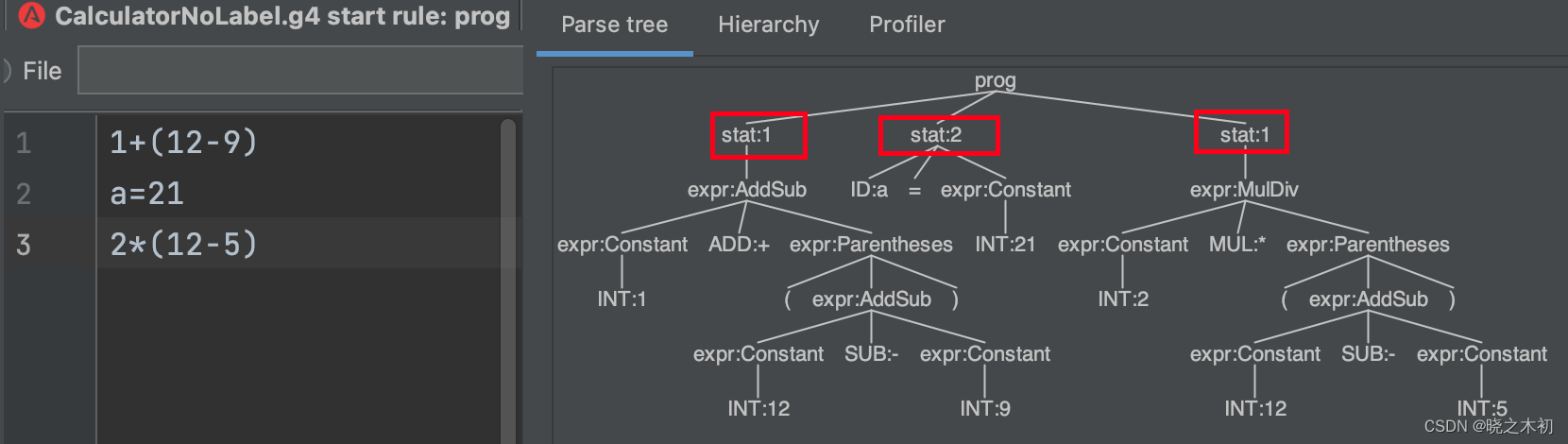
1 Dropout
Dropout是一个常用于深度学习的减轻过拟合的方法。该方法在每一轮训练中随机删除部分隐藏层神经元。被删除的神经元不会进行正向或反向信号传递。在测试阶段所有神经元都会传递信号,但对各个神经元的输出要乘以训练时删除比例。

Dropout实现程序:
class Dropout:
"""
http://arxiv.org/abs/1207.0580
"""
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
在该程序中,我们初始化dropout的比例为0.5。在正向传播中,如果train_flg为True(神经网络在训练状态),会生成一个和输入x形状相同的boolean矩阵mask,mask为False的位置(即被删除的神经元)在正向传播和反向传播的结果都为0。当train_flg为False时(神经网络在预测状态),会将正向传播的结果乘以(1.0 - self.dropout_ratio)输出
实验:利用dropout抑制过拟合
在该测试程序中,我们使用7层神经网络,每层神经元个数100,权重更新方法SGD,学习率0.01,进行300轮训练。每一轮训练样本量仅为300以增大过拟合概率。
此时我们在网络中使用dropout,并测试训练准确度和测试准确度的差距
# coding: utf-8
import os
import sys
sys.path.append("D:\AI learning source code") # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]
# 设定是否使用Dropuout,以及比例 ========================
use_dropout = True # 不使用Dropout的情况下为False
dropout_ratio = 0.2
# ====================================================
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
# 绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
结果:

可以看到dropout可以一定程度上抑制过拟合(没有抑制过拟合的对照组实验数据在之前的文章http://t.csdn.cn/b7c9S)
dropout抑制过拟合的原理:
dropout可以看做是对集成学习的模拟。集成学习即为运行多个相同或类似结构的神经网络进行训练,然后预测时求各个网络预测结果的平均值。dropout删除神经元的操作类似于在每一轮训练一个略有不同的神经网络,最后将每一个网络的结果在预测阶段叠加,实现利用一个神经网络模拟集成学习。
超参数的验证
1 对数据分类:
一般来说,我们将神经网络数据集分为训练数据,测试数据,和验证数据。训练数据用于训练网络权重和偏置,测试数据用于验证网络泛化能力,防止过拟合,而验证数据用于评估超参数。这里注意不可使用测试数据验证超参数,否则可能导致超参数对测试数据过拟合,即调试的超参数只适用于测试数据。
对于没有进行分类的数据集,如这里测试用的mnist数据集,我们可以先在训练数据中分出20%作为验证数据
(x_train, t_train), (x_test, t_test) = load_mnist()
x_train, t_train = shuffle_dataset(x_train, t_train)
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
这里我们在分割数据集前先随机打乱数据集以进一步保障数据随机性,然后将数据集前20%作为验证数据,后80%作为训练数据
2 超参数最优化步骤
1 确定一个大致的超参数取值范围
2 在设置的范围内随机取得超参数值
3 利用该超参数值进行学习,使用验证数据评估学习精度(要将学习的epoch数设置很小以节省时间)
4 多次重复2,3步骤,并根据结果缩小取值范围
有研究表明在范围内随机取样比规律性搜索效果更好,因为在多个超参数中,不同超参数对识别精度影响程度不同
一般来说,找到合适的超参数数量级即可,不需要精确到具体某个值
超参数优化实验
# coding: utf-8
import sys, os
sys.path.append("D:\AI learning source code") # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.util import shuffle_dataset
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了实现高速化,减少训练数据
x_train = x_train[:500]
t_train = t_train[:500]
# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
def __train(lr, weight_decay, epocs=50):
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,
epochs=epocs, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)
trainer.train()
return trainer.test_acc_list, trainer.train_acc_list
# 超参数的随机搜索======================================
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
# 指定搜索的超参数的范围===============
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)
# ================================================
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
# 绘制图形========================================================
print("=========== Hyper-Parameter Optimization Result ===========")
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0
for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):
print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)
plt.subplot(row_num, col_num, i+1)
plt.title("Best-" + str(i+1))
plt.ylim(0.0, 1.0)
if i % 5: plt.yticks([])
plt.xticks([])
x = np.arange(len(val_acc_list))
plt.plot(x, val_acc_list)
plt.plot(x, results_train[key], "--")
i += 1
if i >= graph_draw_num:
break
plt.show()
这一次我们利用mnist数据集测试寻找学习率和权值衰减率这两个超参数的最优值。我们对学习率初始取值10e-6值10e-3 (python程序里表示为 10 ** np.random.uniform(-6, -2)).权重衰减值范围10e-8到10e-4.
注:np.random.uniform范围左闭右开
我们使用7层神经网络,每隐藏层神经元个数100.为了加快训练速度,我们每次训练样本量500,每轮训练100次。在训练完成后,我们选出其中测试准确度最高的前20组,并绘制其训练和测试准确度变化图象。
第一轮前20组结果如下:

=========== Hyper-Parameter Optimization Result ===========
Best-1(val acc:0.79) | lr:0.007167252581661965, weight decay:4.46411213720861e-08
Best-2(val acc:0.76) | lr:0.009590540451785262, weight decay:3.4336503187454634e-06
Best-3(val acc:0.75) | lr:0.007574924636516419, weight decay:1.8694988419536705e-08
Best-4(val acc:0.75) | lr:0.008691535159159042, weight decay:5.358524004570447e-05
Best-5(val acc:0.74) | lr:0.008869169716698419, weight decay:5.906144381013852e-07
Best-6(val acc:0.74) | lr:0.007231956339661699, weight decay:5.1648136815500515e-08
Best-7(val acc:0.73) | lr:0.006823929935149825, weight decay:6.587792640131085e-06
Best-8(val acc:0.72) | lr:0.005506621708230906, weight decay:6.907800794800708e-06
Best-9(val acc:0.71) | lr:0.009160313797949956, weight decay:5.047627735555578e-08
Best-10(val acc:0.7) | lr:0.006506168259111944, weight decay:4.886725890956679e-05
Best-11(val acc:0.69) | lr:0.009539273908181656, weight decay:1.1043227008270985e-05
Best-12(val acc:0.69) | lr:0.007798786280457097, weight decay:2.566925672778291e-06
448464, weight decay:9.47276313549097e-06
Best-18(val acc:0.56) | lr:0.004121973859588465, weight decay:1.278735236820568e-07
Best-19(val acc:0.54) | lr:0.005094840375624678, weight decay:1.3168432394782485e-07
Best-20(val acc:0.52) | lr:0.0021804464282101947, weight decay:1.4357750811527073e-07
根据第一轮测试结果,我们将学习率范围缩小到10e-4至10e-3,将权值衰减率范围缩小到10e-8至10e-6,开始第二轮实验
第二轮实验结果

=========== Hyper-Parameter Optimization Result ===========
Best-1(val acc:0.8) | lr:0.007860334709347631, weight decay:3.5744103167252943e-07
Best-2(val acc:0.79) | lr:0.009101764902840044, weight decay:7.304973331423018e-08
Best-3(val acc:0.79) | lr:0.0077682308379276544, weight decay:8.08776787254994e-08
Best-4(val acc:0.78) | lr:0.007695432026250778, weight decay:2.4699443793745103e-07
Best-5(val acc:0.77) | lr:0.005844523564130418, weight decay:1.1571928419657492e-08
Best-6(val acc:0.76) | lr:0.008100878064710397, weight decay:9.921361407618477e-07
Best-7(val acc:0.74) | lr:0.007225166920829242, weight decay:1.1863229062662078e-08
Best-8(val acc:0.74) | lr:0.005706941972517327, weight decay:4.595973192460211e-06
Best-9(val acc:0.73) | lr:0.006445581641493332, weight decay:2.9452804347731977e-07
Best-10(val acc:0.73) | lr:0.00693450459896848, weight decay:2.0186451326501946e-06
Best-11(val acc:0.65) | lr:0.004925747032013345, weight decay:5.919824221197248e-07
Best-12(val acc:0.64) | lr:0.007030579937109058, weight decay:3.6013880654217633e-06
Best-13(val acc:0.64) | lr:0.005998218080578915, weight decay:2.6194581561983115e-06
Best-14(val acc:0.63) | lr:0.004333280515717759, weight decay:3.293391789330398e-06
Best-15(val acc:0.57) | lr:0.003608522576771299, weight decay:8.316798762001302e-08
Best-16(val acc:0.56) | lr:0.0036538430517432698, weight decay:8.428957748502751e-07
Best-17(val acc:0.56) | lr:0.002554863407218098, weight decay:2.398791245915158e-06
Best-18(val acc:0.54) | lr:0.003487090693530097, weight decay:3.1726798158025344e-08
Best-19(val acc:0.54) | lr:0.00494510123268657, weight decay:1.1596593557212992e-07
Best-20(val acc:0.53) | lr:0.004066867353963753, weight decay:3.0451709733114034e-08
可以看到排名靠前的模型学习率基本上都固定在10e-3这个数量级,而对于weight decay则主要集中在10e-7和10e-8中。下一轮实验中我们将学习率固定为0.007,而weight decay定在10e-7和10e-8间
第三轮实验结果:

=========== Hyper-Parameter Optimization Result ===========
Best-1(val acc:0.9) | lr:0.007, weight decay:2.0423654363915898e-07
Best-2(val acc:0.88) | lr:0.007, weight decay:2.0464597011239193e-08
Best-3(val acc:0.86) | lr:0.007, weight decay:2.1418827188785024e-07
Best-4(val acc:0.85) | lr:0.007, weight decay:2.568854551694536e-08
Best-5(val acc:0.85) | lr:0.007, weight decay:2.5102331031174626e-08
Best-6(val acc:0.84) | lr:0.007, weight decay:1.641132728663186e-08
Best-7(val acc:0.84) | lr:0.007, weight decay:2.2668599269481673e-08
Best-8(val acc:0.84) | lr:0.007, weight decay:1.2593373600583017e-07
Best-9(val acc:0.83) | lr:0.007, weight decay:5.965681876085778e-07
Best-10(val acc:0.83) | lr:0.007, weight decay:3.184447130202175e-08
Best-11(val acc:0.83) | lr:0.007, weight decay:6.429143459339116e-07
Best-12(val acc:0.83) | lr:0.007, weight decay:9.829436450746176e-07
Best-13(val acc:0.83) | lr:0.007, weight decay:1.475800382782156e-08
Best-14(val acc:0.83) | lr:0.007, weight decay:4.4960017860216687e-08
Best-15(val acc:0.82) | lr:0.007, weight decay:2.6357274929242283e-08
Best-16(val acc:0.82) | lr:0.007, weight decay:5.25981898629044e-08
Best-17(val acc:0.82) | lr:0.007, weight decay:3.165929380917094e-08
Best-18(val acc:0.81) | lr:0.007, weight decay:4.0322974353983454e-08
Best-19(val acc:0.81) | lr:0.007, weight decay:5.27878837562846e-07
Best-20(val acc:0.81) | lr:0.007, weight decay:8.988618606625146e-07
结论:学习率设置在10e-3这个数量级,weight decay在10e-7到10e-8直接都可以,影响不大