内表:
内表是可以在程序内部定义且使用的表,属于本地表。
与C语言比较:
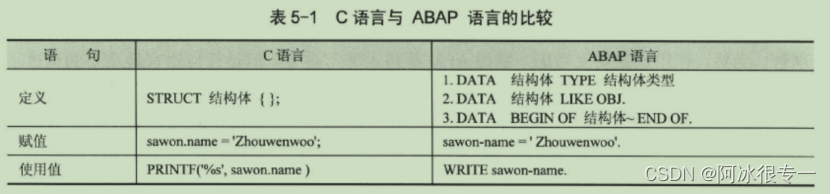
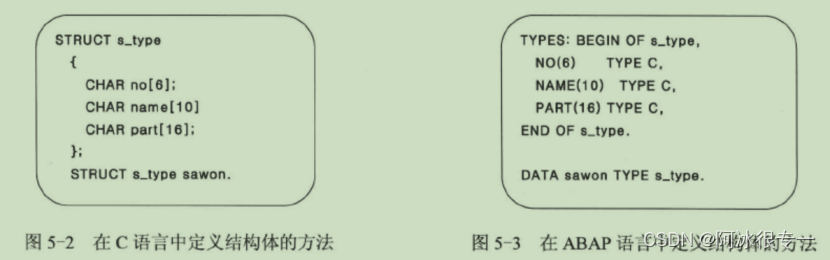
C语言的数组和内表比较:
内表是动态数组(Dynamic Data Object)
INITIALSIZE 语句并非实际占用内存空间,而只是预约(RESERVE)内存空间。

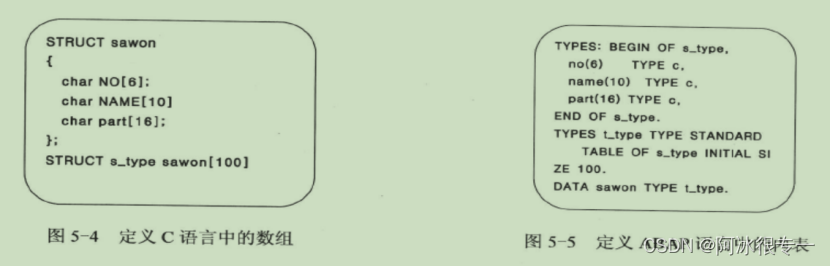
创建内表:
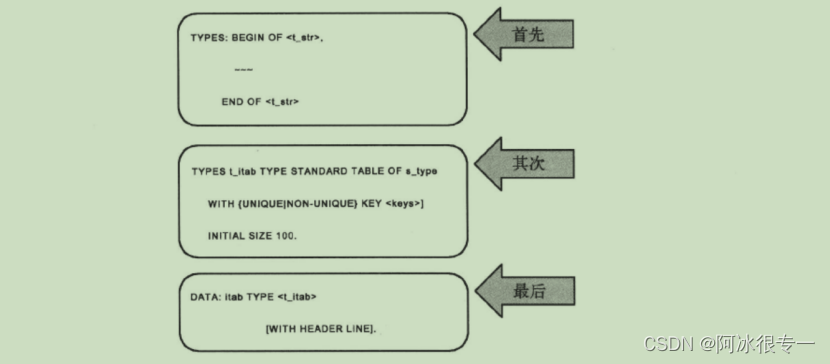
参照局部表类型创建内表
首先定义结构体类型,然后参照此结构体类型定义内表类型,最后再参照此内表的类型定义内表。
参照全局表类型创建内表:

例:
*参照局部表类型创建内表
TYPES: BEGIN OF s_type,"定义结构体参数类型
no(6) TYPE c,
name(10) TYPE c,
part(16) TYPE c,
END OF s_type.
DATA gt_itab TYPE STANDARD TABLE OF s_type
WITH NON-UNIQUE KEY no " 指定no字段唯一
WITH HEADER LINE. " 用了该语法以后,itab即是一个内表,又是一个与该内表结构相同的工作区
gt_itab-no = '0001'.
gt_itab-name = 'enjoy abap'.
gt_itab-part = 'sap team'.
APPEND gt_itab.
LOOP AT gt_itab.
WRITE : gt_itab-no,gt_itab-name,gt_itab-part.
ENDLOOP.
*参照全局表定义内表
DATA gt_itab TYPE SORTED TABLE OF scarr WITH UNIQUE KEY carrid.
DATA gs_itab LIKE LINE OF gt_itab.
SELECT * INTO TABLE gt_itab FROM scarr.
LOOP AT gt_itab INTO gs_itab.
WRITE: / gs_itab-carrid,gs_itab-carrname.
ENDLOOP.内表与表头

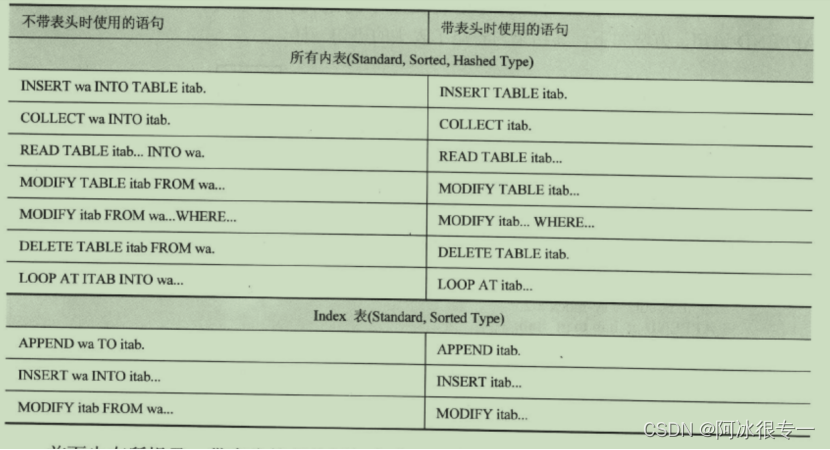
比较内表循环语句中带表头的内表与不带表头的内表的使用方法。使用不带表头的内表时,需通过工作区 (Work Area)编辑内表中的数据,而使用带表头的内表时,则可以直接用表的名字编辑内表值。

使用modify时:
 使用read时:
使用read时:

汇总:
例:
*带表头和不带表头的用法区别
*带表头
TYPES:BEGIN OF t_str,
col1 TYPE i,
col2 TYPE i,
END OF t_str.
DATA gt_itab TYPE TABLE OF t_str WITH HEADER LINE."代表头的gt_itab内表
DO 3 TIMES.
gt_itab-col1 = sy-index.
gt_itab-col2 = sy-index ** 2.
APPEND gt_itab.
ENDDO.
LOOP AT gt_itab.
WRITE: / gt_itab-col1,gt_itab-col2.
ENDLOOP.
*不带表头
TYPES:BEGIN OF t_str,
col1 TYPE i,
col2 TYPE i,
END OF t_str.
DATA gt_itab TYPE TABLE OF t_str. "定义无表头的内表gt_itab
DATA gs_str LIKE LINE OF gt_itab. "根据内表定义结构体作为工作区输出数据
DO 3 TIMES.
gs_str-col1 = sy-index.
gs_str-col2 = sy-index ** 2.
APPEND gs_str TO gt_itab. "向内表追加数据
ENDDO.
LOOP AT gt_itab INTO gs_str. "需要借助gs_str结构体输出内表
WRITE : / gs_str-col1,gs_str-col2.
ENDLOOP.内表的类型:
标准表
标准表是有顺次索引的树型结构内表,是利用索引查找内表行数据时易于使用的内表类型。使用 READ、MODIFY 及DELETE 语句时也会使用索引。标准表的关键字并非唯一,即标准表中不能使用 WITHUNIOUE 语句。

例:
*标准表
*1定义结构体类型
TYPES:BEGIN OF t_line,
field1 TYPE c LENGTH 5,
field2 TYPE c LENGTH 4,
field3 TYPE i,
END OF t_line.
**2定义标准表类型
TYPES t_tab TYPE STANDARD TABLE OF t_line WITH NON-UNIQUE DEFAULT KEY. "default key将内表中以char类型定义的前几个字段设为关键字
**3定义内表
DATA gt_itab TYPE t_tab WITH HEADER LINE.
gt_itab-field1 = 'enjoy'.
gt_itab-field2 = 'abap'.
gt_itab-field3 = 1.
APPEND gt_itab. "因为定义了表头,所以这里不添加到内表也行,应为上面就是直接赋值给内表。
READ TABLE gt_itab INDEX 1.
WRITE : / gt_itab-field1,gt_itab-field2,gt_itab-field3.排序表
标准表与排序表是索引表。其中排序表是已经按关键字排序好的内表类型。即当程序员需要保存一直以关键字排序好的结果时使用此类型。与标准表相同,其拥有索引,可以用索引或关键字查询对应的行。排序表与标准表的另一个不同点为 Uniqueness。排序表定义关键字时,可使用 WITHUNIQUE 语句,而标准表只能使用 WITH NON-UNIQUE 语句。排序表自带 BINARYSEARCH功能,因此表行数据与检索速度成反比。定义排序表时,务必明确指定 Unique/Non-unique。表已经排序,因此使用 Sort 命令会发生错误。
例:
*排序表
*1定义结构体类型
TYPES:BEGIN OF t_line,
col TYPE c,
seq TYPE i,
END OF t_line.
**2定义排序表类型
TYPES t_tab TYPE SORTED TABLE OF t_line WITH UNIQUE KEY col.
**3定义内表类型
DATA gt_itab TYPE t_tab WITH HEADER LINE.
gt_itab-col = 'B'.
gt_itab-seq = 1.
INSERT TABLE gt_itab. "若使用append会发生排序问题‘“Dump Error”
gt_itab-col = 'A'.
gt_itab-seq = 2.
INSERT TABLE gt_itab.
CLEAR gt_itab. "清空的是表头的数据
READ TABLE gt_itab INDEX 2.
WRITE : / gt_itab-col,gt_itab-seq.哈希表
哈希表没有顺次索引,只能用哈希值计算出的 Key 值进行检索。检索速度与内表的数据无关,始终是相同的。哈希值用于直接读取哈希算法算出的内存地址中存储的数据。哈希表定要设定为 Unique 形式。
哈希表的内表不存在索引,因此不能使用 READ TABLE~INDEX 语句。需使用 READ TABLE~WITHTABLE KEY或WITH KEY 语,才能访问内表数据。
例:
*哈希表(一定要设成UNIQUE形式)
**1定义结构体
TYPES:BEGIN OF t_line,
col TYPE c,
seq TYPE i,
END OF t_line.
**2定义哈希表类型
TYPES t_tab TYPE HASHED TABLE OF t_line WITH UNIQUE KEY col.
**3定义内表
DATA gt_itab TYPE t_tab WITH HEADER LINE.
gt_itab-col = 'B'.
gt_itab-seq = 1.
INSERT TABLE gt_itab.
gt_itab-col = 'A'.
gt_itab-seq = 2.
INSERT TABLE gt_itab.
CLEAR gt_itab.
READ TABLE gt_itab WITH TABLE KEY col ='A'.
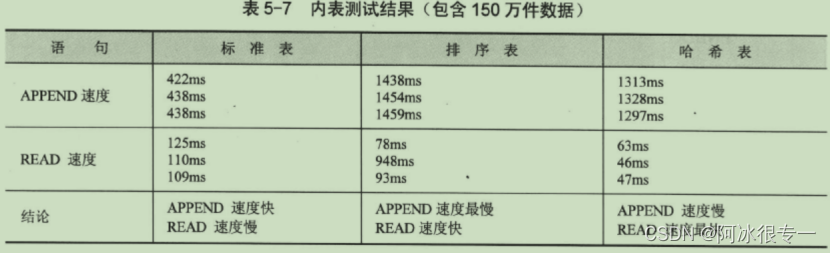
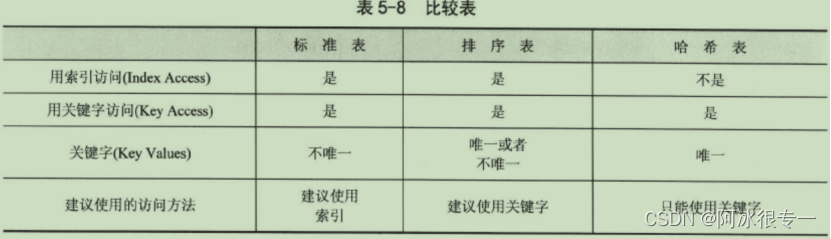
WRITE : / gt_itab-col,gt_itab-seq.比较内表执行速度
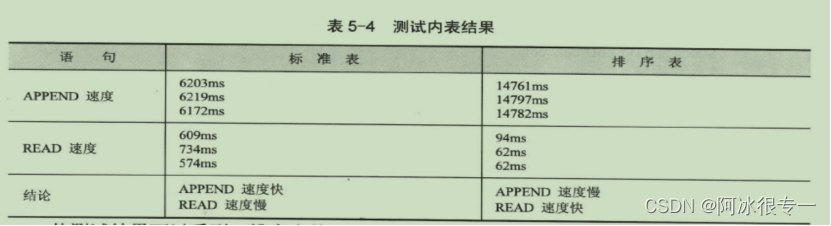
二分查找:

二分查找再不同类型的内表的查询速度:
 测试哈希表速度:
测试哈希表速度:
内表命令:
内表赋值:
内表与其他变量一样,也可用 MOVE 语句进行赋值。要注意的是带表头的内表以下面的的方法赋值时只会复制表头中的数据。

带表头的内表表头与内表的名字相同。使用符号“D”区分表头与表体。中括号“[]”指的是带表头内表的表体。即带表头的内表名字指表头,不带表头的内表名字指表体。因此,在例题中根据是否带表头的情况,分别使用了 MOVE gt_itabll TO gt_itab2 语句。
例:
*内表赋值
TYPES:BEGIN OF t_line,
col1 TYPE i,
col2 TYPE i,
END OF t_line.
DATA: gt_itab1 TYPE STANDARD TABLE OF t_line WITH HEADER LINE,
gt_itab2 TYPE STANDARD TABLE OF t_line,
gs_wa like LINE OF gt_itab2.
DO 5 TIMES.
gt_itab1-col1 = sy-index.
gt_itab1-col2 = sy-index ** 2.
insert TABLE gt_itab1.
ENDDO.
move gt_itab1[] to gt_itab2."[]指的是代表头内表的表体
LOOP AT gt_itab2 into gs_wa.
WRITE : / gs_wa-col1,gs_wa-col2.
ENDLOOP.内表初始化:
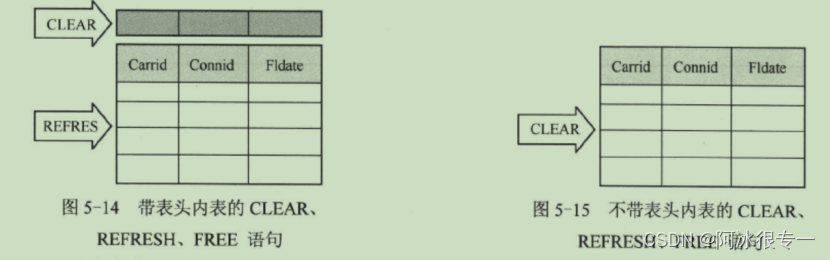
带表头和不带表头的区别:
例:
*内表初始化
DATA:BEGIN OF gs_line,
col1 TYPE i,
col2 TYPE c,
END OF gs_line.
DATA: gt_itab like STANDARD TABLE OF gs_line.
gs_line-col1 = 1.
gs_line-col2 = 'A'.
insert gs_line into TABLE gt_itab.
REFRESH gt_itab. "情况表内数据,但无法释放空间
*free gt_itab. "释放空间
*clear gt_itab. "清空表体
IF gt_itab is INITIAL. "如果gt_itab被初始化了,就执行下面的语句
WRITE : 'Internal table have no data.'.
free gt_itab. "初始化后删除内存空间
ENDIF.Clear:
返回(Release)内存空间。但不删除刚开始要求的内存容量信息。如果是带表头的内表,则下面语句只删除内表的表头。而不带表头的内表删除的是表体。

REFRESH :
语句只删除表内数据,无法删除内存空间,若想释放内存空间需使用FREE 语句。

综上所述,CLEAR 语句删除内表数据的同时释放了内存空间,相反 REFRESH 语句只能删除内表数据。若使用了 REFRESH 语句,则有必要使用 FREE 语句释放内存。
内表排序
作用在标准表和哈希表上:

例:
*内表排序
DATA:BEGIN OF gs_line,
col1 TYPE c,
col2 TYPE i,
END OF gs_line.
DATA gt_itab LIKE STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY col1.
gs_line-col1 = 'B'.
gs_line-col2 = 3.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'C'.
gs_line-col2 = 4.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'A'.
gs_line-col2 = 2.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'A'.
gs_line-col2 = 1.
APPEND gs_line TO gt_itab.
SORT gt_itab.
PERFORM write_data.
SORT gt_itab BY col1 col2.
PERFORM write_data.
SORT gt_itab BY col1 DESCENDING col2 ASCENDING.
PERFORM write_data.
FORM write_data.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-col1,gs_line-col2.
ENDLOOP.
ULINE.
ENDFORM.指定字段:

内表属性:
LINES 返回内表包含的数据件数,OCCURS 返回内表的初始大小。另外,KIND 返回内表的类型,其中 T代表标准表,S 代表排序表, 代表哈希表。在这几种内表属性选项中最常用的是 LINES。

例:
*内表属性
DATA:BEGIN OF gs_line,
col1 TYPE c,
col2 TYPE i,
END OF gs_line.
DATA gt_itab LIKE STANDARD TABLE OF gs_line INITIAL SIZE 10.
DATA: gv_line TYPE i.
DO 20 TIMES.
gs_line-col1 = sy-index.
gs_line-col2 = sy-index * 2.
INSERT gs_line INTO TABLE gt_itab.
ENDDO.
DESCRIBE TABLE gt_itab LINES gv_line. "lines返回内表包含的数据件数
WRITE: / 'internal table line is :',gv_line.追加数据
利用insert
可利用 INSERT 语追加多条数据,但是 Itab1 与Itab2 表类型要相同。

例:
*利用insert追加数据
data:begin of gs_line,
col1 type c,
col2 type i,
end of gs_line.
DATA gt_itab1 LIKE STANDARD TABLE OF gs_line
WITH NON-UNIQUE KEY col1.
DATA gt_itab2 LIKE SORTED TABLE OF gs_line
WITH NON-UNIQUE KEY col1.
gs_line-col1 = 'B'.
gs_line-col2 = 1.
INSERT gs_line INTO TABLE gt_itab1.
gs_line-col1 = 'A'.
gs_line-col2 = 2.
INSERT gs_line INTO TABLE gt_itab1.
gs_line-col1 = 'C'.
gs_line-col2 = 3.
INSERT gs_line INTO TABLE gt_itab1.
*INSERT LINES OF gt_itab1 INTO TABLE gt_itab2.
INSERT LINES OF gt_itab1 FROM 1 TO 2 INTO TABLE gt_itab2. "下标从一开始
LOOP AT gt_itab2 INTO gs_line.
WRITE: / gs_line-col1,gs_line-col2.
ENDLOOP.
********************************************************************************
*利用append追加数据
data:begin of gs_line,
col1 type c,
col2 type i,
end of gs_line.
DATA gt_itab LIKE STANDARD TABLE OF gs_line
WITH NON-UNIQUE KEY col1.
DATA gt_temp LIKE STANDARD TABLE OF gs_line WITH NON-UNIQUE KEY col1.
gs_line-col1 = 'B'.
gs_line-col2 = 1.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'A'.
gs_line-col2 = 2.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'A'.
gs_line-col2 = 3.
APPEND gs_line TO gt_itab.
gs_line-col1 = 'C'.
gs_line-col2 = 4.
APPEND gs_line TO gt_itab.
APPEND LINES OF gt_itab TO gt_temp.
APPEND LINES OF gt_itab FROM 1 TO 2 TO gt_temp.
LOOP AT gt_temp INTO gs_line.
WRITE : / gs_line-col1,gs_line-col2.
ENDLOOP.
**********************************************************
*append initial line 创建一个空表后追加数据
DATA:BEGIN OF gs_line,
col1 TYPE c,
col2 TYPE i,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line INITIAL SIZE 2.
gs_line-col1 = 'C'.
gs_line-col2 = 1.
APPEND gs_line to gt_itab SORTED BY col1.
gs_line-col1 = 'A'.
gs_line-col2 = 2.
APPEND gs_line to gt_itab SORTED BY col1.
gs_line-col1 = 'B'.
gs_line-col2 = 3.
APPEND gs_line to gt_itab SORTED BY col1.
LOOP AT gt_itab into gs_line.
WRITE: / gs_line-col1,gs_line-col2.
ENDLOOP.利用索引追加
利用Index 语句可以在 Index 指定的位置追加一条数据。此方法不适用于哈希表。语句执行成功,系统变量 SY-SUBRC 返回0,同时系统变量 SY-TABIX 返回索引值。

不同内表追加数据:
标准表
-追加数据到内表最后一行。
与APPEND语句有相同的效果
排序表
按照内表排序好的顺序追加数据。
若是关键字并非唯一(Non-UNIOUE KEY)的类型,重复的数据会追加到相同数据的上行中。
-哈希表
按照表关键字的哈希索引顺序追加数据
Append:
语法与insert一致

不同内表追加数据:
标准表
将数据追加到内表最后一行
可以利用 SORTED BY 选项,以关键字为基准按照降序(DESCENDING)进行排序
排序表
排序表是有序表,需按照排好的顺序追加数据,否则会发生 Dump Error。
哈希表
-不能使用 APPEND 语句。
APPEND INITIAL LINE:
使用SORTED BY 语,会自动以字段f为基准降序(DESCENDING)排序后追加数据此语句只适用于标准表,另外还需用 INITIAL SIZE 语指定大小。

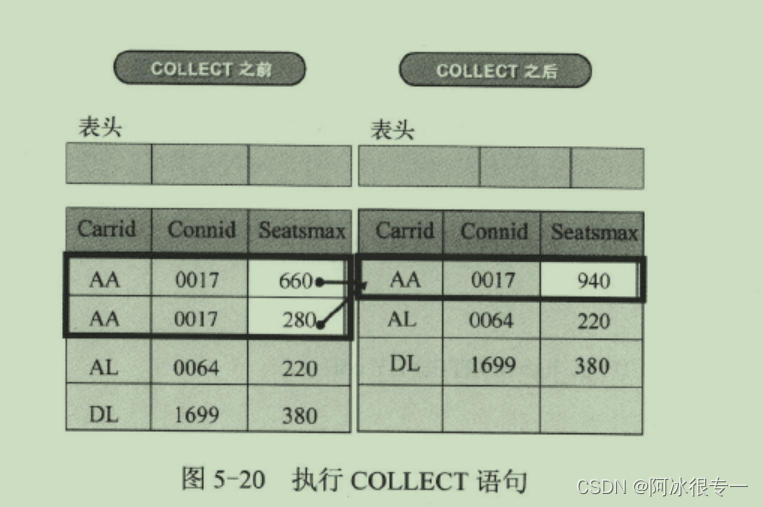
Collect:
使用 COLLECT 语句可以合计内表中数字类型的字段。
除了关键字以外的数据都需要是数字类型(f、i、p)。执行 COLLECT 语句,当存在相同关键字的数据时,合计数字类型的字段,不存在相同关键字的数据时,直接追加数据。不存在关键字的内表,则会把 CHAR 类型的字段作为关键字执行相同的操作。内表中若存在以CHAR 类型的 carrid 与 connid为基准的相同数据,则会以关键字作为基准合计数字类型的字段 seatsmax 值。

例:
*COLLECT语句
DATA:BEGIN OF gs_line,
col1(3) TYPE c,
col2(2) TYPE n,
col3 TYPE i,
END OF gs_line.
DATA gt_itab LIKE STANDARD TABLE OF gs_line
WITH NON-UNIQUE KEY col1 col2.
gs_line-col1 = 'AA'.
gs_line-col2 = '17'.
gs_line-col3 = 660.
COLLECT gs_line INTO gt_itab.
gs_line-col1 = 'AL'.
gs_line-col2 = '34'.
gs_line-col3 = 220.
COLLECT gs_line INTO gt_itab.
gs_line-col1 = 'AA'.
gs_line-col2 = '17'.
gs_line-col3 = 280.
COLLECT gs_line INTO gt_itab.
LOOP AT gt_itab INTO gs_line.
WRITE: / gs_line-col1,gs_line-col2,gs_line-col3.
ENDLOOP.修改内表数据:
Modify
利用如下语句,即以关键字为基准修改内表行数据。内表关键字并非唯一,即存在重复数据时,执行 MODIFY 语句会修改第一条数据。

例:
*修改内表数据MODIFY
DATA:BEGIN OF gs_line,
carrid TYPE sflight-carrid,
carrname TYPE scarr-carrname,
fldate TYPE sflight-fldate,
END OF gs_line.
DATA gt_itab LIKE TABLE OF gs_line.
SELECT carrid connid INTO CORRESPONDING FIELDS OF TABLE gt_itab
FROM sflight.
LOOP AT gt_itab INTO gs_line.
AT NEW carrid.
SELECT SINGLE carrname INTO gs_line-carrname
FROM scarr WHERE carrid = gs_line-carrid.
MODIFY gt_itab FROM gs_line INDEX sy-tabix TRANSPORTING carrname.
ENDAT.
WRITE: / gs_line-carrid,gs_line-carrname.
ENDLOOP.Where:


索引:
利用索引可以修改对应行的值。因为使用索引,所以只能用于标准表与排序表。在 LOOP语句中可以省略INDEX 选项,此时会修改内表当前索引行数据。

![[算法笔记]最长递增子序列和编辑距离](https://img-blog.csdnimg.cn/8b9eb342e9e54f05b4542a12267bd7f9.jpeg#pic_center)
![[附源码]SSM计算机毕业设计时事资讯平台JAVA](https://img-blog.csdnimg.cn/14ea4e7b870a4e659bb7d1ac73269326.png)






![[一篇读懂]C语言十讲:单链表的新建、查找](https://img-blog.csdnimg.cn/52deffe5140d4d538cedf803d000e167.png#pic_center)