6.3 MySQL 存储偏移量
此处将偏移量数据存储到MySQL表中,数据库及表的DDL和DML语句如下:
-- 1. 创建数据库的语句
CREATE DATABASE IF NOT EXISTS db_spark DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
USE db_spark ;
-- 2. 创建表的语句
CREATE TABLE `tb_offset` (
`topic` varchar(255) NOT NULL,
`partition` int NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint NOT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;
-- 3. 插入数据语句replace
replace into tb_offset (`topic`, `partition`, `groupid`, `offset`) values(?, ?, ?, ?)
--/*
-- replace语句执行时,分以下两种情况:
-- - 情况1:insert
-- 当不存在主键冲突或唯一索引冲突,相当于insert操作
-- - 情况2:delete and insert
-- 当存在主键冲突或唯一索引冲突,相当于delete操作,加insert操作
--*/
-- 4. 查询数据语句select
select * from tb_offset where topic in ('xx', 'yy') AND groupid = 'gid001' ;
select * from tb_offset where topic in (?) and groupid = ? ;
编写工具类
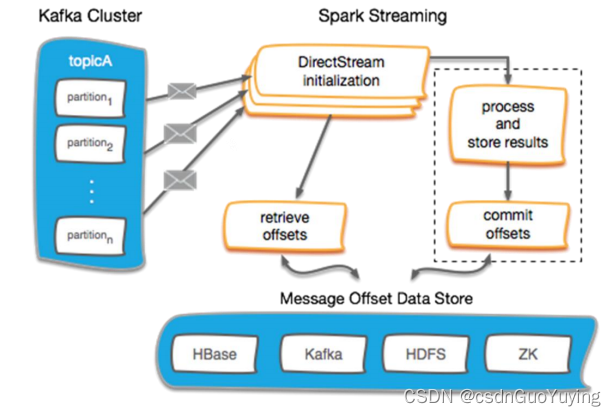
工具类OffsetsUtils从MySQL数据库表中读取消费的偏移量信息和保存最近消费的偏移量值,示意图如下所示:
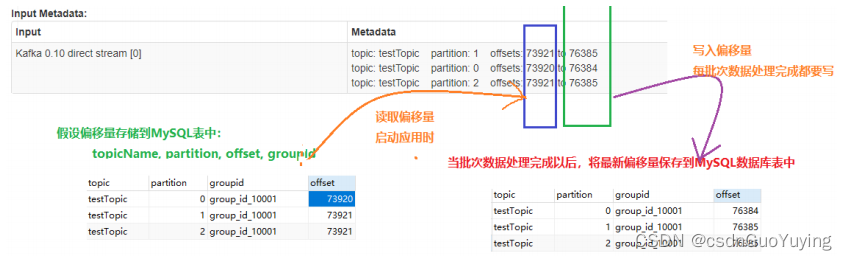
工 具 类 中 包 含 如 何 保 存 偏 移 量 【 saveOffsetsToTable 】 和 读 取 偏 移 量【getOffsetsToMap】两个函数,相关声明如下:
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
/**
* 将消费Kafka Topic偏移量数据存储MySQL数据库,工具类用于读取和保存偏移量数据
*/
object OffsetsUtils {
/**
* 依据Topic名称和消费组GroupId获取各个分区的偏移量
*
* @param topicNames Topics名称
* @param groupId 消费组ID
*/
def getOffsetsToMap(topicNames: Array[String], groupId: String): Map[TopicPartition, Long] ={
null
}
/**
* 保存Streaming每次消费Kafka数据后最新偏移量到MySQL表中
*
* @param offsetRanges Topic中各个分区消费偏移量范围
* @param groupId 消费组ID
*/
def saveOffsetsToTable(offsetRanges: Array[OffsetRange], groupId: String): Unit = {
}
}
依据业务实现工具类中方法,主要考察就是对MySQL数据库表数据的操作:从表中读取数据和向表写入数据,完整代码如下:
package cn.itcast.spark.offset
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import scala.collection.mutable
/**
* 将消费Kafka Topic偏移量数据存储MySQL数据库,工具类用于读取和保存偏移量数据
* 表的创建语句:
CREATE TABLE `tb_offset` (
`topic` varchar(255) NOT NULL,
`partition` int NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint NOT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
*/
object OffsetsUtils {
/**
* 依据Topic名称和消费组GroupId获取各个分区的偏移量
*
* @param topicNames Topics名称
* @param groupId 消费组ID
*/
def getOffsetsToMap(topicNames: Array[String], groupId: String): Map[TopicPartition, Long] ={
// 构建集合
val map: mutable.Map[TopicPartition, Long] = scala.collection.mutable.Map[TopicPartition, Lon
g]()
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
var result: ResultSet = null
try{
// a. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// b. 获取连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnic
ode=true", //
"root", //
"123456" //
)
// c. 编写SQL,获取PreparedStatement对象
val topicNamesStr = topicNames.map(topicName => s"\'$topicName\'").mkString(", ")
val querySQL =
s"""
|SELECT
| `topic`, `partition`, `groupid`, `offset`
|FROM
| db_spark.tb_offset
|WHERE
| groupid = ? AND topic in ($topicNamesStr)
|""".stripMargin
pstmt = conn.prepareStatement(querySQL)
pstmt.setString(1, groupId)
// d. 查询数据
result = pstmt.executeQuery()
// e. 遍历获取值
while (result.next()){
val topicName = result.getString("topic")
val partitionId = result.getInt("partition")
val offset = result.getLong("offset")
// 加入集合中
map += new TopicPartition(topicName, partitionId) -> offset
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != result) result.close()
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
// 返回集合,转换为不可变的
map.toMap
}
/**
* 保存Streaming每次消费Kafka数据后最新偏移量到MySQL表中
*
* @param offsetRanges Topic中各个分区消费偏移量范围
* @param groupId 消费组ID
*/
def saveOffsetsToTable(offsetRanges: Array[OffsetRange], groupId: String): Unit = {
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// a. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// b. 获取连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnic
ode=true", //
"root", //
"123456" //
)
// c. 编写SQL,获取PreparedStatement对象
val insertSQL = "replace into db_spark.tb_offset (`topic`, `partition`, `groupid`, `offse
t`) values (?, ?, ?, ?)"
pstmt = conn.prepareStatement(insertSQL)
// d. 设置参数
offsetRanges.foreach{offsetRange =>
pstmt.setString(1, offsetRange.topic)
pstmt.setInt(2, offsetRange.partition)
pstmt.setString(3, groupId)
pstmt.setLong(4, offsetRange.untilOffset)
// 加入批次
pstmt.addBatch()
}
// e. 批量插入
pstmt.executeBatch()
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
def main(args: Array[String]): Unit = {
/*
saveOffsetsToTable(
Array(
OffsetRange("xx-tp", 0, 11L, 100L),
OffsetRange("xx-tp", 1, 11L, 100L),
OffsetRange("yy-tp", 0, 10L, 500L),
OffsetRange("yy-tp", 1, 10L, 500L)
),
"group_id_00001"
)
*/
//getOffsetsToMap(Array("xx-tp"), "group_id_00001").foreach(println)
}
}
加载和保存偏移量
从Kafka Topic消费数据时,首先从MySQL数据库加载偏移量,如果有值,使用如下函数:

从Kafka Topic消费数据时,直接获取的DStream中每批次RDD都是KafkaRDD,可以获取数据偏移量范围信息OffsetRanges。

修改前面实时订单消费额统计代码,自己管理消费偏移量,存储到MySQL表中,代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
/**
* SparkStreaming从Kafka Topic实时消费数据,手动管理消费偏移量,保存至MySQL数据库表
*/
object StreamingManagerOffsets {
/**
* 抽象一个函数:专门从数据源读取流式数据,经过状态操作分析数据,最终将数据输出
*/
def processData(ssc: StreamingContext): Unit ={
// 1. 从Kafka Topic实时消费数据
val groupId: String = "group_id_10001" // 消费者GroupID
val kafkaDStream: DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array("search-log-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
// TODO: 从MySQL数据库表中获取偏移量信息
val offsetsMap: Map[TopicPartition, Long] = OffsetsUtils.getOffsetsToMap(topics, groupId)
val consumerStrategy: ConsumerStrategy[String, String] = if(offsetsMap.isEmpty){
// TODO: 如果第一次消费topic数据,此时MySQL数据库表中没有偏移量信息, 从最大偏移量消费数据
ConsumerStrategies.Subscribe(topics, kafkaParams)
}else{
// TODO: 如果不为空,指定消费偏移量
ConsumerStrategies.Subscribe(topics, kafkaParams, offsetsMap)
}
// v.采用消费者新API获取数据
KafkaUtils.createDirectStream(ssc, locationStrategy, consumerStrategy)
}
// TODO: 其一、创建空Array数组,指定类型
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
// 2. 词频统计,实时累加统计
// 2.1 对数据进行ETL和聚合操作
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
// TODO:其二、从KafkaRDD中获取每个分区数据对应的偏移量信息
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val reduceRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter{ record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map{record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
// 返回
reduceRDD
}
// 2.2 使用mapWithState函数状态更新, 针对每条数据进行更新状态
val spec: StateSpec[String, Int, Int, (String, Int)] = StateSpec.function(
// (KeyType, Option[ValueType], State[StateType]) => MappedType
(keyword: String, countOption: Option[Int], state: State[Int]) => {
// a. 获取当前批次中搜索词搜索次数
val currentState: Int = countOption.getOrElse(0)
// b. 从以前状态中获取搜索词搜索次数
val previousState = state.getOption().getOrElse(0)
// c. 搜索词总的搜索次数
val latestState = currentState + previousState
// d. 更行状态
state.update(latestState)
// e. 返回最新省份销售订单额
(keyword, latestState)
}
)
// 设置状态的初始值,比如状态数据保存Redis中,此时可以从Redis中读取
//spec.initialState(ssc.sparkContext.parallelize(List("罗志祥" -> 123, "裸海蝶" -> 342)))
// 调用mapWithState函数进行实时累加状态统计
val stateDStream: DStream[(String, Int)] = reduceDStream.mapWithState(spec)
// 3. 统计结果打印至控制台
stateDStream.foreachRDD{(rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"BatchTime: $batchTime")
println("-------------------------------------------")
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition{_.foreach(println)}
}
// TODO: 其三、保存每批次数据偏移量到MySQL数据库表中
OffsetsUtils.saveOffsetsToTable(offsetRanges, groupId)
}
}
// 应用程序入口
def main(args: Array[String]): Unit = {
// 1). 构建流式上下文StreamingContext实例对象
val ssc: StreamingContext = StreamingContext.getActiveOrCreate(
() => {
// a. 创建SparkConf对象
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b. 创建StreamingContext对象
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
)
ssc.checkpoint(s"datas/streaming/offsets-${System.nanoTime()}")
// 2). 实时消费Kafka数据,统计分析
processData(ssc)
// 3). 启动流式应用,等待终止(人为或程序异常)
ssc.start()
ssc.awaitTermination() // 流式应用启动以后,一直等待终止,否则一直运行
// 无论是否异常最终关闭流式应用(优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
经过测试发现完全没有问题的,代码可以进一步优化,提高性能:由于每批次数据结果RDD输出以后,都需要向MySQL数据库表更新偏移量数据,频繁连接数据库,建议构建数据库连接池,每次从池子中获取连接。
实际项目中将偏移量保存至Zookeeper上或者Redis中,原因如下:
- 1)、保存Zookeeper上:方便使用Kafka 监控工具管理Kafka 各个Topic被消费信息;
- 2)、保存Redis上:从Redis读取数据和保存数据很快,基于内存数据库;


![[jetson]paddlepaddle2.4.0在jetpack5.0.2源码编译流程](https://img-blog.csdnimg.cn/5e1f0192483249e09b608ee31bc86f40.jpeg)