前言
在工作生活中,我们时常会遇到一些性能问题:比如手机用久了,在滑动窗口或点击 APP 时会出现页面反应慢、卡顿等情况;比如运行在某台服务器上进程的某些性能指标(影响用户体验的 PCT99 指标等)不达预期,产生告警等;造成性能问题的原因多种多样,可能是网络延迟高、磁盘 IO 慢、调度延迟高、内存回收等,这些最终都可能影响到用户态进程,进而被用户感知。
在 Linux 服务器场景中,内存是影响性能的主要因素之一,本文从内存管理的角度,总结归纳了一些常见的影响因素(比如内存回收、Page Fault 增多、跨 NUMA 内存访问等),并介绍其对应的调优方法。
内存回收
操作系统总是会尽可能利用速度更快的存储介质来缓存速度更慢的存储介质中的内容,这样就可以显著的提高用户访问速度。比如,我们的文件一般都存储在磁盘上,磁盘对于程序运行的内存来说速度很慢,因此操作系统在读写文件时,都会将磁盘中的文件内容缓存到内存上(也叫做 page cache),这样下次再读取到相同内容时就可以直接从内存中读取,不需要再去访问速度更慢的磁盘,从而大大提高文件的读写效率。上述情况需要在内存资源充足的前提条件下,然而在内存资源紧缺时,操作系统自身难保,会选择尽可能回收这些缓存的内存,将其用到更重要的任务中去。这时候,如果用户再去访问这些文件,就需要访问磁盘,如果此时磁盘也很繁忙,那么用户就会感受到明显的卡顿,也就是性能变差了。
在 Linux 系统中,内存回收分为两个层面:整机和 memory cgroup。
在整机层面
设置了三条水线:min、low、high;当系统 free 内存降到 low 水线以下时,系统会唤醒kswapd 线程进行异步内存回收,一直回收到 high 水线为止,这种情况不会阻塞正在进行内存分配的进程;但如果 free 内存降到了 min 水线以下,就需要阻塞内存分配进程进行回收,不然就有 OOM(out of memory)的风险,这种情况下被阻塞进程的内存分配延迟就会提高,从而感受到卡顿。
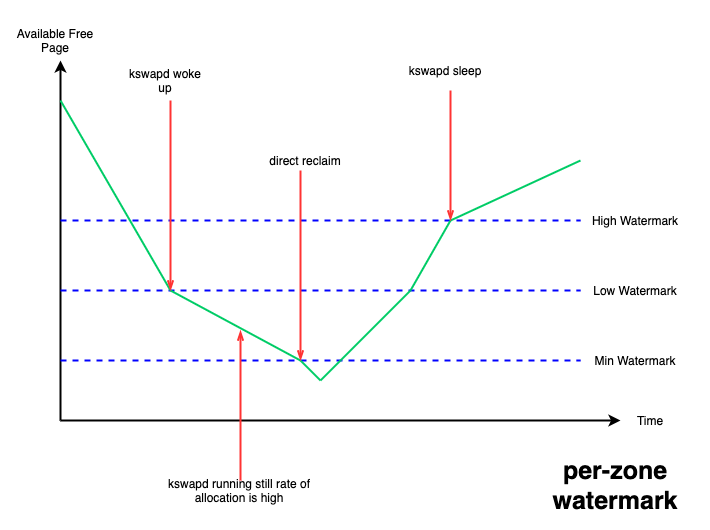
图 1. per-zone watermark
这些水线可以通过内核提供的 /proc/sys/vm/watermark_scale_factor 接口来进行调整,该接口合法取值的范围为 [0, 1000],默认为 10,当该值设置为 1000 时,意味着 low 与 min 水线,以及 high 与 low 水线间的差值都为总内存的 10% (1000/10000) 。
针对 page cache 型的业务场景,我们可以通过该接口抬高 low 水线,从而更早的唤醒 kswapd 来进行异步的内存回收,减少 free 内存降到 min 水线以下的概率,从而避免阻塞到业务进程,以保证影响业务的性能指标。
在 memory cgroup 层面
目前内核没有设置水线的概念,当内存使用达到 memory cgroup 的内存限制后,会阻塞当前进程进行内存回收。不过内核在 v5.19内核 中为 memory cgroup提供了 memory.reclaim 接口,用户可以向该接口写入想要回收的内存大小,来提早触发 memory cgroup 进行内存回收,以避免阻塞 memory cgroup 中的进程。
Huge Page
内存作为宝贵的系统资源,一般都采用延迟分配的方式,应用程序第一次向分配的内存写入数据的时候会触发 Page Fault,此时才会真正的分配物理页,并将物理页帧填入页表,从而与虚拟地址建立映射。
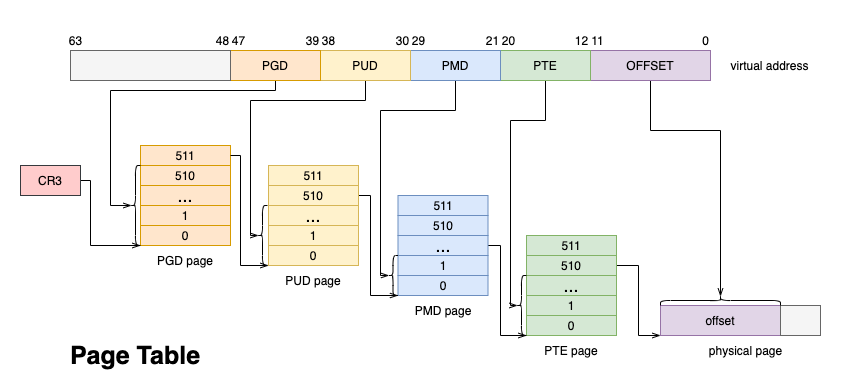
图 2. Page Table
此后,每次 CPU 访问内存,都需要通过 MMU 遍历页表将虚拟地址转换成物理地址。为了加速这一过程,一般都会使用 TLB(Translation-Lookaside Buffer)来缓存虚拟地址到物理地址的映射关系,只有 TLB cache miss 的时候,才会遍历页表进行查找。
页的默认大小一般为 4K,随着应用程序越来越庞大,使用的内存越来越多,内存的分配与地址翻译对性能的影响越加明显。试想,每次访问新的 4K 页面都会触发 Page Fault,2M 的页面就需要触发 512 次才能完成分配。
另外 TLB cache 的大小有限,过多的映射关系势必会产生 cacheline 的冲刷,被冲刷的虚拟地址下次访问时又会产生 TLB miss,又需要遍历页表才能获取物理地址。
对此,Linux 内核提供了大页机制 。上图的 4 级页表中,每个 PTE entry 映射的物理页就是 4K,如果采用 PMD entry 直接映射物理页,则一次 Page Fault 可以直接分配并映射 2M 的大页,并且只需要一个 TLB entry 即可存储这 2M 内存的映射关系,这样可以大幅提升内存分配与地址翻译的速度 。
因此,一般推荐占用大内存应用程序使用大页机制分配内存 。当然大页也会有弊端:比如初始化耗时高,进程内存占用可能变高等。
可以使用 perf 工具对比进程使用大页前后的 PageFault 次数的变化:
perf stat -e page-faults -p-- sleep 5目前内核提供了两种大页机制,一种是需要提前预留的静态大页形式,另一种是透明大页(THP, Transparent Huge Page) 形式。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
1. 静态大页
首先来看静态大页,也叫做 HugeTLB。静态大页可以设置 cmdline 参数在系统启动阶段预留,比如指定大页 size 为 2M,一共预留 512 个这样的大页:
hugepagesz=2M hugepages=512还可以在系统运行时动态预留,但该方式可能因为系统中没有足够的连续内存而预留失败。
-
预留默认 size(可以通过 cmdline 参数 default_hugepagesz=指定size)的大页:
echo 20 > /proc/sys/vm/nr_hugepages-
预留特定 size 的大页:
echo 5 > /sys/kernel/mm/hugepages/hugepages-*/nr_hugepages-
预留特定 node 上的大页:
echo 5 > /sys/devices/system/node/node*/hugepages/hugepages-*/nr_hugepages当预留的大页个数小于已存在的个数,则会释放多余大页(前提是未被使用)。
编程中可以使用 mmap(MAP_HUGETLB) 申请内存。详细使用可以参考内核文档 :https://www.kernel.org/doc/Documentation/admin-guide/mm/hugetlbpage.rst
这种大页的优点是一旦预留成功,就可以满足进程的分配请求,还避免该部分内存被回收;缺点是:
(1) 需要用户显式地指定预留的大小和数量。
(2) 需要应用程序适配,比如:
-
mmap、shmget 时指定 MAP_HUGETLB;
-
挂载 hugetlbfs,然后 open 并 mmap
当然也可以使用开源 libhugetlbfs.so,这样无需修改应用程序
预留太多大页内存后,free 内存大幅减少,容易触发系统内存回收甚至 OOM
紧急情况下可以手动减少 nr_hugepages,将未使用的大页释放回系统;也可以使用 v5.7 引入的HugeTLB + CMA 方式,细节读者可以自行查阅。
2. 透明大页
再来看透明大页,在 THP always 模式下,会在 Page Fault 过程中,为符合要求的 vma 尽量分配大页进行映射;如果此时分配大页失败,比如整机物理内存碎片化严重,无法分配出连续的大页内存,那么就会 fallback 到普通的 4K 进行映射,但会记录下该进程的地址空间 mm_struct;然后 THP 会在后台启动khugepaged 线程,定期扫描这些记录的 mm_struct,并进行合页操作。因为此时可能已经能分配出大页内存了,那么就可以将此前 fallback 的 4K 小页映射转换为大页映射,以提高程序性能。整个过程完全不需要用户进程参与,对用户进程是透明的,因此称为透明大页。
虽然透明大页使用起来非常方便、智能,但也有一定的代价:
(1)进程内存占用可能远大所需:因为每次Page Fault 都尽量分配大页,即使此时应用程序只读写几KB
(2)可能造成性能抖动:
-
在第 1 种进程内存占用可能远大所需的情况下,可能造成系统 free 内存更少,更容易触发内存回收;系统内存也更容易碎片化。
-
khugepaged 线程合页时,容易触发页面规整甚至内存回收,该过程费时费力,容易造成 sys cpu 上升。
-
mmap lock 本身是目前内核的一个性能瓶颈,应当尽量避免 write lock 的持有,但 THP 合页等操作都会持有写锁,且耗时较长(数据拷贝等),容易激化 mmap lock 锁竞争,影响性能。
因此 THP 还支持 madvise 模式,该模式需要应用程序指定使用大页的地址范围,内核只对指定的地址范围做 THP 相关的操作。这样可以更加针对性、更加细致地优化特定应用程序的性能,又不至于造成反向的负面影响。
可以通过 cmdline 参数和 sysfs 接口设置 THP 的模式:
cmdline 参数:
transparent_hugepage=madvisesysfs 接口:
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled详细使用可以参考内核文档 : https://www.kernel.org/doc/Documentation/admin-guide/mm/transhuge.rst
mmap_lock 锁
上一小节有提到 mmap_lock 锁,该锁是内存管理中的一把知名的大锁,保护了诸如mm_struct 结构体成员、 vm_area_struct 结构体成员、页表释放等很多变量与操作。
mmap_lock 的实现是读写信号量 ,当写锁被持有时,所有的其他读锁与写锁路径都会被阻塞。Linux 内核已经尽可能减少了写锁的持有场景以及时间,但不少场景还是不可避免的需要持有写锁,比如 mmap 以及 munmap 路径、mremap 路径和 THP 转换大页映射路径等场景。
应用程序应该避免频繁的调用会持有 mmap_lock 写锁的系统调用 (syscall) ,比如有时可以使用 madvise(MADV_DONTNEED)释放物理内存,该参数下,madvise 相比 munmap 只持有 mmap_lock 的读锁,并且只释放物理内存,不会释放 VMA 区域,因此可以再次访问对应的虚拟地址范围,而不需要重新调用 mmap 函数。
另外对于 MADV_DONTNEED,再次访问还是会触发 Page Fault 分配物理内存并填充页表,该操作也有一定的性能损耗 。如果想进一步减少这部分损耗,可以改为 MADV_FREE 参数,该参数也只会持有 mmap_lock 的读锁,区别在于不会立刻释放物理内存,会等到内存紧张时才进行释放,如果在释放之前再次被访问则无需再次分配内存,进而提高内存访问速度。
一般 mmap_lock 锁竞争激烈会导致很多 D 状态进程(TASK_UNINTERRUPTIBLE),这些 D 进程都是进程组的其他线程在等待写锁释放。因此可以打印出所有 D 进程的调用栈,看是否有大量 mmap_lock 的等待。
for i in `ps -aux | grep " D" | awk '{ print $2}'`; do echo $i; cat /proc/$i/stack; done内核社区专门封装了 mmap_lock 相关函数,并在其中增加了 tracepoint,这样可以使用 bpftrace 等工具统计持有写锁的进程、调用栈等,方便排查问题,确定优化方向。
bpftrace -e 'tracepoint:mmap_lock:mmap_lock_start_locking /args->write == true/{ @[comm, kstack] = count();}'跨 numa 内存访问
在 NUMA 架构下,CPU 访问本地 node 内存的速度要大于远端 node,因此应用程序应尽可能访问本地 node 上的内存。可以通过 numastat 工具查看 node 间的内存分配情况:
-
观察整机是否有很多 other_node 指标(远端内存访问)上涨:
watch -n 1 numastat -s-
查看单个进程在各个node上的内存分配情况:
numastat -p1. 绑 node
可以通过 numactl 等工具把进程绑定在某个 node 以及对应的 CPU 上,这样该进程只会从该本地 node 上分配内存。
但这样做也有相应的弊端,比如:该 node 剩余内存不够时,进程也无法从其他 node 上分配内存,只能期待内存回收后释放足够的内存,而如果进入直接内存回收会阻塞内存分配,就会有一定的性能损耗。
此外,进程组的线程数较多时,如果都绑定在一个 node 的 CPU 上,可能会造成 CPU 瓶颈,该损耗可能比远端 node 内存访问还大,比如 ngnix 进程与网卡就推荐绑定在不同的 node 上,这样虽然网卡收包时分配的内存在远端 node 上,但减少了本地 node 的 CPU 上的网卡中断,反而可以获得更好的性能提升。
2. numa balancing
内核还提供了 numa balancing 机制,可以通过 /proc/sys/kernel/numa_balancing 文件或者 cmdline 参数 numa_balancing=进行开启。
该机制可以动态的将进程访问的 page 从远端 node 迁移到本地 node 上,从而使进程可以尽可能的访问本地内存。
但该机制实现也有相应的代价,在 page 的迁移是通过 Page Fault 机制实现的,会有相应的性能损耗;另外如果迁移时找不到合适的目标 node,可能还会把进程迁移到正在访问的 page 的 node 的 CPU 上,这可能还会导致 cpu cache miss,从而对性能造成更大的影响。
因此需要根据业务进程的具体行为,来决定是否开启 numa balancing 功能 。
总结
性能优化一直是大家关注的话题,其优化方向涉及到 CPU 调度、内存、IO等,本文重点针对内存优化提出了几点思路。但是鱼与熊掌不可兼得,文章提到的调优操作都有各自的优点和缺点,不存在一个适用于所有情况的优化方法。针对于不同的 workload,需要分析出具体的性能瓶颈,从而采取对应的调优方法,不能一刀切的进行设置 。在没有发现明显性能抖动的情况下,往往可以继续保持当前配置。