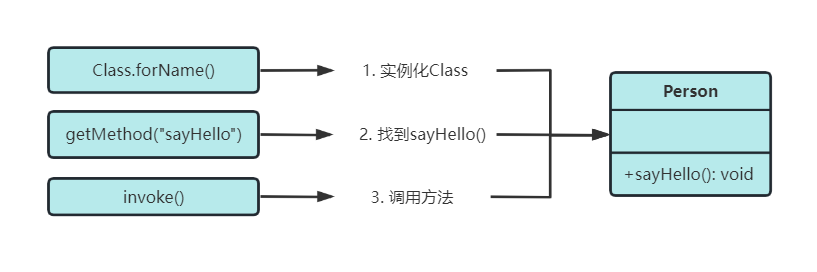
1、前言
Spark SQL 逻辑计划在实现层面被定义为 LogicalPlan 类 。 从 SQL 语句经过 SparkSqlParser解析生成 Unresolved LogicalPlan ,到最终优化成为 Optimized LogicalPlan ,这个流程主要经过3 个阶段。 这 3 个阶段分别产生 Unresolved LogicalPlan, Analyzed LogicalPlan 和Optimized LogicalPlan ,其中 Optimized LogicalPlan 传递到下一个阶段用于物理执行计划的生成。前面文章介绍了spark sql的大体执行流程,在逻辑计划的生成阶段,仅仅介绍了通过SqlParser、Analyzer、Optimizer工具类对sql语句或逻辑计划进行处理。对于具体的解析详情并没有深入研究。本篇文章主要是想深入看下未解析逻辑计划(Unresolved LogicalPlan)到解析后逻辑计划(Analyzed LogicalPlan)的转换过程,例如数据源的确定、表字段的确定等。
2、源码探究
经过SqlParser的解析,SQL语句会转变成一颗语法树,此时这个语法树就称为未解析逻辑计划(Unresolved LogicalPlan)。之所以称为“未解析”,其实是因为语法树上面的库表字段信息还没有和实际的数据源对应上。所以接下来就需要Analyzer工具类对未解析的逻辑计划进行进一步的处理,将语法树中的库表字段等和实际的数据源关联上。从而将语法树转换成解析后的逻辑计划。因为整个解析规则太多太杂,如果整个铺开研究源码,不仅效率低下,很有可能越看越懵。所以这里挑一个我感兴趣的点去追踪探究,我这里挑选的是数据源的解析,简单理解为库表的解析。代码demo如下:
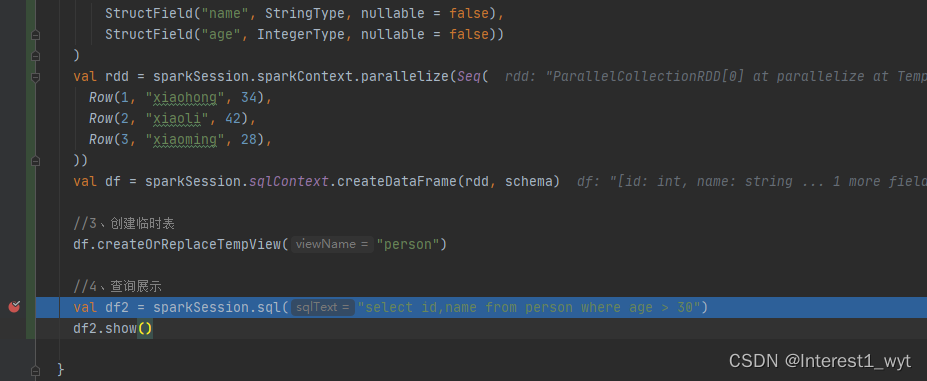
def main(args: Array[String]): Unit = {
//1、创建sparkSession
val sparkSession = SparkSession.builder
.appName("test")
.master("local")
.getOrCreate
import org.apache.spark.sql.types._
//2、构造数据
val schema = StructType(
List(StructField("id", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = false))
)
val rdd = sparkSession.sparkContext.parallelize(Seq(
Row(1, "xiaohong", 34),
Row(2, "xiaoli", 42),
Row(3, "xiaoming", 28),
))
val df = sparkSession.sqlContext.createDataFrame(rdd, schema)
//3、创建临时表
df.createOrReplaceTempView("person")
//4、查询展示
val df2 = sparkSession.sql("select id,name from person where age > 30")
df2.show()
}代码的大体执行流程前面文章已经介绍过了,Analyzer段执行的逻辑在父类RuleExecutor中定义好了,但是具体的解析规则batches则由Analyzer中定义,所以我们这里直接到Analyzer中查看对应的batches,然后再对应的处理方法中加断点查看解析的规则。
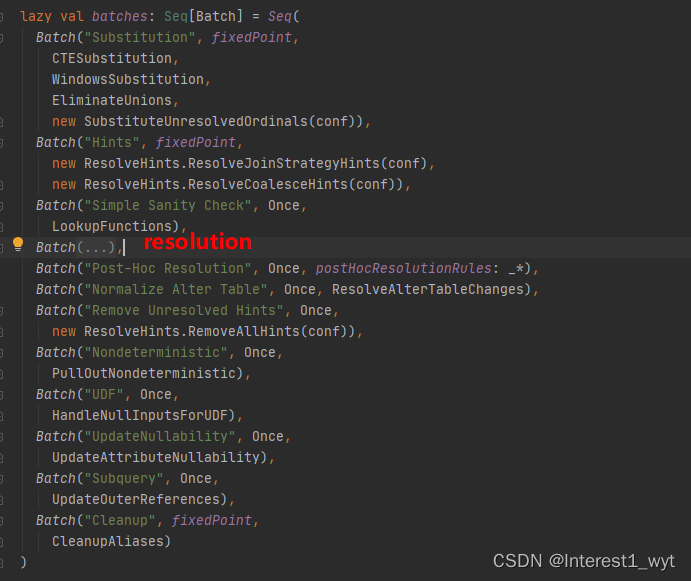
Resolution规则太多,所以给折叠起来了,它也是解析的主要规则批。我现在使用的spark版本是3.0.1,可以看到总共有12大类解析规则。我们感兴趣的库表解析其实在关系策略组Resolution中,具体的解析类为ResolveRelations:
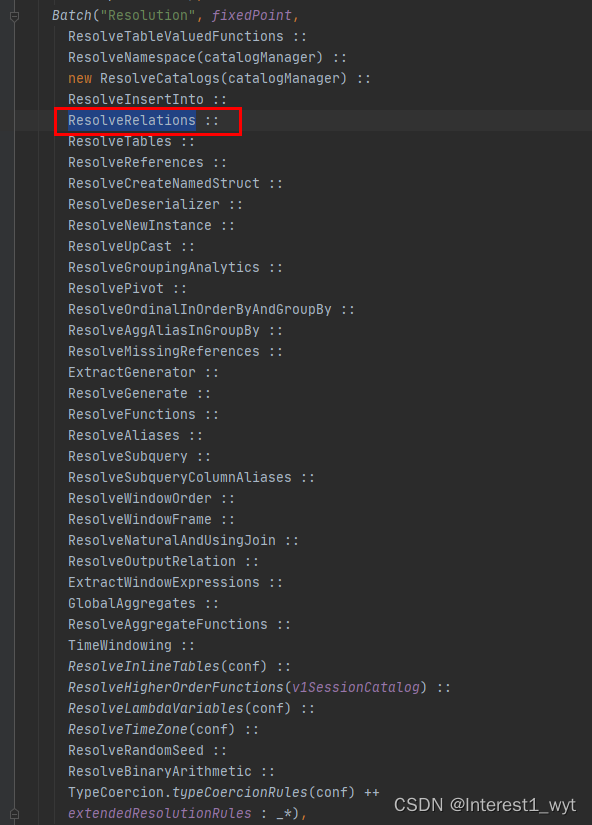
下面来看下ResolveRelations相关的代码,这里我是通过断点进去看的,也建议初次看的时候也根据断点来。打断点的流程首先是取消所有断点,然后只在查询语句前加断点,随后在ResolveRelations中加入断点。如下:
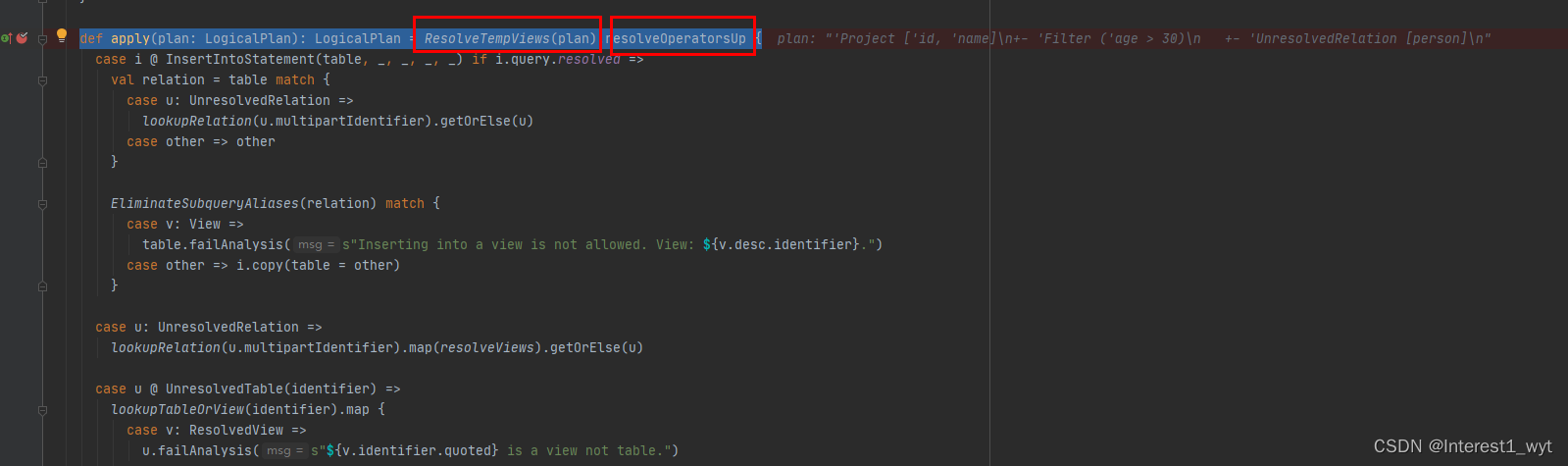
首先进入ResolveRelations的apply方法中,这块有两个重点,第一是解析临时表ResolveTempViews方法,其包含了解析临时表的关键内容。第二个是resolveOperatorsUp,它表示自底向上遍历所有节点,即后序遍历语法树(还有一个resolveOperatorsDown,它表示自上向下遍历所有节点,即前序遍历语法树)。
接着看下ResolveTempViews方法:
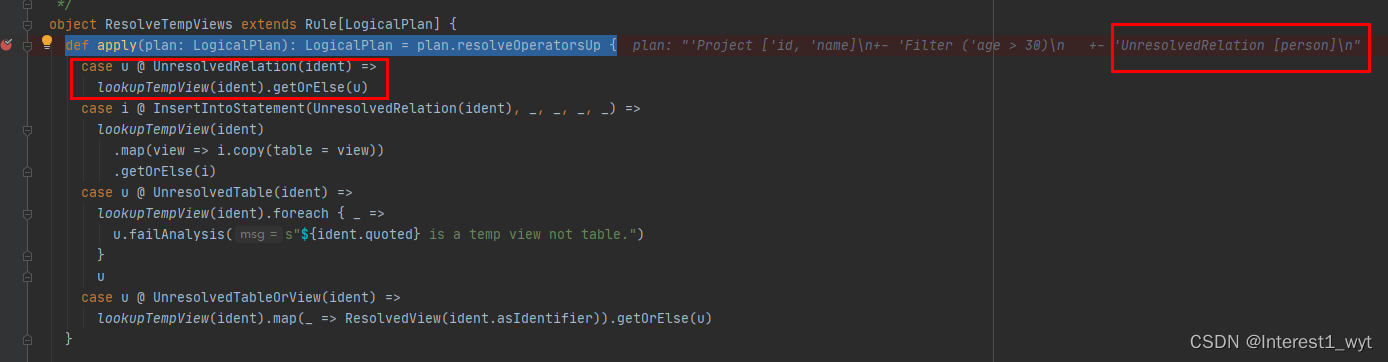
可以看到语法树底层是UnresolvedRelation,所以模式匹配肯定进入第一个case中,即会接着执行lookupTempView(ident)方法。
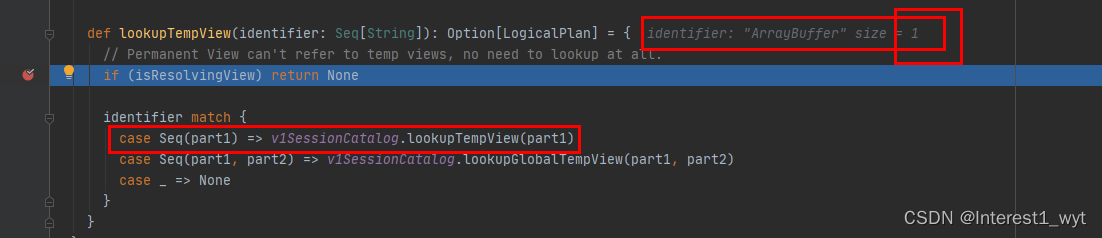
因为 还没解析,且入参只有一个,所以identifier的模式匹配也只会匹配第一个case:

这块有两个重点,第一是会格式化输入的表名,大体是根据表名是否大小写敏感进而进行转换,该参数可以自定义配置。第二个则是获取表的logicplan并封装成子查询SubqueryAlias。接着进入getTempView中看下:
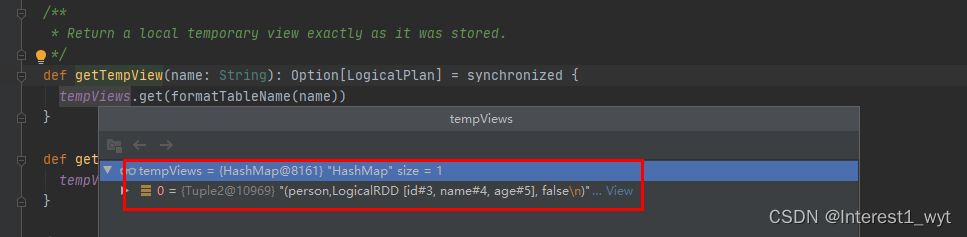 可以看到该方法逻辑比较简单,就是从一个hashmap中取出logincal对象并返回。该hashmap点击查看其对应的put方法可以看到,只在两个地方put,一个是创建view的时候,还有就是重命名的时候。
可以看到该方法逻辑比较简单,就是从一个hashmap中取出logincal对象并返回。该hashmap点击查看其对应的put方法可以看到,只在两个地方put,一个是创建view的时候,还有就是重命名的时候。
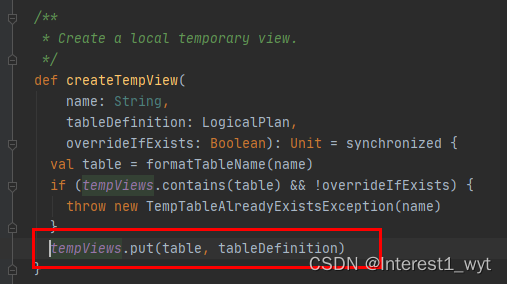
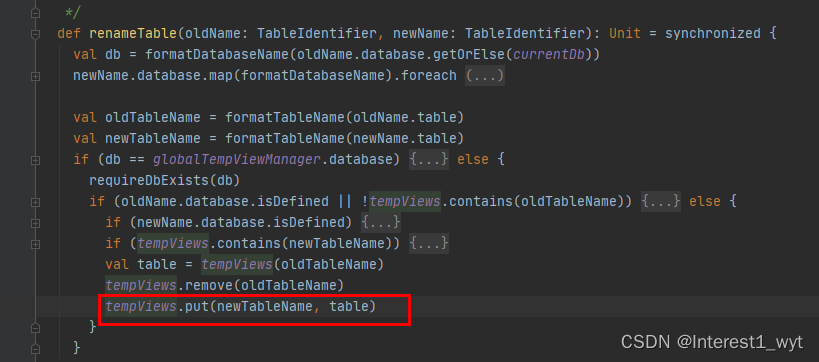
而我们的代码demo中,因为没有查数据库,而是在内存造的数据并注册成view,因此hashmap中就有了person表相关的信息。
引申:至此demo中整个表的解析就结束了。但是由于我们查询的是自己注册的view,所以在查询解析数据源的过程比较简单,当我们查询数据库或其它数据源的时候就比较复杂了 。不过他们的入口还是在ResolveRelations中。
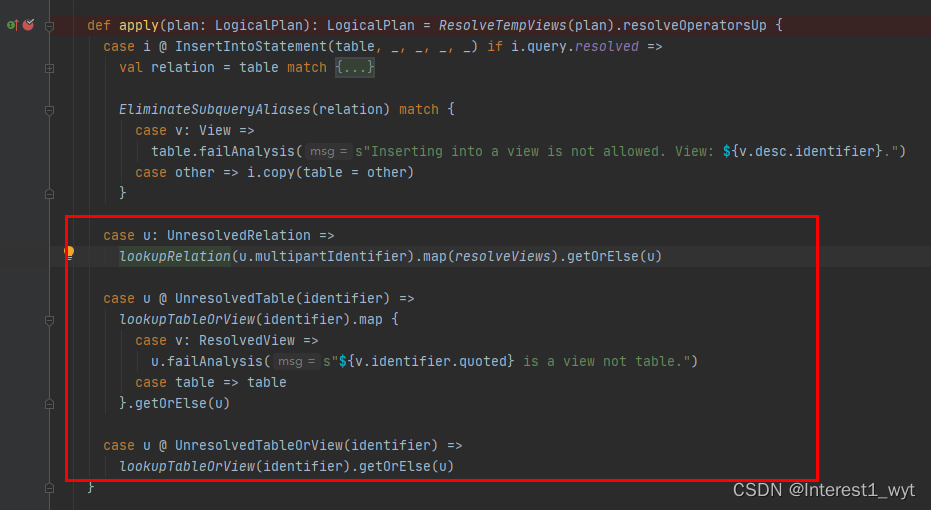
这里的代码不过多解析,感兴趣的可以自己看下,后面会有一篇自定义数据源相关的文章,那个时候我会结合这块代码详细介绍下。
3、总结
spark sql的解析规则太多,很多我其实也没有看到,只是在用到或者感兴趣的时候再去看下大体的解析逻辑,所以如果有介绍不到位的地方,希望大家多多指教。
最后分享给大家一个spark sql查询的技巧,那就是通过配置,让spark sql执行中生效的规则以及规则的处理前后结果打印出来,如下:
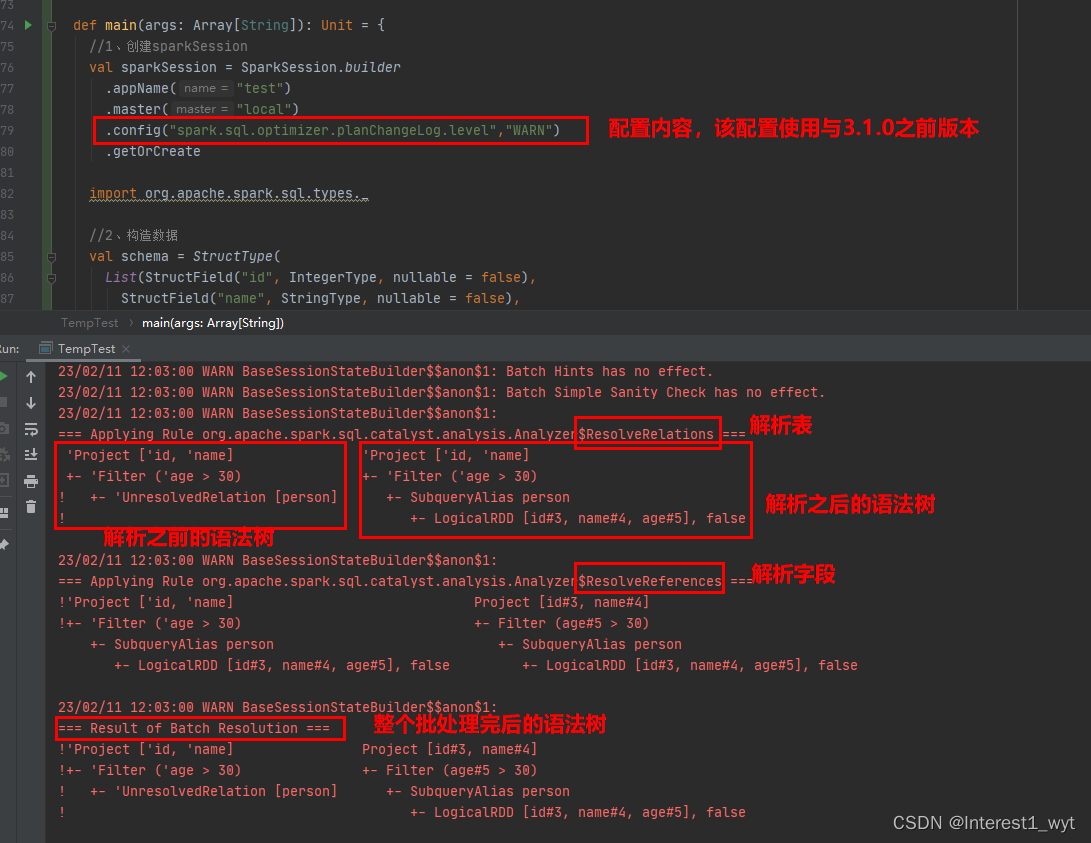
可以看到在Resolution策略批中,生效的规则有ResolveRelations和Reference,前者负责库表解析,后者负责字段解析。另外spark.sql.optimizer.planChangeLog.level=WARN只适用于spark3.1.0之前的版本,后续的版本使用spark.sql.planChangeLog.level=WARN配置



![[1.1_1]计算机系统概述——操作系统的概念、功能和目标](https://img-blog.csdnimg.cn/img_convert/c06e19f2aa66fdabcc8e9e32293a3bdc.png)
![[架构之路-126]-《软考-系统架构设计师》-操作系统-5-虚拟化技术、Docker与虚拟机比较](https://img-blog.csdnimg.cn/img_convert/6682a532785ae32d6f4d992ea27d2458.png)