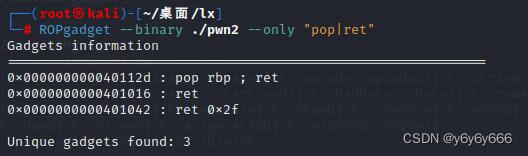
1、音频分⽚(plane)与打包(packed)
解码出来的AVFrame,它的data字段放的是视频像素数据或者音频的PCM裸流数据,linesize字段放的是对齐后的画面行长度或者音频的分片长度:
/**
* For video, size in bytes of each picture line.
* For audio, size in bytes of each plane.
*
* For audio, only linesize[0] may be set. For planar audio, each channel
* plane must be the same size.
*
* For video the linesizes should be multiples of the CPUs alignment
* preference, this is 16 or 32 for modern desktop CPUs.
* Some code requires such alignment other code can be slower without
* correct alignment, for yet other it makes no difference.
*
* @note The linesize may be larger than the size of usable data -- there
* may be extra padding present for performance reasons.
*/
intlinesize[AV_NUM_DATA_POINTERS];
视频相关的在之前的博客中有介绍,音频的话可以看到它只有linesize[0]会被设置,如果有多个分片,每个分片的size都是相等的。
要理解这里的分片size,先要理解音频数据的两种存储格式分⽚(plane)与打包(packed)。以常见的双声道音频为例子,
分⽚存储的数据左声道和右声道分开存储,左声道存储在data[0],右声道存储在data[1],他们的数据buffer的size都是linesize[0]。
打包存储的数据按照LRLRLR...的形式交替存储在data[0]中,这个数据buffer的size是linesize[0]。
AVSampleFormat枚举音频的格式,带P后缀的格式是分配存储的:
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
不带P后缀的格式是打包存储的:
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
2、音频数据的实际长度
这里有个坑点备注里面也写的很清楚了,linesize标明的大小可能会大于实际的音视频数据大小,因为可能会有额外的填充。
@note The linesize may be larger than the size of usable data -- there
may be extra padding present for performance reasons.
所以音频数据实际的长度需要用音频的参数计算出来:
intchannelCount=audioStreamDecoder.GetChannelCount();
intbytePerSample=audioStreamDecoder.GetBytePerSample();
intsize=frame->nb_samples*channelCount*bytePerSample;
3、音频格式转换
视频之前的demo中已经可以使用OpenGL播放,而音频可以交给OpenSL来播放,之前我写过一篇《OpenSL ES 学习笔记》详细的使用细节我就不展开介绍了,直接将代码拷贝来使用。
但是由于OpenSLES只支持打包的几种音频格式:
#define SL_PCMSAMPLEFORMAT_FIXED_8 ((SLuint16) 0x0008)
#define SL_PCMSAMPLEFORMAT_FIXED_16 ((SLuint16) 0x0010)
#define SL_PCMSAMPLEFORMAT_FIXED_20 ((SLuint16) 0x0014)
#define SL_PCMSAMPLEFORMAT_FIXED_24 ((SLuint16) 0x0018)
#define SL_PCMSAMPLEFORMAT_FIXED_28 ((SLuint16) 0x001C)
#define SL_PCMSAMPLEFORMAT_FIXED_32 ((SLuint16) 0x0020)
这里我们指的AudioStreamDecoder的目标格式为AV_SAMPLE_FMT_S16,如果原始音频格式不是它,则对音频做转码:
audioStreamDecoder.Init(reader, audioIndex, AVSampleFormat::AV_SAMPLE_FMT_S16);
boolAudioStreamDecoder::Init(MediaReader*reader, intstreamIndex, AVSampleFormatsampleFormat) {
...
boolresult=StreamDecoder::Init(reader, streamIndex);
if (sampleFormat==AVSampleFormat::AV_SAMPLE_FMT_NONE) {
mSampleFormat=mCodecContext->sample_fmt;
} else {
mSampleFormat=sampleFormat;
}
if (mSampleFormat!=mCodecContext->sample_fmt) {
mSwrContext=swr_alloc_set_opts(
NULL,
mCodecContext->channel_layout,
mSampleFormat,
mCodecContext->sample_rate,
mCodecContext->channel_layout,
mCodecContext->sample_fmt,
mCodecContext->sample_rate,
0,
NULL);
swr_init(mSwrContext);
// 虽然前面的swr_alloc_set_opts已经设置了这几个参数
// 但是用于接收的AVFrame不设置这几个参数也会接收不到数据
// 原因是后面的swr_convert_frame函数会通过av_frame_get_buffer创建数据的buff
// 而av_frame_get_buffer需要AVFrame设置好这些参数去计算buff的大小
mSwrFrame=av_frame_alloc();
mSwrFrame->channel_layout=mCodecContext->channel_layout;
mSwrFrame->sample_rate=mCodecContext->sample_rate;
mSwrFrame->format=mSampleFormat;
}
returnresult;
}
AVFrame*AudioStreamDecoder::NextFrame() {
AVFrame*frame=StreamDecoder::NextFrame();
if (NULL==frame) {
returnNULL;
}
if (NULL==mSwrContext) {
returnframe;
}
swr_convert_frame(mSwrContext, mSwrFrame, frame);
returnmSwrFrame;
}
这里我们使用swr_convert_frame进行转码:
intswr_convert_frame(SwrContext*swr, // 转码上下文
AVFrame*output, // 转码后输出到这个AVFrame
constAVFrame*input// 原始输入AVFrame
);
这个方法要求输入输出的AVFrame都设置了channel_layout、 sample_rate、format参数,然后回调用av_frame_get_buffer为output创建数据buff:
/**
* ...
*
* Input and output AVFrames must have channel_layout, sample_rate and format set.
*
* If the output AVFrame does not have the data pointers allocated the nb_samples
* field will be set using av_frame_get_buffer()
* is called to allocate the frame.
* ...
*/
intswr_convert_frame(SwrContext*swr,
AVFrame*output, constAVFrame*input);
SwrContext为转码的上下文,通过swr_alloc_set_opts和swr_init创建,需要把转码前后的音频channel_layout、 sample_rate、format信息传入:
structSwrContext*swr_alloc_set_opts(structSwrContext*s,
int64_tout_ch_layout, enumAVSampleFormatout_sample_fmt, intout_sample_rate,
int64_t in_ch_layout, enumAVSampleFormat in_sample_fmt, int in_sample_rate,
intlog_offset, void*log_ctx);
intswr_init(structSwrContext*s);
4、视频格式转换
之前的demo里面我们判断了视频格式不为AV_PIX_FMT_YUV420P则直接报错,这里我们仿照音频转换的例子,判断原始视频格式不为AV_PIX_FMT_YUV420P则使用sws_scale进行格式转换:
boolVideoStreamDecoder::Init(MediaReader*reader, intstreamIndex, AVPixelFormatpixelFormat) {
...
boolresult=StreamDecoder::Init(reader, streamIndex);
if (AVPixelFormat::AV_PIX_FMT_NONE==pixelFormat) {
mPixelFormat=mCodecContext->pix_fmt;
} else {
mPixelFormat=pixelFormat;
}
if (mPixelFormat!=mCodecContext->pix_fmt) {
intwidth=mCodecContext->width;
intheight=mCodecContext->height;
mSwrFrame=av_frame_alloc();
// 方式一,使用av_frame_get_buffer创建数据存储空间,av_frame_free的时候会自动释放
mSwrFrame->width=width;
mSwrFrame->height=height;
mSwrFrame->format=mPixelFormat;
av_frame_get_buffer(mSwrFrame, 0);
// 方式二,使用av_image_fill_arrays指定存储空间,需要我们手动调用av_malloc、av_free去创建、释放空间
// unsigned char* buffer = (unsigned char *)av_malloc(
// av_image_get_buffer_size(mPixelFormat, width, height, 16)
// );
// av_image_fill_arrays(mSwrFrame->data, mSwrFrame->linesize, buffer, mPixelFormat, width, height, 16);
mSwsContext=sws_getContext(
mCodecContext->width, mCodecContext->height, mCodecContext->pix_fmt,
width, height, mPixelFormat, SWS_BICUBIC,
NULL, NULL, NULL
);
}
returnresult;
}
AVFrame*VideoStreamDecoder::NextFrame() {
AVFrame*frame=StreamDecoder::NextFrame();
if (NULL==frame) {
returnNULL;
}
if (NULL==mSwsContext) {
returnframe;
}
sws_scale(mSwsContext, frame->data,
frame->linesize, 0, mCodecContext->height,
mSwrFrame->data, mSwrFrame->linesize);
returnmSwrFrame;
}
sws_scale看名字虽然是缩放,但它实际上也会对format进行转换,转换的参数由SwsContext提供:
structSwsContext*sws_getContext(
intsrcW, // 源图像的宽
intsrcH, // 源图像的高
enumAVPixelFormatsrcFormat, // 源图像的格式
intdstW, // 目标图像的宽
intdstH, // 目标图像的高
enumAVPixelFormatdstFormat, // 目标图像的格式
intflags, // 暂时可忽略
SwsFilter*srcFilter, // 暂时可忽略
SwsFilter*dstFilter, // 暂时可忽略
constdouble*param // 暂时可忽略
);
sws_scale支持区域转码,可以如我们的demo将整幅图像进行转码,也可以将图像切成多个区域分别转码,这样方便实用多线程加快转码效率:
intsws_scale(
structSwsContext*c, // 转码上下文
constuint8_t*constsrcSlice[], // 源画面区域像素数据,对应源AVFrame的data字段
constintsrcStride[], // 源画面区域行宽数据,对应源AVFrame的linesize字段
intsrcSliceY, // 源画面区域起始Y坐标,用于计算应该放到目标图像的哪个位置
intsrcSliceH, // 源画面区域行数,用于计算应该放到目标图像的哪个位置
uint8_t*constdst[], // 转码后图像数据存储,对应目标AVFrame的data字段
constintdstStride[] // 转码后行宽数据存储,对应目标AVFrame的linesize字段
);
srcSlice和srcStride存储了源图像部分区域的图像数据,srcSliceY和srcSliceH告诉转码器这部分区域的坐标范围,用于计算偏移量将转码结果存放到dst和dstStride中。
例如下面的代码就将一幅完整的图像分成上下两部分分别进行转码:
inthalfHeight=mCodecContext->height/2;
// 转码上半部分图像
uint8_t*dataTop[AV_NUM_DATA_POINTERS] = {
frame->data[0],
frame->data[1],
frame->data[2]
};
sws_scale(mSwsContext, dataTop,
frame->linesize, 0,
halfHeight,
mSwrFrame->data, mSwrFrame->linesize);
// 转码下半部分图像
uint8_t*dataBottom[AV_NUM_DATA_POINTERS] = {
frame->data[0] + (frame->linesize[0] *halfHeight),
frame->data[1] + (frame->linesize[1] *halfHeight),
frame->data[2] + (frame->linesize[2] *halfHeight),
};
sws_scale(mSwsContext, dataBottom,
frame->linesize, halfHeight,
mCodecContext->height-halfHeight,
mSwrFrame->data, mSwrFrame->linesize);
5、AVFrame内存管理机制
我们创建了一个新的AVFrame用于接收转码后的图像:
mSwrFrame=av_frame_alloc();
// 方式一,使用av_frame_get_buffer创建数据存储空间,av_frame_free的时候会自动释放
mSwrFrame->width=width;
mSwrFrame->height=height;
mSwrFrame->format=mPixelFormat;
av_frame_get_buffer(mSwrFrame, 0);
// 方式二,使用av_image_fill_arrays指定存储空间,需要我们手动调用av_malloc、av_free去创建、释放buffer的空间
// int bufferSize = av_image_get_buffer_size(mPixelFormat, width, height, 16);
// unsigned char* buffer = (unsigned char *)av_malloc(bufferSize);
// av_image_fill_arrays(mSwrFrame->data, mSwrFrame->linesize, buffer, mPixelFormat, width, height, 16);
av_frame_alloc创建出来的AVFrame只是一个壳,我们需要为它提供实际存储像素数据和行宽数据的内存空间,如上所示有两种方法:
1.通过av_frame_get_buffer创建存储空间,data成员的空间实际上是由buf[0]->data提供的:
LOGD("mSwrFrame --> buf : 0x%X~0x%X, data[0]: 0x%X, data[1]: 0x%X, data[2]: 0x%X",
mSwrFrame->buf[0]->data,
mSwrFrame->buf[0]->data+mSwrFrame->buf[0]->size,
mSwrFrame->data[0],
mSwrFrame->data[1],
mSwrFrame->data[2]
);
// mSwrFrame --> buf : 0x2E6E8AC0~0x2E753F40, data[0]: 0x2E6E8AC0, data[1]: 0x2E7302E0, data[2]: 0x2E742100
通过av_image_fill_arrays指定外部存储空间,data成员的空间就是我们指的的外部空间,而buf成员是NULL:
LOGD("mSwrFrame --> buffer : 0x%X~0x%X, buf : 0x%X, data[0]: 0x%X, data[1]: 0x%X, data[2]: 0x%X",
buffer,
buffer+bufferSize,
mSwrFrame->buf[0],
mSwrFrame->data[0],
mSwrFrame->data[1],
mSwrFrame->data[2]
);
// FFmpegDemo: mSwrFrame --> buffer : 0x2DAE4DC0~0x2DB4D5C0, buf : 0x0, data[0]: 0x2DAE4DC0, data[1]: 0x2DB2A780, data[2]: 0x2DB3BEA0
而av_frame_free内部会去释放AVFrame里buf的空间,对于data成员它只是简单的把指针赋值为0,所以通过av_frame_get_buffer创建存储空间,而通过av_image_fill_arrays指定外部存储空间需要我们手动调用av_free去释放外部空间。
6、align
细心的同学可能还看到了av_image_get_buffer_size和av_image_fill_arrays都传了个16的align,这里对应的就是之前讲的linesize的字节对齐,会填充数据让linesize变成16、或者32的整数倍:
@paramalign thevalueusedinsrcforlinesizealignment
这里如果为0会填充失败:

1.png
而为1不做填充会出现和实际解码中的linesize不一致导致画面异常:

2.png
av_frame_get_buffer则比较人性化,它推荐你填0让它自己去判断应该按多少对齐:
*@paramalignRequiredbuffersizealignment. Ifequalto0, alignmentwillbe
* chosenautomaticallyforthecurrentCPU. Itishighly
* recommendedtopass0hereunlessyouknowwhatyouaredoing.
7、完整代码
完整的demo代码已经放到Github上,感兴趣的同学可以下载来看看
原文:https://www.jianshu.com/p/9a093d8b91ef
★文末名片可以免费领取音视频开发学习资料,内容包括(FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)以及音视频学习路线图等等。
见下方!↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓