文章目录
- BloomFilter简单介绍
- BloomFilter中的数学知识
- fpp(误判率/假阳性)的计算
- k的最小值
- 公式总结
- 编程语言实现
- golang的实现
- [已知n, p求m和k](https://github.com/bits-and-blooms/bloom/blob/master/bloom.go#L133)
- 参考
BloomFilter简单介绍
BloomFilter我们可能经常听到也在使用, 它的特点是如果判断结果为"不存在", 则一定不存在; 如果判断为存在, 则可能存在. 如下图示例说明当我们判断z元素存在时, 其实是不存在的, 即存在有概率性.
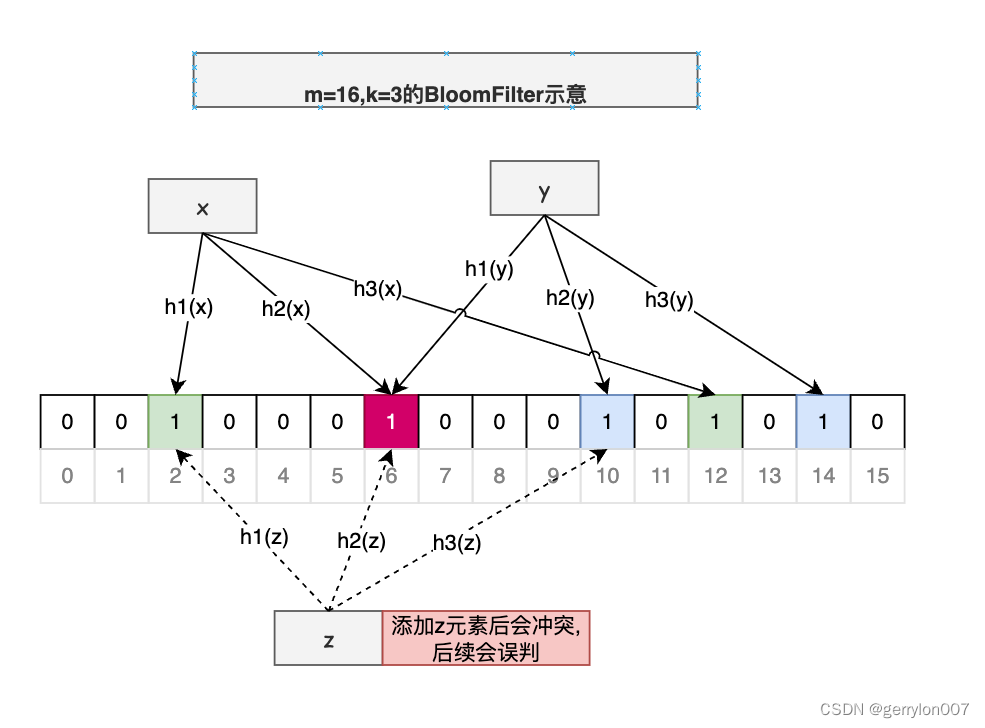
如上图, 长为m=16的二进制向量, 初始全为0; k=3(即添加一个元素需要将3个bit设置为1), 对n=3个元素进行添加操作.
BloomFilter几个关键量定义:
m: 二进制向量大小(多少个二进制位)
n: 要存放的元素个数
k: 哈希函数的个数, 或者说每添加一个元素都要进行k次计算
fpp或者简写为p: 误判率(false positive rate), 即 使用bloomfilter判断为存在时, 但实际不存在的概率
BloomFilter中的数学知识
fpp(误判率/假阳性)的计算
BloomFilter主要的数学原理是: 在某一范围内( 1 < = x < = m ) 1<=x<=m) 1<=x<=m)(x为整数, m通常是很大的, 如 1 0 6 级别 10^6级别 106级别), 任意选取两个整数 i , j , i 和 j 可重复选取 i, j, i和j可重复选取 i,j,i和j可重复选取, 则其相等的概率是非常小的: m m 2 = 1 m \dfrac{m}{m^2}=\dfrac{1}{m} m2m=m1
我们假定hash计算是均匀的, 即每次hash会随机地将m位中的一位设置为1. 那么:
- 一次hash计算(如 h 1 ( x ) h1(x) h1(x))后, 任一位被 置为1 的概率为: 1 m \dfrac{1}{m} m1
- 一次hash计算(如 h 1 ( x ) h1(x) h1(x))后, 任一位 还是0(即未被置为1) 的概率为: 1 − 1 m 1 - \dfrac{1}{m} 1−m1
- 添加一个元素(如
bloomFilter.Add(x), 即执行k次hash)后, 任一位还是0的概率为: ( 1 − 1 m ) k (1 - \dfrac{1}{m})^k (1−m1)k - 添加n个元素后(如上图中的n=3个元素:x,y,z), 任一位还是0的概率为: ( 1 − 1 m ) k n (1 - \dfrac{1}{m})^{kn} (1−m1)kn , 任一位为1的概率为 1 − ( 1 − 1 m ) k n 1- (1 - \dfrac{1}{m})^{kn} 1−(1−m1)kn
- 如果将1个新的元素,添加到已存在n个元素的BloomFilter中,则任一位已经为1的概率与上面相同,为:
1
−
(
1
−
1
m
)
k
n
1- (1 - \dfrac{1}{m})^{kn}
1−(1−m1)kn .
那么添加这个新元素时, k个比特都为1(相当于新元素和已有元素已经分不清了)的概率(此即为新插入元素的误识别率)为:
p = [ 1 − ( 1 − 1 m ) k n ] k p = [1- (1 - \dfrac{1}{m})^{kn}]^{k} p=[1−(1−m1)kn]k
通常来说, m是一个非常大的数(1MiB内存就有
2
20
×
8
≈
800
万
2^{20}\times{8}\approx 800万
220×8≈800万个bit), 并且我们有:
lim
x
→
∞
(
1
+
x
)
1
x
=
e
{ \lim\limits_{x \to \infin} (1+x)^{\frac{1}{x}} = e}
x→∞lim(1+x)x1=e
那么在工程实践中, 可以认为p的近似值为:
p
=
[
1
−
(
1
−
1
m
)
k
n
]
k
=
[
1
−
(
1
−
1
m
)
−
m
×
−
k
n
m
]
k
≈
(
1
−
e
−
k
n
m
)
k
(
当
m
很大时
,
将
−
1
m
看作
x
)
\begin{aligned} p &= [1- (1 - \dfrac{1}{m})^{kn}]^{k} \\ &= [1- (1 - \dfrac{1}{m})^{-m\times\frac{-kn}{m}}]^{k} \\ &\approx (1-e^{-\frac{kn}{m}})^{k} \enspace (当m很大时, 将 -\dfrac{1}{m}看 作x) \end{aligned}
p=[1−(1−m1)kn]k=[1−(1−m1)−m×m−kn]k≈(1−e−mkn)k(当m很大时,将−m1看作x)
k的最小值
计算过程参考: https://cs.stackexchange.com/questions/132088/how-is-the-optimal-number-of-hashes-is-derived-in-bloom-filter
已经遗忘的知识:
- 求导公式: ( ln x ) ′ = 1 x (\ln{x})^{'} = \dfrac{1}{x} (lnx)′=x1
- 求导公式: ( e n x ) ′ = n e n x (\bold{e}^{nx})^{'} = n\bold{e}^{nx} (enx)′=nenx
在某些情况下, 我们对n, m, 的值可以给一个估算值, 以此来获得最小的p(即尽可能准确判断), 那么k就是一个变量了, 问题就变为求
(
1
−
e
−
k
n
m
)
k
(1-e^{-\frac{kn}{m}})^{k}
(1−e−mkn)k的最小值.
令
f
(
k
)
=
(
1
−
e
−
k
n
m
)
k
f(k)=(1-e^{-\frac{kn}{m}})^{k}
f(k)=(1−e−mkn)k, 那么
两边取对数有
:
ln
f
(
k
)
=
ln
(
1
−
e
−
k
n
m
)
k
=
k
ln
(
1
−
e
−
k
n
m
)
设
g
(
k
)
=
k
ln
(
1
−
e
−
k
n
m
)
,
那么
:
g
′
(
k
)
=
ln
(
1
−
e
−
k
n
m
)
+
k
n
m
e
−
k
n
m
1
−
e
−
k
n
m
令
x
=
e
−
k
n
m
,
x
∈
(
0
,
1
)
,
那么有
h
(
x
)
=
ln
(
1
−
x
)
−
x
1
−
x
ln
x
(
注意
k
用
−
m
n
l
n
x
替换
)
=
(
1
−
x
)
ln
(
1
−
x
)
−
x
ln
x
1
−
x
(
x
∈
0
,
1
)
\begin{aligned} & 两边取对数有: \\ & \ln f(k)=\ln (1-e^{-\frac{kn}{m}})^{k} = k \ln(1-e^{-\frac{kn}{m}}) \\ & 设 g(k) = k\ln{(1-e^{-\frac{kn}{m}})}, 那么:\\ & g{'}(k) = \ln{(1-e^{-\frac{kn}{m}})} + k\dfrac{\frac{n}{m}e^{-\frac{kn}{m}}}{1-e^{-\frac{kn}{m}}} \enspace \\ & 令 x = e^{-\frac{kn}{m}}, x \in(0, 1), 那么有 \\ & h(x) = \ln(1-x) - \dfrac{x}{1-x} \ln x \enspace (注意k用-\dfrac{m}{n}lnx替换) \\ & \enspace \enspace \enspace \enspace = \dfrac{(1-x) \ln(1-x)-x \ln x}{1-x} \enspace (x\in{0, 1}) \end{aligned}
两边取对数有:lnf(k)=ln(1−e−mkn)k=kln(1−e−mkn)设g(k)=kln(1−e−mkn),那么:g′(k)=ln(1−e−mkn)+k1−e−mknmne−mkn令x=e−mkn,x∈(0,1),那么有h(x)=ln(1−x)−1−xxlnx(注意k用−nmlnx替换)=1−x(1−x)ln(1−x)−xlnx(x∈0,1)
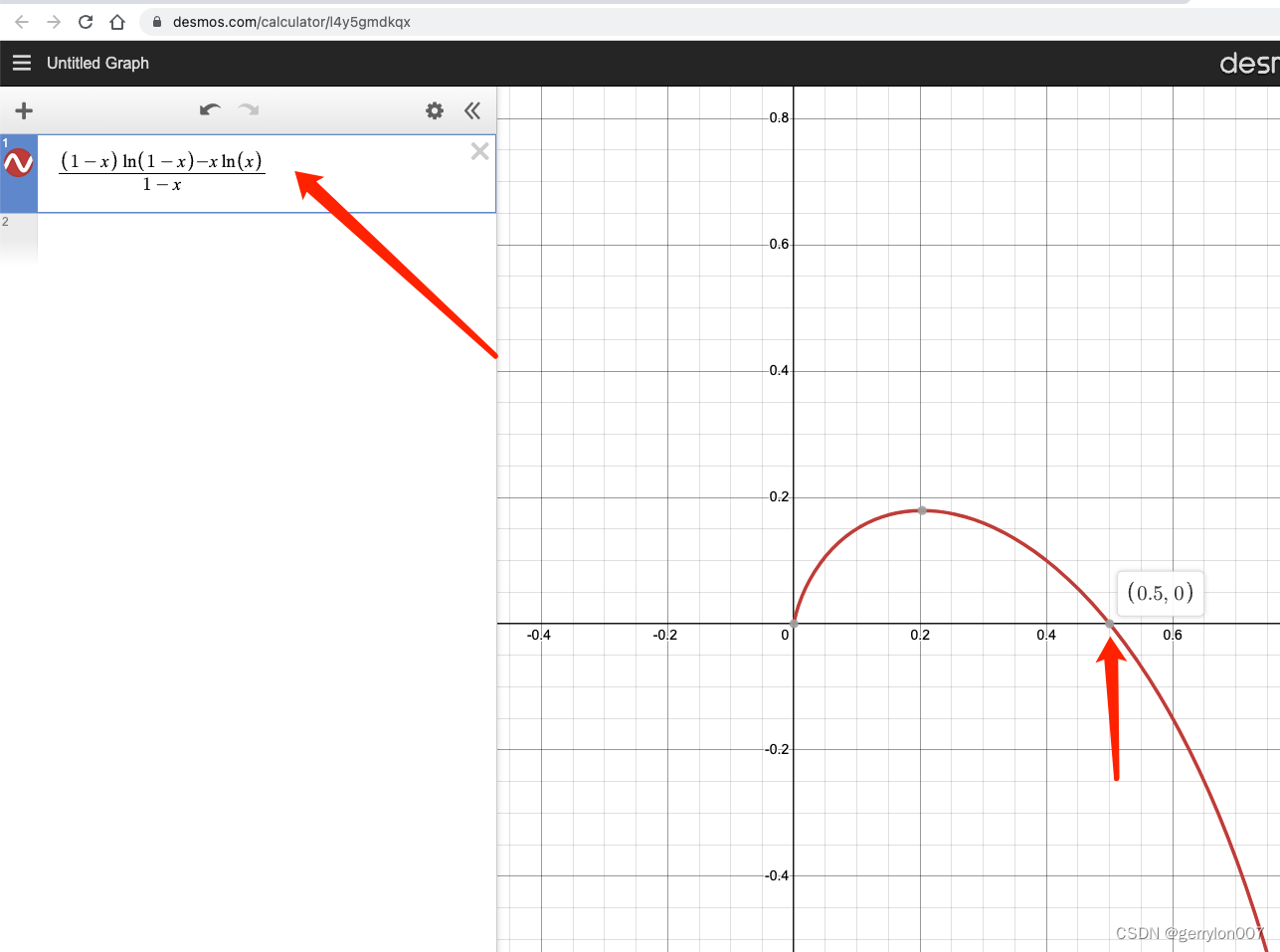
对 h ( x ) = ( 1 − x ) ln ( 1 − x ) − x ln x 1 − x ( x ∈ 0 , 1 ) h(x) = \dfrac{(1-x)\ln(1-x)-x \ln x}{1-x} \enspace (x\in{0, 1}) h(x)=1−x(1−x)ln(1−x)−xlnx(x∈0,1), 不难看出:
- 当 x = 1 2 时 , h ( x ) = 0 x=\dfrac{1}{2}时, h(x)=0 x=21时,h(x)=0
- 当 x > 1 2 时 , h ( x ) < 0 x>\dfrac{1}{2}时,h(x)<0 x>21时,h(x)<0
- 当 x < 1 2 时 , h ( x ) > 0 x<\dfrac{1}{2}时,h(x)>0 x<21时,h(x)>0
站在巨人的肩膀上, 我们可以直接在这里看:
显然在
x
∈
(
0
,
1
)
范围内
,
当
x
=
0.5
时
,
h
(
x
)
最小
x\in(0, 1)范围内, 当x=0.5时, h(x)最小
x∈(0,1)范围内,当x=0.5时,h(x)最小, 此时
k
=
m
n
l
n
2
k=\dfrac{m}{n}ln2
k=nmln2
也就是说:
当
k
<
m
n
l
n
2
k <\dfrac{m}{n}ln2
k<nmln2时(想象k非常接近0),
x
=
e
−
k
n
m
x = e^{-\frac{kn}{m}}
x=e−mkn会非常接近1, 此时
x
>
1
2
x>\dfrac{1}{2}
x>21,
h
(
x
)
<
0
h(x)<0
h(x)<0 ⇒ f(k)在变小;
当
k
>
m
n
l
n
2
k >\dfrac{m}{n}ln2
k>nmln2时(想象k非常接近0),
x
=
e
−
k
n
m
x = e^{-\frac{kn}{m}}
x=e−mkn会非常接近0, 此时
x
<
1
2
x<\dfrac{1}{2}
x<21,
h
(
x
)
>
0
h(x)>0
h(x)>0 ⇒ f(k)在变大;
所以
k
=
m
n
l
n
2
k=\dfrac{m}{n}ln2
k=nmln2时会使得
f
(
k
)
f(k)
f(k)最小, 即此时p最小.
公式总结
- 误判率公式: p = [ 1 − ( 1 − 1 m ) k n ] k p = [1- (1 - \dfrac{1}{m})^{kn}]^{k} p=[1−(1−m1)kn]k
- 误判率近似公式(当
m很大时): p ≈ ( 1 − e − k n m ) k p \approx (1-e^{-\frac{kn}{m}})^{k} p≈(1−e−mkn)k - 已知
m,n, k的最小值(近似)为: k = m n ln 2 ≈ 0.7 m n k=\dfrac{m}{n}\ln{2} \approx 0.7\dfrac{m}{n} k=nmln2≈0.7nm - 已知
n,p, 且k取最小时, m = − n ln p ( l n 2 ) 2 m=-\dfrac{n\ln{p}}{(ln2)^{2}} m=−(ln2)2nlnp
编程语言实现
golang的实现
https://github.com/bits-and-blooms/bloom
已知n, p求m和k
func EstimateParameters(n uint, p float64) (m uint, k uint) {
m = uint(math.Ceil(-1 * float64(n) * math.Log(p) / math.Pow(math.Log(2), 2)))
k = uint(math.Ceil(math.Log(2) * float64(m) / float64(n)))
return
}
参考
- https://en.wikipedia.org/wiki/Bloom_filter
- https://cs.stackexchange.com/questions/132088/how-is-the-optimal-number-of-hashes-is-derived-in-bloom-filter
(完)





![4.创建和加入通道相关(network.sh脚本createChannel函数分析)[fabric2.2]](https://img-blog.csdnimg.cn/7ce081b9fbe5443ca4c8116d340c3d5c.png)