,并且转换后的默认数据类型为64位浮点型
print(c)
d=torch.Tensor((1,4,7,9))
print(d.numpy())#使用torch.numpy()函数即可转化为numpy数组

(4)随机数生成张量
在pytorch中还可以通过相关随机数来生成张量,并且可以指定生成函数的分布函数。
import torch
torch.manual_seed(123)#使用该函数指定生成随机数的种子
a=torch.normal(mean= 0.0,std=torch.tensor(1.0))#该语句表示生成服从正态分布(0,1)的随机数
print(a)
'''
在torch.normal()函数中,通过mean参数指定随机数的均值,std参数指定随机数的标准差
如果mean参数和std参数都只有一个元素则只会生成一个随机数
如果mean参数和std参数有多个值,则可以生成多个随机数
'''
b=torch.normal(mean=0.0,std=torch.arange(1,5.0))
print(b)
"""
上面这个例子,每个随机数的分布均值0,标准差则分别为1、2、3、4
"""
c=torch.normal(mean=torch.arange(1,4.0),std=torch.arange(1,4.0))
print(c)
"""
上面的例子中,每个随机数服从的分布均值分别为1、2、3 分布的标准差也为1、2、3
""" 在pytorch中还有其他函数生成随机数张量
在pytorch中还有其他函数生成随机数张量
a=torch.rand(2,3)#torch.rand()函数:在区间0-1上生成服从均匀分布的张量
print(a)
"""
torch.rand_like函数:根据其他张量维度,生成与维度相同的随机数张量
"""
b=torch.ones(3,3)
c=torch.rand_like(b)
print(c)
"""
torch.randn()函数,生成服从标准正态分布的随机数张量
"""
d=torch.randn(4,4)
print(d)
"""
torch.randperm(n)函数,则可以将0-n(包含0不包含n)之间的整数进行随机排序后输出
"""
print(torch.randperm(10))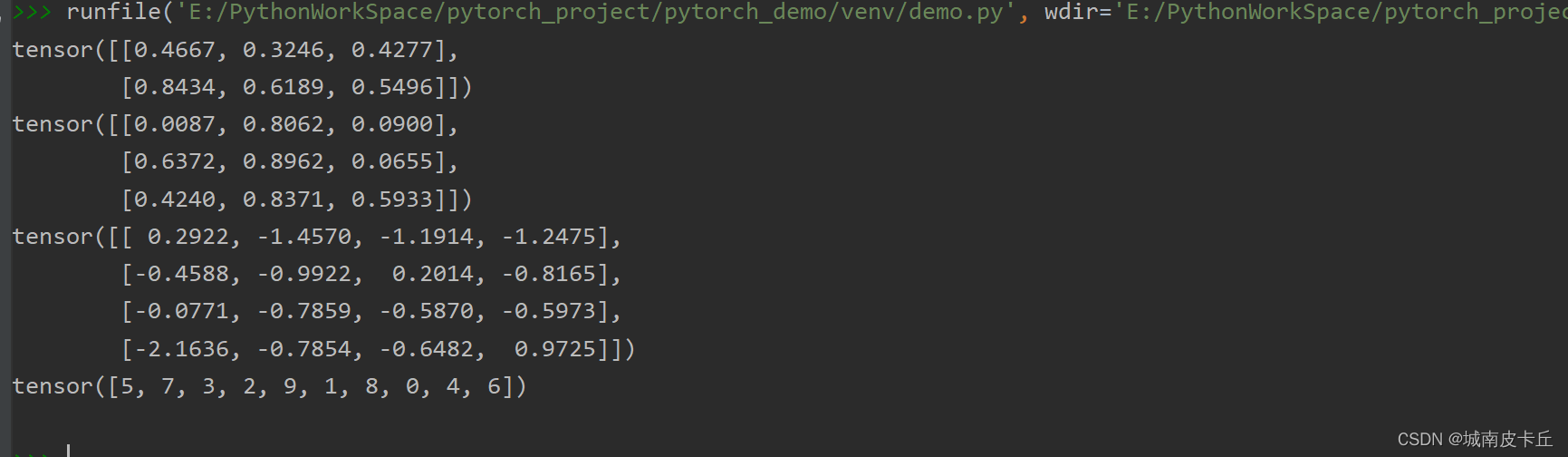
(5)其他函数生成特殊张量
"""
torch.arange()函数:参数start指定开始,参数end指定结束,参数step指定步长
"""
a=torch.arange(start=0,end=10,step=2)
print(a)
"""
torch.linspace()函数在指定范围内生成固定数量的等间隔张量
"""
b=torch.linspace(start=0,end=10,steps=5)
print(b)
"""
torch.logspace():生成以对数为间隔的张量
"""
c=torch.logspace(start=0,end=10,steps=5)
#输出结果10**(torch.linspace(start=0,end=10,steps=5))等价
d=10**(torch.linspace(start=0,end=10,steps=5))
print(c)
print(d)

pytorch中还包含许多预定义的函数,用于生成特定的张量。
| 函数 | 描述 |
| torch.zeros(2,2) | 2*2的全是0的张量 |
| torch.eye(2) | 2*2的单位张量 |
| torch.ones(2,2) | 2*2全是1的张量 |
| torch.empty(2,2) | 2*2的空向量 |
| torch.full((2,2),fill_value=0.5) | 2*2用0.5填充的张量 |
1.3 张量操作
上面我们介绍了张量的操作方法,在本节我们将介绍 如何进行张量形状改变、获取或者改变张量中的元素、对张量进行拼接和拆分等操作。
(1)改变张量的形状
"""
tensor.reshape()函数:设置张量的形状大小
"""
a=torch.arange(start=0,end=12.0,step=2)
b=a.reshape(2,3)
print(b)
"""
tensor.resize_()方法:针对输入的形状大小对张量形状进行修改
"""
c=a.resize_(2,3)
print(c)
"""
A.resize_as_(B):将张量A的形状尺寸设置为跟B相同的形状大小
"""
x=torch.linspace(start=0,end=10,steps=6)
# print(x)
y=x.resize_as_(b)
print(y)
上面的方法都是对张量的形状进行修改,如果我们想要对张量的维度进行修改,比如2维度张量变成3维度,或者3维度张量降低至2维度,该如何操作呢?
"""
torch.unsqueeze()函数:在张量的指定维度插入新的维度得到维度提升的张量
"""
a=torch.arange(12.0).reshape(3,4)
print(a.shape)#a为3*4的二维张量
b=torch.unsqueeze(a,dim=1)
print(b)
print(b.shape)#b为3*1*4的三维张量
"""
torch.squeeze()函数:移除所有维度为1的维度
"""
c=torch.squeeze(b)
print(c)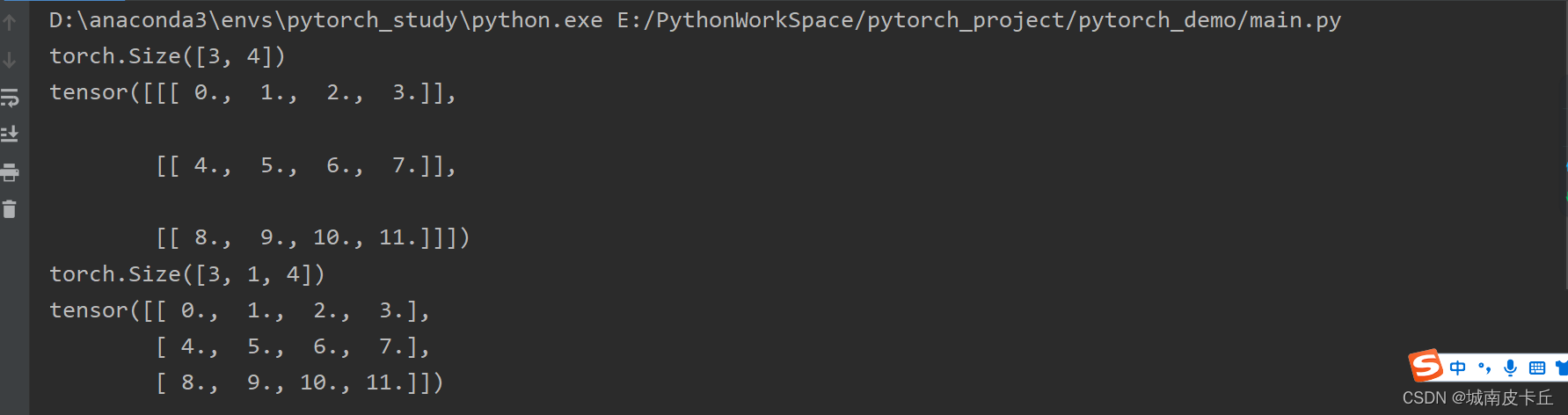
还可以通过调用以下函数对张量维度进行操作。看下面的例子。
"""
pytorch中还可以使用expand()方法对张量的维度进行拓展,从而对张量的形状大小进行修改
"""
print("------------------------")
a=torch.arange(4)
b=a.expand(3,-1)
print(b)#e为3*4的二维张量
"""
A.expand_as(C)方法:将张量A根据张量C的形状大小进行拓展,得到新的张量
"""
c=torch.tensor((2,4,6,7))
d=c.expand_as(b)
print(d)
"""
repeat()方法:将张量看做一个整体,然后根据指定的形状进行重复的填充,得到新的张量
"""
e=d.repeat(1,3,2)
print(e)
(2)获取张量的元素
首先看一下通过张量元素切片和索引的方法来获取张量中的某些元素
a=torch.arange(12).reshape(3,4)
print(a)
print(a[0])
print(a[1])
print(a[0:2,0:2])#获取两行两列元素
print(a[a>5])#获取a中大于5的元素
b=-a
print(torch.where(a>5,a,b))#当a>5为真,返回a对应位置的值;为假时返回b对应位置的值
"""
torch.tril()函数:获取张量下三角部分的内容而将上三角部分的元素设置为0
torch.triu()函数:获取张量上三角的部分而将下三角部分的元素设置为0
torch.diag()函数:获取矩阵张量的对角线元素
"""
a=torch.arange(9).reshape(3,3)
print(a)
print(torch.tril(a,diagonal=0))
print(torch.triu(a,diagonal=0))
print(torch.diag(a,diagonal=0))
print(torch.diag(a,diagonal=1))
print(torch.diag(a,diagonal=-1))
#通过diagonal参数来控制获取的对角线元素,相对于对角线的位移
(3)拼接和拆分
在pytorch中提供了将多个张量拼接为一个张量,将一个张量拆分为几个小的张量。
"""
torch.cat()、torch.stack()函数:将多个张量按照指定的维度进行拼接
"""
a=torch.arange(3)
b=torch.arange(3)
print(torch.cat((a,b),dim=0))
print(torch.stack((a,b),dim=1))
print(torch.stack((a,b),dim=0)) 
下面看一下张量拆分的例子:
a=torch.arange(12).reshape(3,4)
b1,b2=torch.chunk(a,2,dim=0)#将张量a在维度0上拆分为2个张量
print(b1)
print(b2)
c1,c2=torch.chunk(a,2,dim=1)
print(c1)
print(c2)
在pytorch中,torch.chunk()函数可以将张量分割为特定数量的块;torch.split()函数不仅可以将张量分割为特定数量的块,还可以指定每个块的大小。
a=torch.arange(12).reshape(3,4)
print(a)
b1,b2=torch.split(a,[1,3],dim=1)#将张量分为2块,并指定数量大小分别为1、3
print(b1)
print(b2)
1.4 张量的计算
张量计算主要包括张量之间的大小比较、张量的基本运算(元素之间的运算和矩阵之间的运算)、张量与统计相关的运算(排序、最大值、最小值)
(1)张量比较大小
torch.eq()函数:逐个判断张量中的每一个元素是否对应相等
torch.equal()函数:判断两个张量是否具有相同的形状和元素
import torch
a=torch.tensor([0,1,2,3,4])
b=torch.arange(5)
c=torch.Tensor([1,1,9,3,3])
print(torch.eq(a,b))
print(torch.eq(a,c))#注意:只能跟形状相同的张量比较,否则报错
print(torch.equal(a,b))
print(torch.equal(b,c))#可以与形状不相同的张量比较但直接返回False,与形状相同的张量比较,比较的是逐个元素是否相等
torch.ge()函数:逐个元素比较是否大于等于
torch.le()函数:逐个元素比较是否小于等于
torch.gt()函数:逐个元素比较大于
torch.lt()函数:逐个元素比较小于
注意:以上四个函数使用的前提是张量的形状相同,否则报错
import torch
a=torch.tensor([0,1,2,3,4])
b=torch.arange(5)
c=torch.Tensor([1,1,9,3,5])
print(torch.ge(a,b))
print(torch.ge(a,c))#注意:只能跟形状相同的张量比较,否则报错
print(torch.gt(a,b))
print(torch.gt(c,b))
print(torch.le(a,c))
print(torch.lt(a,c))
torch.ne()函数:逐个比较元素是否不相等(张量形状必须相同)
torch.isnan()函数:判断张量中的元素是否为空缺值
import torch
a=torch.tensor([0,1,2,3,4])
b=torch.arange(5)
c=torch.Tensor([1,1,9,3,6])
print(torch.ne(a,b))
print(torch.ne(a,c))
print(torch.isnan(torch.tensor([1,float('nan'),2])))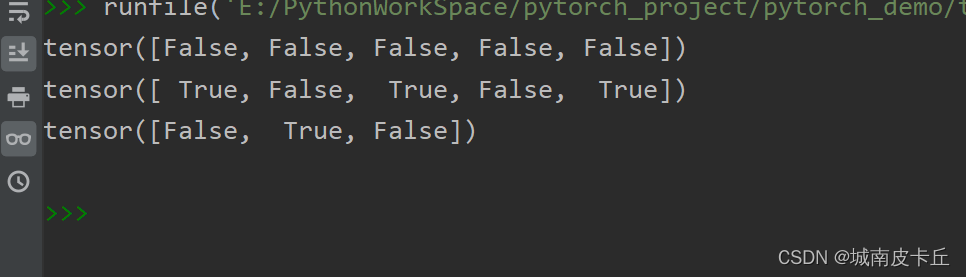
torch.allclose()函数:比较两个元素是否接近,比较A和B是否接近的公式为:
![]()
a=torch.tensor([2.0])
b=torch.tensor([2.4])
print(torch.allclose(a,b,rtol=0.4,atol=0.02,equal_nan=False))
c=torch.tensor(float("nan"))
print(torch.allclose(c,c,equal_nan=False))
print(torch.allclose(c,c,equal_nan=True))
(2)基本运算
张量的基本运算包括加减乘除四则运算、幂运算、平方根、对数、矩阵相乘、矩阵的转置、矩阵的秩等。
张量的加减乘除四则运算,示例如下:
a=torch.arange(6).reshape(2,3)
b=torch.linspace(10,20,steps=6).reshape(2,3)
print(a)
print(b)
print(a*b)#逐个元素相乘
print(a/b)#逐个元素相除
print(a+b)#逐个元素相加
print(a-b)#逐个元素相减
print(b//a)#逐个元素整除
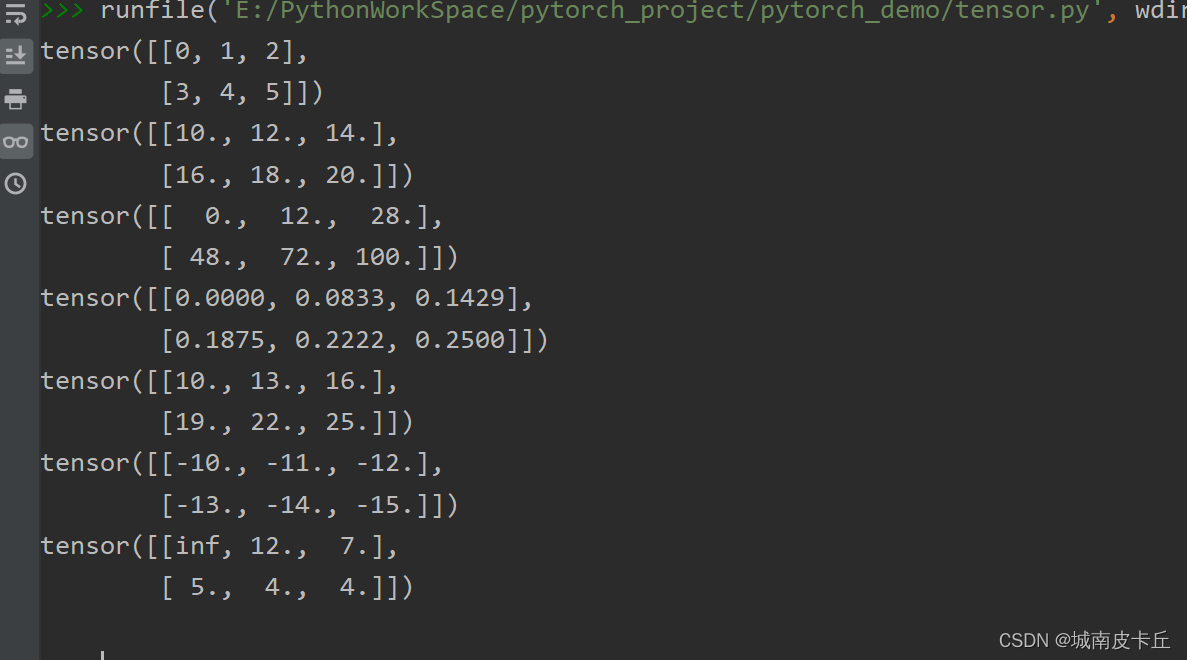
张量的幂运算、指数运算。示例如下:
a=torch.arange(6).reshape(2,3)
b=torch.linspace(10,20,steps=6).reshape(2,3)
print(a)
#幂运算
print("幂运算-------------------")
print(torch.pow(a,2))
print(a**2)
print(torch.sqrt(a))#平方根运算
print(torch.rsqrt(a))#平方根的倒数运算
print(1/(a**0.5))
#指数运算:以e为底数
print("指数运算------------")
print(torch.exp(a))
#对数运算以10为底数
print("对数运算---------")
print(torch.log(a))tensor([[0, 1, 2],
[3, 4, 5]])
幂运算-------------------
tensor([[ 0, 1, 4],
[ 9, 16, 25]])
tensor([[ 0, 1, 4],
[ 9, 16, 25]])
tensor([[0.0000, 1.0000, 1.4142],
[1.7321, 2.0000, 2.2361]])
tensor([[ inf, 1.0000, 0.7071],
[0.5774, 0.5000, 0.4472]])
tensor([[ inf, 1.0000, 0.7071],
[0.5774, 0.5000, 0.4472]])
指数运算------------
tensor([[ 1.0000, 2.7183, 7.3891],
[ 20.0855, 54.5981, 148.4132]])
对数运算---------
tensor([[ -inf, 0.0000, 0.6931],
[1.0986, 1.3863, 1.6094]])
张量的数据裁剪。
a=torch.arange(6).reshape(2,3)
b=torch.tensor((1,1,3,4,0.3,2.4))
print(a)
print(torch.clamp_max(a,3))#根据最大值裁剪
print(torch.clamp_max(b,2))
print(torch.clamp_min(a,3))#根据最小值裁剪
print(torch.clamp_min(b,2))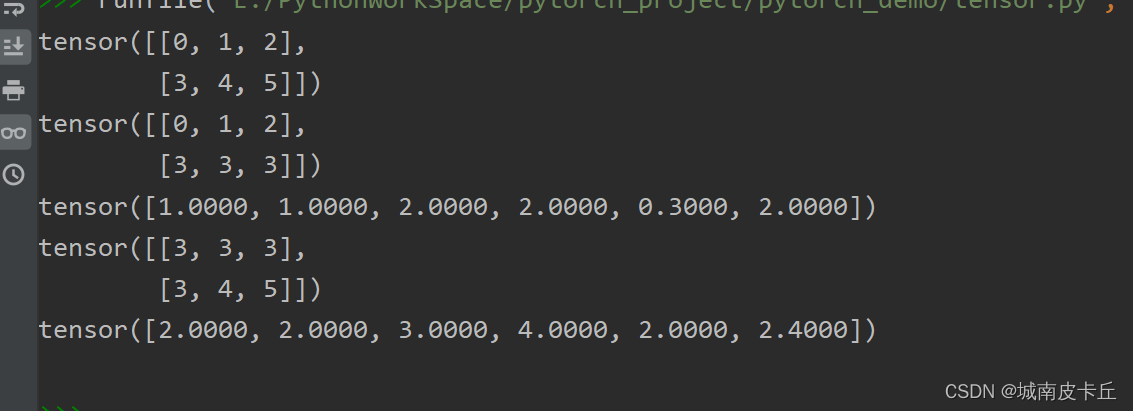
张量的转置、乘积、逆矩阵、迹运算。
a=torch.arange(6.0).reshape(2,3)
b=torch.tensor((1,1,3,4,0.3,2.4)).reshape(3,2)
print(a)
print(torch.t(a))#矩阵的转置
print(a.matmul(b))#矩阵的乘积
c=torch.randn(3,3)
print(c)
print(torch.inverse(c))#矩阵的逆矩阵
print(torch.trace(c))#求矩阵的迹
(3) 统计相关的计算
获取张量中的均值、标准差、最大值、最小值以及位置的函数
"""
max()函数:计算张量中的最大值
argmax()函数:找出张量中最大值的位置
min()函数:计算张量中的最小值
argmin()函数:找出张量中最小值的位置
"""
a=torch.tensor([2,11,4,66,75,3,4,55,73,72,13,45])
#一维张量下的操作
print("a的最大值:",a.max())
print("a最大值的位置:",a.argmax())
print("a的最小值",a.min())
print("a最小值的位置",a.argmin())
#二维张量下的操作
b=a.reshape(3,4)
print("张量b",b)
#b张量最大值以及位置(行)
print("b最大值",b.max(dim=1))
print("b最大值得位置",b.argmax(dim=1))
#b张量最小值以及位置(列)
print("b最小值",b.min(dim=0))
print("b最小值位置",b.argmin(dim=0))a的最大值: tensor(75)
a最大值的位置: tensor(4)
a的最小值 tensor(2)
a最小值的位置 tensor(0)
张量b tensor([[ 2, 11, 4, 66],
[75, 3, 4, 55],
[73, 72, 13, 45]])
b最大值 torch.return_types.max(
values=tensor([66, 75, 73]),
indices=tensor([3, 0, 0]))
b最大值得位置 tensor([3, 0, 0])
b最小值 torch.return_types.min(
values=tensor([ 2, 3, 4, 45]),
indices=tensor([0, 1, 0, 2]))
b最小值位置 tensor([0, 1, 0, 2])
torch.sort()函数:对一维张量进行排序,或者对高维张量在指定的维度进行排序,在输出排序结果的同时,还会输出对应的值在原始位置的索引。
a=torch.tensor([2,11,4,66,75,3,4,55,73,72,13,45])
#一维张量下的操作
print(torch.sort(a))
print(torch.sort(a,descending=True))
#二维张量下的操作
b=a.reshape(3,4)
print("张量b",b)
print(torch.sort(b))
torch.return_types.sort(
values=tensor([ 2, 3, 4, 4, 11, 13, 45, 55, 66, 72, 73, 75]),
indices=tensor([ 0, 5, 2, 6, 1, 10, 11, 7, 3, 9, 8, 4]))
torch.return_types.sort(
values=tensor([75, 73, 72, 66, 55, 45, 13, 11, 4, 4, 3, 2]),
indices=tensor([ 4, 8, 9, 3, 7, 11, 10, 1, 2, 6, 5, 0]))
张量b tensor([[ 2, 11, 4, 66],
[75, 3, 4, 55],
[73, 72, 13, 45]])
torch.return_types.sort(
values=tensor([[ 2, 4, 11, 66],
[ 3, 4, 55, 75],
[13, 45, 72, 73]]),
indices=tensor([[0, 2, 1, 3],
[1, 2, 3, 0],
[2, 3, 1, 0]]))
"""
torch.topk()函数:根据指定的k值,计算出张量中取值大小为前k大的数值及位置
torch.kthvalue()函数:根据指定的k值,计算出张量中取值大小为第K小的数值及位置
"""
a=torch.tensor([2,11,4,66,75,3,4,55,73,72,13,45])
print("a中前11大",torch.topk(a,11))
print("a中前4大",torch.topk(a,4))
print("a中第5小",torch.kthvalue(a,5))
print("------------------")
b=a.reshape(3,4)
#获取二维张量每列中前2大的
print("b张量",b)
print("b中每列前2大",torch.topk(b,2,dim=0))
print("b中每行第3小",torch.kthvalue(b,3,dim=1))
a中前11大 torch.return_types.topk(
values=tensor([75, 73, 72, 66, 55, 45, 13, 11, 4, 4, 3]),
indices=tensor([ 4, 8, 9, 3, 7, 11, 10, 1, 2, 6, 5]))
a中前4大 torch.return_types.topk(
values=tensor([75, 73, 72, 66]),
indices=tensor([4, 8, 9, 3]))
a中第5小 torch.return_types.kthvalue(
values=tensor(11),
indices=tensor(1))
------------------
b张量 tensor([[ 2, 11, 4, 66],
[75, 3, 4, 55],
[73, 72, 13, 45]])
b中每列前2大 torch.return_types.topk(
values=tensor([[75, 72, 13, 66],
[73, 11, 4, 55]]),
indices=tensor([[1, 2, 2, 0],
[2, 0, 0, 1]]))
b中每行第3小 torch.return_types.kthvalue(
values=tensor([11, 55, 72]),
indices=tensor([1, 3, 1]))
"""
torch.mean()根据指定维度计算均值
torch.sum()根据指定维度求和
torch.cumsum()根据指定的维度计算累加和
"""
a=torch.tensor([2,11,4,66,75,3.0,4,55,73,72,13,45]).reshape(3,4)
print(a)
print(torch.mean(a,dim=1,keepdim=True))#计算每行的均值
print(torch.mean(a,dim=0,keepdim=True))#计算每列的均值
print("---------")
print(torch.sum(a,dim=1,keepdim=True))#计算每行的和
print(torch.sum(a,dim=0,keepdim=True))#计算每列的和
print("--------")
print(torch.cumsum(a,dim=1))#按照行累加计算
print(torch.cumsum(a,dim=0))#按照列累加计算
tensor([[ 2., 11., 4., 66.],
[75., 3., 4., 55.],
[73., 72., 13., 45.]])
tensor([[20.7500],
[34.2500],
[50.7500]])
tensor([[50.0000, 28.6667, 7.0000, 55.3333]])
---------
tensor([[ 83.],
[137.],
[203.]])
tensor([[150., 86., 21., 166.]])
--------
tensor([[ 2., 13., 17., 83.],
[ 75., 78., 82., 137.],
[ 73., 145., 158., 203.]])
tensor([[ 2., 11., 4., 66.],
[ 77., 14., 8., 121.],
[150., 86., 21., 166.]])
"""
torch.median():根据指定维度计算中位数
torch.prod():根据指定维度进行乘积运算
torch.cumprod():根据指定维度计算累乘积
torch.std():计算张量的标准差
"""
a=torch.tensor([[1,3,2],[3,4,6]])
print(torch.median(a,dim=1,keepdim=True))#计算每行的中位数
print("---------------")
b=torch.tensor([[1,3,2],[3,4.0,6],[2,3,1]])
print(torch.prod(b,dim=1,keepdim=True))#按照行进行乘积运算
print(torch.cumprod(b,dim=0))#按照列进行累乘计算
print("----------")
print(torch.std(b))#计算标准差
torch.return_types.median(
values=tensor([[2],
[4]]),
indices=tensor([[2],
[1]]))
---------------
tensor([[ 6.],
[72.],
[ 6.]])
tensor([[ 1., 3., 2.],
[ 3., 12., 12.],
[ 6., 36., 12.]])
----------
tensor(1.5635)