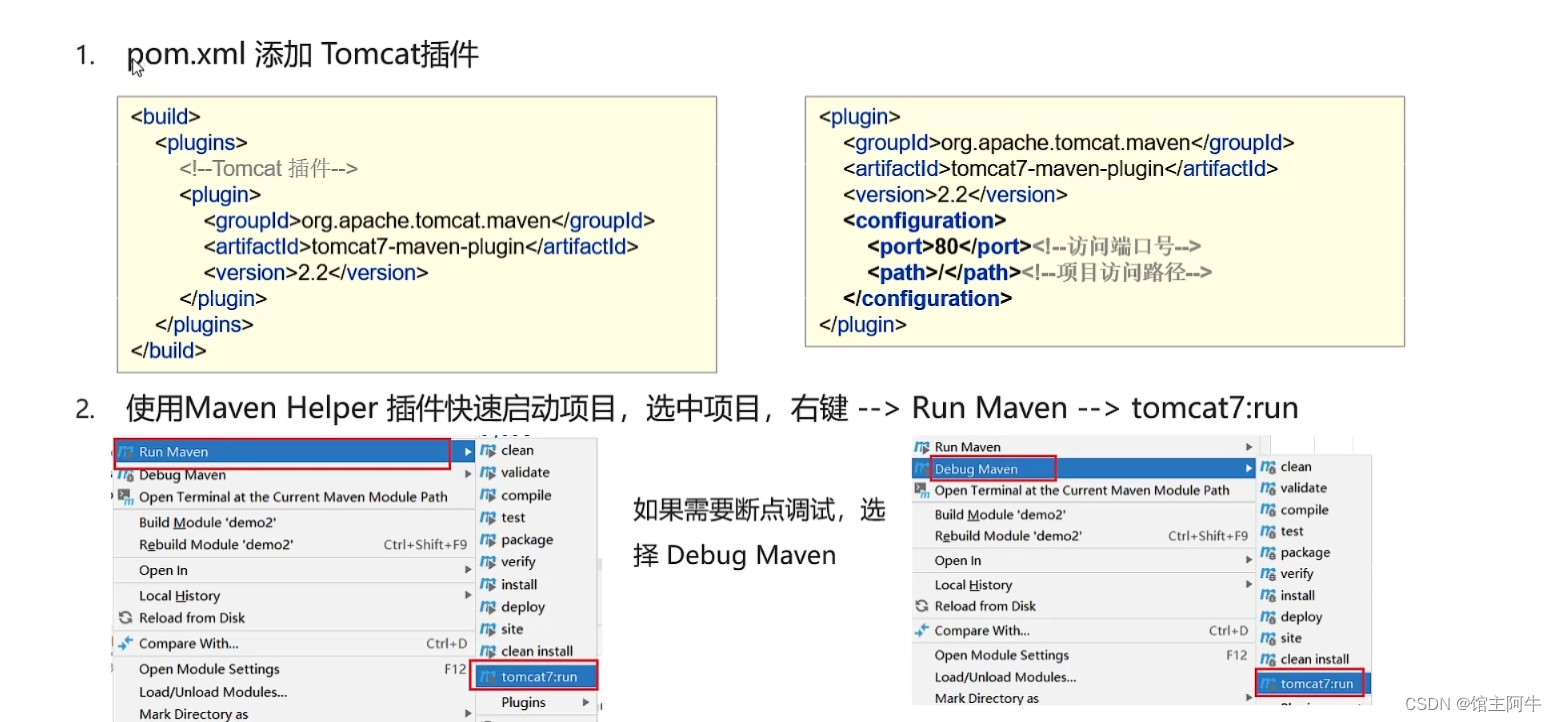
基频归一化
基频为什么要归一化?为了消除人际随机差异,提取恒定参数,在语际变异中找到共性。
引言
声调的主要载体就是基频。但是对声调的感知会因人而异,例如某个听感上的高升调,不同的调查人员可能会分别描写成 [24]、[25]、[35]。他们可能都对,因为声调描写中的这种不确定性实际上反映了两个基本事实:其一,不同的发音人可能有发音差别(甚至同一个人说两次都不一样);二,描写工具(五度制)本身并未对这些差异有精确定义。
但是,另一方面,这个语言信号,不管男女老少谁说,也不管是尖叫乱喊还是一字一顿,在听者耳中的语言内容是一样的。这说明在感知层面有不变的范畴存在,这种感知范畴有可能用作音韵学层面的对立特征。
归一化的主要目的就是消除人际随机差异,提取恒定参数,即滤掉个人特性,获得具有语言学意义的信息。
个人各自的归一化的物理含义就是以本人的频域作为坐标,以显示本人的各个声调在此空间中的分布。
基频归一化的作用:
- 把对声调的感觉描绘建立在标准化的定量描写的基础上。
- 减录音时的发音风格(正式、随意、紧张)差异。
方法
归一化一般有两个步骤,一是在坐标上作平移,一是压缩或扩大频域。基本公式如下:

线性法:z-score,频域分数,频域比例,
对数法:对数半音差比,对数z-score、对数频域比例
基频平滑
目前声调识别有很多方法,但一般都基于基音的轮廓信息。基音是指声带震动的基频,它是随着时间和发音高低而不断变化的。基音变化的不同轨迹也就是我们所说的声调。因此声调识别是以提取基音为基础的。在提取基音的过程中,无论采用哪一种方法提取的基音频率轨迹与真实的基音频率轨迹都不可能完全吻合。
实际情况是,大部分段落吻合,而在一些局部段落或区域中有一个或几个基频估值偏离甚至远离正常轨迹,这种情况我们称为基音轨迹产生了若干错误点,或称基频野点。这些错误点主要包括倍频点、半频点和随机错误点。为了去除这些野点,就需要对基频曲线做平滑处理。
常见方法:线性平滑、中值平滑、线性插值方法