文章目录
- 🚩图的理解
- 🍁无向图
- 🍁有向图
- 🍁完全图
- 🍁常用性质
- 🚩图的数据结构搭建
- 🍁邻接矩阵
- 🍁邻接表
- 🍁邻接矩阵式存储的代码实现
- 🍁邻接矩阵造图测试
- 🍁邻接表式存储的代码实现
- 🍁邻接表造图测试
- 🚩图的深度优先遍历
- 🍁代码实现
- 🍁代码测试
- 🚩图的广度优先遍历
- 🍁代码实现
- 🍁代码测试
- 🚩总结
🚩图的理解
图是一种较线性表和树更为复杂的数据结构,在线性表中,数据元素之间有着明显的线性关系,每个数据都有一个直接前驱和直接后继。而在树形结构中,数据元素之间有着明显的层次关系,并且每一层上的数据元素可能和下一层中多个元素(即孩子节点)相关,但此元素只能和上一层中一个元素(即它的双亲结点)相关。在图型结构中,节点之间的关系可以是任意的!图中任意的两个数据元素之间都可能相关。我个人认为,上述三种数据结构的学习难度排序为:线性表 < 树 < 图
三种数据结构的学习一个比一个抽象,不好用语言去描述,很多时候甚至都是意会出来的😓。说图很难学,那是没有掌握到图的结构特点,只要从最基础的知识开始学起,把整个框架的地基给打好,学习图后面的知识会相对轻松很多。不说那么多了,下面进入正题。
🍁无向图
可以这么大致理解无向图的构造:一堆顶点和边构成的图表
例如:
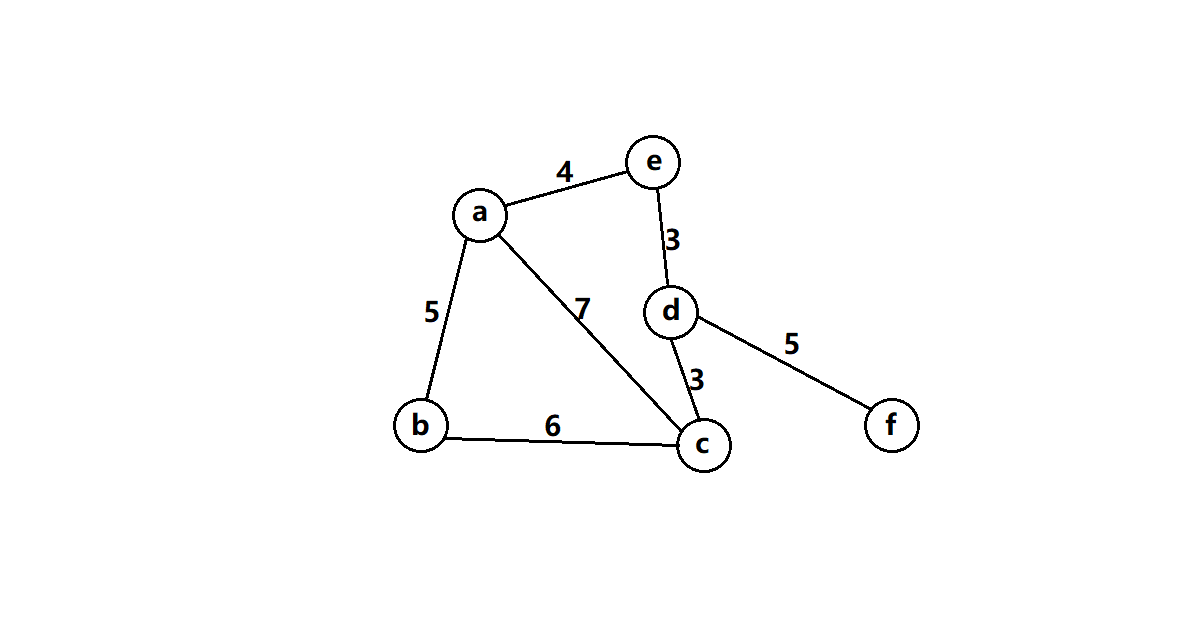
顶点:a、b、c、d、e、f
边:顶点之间的连线(不考虑方向性,即两个顶点是双向的)。
权值:边所承载的值的大小,比如图中的a与b之间的5,a与e之间的4等等。这可能代表花费的时间、金钱,也可能是路程的长短,结合不同的场景有不同的含义。
🍁有向图
将无向图中的边换为弧,就会使得顶点之间变得有向。
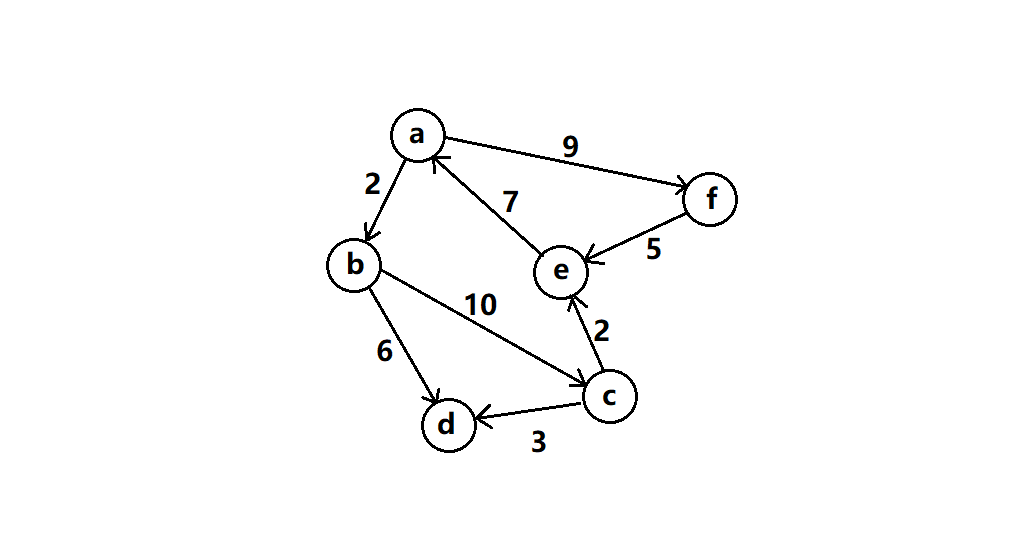
弧:从一个顶点到另一个顶点的有向线。例如<a,b>就是顶点a到b的一条有向弧,弧尾(初始点)是a,弧头(终端点)是b。
🍁完全图
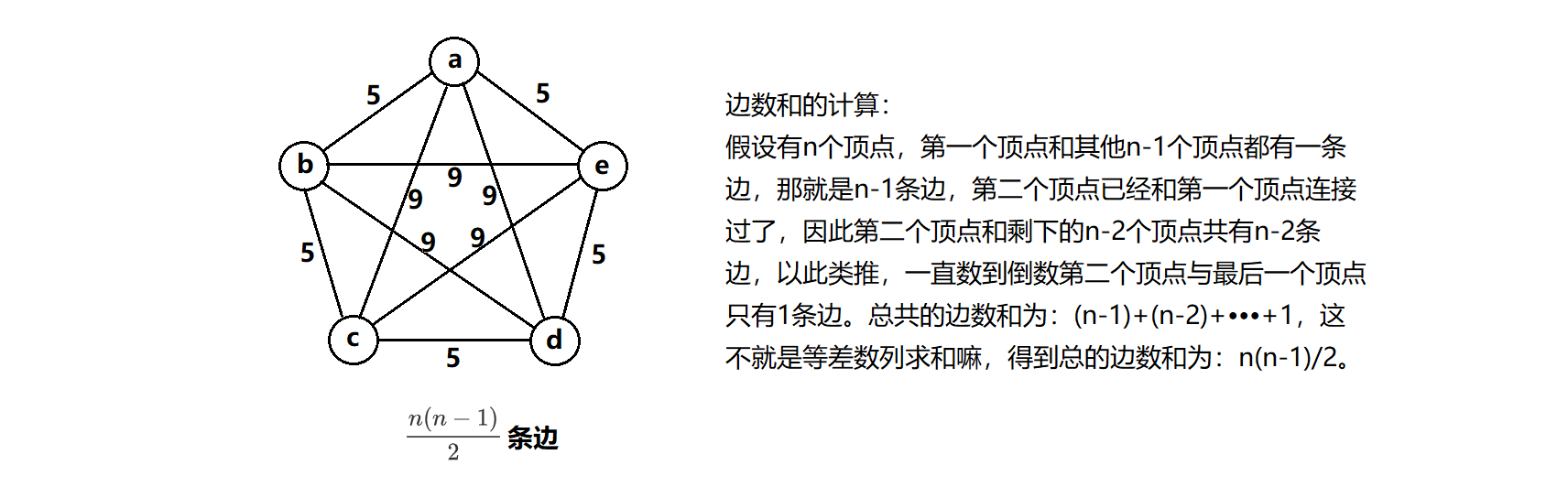
完全图的定义:任意两个顶点之间直接相连并能互相指向的图。
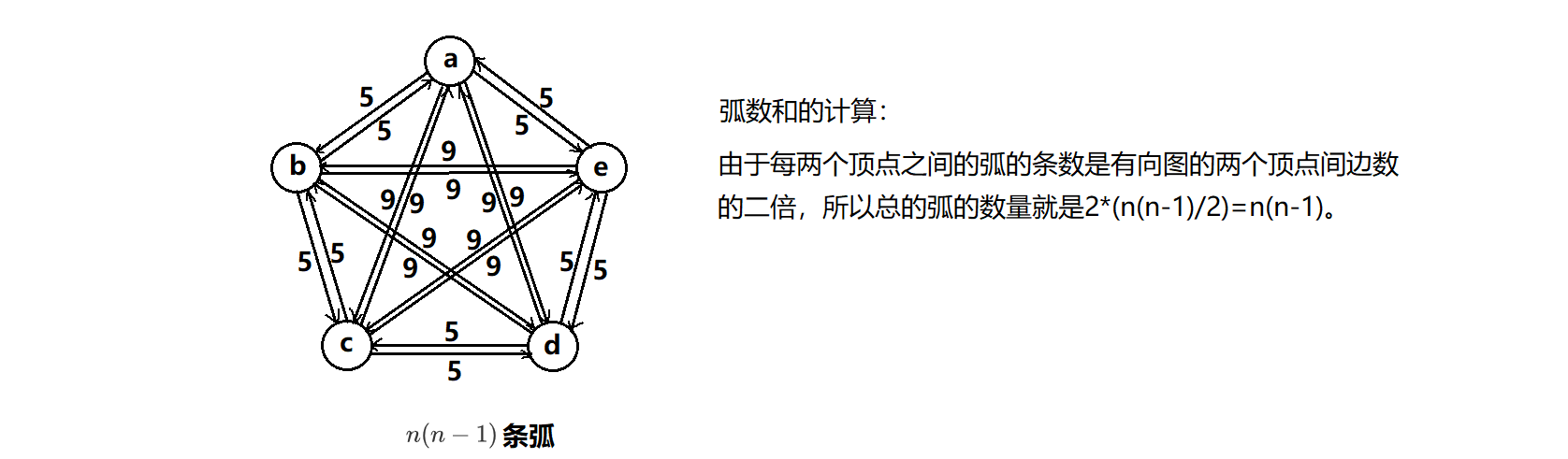
这里其实分为有向完全图和无向完全图两种。
🍂无向完全图:
🍂有向完全图:
🍁常用性质
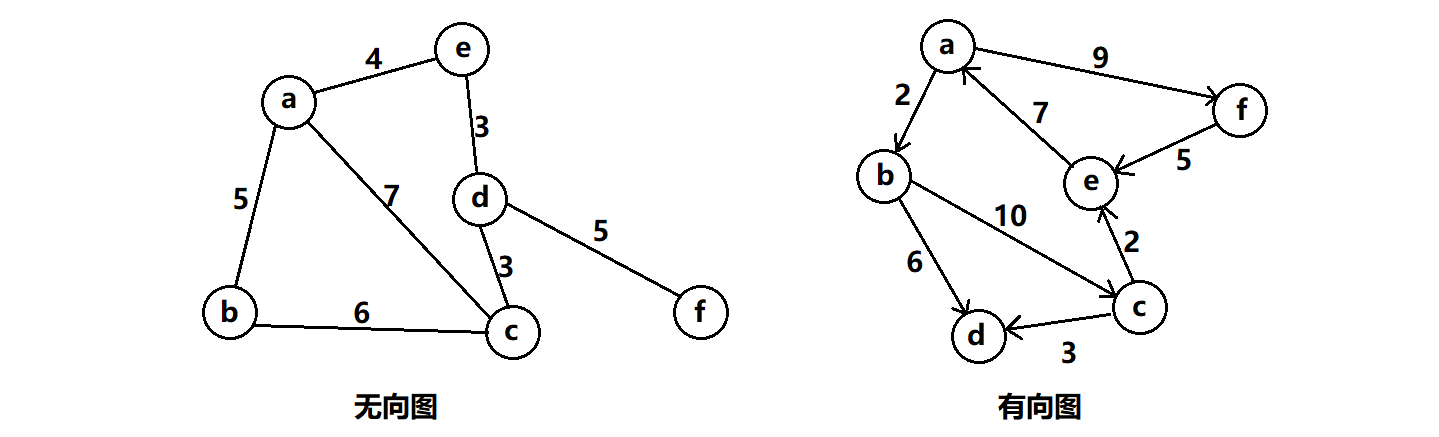
无论是有向图还是无向图,除了顶点和权值之外,还有一些共同的性质,分别是入度、出度、邻接点、路、连通图、连通分量等等。
入度:一个顶点作为弧头的次数,简单来讲就是一个顶点被指向的次数。
比如上面有向图中顶点a被顶点e指向了,那么顶点a的入度就是1。
出度:一个顶点作为弧尾的次数,也就是一个顶点指向其他顶点的次数。
比如上面有向图中顶点a分别指向顶点b与顶点f,那么顶点a的出度为2。
度:对于无向图来说,并不区分入度与出度,一个顶点有几条边,该顶点的度就是多少。对于有向图来说,顶点的度=顶点的入度+顶点的出度。
比如上面有向图中顶点a的度为 1+2=3;而上面无向图中顶点 f 的度直接为2。
邻接点:对于一个顶点来说,它指向的顶点,就称为它的邻接点。对于无向图来说,相连的两个点互为邻接点。
比如上面有向图中顶点a的邻接点为b、f,但有无向图中顶点a、b、c互为邻接点。
路径:从一个顶点到另一个顶点,中间只要能走得通,那么走过的点组成得集合就称为首尾顶点之间的路径。如果是在有向图中,那么该路同样具有方向性。
简单路径:顶点不重复出现的路径称为简单路径。
回路或环:路径的起点与终点相同的路径就构成回路(环)。
比如上面无向图中a、b、c就构成回路,有向图中a、e、f也构成回路。
连通图:在无向图中,如果对于任意的两个顶点都是存在路径的(任意两个顶点都是连通的),那么该图称为连通图。
上面的无向图就是连通图,下面这个就是非连通图。
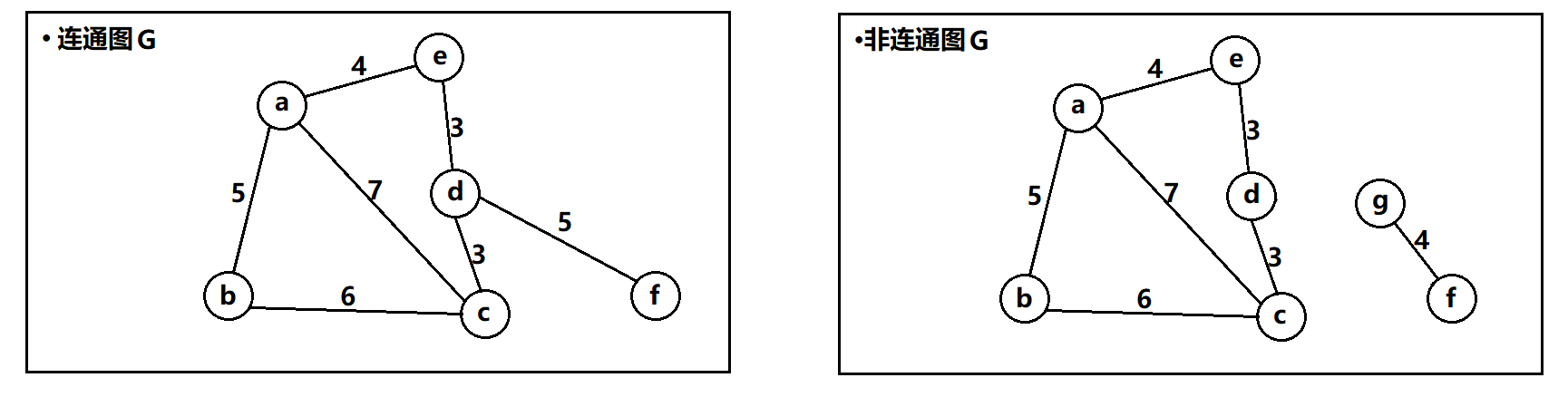
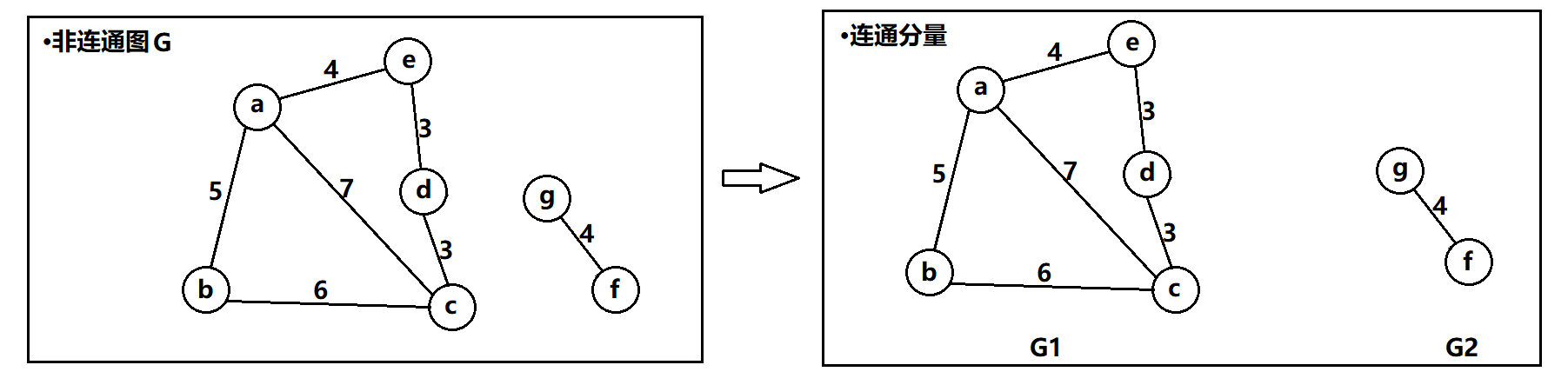
连通分量:无向图中的极大连通子图。例:
强连通图:在有向图中,对任意的两个顶点都存在路径,那么就称之为强连通图。
最开始给的一个有向图并不是强连通图,因为顶点b到其他顶点没有路径。下面给一个强连通图的例子(只需要在原图的基础上加一条b到a的弧就可以了):
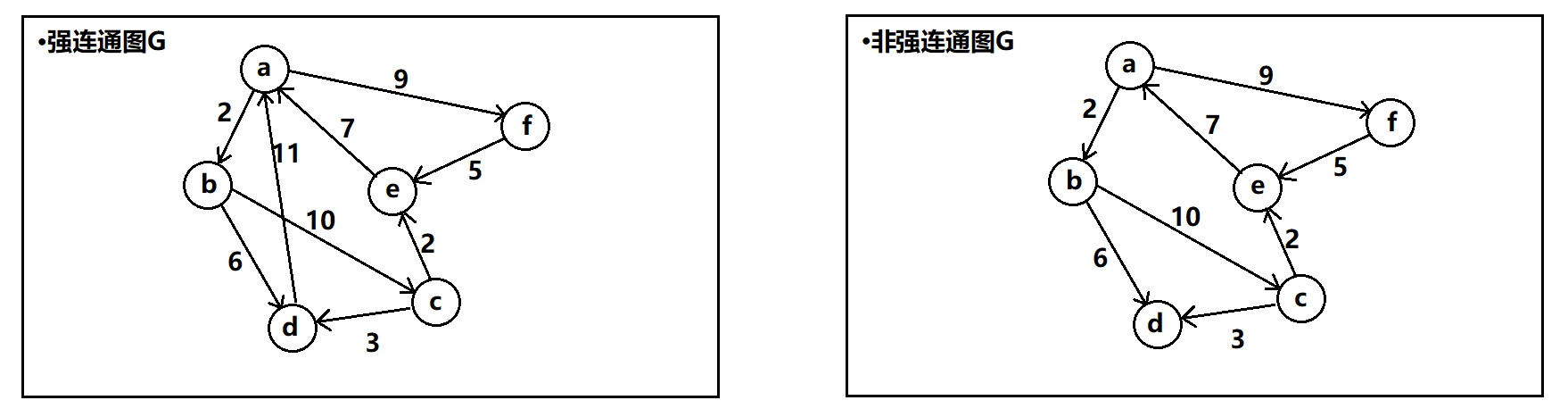
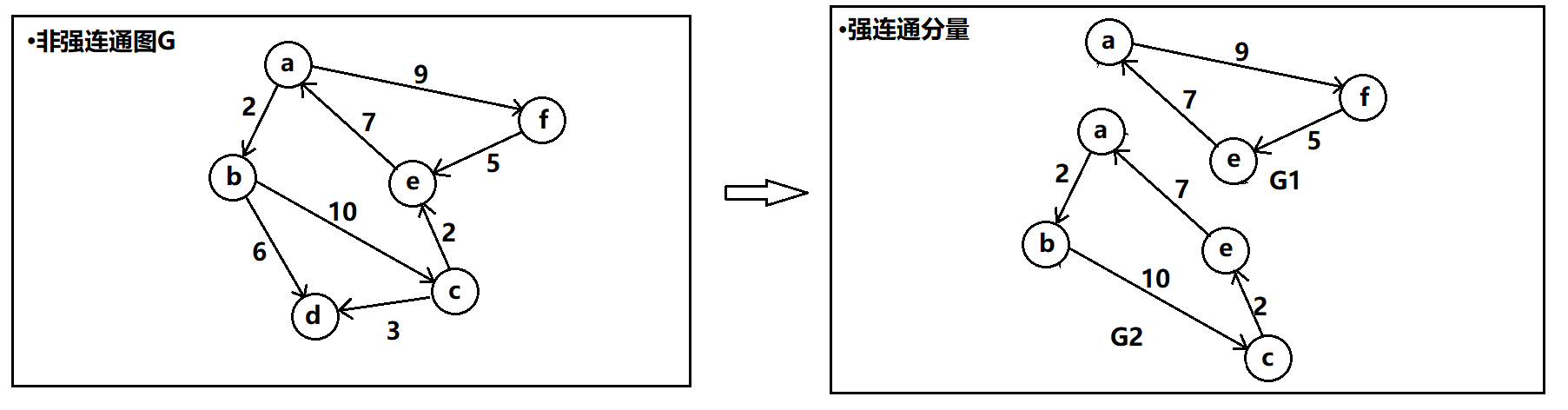
强连通分量:有向图中的极大强连通子图。
🚩图的数据结构搭建
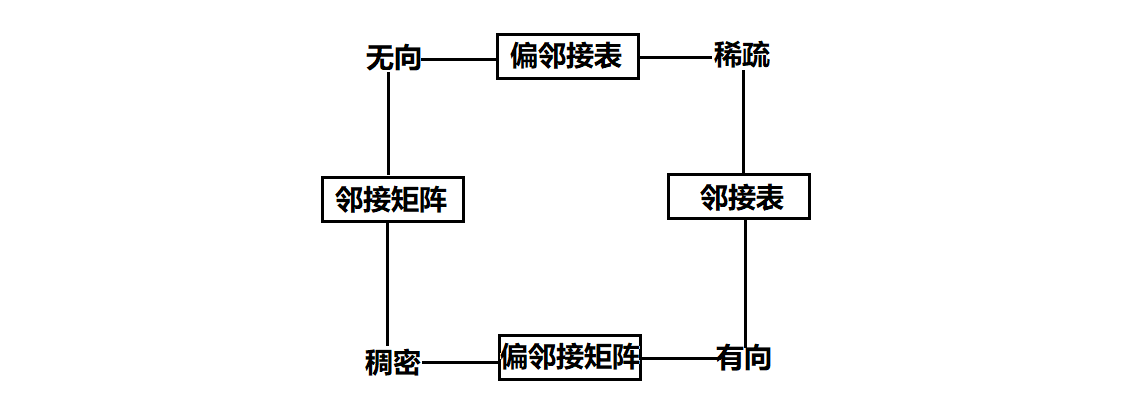
图的数据结构总共有两种:**邻接矩阵与邻接表**两种。
邻接矩阵从字面意思理解就是用一个二维数组来存,具体到每行就是对应着的一个顶点的所有的邻接点。
而邻接表就是把每行的一维数组换成一条单链表来存放邻接点,避免了空间的浪费。
所以说,具体到数据管理的时候,两种管理方式用到的都是以<顶点,其所有邻接点>整体管理,这样将所有的<顶点,邻接点>管理起来时,整个图的结构就被管理起来了。
🍁邻接矩阵
下面以无向图作为示范讲解:
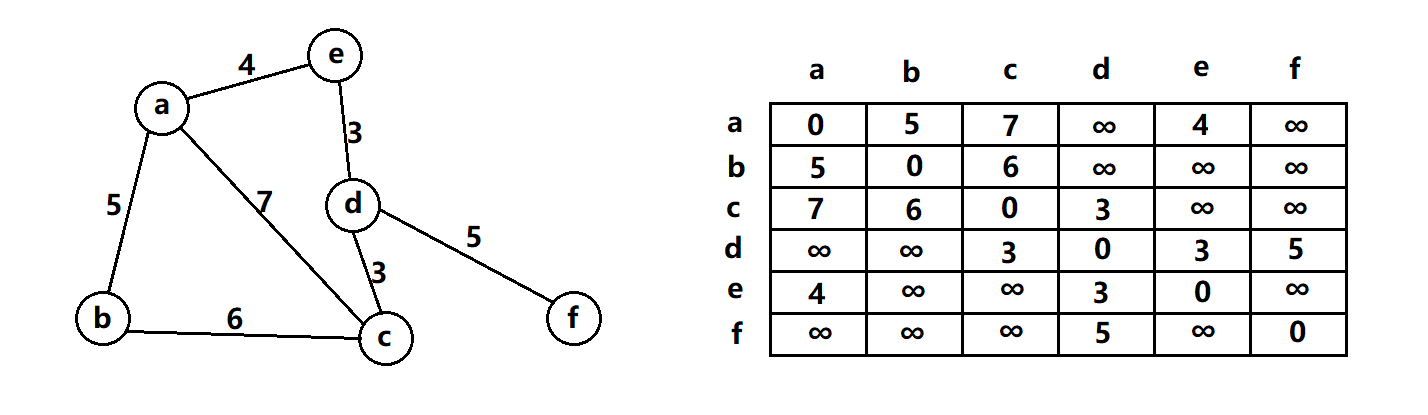
二维数组存放的是两个顶点之间的权值。首先,这里规定定点顶点自己的权值一般默认为0(也可以根据特殊场景自定义),其次规定两个没有直接相连的顶点的权值为∞(∞为无穷大,同样可以根据特殊场景自定义)。由于是无向图,所以生成的二维矩阵是一个对称矩阵。这样存储有一个缺点,就是当顶点之间的关系比较少时,矩阵里的很多空间都会被浪费掉。也就是说,邻接矩阵适合存放稠密图,不适合存放稀疏图。
🍁邻接表
仍旧以无向图讲解:
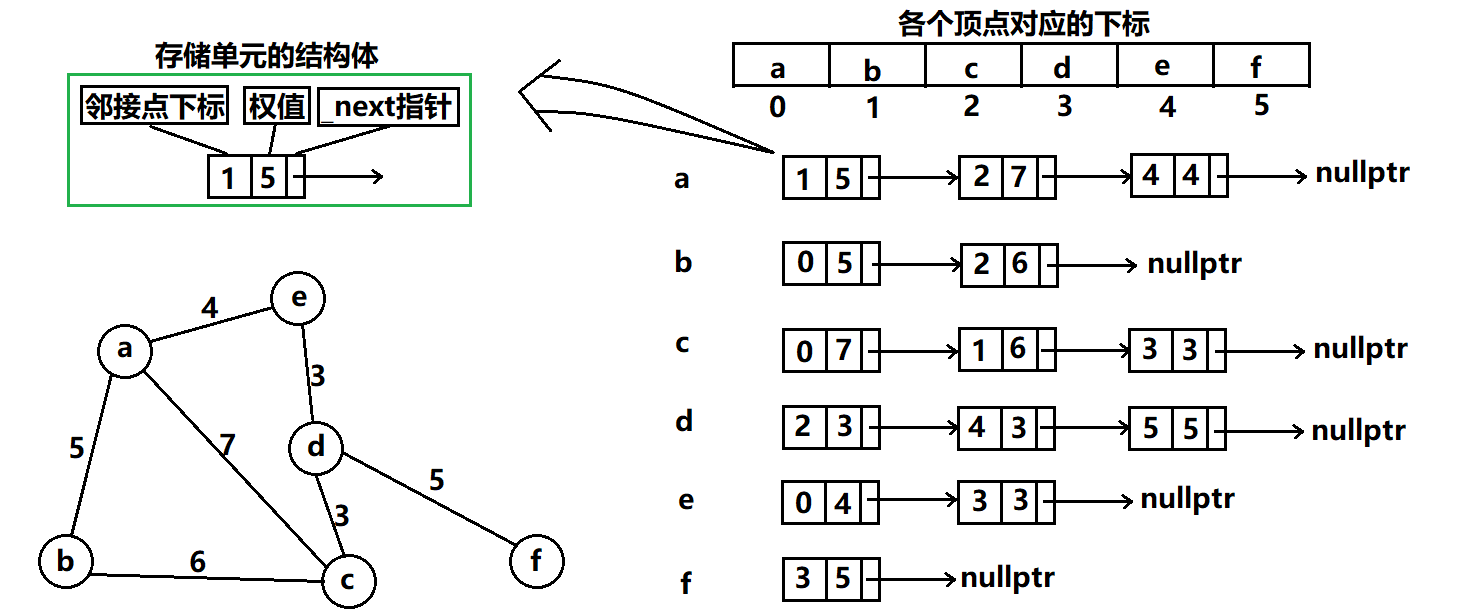
注意里面的链表节点用的是一个结构体。可以看出,邻接表所需要的存储单元更少。
🙋♂️:可是一个结构体所需要的空间也不少哇!是不是在有些情况下会比邻接矩阵更浪费空间?
👨🏫:没错,这种情况确实可能存在。一般是图比较稠密的时候,假设是无向图,且是一个完全图。那么这种情况下的邻接表有(n-1)2个结构体,邻接矩阵有n2个四字节的int类型的下标数据。假设一个结构体是12个字节,那么显然邻接表所消耗的空间更大。所以要根据情况来选择具体的存储结构,这里我有一点建议:稠密无向图尽量使用邻接矩阵存储,稀疏有向图尽量使用邻接表存储,除了这两种情况之外,其他两种情况有一定的偏向性使用,主要是稀疏和稠密占更大的决定性因素。
🍁邻接矩阵式存储的代码实现
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <cstring>
using namespace std;
顶点的数据类型 权值类型 权值的最大值默认为INT32_MAX,即∞ 默认为无向图
template <class V, class W, W MAX_W = INT32_MAX, bool Direction = false>
class Graph
{
private:
vector<V> _vertexs; //顶点数组
map<V, int> _indexMap; //顶点对应的下标(相当于映射关系的建立),用map管理方便大量数据快速查找
vector<vector<W>> _matrix; //邻接矩阵
public:
Graph() = default;//无参构造为默认提供的
Graph(const V *vertexs, int n)//顶点数组与个数传参
{
_vertexs.reserve(n);//初始化顶点数组与下标集
for (int i = 0; i < n; ++i)
{
_vertexs.push_back(vertexs[i]);
_indexMap[vertexs[i]] = i;
}
_matrix.resize(n);
for (int i = 0; i < n; ++i)
{
_matrix[i].resize(n, MAX_W);//初始化邻接矩阵,每个元素默认赋值为∞
_matrix[i][i]=W();//对角线上的权值为0
}
}
size_t GetVertexIndex(const V& x)//获得顶点在顶点数组中的下标
{
auto it = _indexMap.find(x);
if (it != _indexMap.end())//找到的话返回下标
{
return it->second;
}
else
{
throw invalid_argument("顶点不存在");//找不到的话就抛异常
return -1;
}
}
//添加关系(边)
void _AddEdge(const size_t srci, const size_t dsti, const W& wight)
{
_matrix[srci][dsti] = wight;//两个顶点之间的权值进行赋值
if (Direction == false) //是无向图的话就在矩阵的对应位置也对边的权值进行赋值
{
_matrix[dsti][srci] = wight;
}
}
// 参数: 起始顶点 终端顶点 权值
void AddEdge(const V& src, const V& dst, const W& wight)
{
int srci = GetVertexIndex(src);//拿到起始顶点映射的下标
int dsti = GetVertexIndex(dst);//拿到终端顶点映射的下标
_AddEdge(srci, dsti, wight); //嵌套一下用下标的方式添加边,方便在之后处理矩阵的特定情境通过下标加边。
}
void Print()//邻接矩阵的输出
{
// 顶点数组以及映射的下标输出
cout<<"顶点及其映射: "<<endl;
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
// 矩阵
cout<<"邻接矩阵: "<<endl;
// 横下标
cout << " ";
for (size_t i = 0; i < _vertexs.size(); ++i)
{
printf("%4d", i);
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); ++i)
{
cout << i << " "; // 竖下标
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (_matrix[i][j] == MAX_W)
{
printf(" %s", "∞");
}
else
{
printf("%4d", _matrix[i][j]);
}
}
cout << endl;
}
cout << endl;
}
};
🍁邻接矩阵造图测试
void TestGraphCreate()
{
const char* str = "abcdef";
Graph<char, int> g(str, strlen(str));
g.AddEdge('a', 'b', 5);
g.AddEdge('a', 'c', 7);
g.AddEdge('a', 'e', 4);
g.AddEdge('b', 'a', 5);
g.AddEdge('b', 'c', 6);
g.AddEdge('c', 'b', 6);
g.AddEdge('c', 'a', 7);
g.AddEdge('c', 'd', 3);
g.AddEdge('d', 'c', 3);
g.AddEdge('d', 'e', 3);
g.AddEdge('d', 'f', 5);
g.AddEdge('f', 'd', 5);
g.AddEdge('e', 'a', 4);
g.AddEdge('e', 'd', 3);
g.Print();
}
int main()
{
TestGraphCreate();
return 0;
}
💻测试结果:
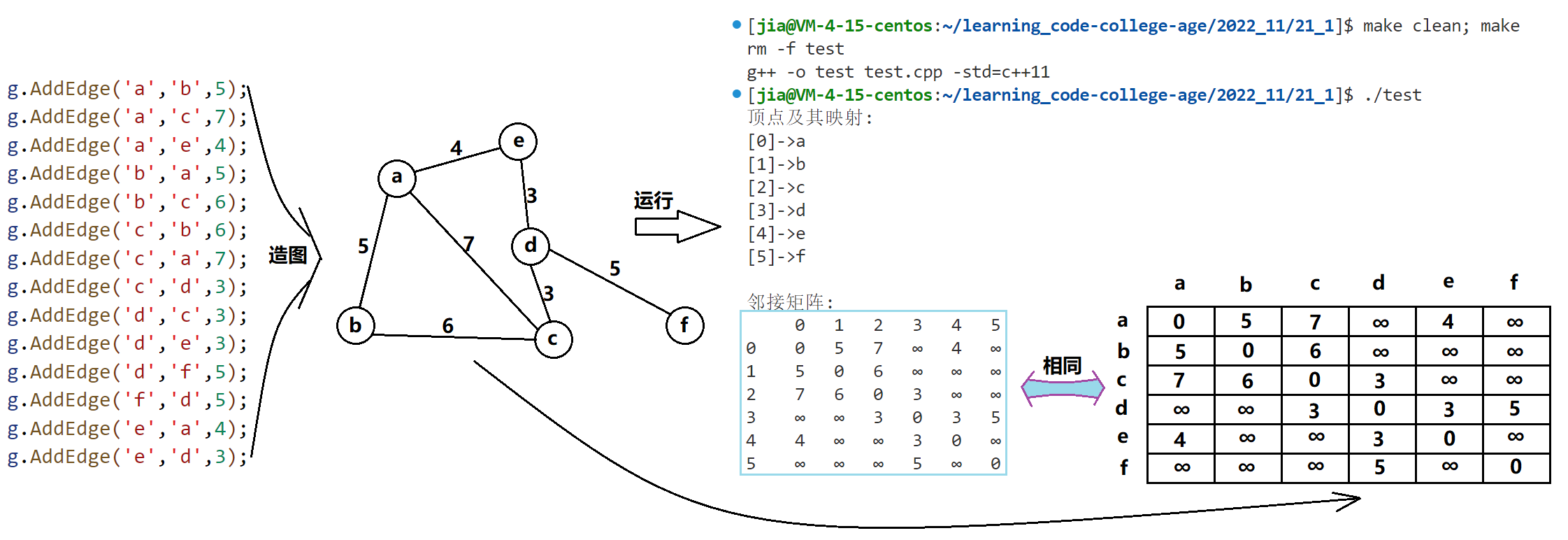
测试无误✔
🍁邻接表式存储的代码实现
#include <iostream>
#include <vector>
#include <map>
#include <string>
#include <cstring>
// 权值
template <class W>
struct Edge//边(弧)的结构体
{
int _dsti; // 终端顶点的下标
W _w; // 权值
Edge<W>* _next;//指向下一个结构体的指针
Edge(int dsti, const W& w)
: _dsti(dsti), _w(w), _next(nullptr)
{}
};
// 顶点的数据类型 权值类型 默认为无向图
template <class V, class W, bool Direction = false>
class Graph
{
typedef Edge<W> Edge;
private:
vector<V> _vertexs; // 顶点集合
map<V, int> _indexMap; // 顶点映射下标
vector<Edge*> _tables; // 邻接表数组,存放的是单链表的头节点
public:
Graph(const V* a, size_t n)//顶点数组与个数传参
{
_vertexs.reserve(n);//初始化顶点数组与下标集
for (size_t i = 0; i < n; ++i)
{
_vertexs.push_back(a[i]);
_indexMap[a[i]] = i;
}
_tables.resize(n, nullptr);//邻接表的初始化
}
size_t GetVertexIndex(const V& v)//获得顶点在顶点数组中的下标
{
auto it = _indexMap.find(v);
if (it != _indexMap.end())
{
return it->second;//找到的话返回下标
}
else
{
throw invalid_argument("顶点不存在");//找不到的话就抛异常
return -1;
}
}
// 参数: 起始顶点 终端顶点 权值
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);//拿到起始顶点映射的下标
size_t dsti = GetVertexIndex(dst);//拿到终端顶点映射的下标
Edge* eg = new Edge(dsti, w);//构建新的边(弧)
//更新对应顶点,头插新边(弧),使其邻接表的头节点更改成新的边(弧),实现新边(弧)的头插保存
eg->_next = _tables[srci];
_tables[srci] = eg;
//无向图的话再进行一次反向链接
if (Direction == false)
{
Edge* eg = new Edge(srci, w);
eg->_next = _tables[dsti];
_tables[dsti] = eg;
}
}
void Print()
{
// 顶点
cout << "顶点及其映射: " << endl;
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]"
<< "->" << _vertexs[i] << endl;
}
cout << endl;
//链表输出
cout << "邻接表输出: " << endl;
for (size_t i = 0; i < _tables.size(); ++i)
{
cout << _vertexs[i] << "->";
Edge* cur = _tables[i];
while (cur)
{
cout << "[" << cur->_dsti << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
};
🍁邻接表造图测试
void TestGraphCreate()
{
const char* str = "abcdef";
Graph<char, int> g(str, strlen(str));
g.AddEdge('a', 'b', 5);
g.AddEdge('a', 'c', 7);
g.AddEdge('a', 'e', 4);
g.AddEdge('b', 'c', 6);
g.AddEdge('c', 'd', 3);
g.AddEdge('d', 'e', 3);
g.AddEdge('d', 'f', 5);
g.Print();
}
int main()
{
link_table::TestGraphCreate();
return 0;
}
💻测试结果:
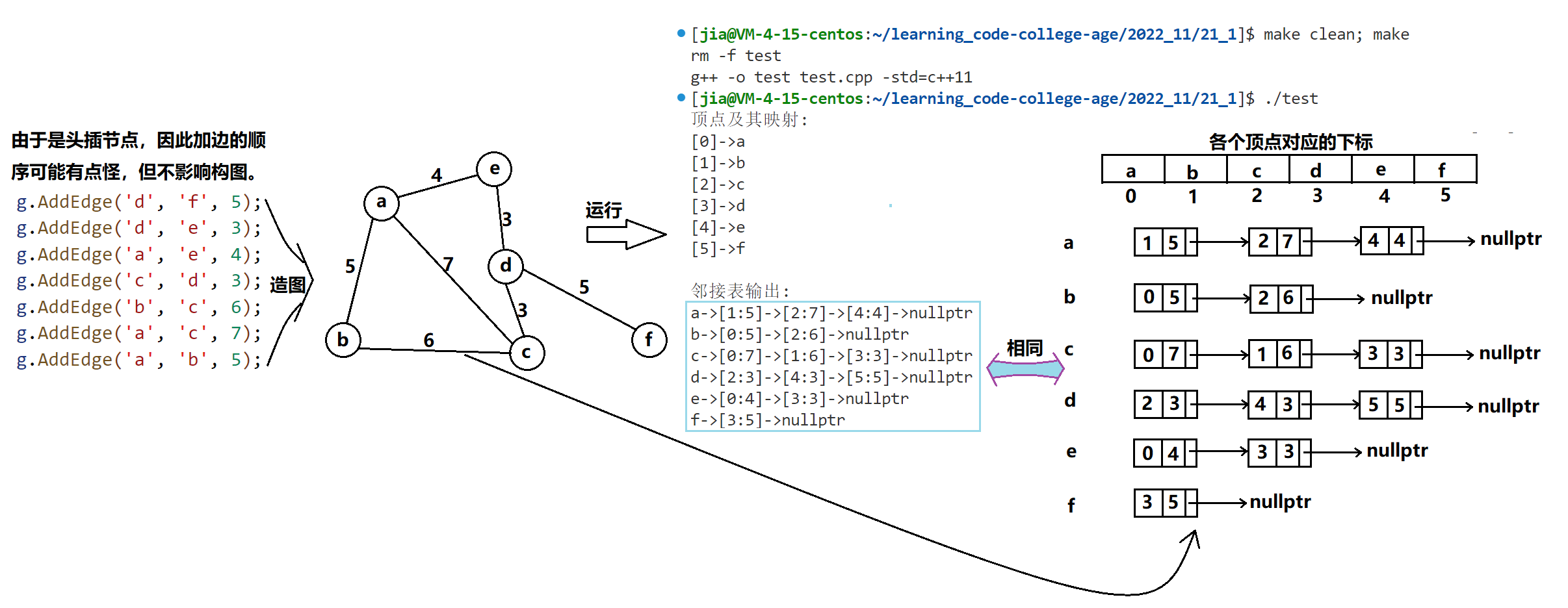
测试无误✔
接下来我们主要以邻接矩阵存储形式来讲解两种遍历方式。
🚩图的深度优先遍历
图的深度遍历和二叉树的深度遍历的思想是一样的,都是“一路到底”的遍历方式,直到遍历完一路之后,再回退到最开始深度遍历时由于分叉而没遍历的路径,继续深度遍历。
我先给出代码,再结合代码下面的图会更好理解一点。
🍁代码实现
void _DFS(size_t srci, vector<bool>& visited)//递归函数
{
visited[srci] = true;//进到函数时就直接访问顶点并设置成已访问
cout << _vertexs[srci] << " ";//输出节点就算是访问过了
for (size_t i = 0; i < _vertexs.size(); ++i)//for循环遍历此时顶点的邻接点,递归之后回到此顶点的循环内继续找邻接点,
{ //for循环内递归,这就是能够将每个分支都一路到底的原因。
if (visited[i] == false && _matrix[srci][i] != MAX_W)//顶点没访问过且权值不是∞,就递归式的往下走
{
_DFS(i, visited);
}
}
}
//深度优先级遍历 参数:起始顶点x
void DFS(const V& x)
{
size_t n = _vertexs.size();
size_t srci = GetVertexIndex(x);//拿到顶点映射的下标
vector<bool> visited(n, false);//定义一个bool数组,与顶点形成映射,初始时设置成未访问。
_DFS(srci, visited);//嵌套一层,方便传自己想要的参数来实现递归
}
例如:
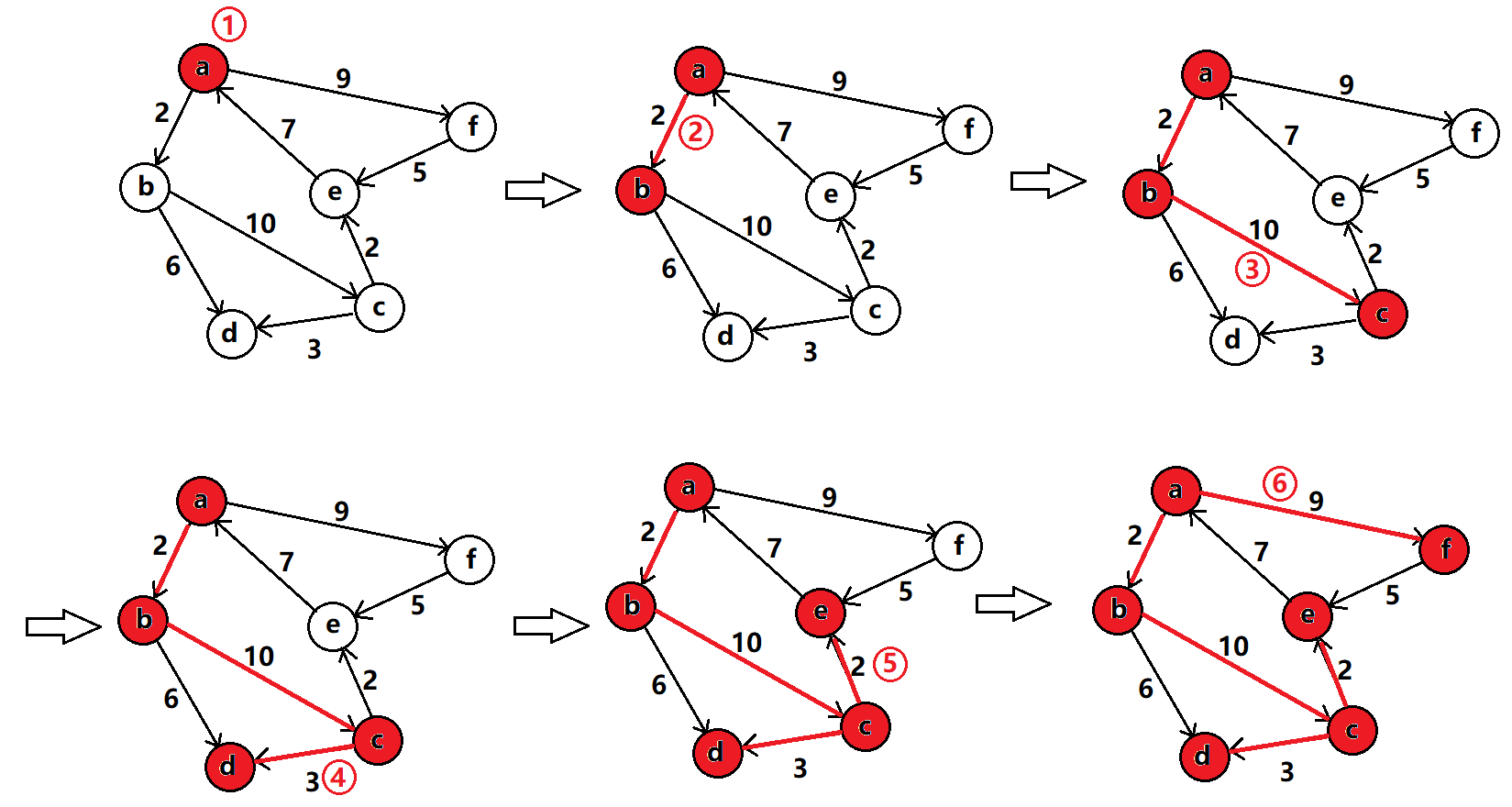
🍁代码测试
就以上面的流程图造图遍历一下试试看。
void TestDFS()
{
const char* str = "abcdef";
Graph<char, int,INT32_MAX,true> g(str, strlen(str));//构造有向图
g.AddEdge('a', 'b', 2);
g.AddEdge('a', 'f', 9);
g.AddEdge('b', 'c', 10);
g.AddEdge('b', 'd', 6);
g.AddEdge('c', 'd', 3);
g.AddEdge('c', 'e', 2);
g.AddEdge('e', 'a', 7);
g.AddEdge('f', 'e', 5);
g.Print();
g.DFS('a');
}
int main()
{
TestDFS();
return 0;
}
💻测试结果:

🚩图的广度优先遍历
广度优先级遍历:层层遍历各个顶点。
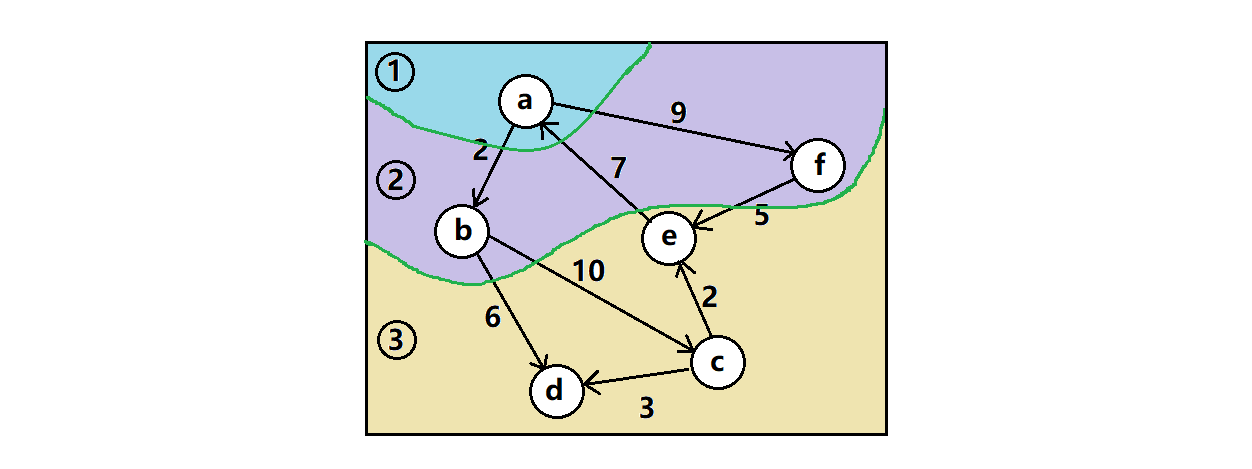
同样是借助二叉树的广度优先遍历思想,要想一层一层的访问各顶点,就得控制顶点的优先级。只要顶点的邻接点被看到了,就认为占住了接拉来访问的位置,不访问完他们就不能访问这些邻接点的邻接点。意思就是要排队访问,谁先来谁先走。这不就是队列吗?所以我们就用队列来实现图的广度。
🍁代码实现
//从某一个顶点的广度优先级遍历
void BFS(const V& src)
{
size_t n = _vertexs.size();
size_t srci = GetVertexIndex(src);//获得初始顶点映射下标
queue<int> q; //创建队列控制顶点层序排队
vector<bool> visited(n, false); //控制顶点是否访问过
size_t levesize = 1; //当前层的节点个数,初始为1
q.push(srci);//入队初始顶点
//设置初始顶点为已访问。注意,只要进队就意味着肯定要被访问,直接先设为已访问,避免多次重复入队。
visited[srci] = true;
while (!q.empty())//只要队不为空,就得遍历下去
{
for (size_t i = 0; i < levesize; ++i)//在当前层中控制顶点的出队和入队
{
int front = q.front();//拿队头的顶点
q.pop();
cout << _vertexs[front] << " ";//输出就是访问的意思
for (size_t j = 0; j < n; ++j)//找当前顶点的邻接点
{
if (_matrix[front][j] != MAX_W && _matrix[front][j] != W())
{
if (visited[j] == false)//走到这,表示找到了下一层要被访问的顶点,就入队。
{
q.push(j);
visited[j] = true;//入队就意味着肯定要被访问,直接设置其为已访问
}
}
}
}
cout << endl;//访问完当前层才换行输出
levesize = q.size();//重新跟新层数
}
}
🍁代码测试
void TestBFS()
{
const char* str = "abcdef";
Graph<char, int, INT32_MAX, true> g(str, strlen(str));
g.AddEdge('a', 'b', 2);
g.AddEdge('a', 'f', 9);
g.AddEdge('b', 'c', 10);
g.AddEdge('b', 'd', 6);
g.AddEdge('c', 'd', 3);
g.AddEdge('c', 'e', 2);
g.AddEdge('e', 'a', 7);
g.AddEdge('f', 'e', 5);
g.BFS('a');
}
int main()
{
TestBFS();
return 0;
}
💻测试结果:
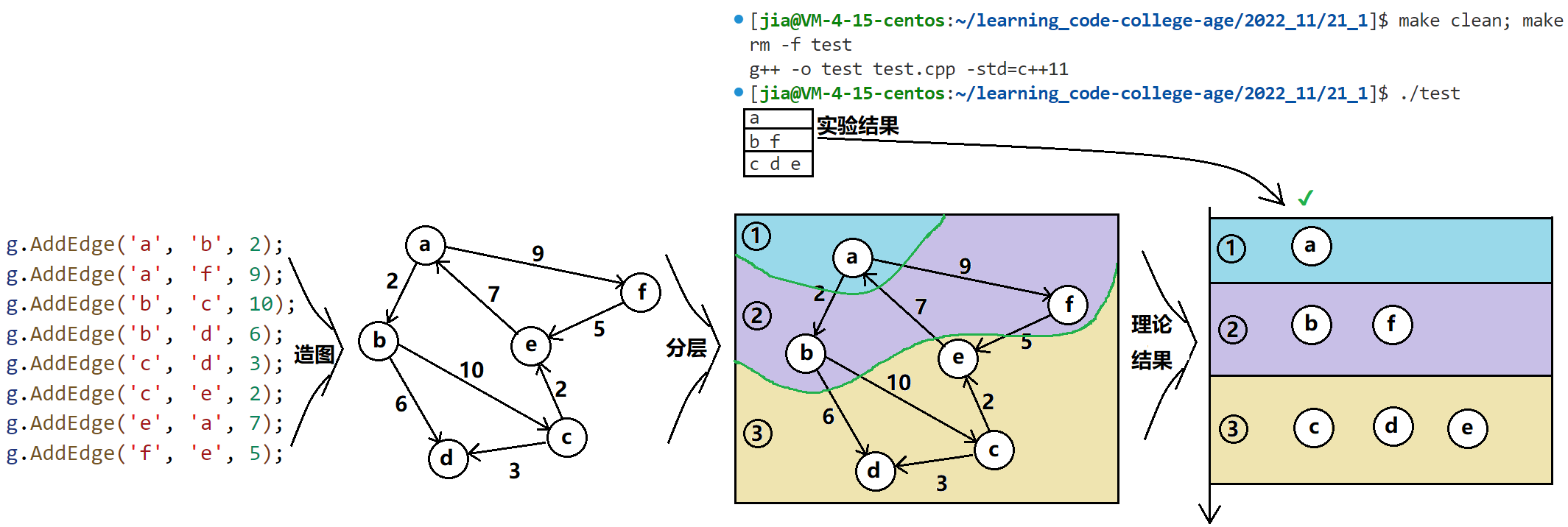
🚩总结
图的存储方式并不是最重要的,最重要的是理解与运用顶点与邻接点的关系。至于衍生出来的一系列问题,那都是基于基本性质的应用和组合。这次讲的两种遍历方式只是图知识的冰山一角,更多有趣又巧妙的算法与问题会在接下来的几篇博客中持续更新,记得持续关注哦,喵🐾~