论文链接:https://aclanthology.org/N19-4013.pdf
目录
摘要
1 简介
2 背景及相关工作
3 系统架构
3.1 Anserini Retriever
3.2 BERT 阅读器
4 实验结果
5演示
6结论
摘要
我们展示了一个端到端的问答系统,它将 BERT 与开源 Anserini 信息检索工具包集成在一起。
与当今大多数对少量输入文本进行操作的问答和阅读理解模型相比,我们的系统将 IR 的最佳实践与基于 BERT 的阅读器相结合,以从大量维基百科文章中识别答案以端到端的方式。我们报告了在标准基准测试集上比以前的结果有很大改进,表明使用 SQuAD 微调预训练 BERT 足以在识别答案跨度方面实现高精度。
1 简介
BERT(Devlin 等人,2018 年)是一系列大量使用预训练的神经模型的最新改进(Peters 等人,2018 年;Radford 等人,2018 年),在许多自然语言领域取得了令人瞩目的进步处理任务,从句子分类到问题回答再到序列标记。与我们的任务最相关的是,Nogueira 和 Cho (2019) 在使用 BERT 进行基于查询的段落重新排序方面取得了令人瞩目的成果。在此演示中,我们将 BERT 与开源 Anserini IR 工具包相集成,以创建 BERT-serini,一个端到端的开放域问答 (QA) 系统。
大多数 QA 或阅读理解模型被描述为重新排序器或提取器,因为它们假设输入相对少量的文本(文章、前 k 个句子或段落等),我们的系统直接在维基百科的大型语料库上运行文章。我们将来自信息检索社区的最佳实践与BERT集成在一起,以生成端到端系统,并且在标准基准测试集合上的实验表明,与以前的工作相比,有了很大的改进。我们的结果表明,使用 SQuAD(Rajpurkar 等人,2016 年)微调预训练 BERT 足以在识别答案跨度方面实现高精度。这种设计的简单性是我们架构的一大特色。我们已将 BERTserini 部署为聊天机器人,用户可以在从笔记本电脑到手机的各种平台上与之交互。
2 背景及相关工作
虽然问答的起源可以追溯到 1960 年代,但现代的表述可以追溯到 1990 年代后期的文本检索会议 (TREC)(Voorhees 和 Tice,1999)。扎根于信息检索,人们普遍认为 QA 系统将包含管道阶段,这些管道阶段会选择越来越细粒度的文本段(Tellex 等人,2003 年):文档检索以从大型语料库,然后通过段落排名来识别包含答案的文本片段,最后是答案提取来识别答案跨度。
随着 NLP 研究人员对 QA 越来越感兴趣,他们更加重视管道的后期阶段,以强调语言分析的各个方面。信息检索技术退居幕后,完全被忽视了。当今最流行的 QA 基准数据集——例如,TrecQA(Yao 等人,2013 年)、WikiQA(Yang 等人,2015 年)和 MSMARCO(Bajaj 等人,2016 年)——最适合作为答案选择任务.也就是说,系统会收到问题以及可供选择的候选句子列表。当然,这些候选列表必须来自某个地方,但他们的来源不在问题的表述中。同样,阅读理解数据集,如SQuAD (Rajpurkar et al., 2016)完全避免检索,因为只有一个文档可以提取答案。
相比之下,我们所说的“端到端”问答是从大量文档开始的。由于使用当前模型(主要基于神经网络)将推理穷尽地应用于语料库中的所有文档是不切实际的,因此该公式必然需要某种类型的基于术语的检索技术来限制正在考虑的输入文本——并且因此,架构非常类似于十多年前的流水线系统。最近,人们对这项任务重新产生了兴趣,其中最著名的是 Dr.QA(Chen 等人,2017 年)。最近的其他论文研究了检索在这种端到端公式中的作用(Wang 等人,2017 年;Kratzwald 和 Feuerriegel,2018 年;Lee 等人,2018 年),其中一些本质上具有重新发现- 从 1990 年代末和 2000 年代初产生的想法。
对于广泛的应用,研究人员最近证明了在语言建模任务上经过预训练的神经模型的有效性(Peters 等人,2018 年;Radford 等人,2018 年); BERT(Devlin 等人,2018 年)是这一想法的最新改进。我们的工作通过将 BERT 与 Anserini 相结合来解决端到端的问答问题,Anserini 是一种建立在流行的开源 Lucene 搜索引擎之上的 IR 工具包。 Anserini (Yang et al., 2017, 2018) 代表了研究人员最近为使学术 IR 更好地与构建现实世界搜索应用程序的实践保持一致所做的努力,其中 Lucene 已成为行业中使用的事实上的平台。通过强调严格的软件工程和可复制性的回归测试,Anserini 将当今的 IR 最佳实践编纂成文。最近,Lin (2018) 表明,十多年前提出的查询扩展模型的调整良好的 Anserini 实现仍然优于最近的两个文档排名神经模型。因此,BERT 和 Anserini 代表了构建端到端问答系统的坚实基础。
3 系统架构
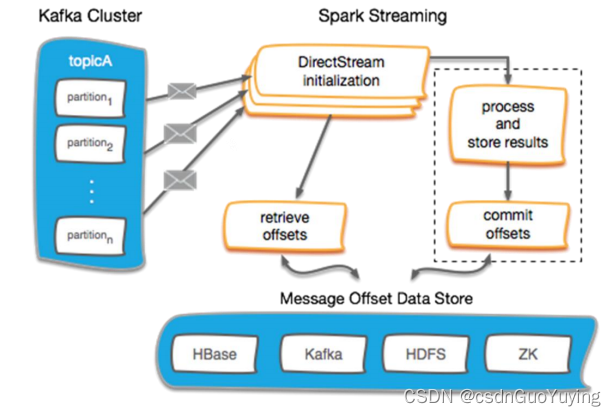
BERTserini 的架构如图 1 所示,由两个主要模块组成,即 Anserini 检索器和 BERT 读取器。检索器负责选择包含答案的文本片段,然后将其传递给阅读器以识别答案范围。
为了便于与以前的工作进行比较,我们使用Chen等人(2017)(2016年12月起)描述的相同的维基百科语料库,其中包括508万篇文章。接下来,我们依次描述每个模块。
3.1 Anserini Retriever
为简单起见,我们采用了单级检索器,直接识别维基百科中的文本片段以传递给 BERT 阅读器,而不是首先检索文档然后对其中的段落进行排序的多级检索器。然而,为了增加灵活性,我们在索引时尝试了不同粒度的文本:
文章:5.08M维基百科文章被直接索引;也就是说,一篇文章是检索的单位。
段落:语料库被预先分割成 2950 万个段落并进行了索引,其中每个段落都被视为一个“文档”(即检索单元)。
句子:语料库被预先分割成 7950 万个句子并进行了索引,其中每个句子都被视为一个“文档”。
在推理时,我们使用问题作为“词袋”查询来检索 k 个文本段(上述条件之一)。我们使用 Anserini 的 post-v0.3.0 分支,以 BM25 作为排名函数(Anserini 的默认参数)。
3.2 BERT 阅读器
来自检索器的文本片段被传递给 BERT 阅读器。我们使用 Devlin 等人的模型 (2018),但有一个重要的区别:为了允许比较和聚合来自不同片段的结果,我们删除了不同答案范围内的最终 softmax 层;参见(克拉克和加德纳,2018 年)。
我们的 BERT 阅读器基于谷歌的参考实现 (TensorFlow 1.12.0)。训练,我们从 BERT-Base 模型(uncased,12 层,768 隐藏,12 头,110M 参数)开始,然后在 SQuAD(v1.1)的训练集上微调模型).读取器的所有输入都被填充为 384 个token;学习率设置为 3 × 10−5 并使用所有其他默认设置。
在推理时,对于检索到的文章,我们逐段应用 BERT 阅读器。对于检索到的段落,我们对整个段落进行推理。对于检索到的句子,我们对整个句子进行推理。在所有情况下,读者都会选择最佳文本跨度并提供分数。然后我们通过线性插值将读者分数与检索器分数结合起来:
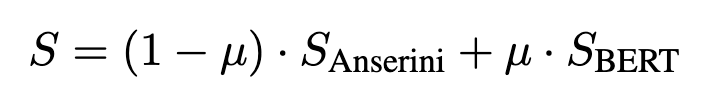
其中 μ ∈ [0, 1] 是超参数。我们对来自 SQuAD 训练集的 1000 个随机选择的问答对调整 μ,并以十分之一的增量考虑所有值。
4 实验结果
我们采用与 Chen 等人完全相同的评估方法 (2017),也用于后续工作。试题来自SQuAD的开发集;因为我们的答案来自不同的文本,所以我们只根据 SQuAD 答案范围进行评估(即忽略段落上下文)。我们的评估指标也与 Chen 等人相同 (2017):精确匹配 (EM) 分数和 F1 分数(在token级别)。此外,我们计算召回率 (R),即在任何检索到的片段中出现正确答案的问题部分;这就是Chen et al.(2017)所说的文献检索结果。请注意,此召回与F1分数中的token级召回组件不同。
我们的主要结果如表 1 所示,其中我们报告了具有不同 Anserini 检索条件(文章、段落和句子)的指标。我们比较了 k = 5 时的文章检索、k = 29 时的段落检索和 k = 78 时的句子检索。文章设置与 Chen 等人的检索条件相匹配 (2017)。选择段落和句子条件的 k 值,以便读者考虑大致相同数量的文本:每个段落平均包含 2.7 个句子,每篇文章平均包含 5.8 个段落。该表还复制了以前工作的结果以供比较。
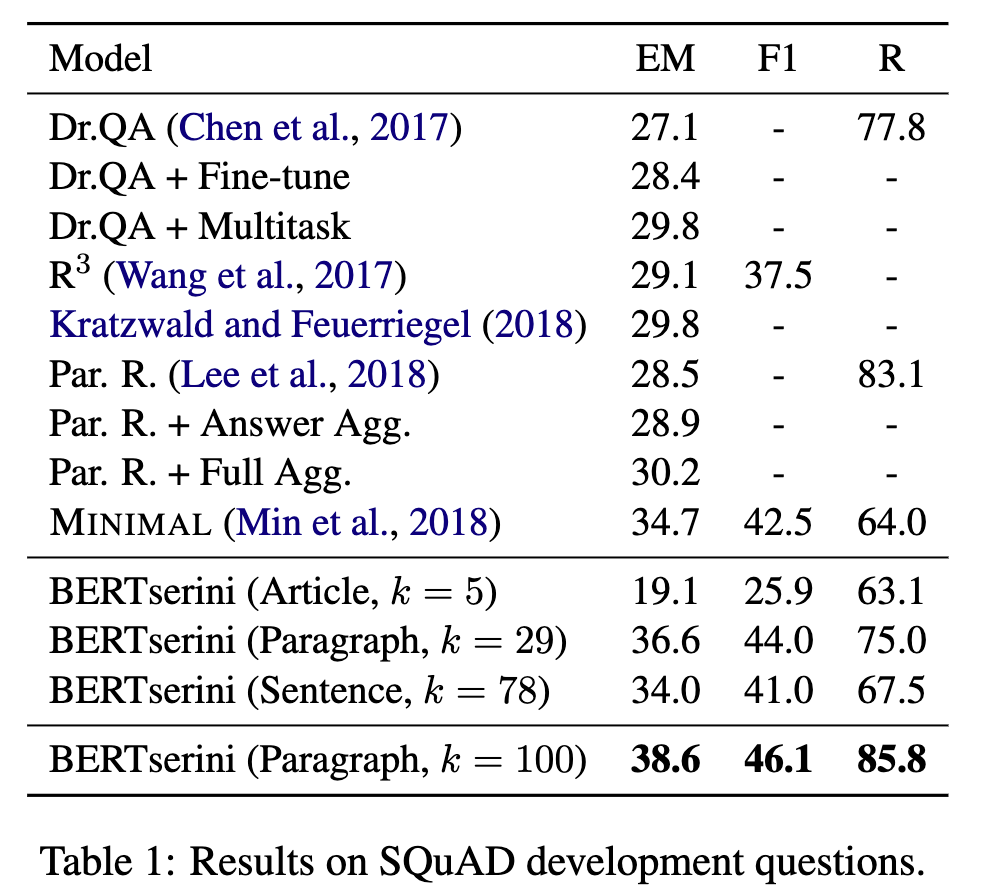
我们看到文章检索的性能大大低于段落检索:我们认为,原因是文章很长并且包含许多不相关的句子,这些句子会分散 BERT 阅读器的注意力。句子的表现还算不错,但不如段落,因为它们通常缺乏读者识别答案范围的上下文。段落似乎代表了一个“最佳点”,与以前的结果相比,精确匹配分数有了很大的提高。
我们看到文章检索的性能大大低于段落检索:我们认为,原因是文章很长并且包含许多不相关的句子,这些句子会分散 BERT 阅读器的注意力。句子的表现还算不错,但不如段落,因为它们通常缺乏读者识别答案范围的上下文。段落似乎代表了一个“最佳点”,与以前的结果相比,精确匹配分数有了很大的提高。
我们的下一个实验检查了不同 k 的影响,k 是 BERT 阅读器考虑的文本片段的数量。在这里,我们只关注段落条件,μ = 0.5(通过交叉验证学习的值)。图 2 绘制了关于 k 的三个指标:召回率、前 k 个精确匹配最高部精确匹配。召回率测量正确答案出现在任何检索到的片段中的问题的比例,与表 1 完全一样。
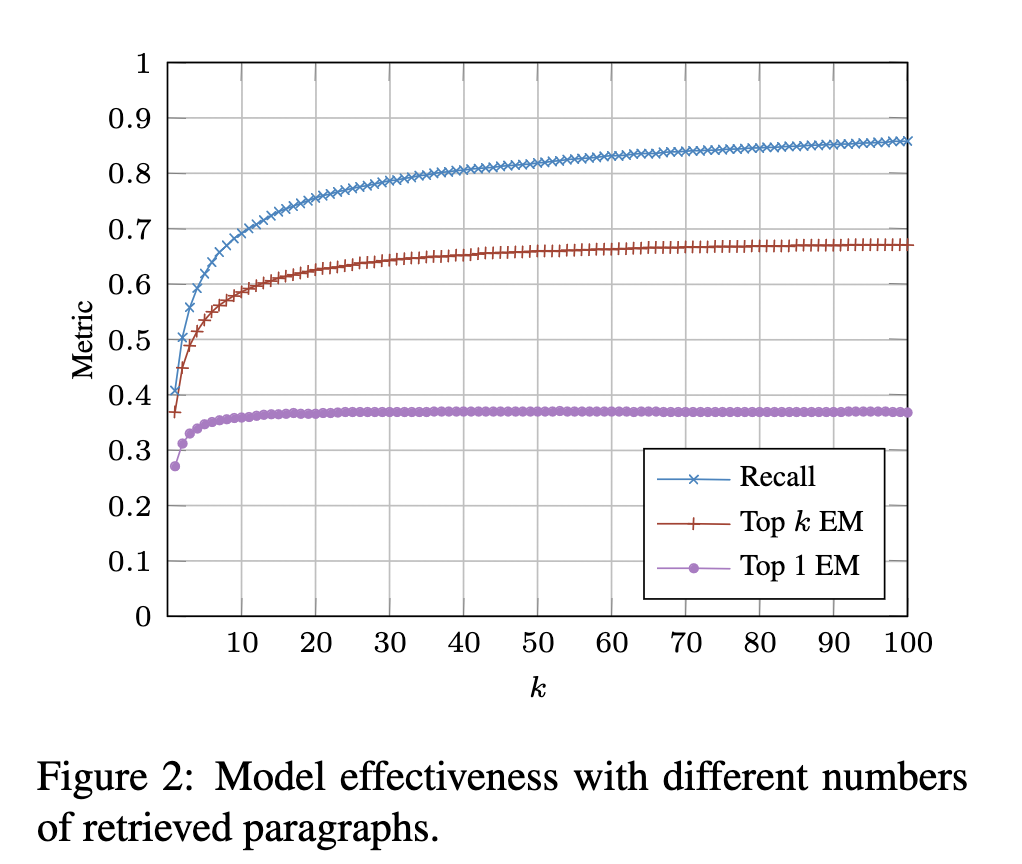
顶部精确匹配表示一种宽松的条件,在这种条件下,系统在任何检索到的段中接受正确识别的跨度。最后,根据得分最高的跨度评估最高精确匹配,与表 1 中报告的结果相当。表中还报告了 k = 100 的段落条件的分数:我们注意到精确匹配分数大大高于我们所知道的先前发布的最佳结果。
我们看到,正如预期的那样,分数随着 k 值的增加而增加。然而,top exact match score 在 k = 10 左右后似乎并没有增加太多。top k exact match score 继续增长的时间更长一些,但也达到了饱和。召回率似乎会一直增加到 k = 100,尽管随着 k 的增加速度会变慢。这意味着 BERT 阅读器无法利用这些出现在候选池中的额外答案段落。
这些曲线还提供了失败分析:顶部召回曲线(蓝色)表示当前 Anserini 检索器的上限。在 k = 100 时,它能够在大约 86% 的时间内返回至少一个相关段落,因此我们可以得出结论,段落检索似乎不是当前实施中整体有效性的瓶颈。
顶部蓝色召回曲线和顶部 k 精确匹配曲线(红色)之间的差距量化了 BERT 阅读器的改进空间;这些代表读者在任何段落中都没有找到正确答案的情况。最后,红色曲线和底部顶部精确匹配曲线(紫色)之间的差距代表 BERT 确实识别出正确答案的情况,但不是得分最高的跨度。这种差距可以被描述为评分或分数聚合失败,它似乎是最大的改进领域——表明我们目前的方法(BERT 和 Anserini 分数之间的加权插值)是不够的。我们正在探索能够整合更多相关信号的重新排序模型。
最后一个警告:此错误分析基于 SQuAD ground truth。尽管我们的答案可能与 SQuAD 的答案跨度不匹配,但它们可能是可以接受的(例如,对时间相关问题的不同答案)。在未来的工作中,我们计划手动检查错误样本以生成更准确的故障分类。
5演示
我们部署了 BERTserini 作为聊天机器人,用户可以通过两种不同的方式与之交互:Slackbot 和 RSVP.ai 的智能平台,允许企业轻松快速地构建自然对话服务。但是,两者都使用相同的后端服务。 RSVP.ai 聊天平台的屏幕截图如图 3 所示。当前界面使用段落索引条件,但我们仅返回包含 BERT 阅读器识别的答案的句子。答案跨度在响应中突出显示 (Lin et al., 2003)。在屏幕截图中,我们可以看到 BERTserini 可以处理的问题的多样性——不同类型的命名实体以及答案不是名词短语的查询。
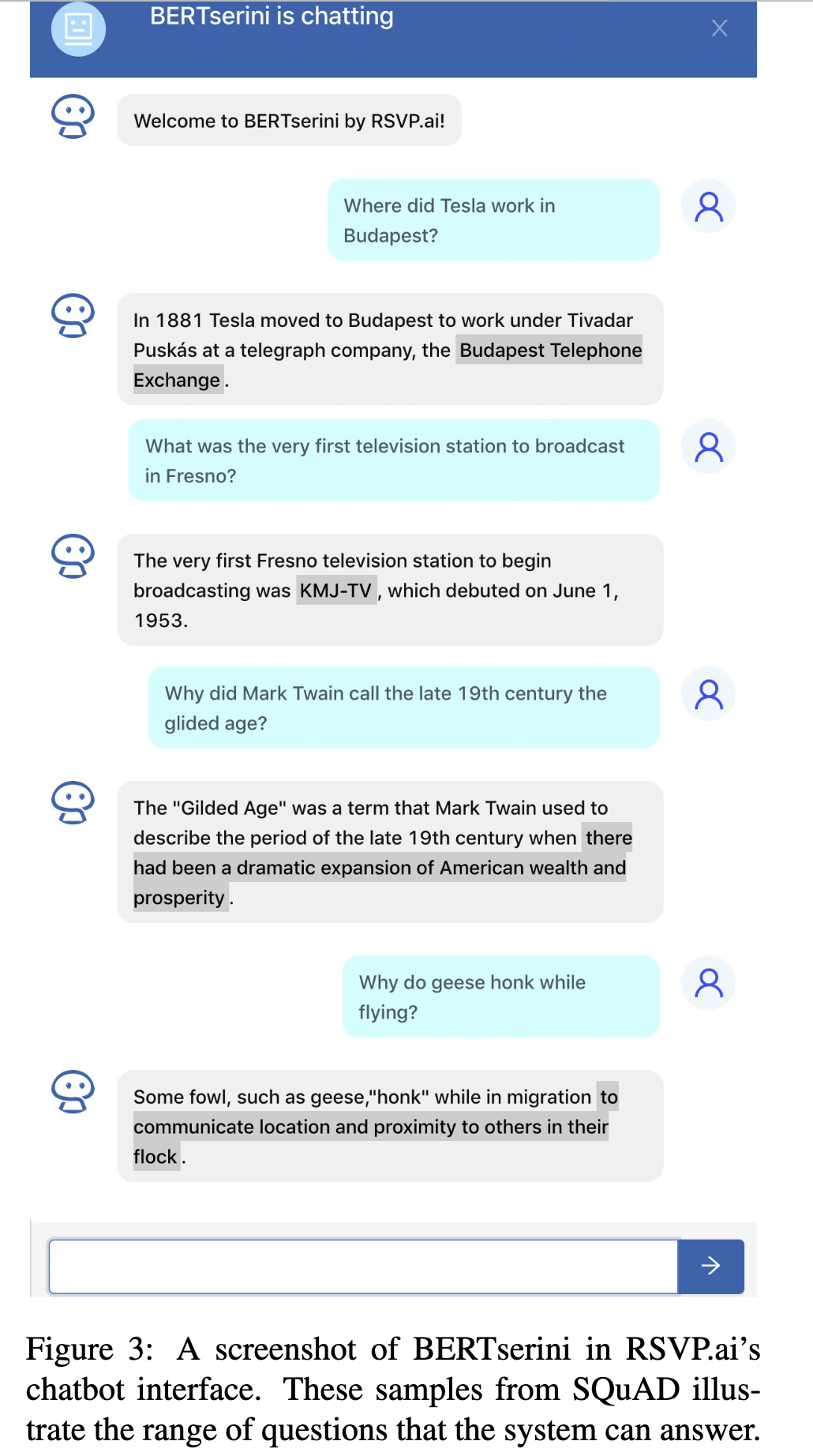
根据图 2 中的分析,在我们的演示系统中,我们在段落条件下设置 k = 10。虽然这不能为我们提供最大可能的准确性,但它代表了良好的成本/质量权衡。为了量化处理时间,我们从 SQuAD 中随机选择了 100 个问题并记录了平均延迟;测量是在配备 Intel Xeon E5-2620 v4 CPU (2.10GHz) 和 Tesla P40 GPU 的机器上进行的。 Anserini 检索(在 CPU 上)平均每个问题 0.5 秒,而 BERT 处理时间(在 GPU 上)平均每个问题 0.18 秒。
6结论
我们介绍了 BERTserini,这是我们的端到端开放域问答系统,它集成了 BERT 和 Anserini IR 工具包。通过一个简单的两级流水线架构,我们能够实现对以前系统的重大改进。错误分析指出了检索、答案提取和答案聚合方面的改进空间——所有这些都代表着持续的努力。此外,我们也有兴趣扩展我们系统的多语言功能。



![[jetson]paddlepaddle2.4.0在jetpack5.0.2源码编译流程](https://img-blog.csdnimg.cn/5e1f0192483249e09b608ee31bc86f40.jpeg)