重试机制
因为网络抖动等原因导致 RPC 调用失败,这时候使用重试机制可以提高请求的最终成功率,减少故障影响,让系统运行更稳定。
重试简易实现方案
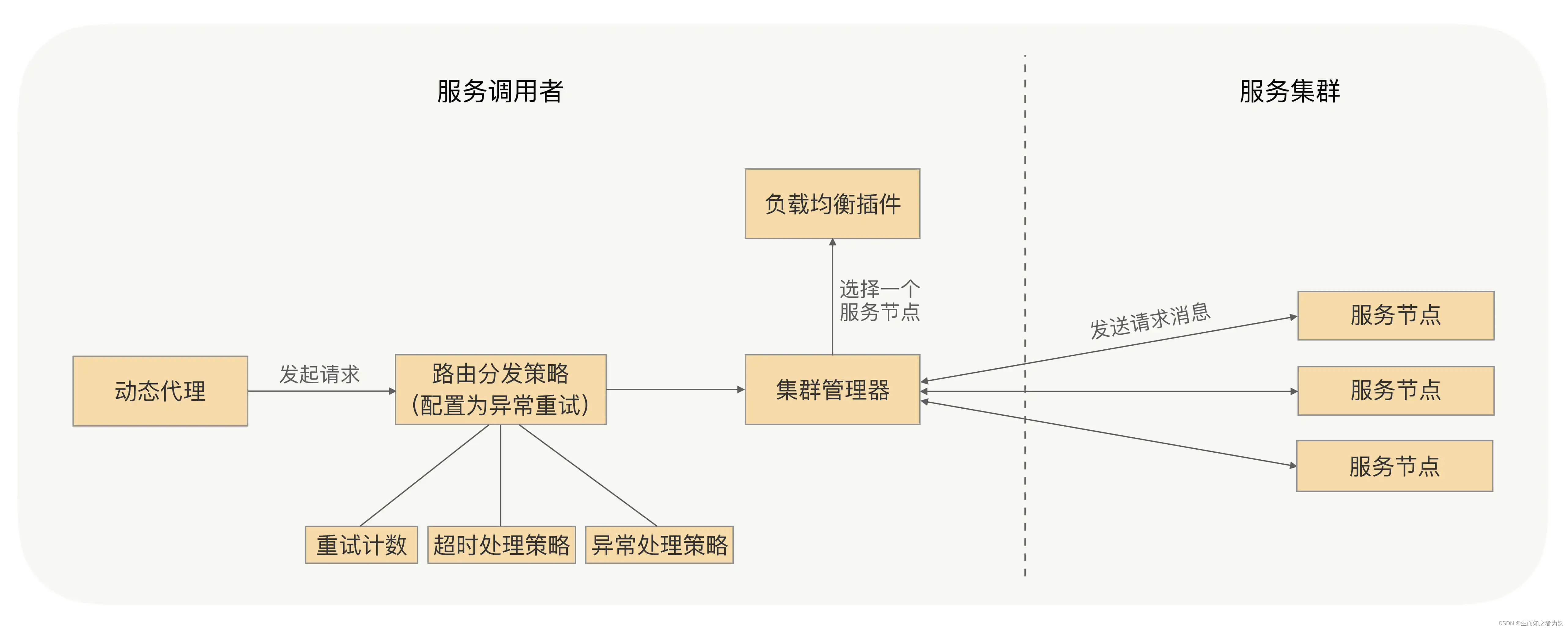
在重试的过程中,为了能够在约定的时间内进行安全可靠地重试,在每次触发重试之前,我们需要先判定下这个请求是否已经超时,如果超时了会直接返回超时异常,否则我们需要重置下这个请求的超时时间,防止因多次重试导致这个请求的处理时间超过用户配置的超时时间,从而影响到业务处理的耗时。在发起重试、负载均衡选择节点的时候,我们应该去掉重试之前出现过问题的那个节点,这样可以提高重试的成功率,并且我们允许用户配置可重试异常的白名单,这样可以让 RPC 框架的异常重试功能变得更加友好。
要点
1、确保业务是幂等性。防止多次重试导致业务
2、超时时间重置,每次重试之前重置超时时间
3、故障机器剔除,可以参考rocketmq中的故障延迟机制来剔除故障机器。通过故障延迟机制和维护故障列表faultItemTable来在随机选择的基础上选性能最优和未使用过的可靠Broker来发送信息,若无则在faultItemTable中选择次优Broker来发送消息,以此实现高性能,可以有效地规避故障Borker。
● 若开启故障延迟机制则在随机递增取模的基础上对已发送过请求的Broker做延迟规
避,当当前Broker不在故障机器表faultItemTable中或存在但当前时间超过规避时限则判定Broker的队列可用。规避时限的设置是通过两个数组latencyMax和notAvailableDuration维护的,当上次请求耗时时间latency超过latencyMax中的某个值,则会在数组notAvailableDuration中选择对应的时间期限值进行规避,因此当前请求时间-(上次请求时间+规避时限)>0则判定可用。
private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L};
private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L};
● 多次轮训选择一个队列判断是否可用,若有可用队列则直接返回可用队列。若无可用队列则从故障Broker列表中随机选择一个Broker,若该Broker中有写队列,则将该Broker和写队列信息写入消息队列MessageQueue中并返回。若无,则从故障列表中剔除该结点(真正从路由信息中剔除),并随机从messageQueueList中选择一个队列来发送消息。
重试危害
重试有放大故障的风险。无限制的重试可以打高下游应用的负载,导致其宕机无法提供正常服务。而且重试还会存在链路放大的效应。假设正常访问量是 n,链路一共有 m 层,每层重试次数为 r,则最后一层受到的访问量最大,为 n * r ^ (m - 1) 。这种指数放大的效应很可怕,可能导致链路上多层都被打挂,整个系统雪崩。
退避策略
对于一些暂时性的错误,如网络抖动等,可能立即重试还是会失败,通常等待一小会儿再重试的话成功率会较高,并且也可能打散上游重试的时间,较少因为同时都重试而导致的下游瞬间流量高峰。决定等待多久之后再重试的方法叫做退避策略,我们实现了常见的退避策略,如:
线性退避:每次等待固定时间后重试。
随机退避:在一定范围内随机等待一个时间后重试。
指数退避:连续重试时,每次等待时间都是前一次的倍数。
重试机制控制方案
1、单点重试限制:滑动时间窗口方式,对于同一个资源请求,通过计算时间窗口内的成功率来限制上游是否允许重试。
2、限制链路重试:1)响应包中设置retry_flag来通知上游是否可以进行重试。2)返回业务码告知上游是否可以进行重试(入侵性强)
参考:https://www.infoq.cn/article/5fboevkal0gvgvgeac4z
https://time.geekbang.org/column/article/211261



![[ vulnhub靶机通关篇 ] Empire Breakout 通关详解](https://img-blog.csdnimg.cn/67ebd906a15f47f6b83b181a03c77207.png)




![[C++]vector模拟实现](https://img-blog.csdnimg.cn/2c75a68a41454f10a47da1e110d276cc.png)
