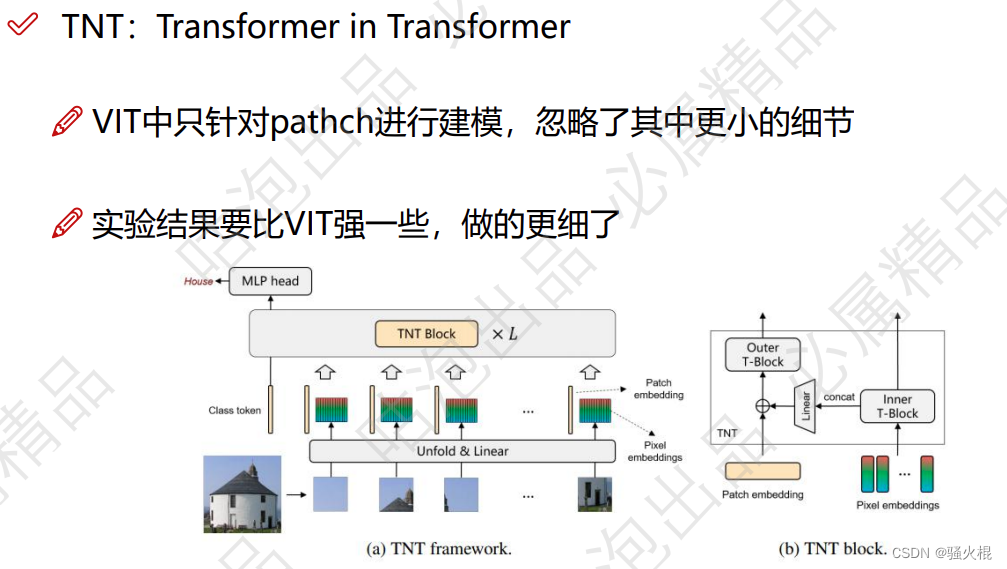
1.索引
1.1概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结果实现。(这里只用通俗的语言和图片进行介绍)
1.2作用
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
索引所引起的作用类似书架目录,可用于快速定位、检索数据。
索引对于提高数据库的性能有很大的帮助。
1.3使用场景
要考虑数据库表的某列或某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询。
该数据库表的插入操作,以及对这些列的修改频率比较低。
索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以及提高效率。
反之,如果非条件查询列,或经常做插入、修改操作,或者磁盘空间不足时,不考虑创建索引。
1.4使用
创建主键约束(primary key)、唯一约束(unique)、外键约束(foreign key)时,会自动创建对应列的索引。
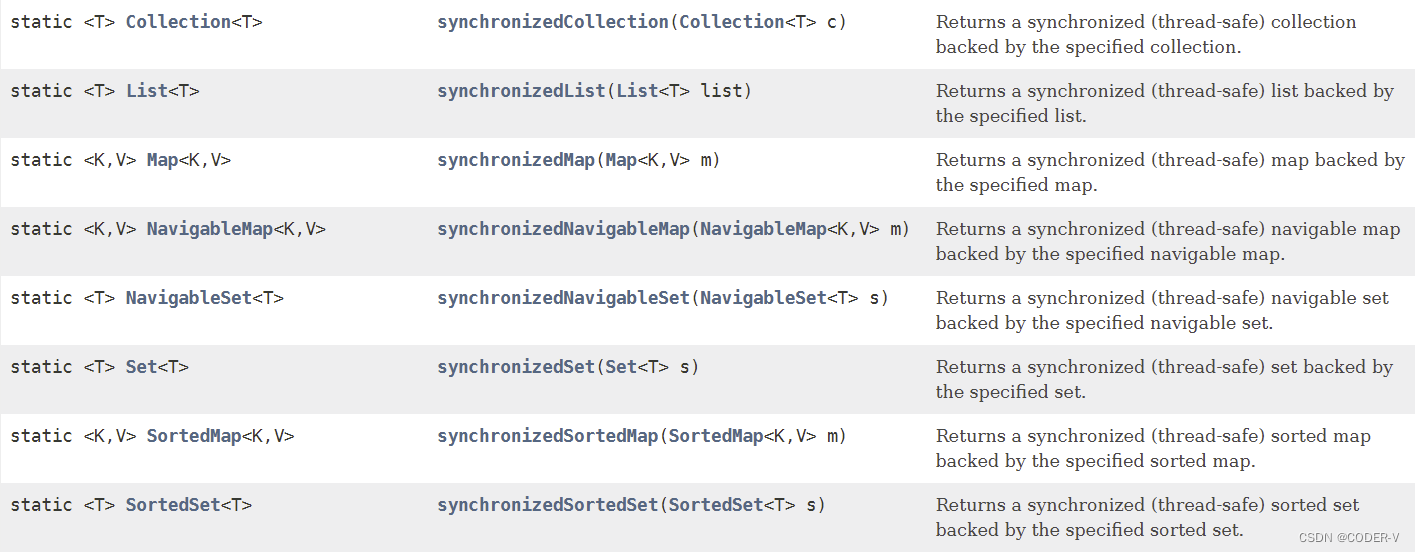
查看索引
show index from table_name;【案例】
查看学生表已有的索引

创建索引
对于一些非主键、非唯一约束、外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);【案例】
创建班级表中,name字段的索引

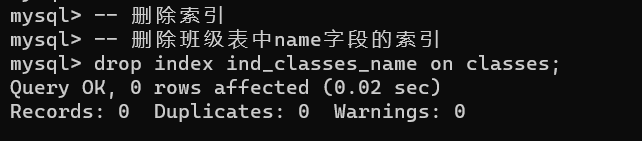
删除索引
drop index 索引名 on 表名;【案例】
删除班级表中name字段的索引
【注意】我们目前使用on的情况,只用jion ... on, drop index ... on,create index ... on
1.5案例
准备测试表:
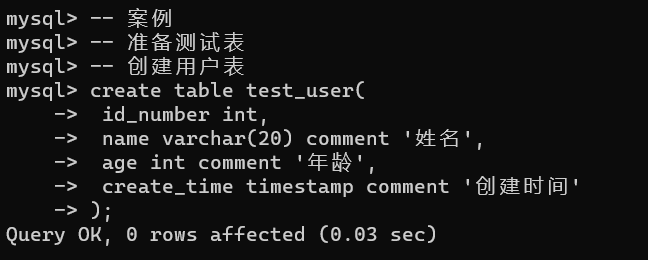
创建、展示、删除索引:

1.6索引背后的数据结构(常见面试题)
索引时通过B+树的数据结构来实现数据的查找的。
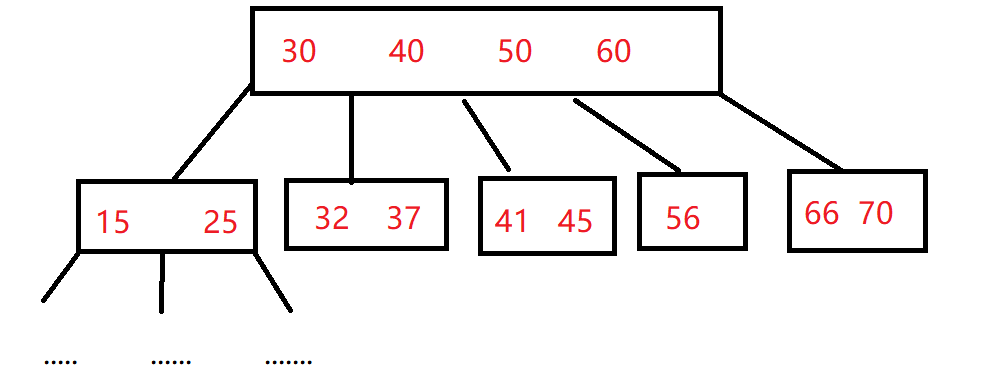
1.6.1 B树(B-树)
我们先了解B-树,也叫做B树。
【注意】“-"读作杠,不是减。
【解析】
B树是一个度为N的树
在关键值key左边的节点都比key小,在关键字key右边的节点都比key大。
树的高度越高,进行查询比较的时候,访问磁盘的次数越多,速度越慢。
无法进行模糊匹配和范围查询(很复杂,需要来回找)
B+树就是在此基础上,进行改进的!
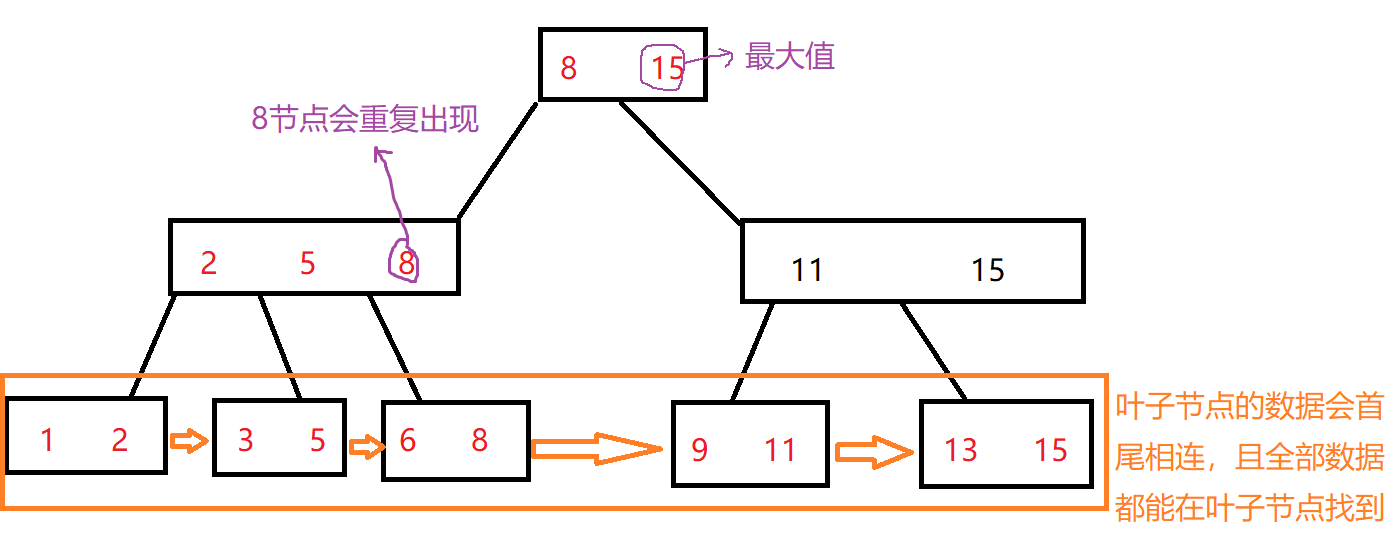
1.6.2 B+树
B+树也叫N叉搜索树。
【解析】
每个节点的最右边即为这颗子树的最大值;
每个节点中,最大值都会重复出现;
叶子节点会首尾相连;
【优势】
能进行范围查询和模糊匹配(每个key都会在叶子节点出现,不用来回查找);
占用内存小:只有叶子节点才会储存完整的信息,非叶子节点只会存储key值,我们可以将索引直接放到内存中也不会占用很大的空间。这样做大大减少了访问硬盘的次数,提高了查找的效率。
所占内存大小估计:假设每个key值占4个字节,总共有10亿条数据,所占内存3.73G,是非常小的。
3.查找次数稳定:每个数据的完整信息都是在叶子节点,查找的次数都是相同的。不会出现个别数据查找的特别慢。
2.事务(常见面试题)
2.1为什么使用事务
-- 使用事物的原因
update account set money = money - 2000
where name = '顾客';
update account set money = money + 2000
where name = '商家';比如上述是一个转账过程。在执行完第一条命令的时候,如果服务器突然宕机,就会出现钱扣了,但是商家没有收到钱的情况。
【解决方案】使用事物来控制,保证两条语句是完全执行的,要么完全失败。
2.2事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么成功,要么失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
2.3使用
-- 使用事务
start transaction;
update account set money = money - 2000
where name = '顾客';
update account set money = money + 2000
where name = '商家';
commit;开始事务:start transaction;
执行多条SQL语句;
回滚或者提交:rollback/commit
2.4事务的四大特性(重点)
原子性[核心的特征]
事务具有原子性,即不可分割性。要么完全执行,要么不执行,不会出现只执行一般宕机的情况。如果服务器在执行事务过程中突然停电,那么在来电的时候,会进行回滚,恢复到原来的数据状态。
一致性
执行事务前后数据是可靠的。例如上述转账的事务,如果事务成功,商家会收到钱,顾客会减少余额。不会出现其他的情况。如果事务失败,顾客的钱不会减少,商家的钱不会增多。同样不会出现其他情况。
持久性
事务修改的内容是写到了硬盘上的,持久存在的。宕机、重启、断电等都不会影响到数据的安全。
隔离性(重点)
隔离性是为了解决“并发”执行事务,而引起的问题。
2.4.1隔离性
并发:多个事务同时读取了一个数据。
【形象的例子】
一个饭馆在同一时间同时进来多个顾客,我们应当先服务谁?
脏读问题
【形象的例子】比如老师正在写笔记(网上),同学可能会看老师的笔记,看来一会就离开了。然后老师继续写笔记,并修改了它。最后上课的时候发现,老师的笔记和昨天看到的不一样了。这就产生了脏读问题。
【对应的实例】我们在某个游戏中充钱,当我们执行完充钱操作(业务没有结束),用户进行查看,发现钱已经有了,但是后来业务回滚,导致钱又消失了。这会让用户产生疑惑。
【解决方法】为了解决脏读问题,mySQL引入了“写操作加锁”的机制。只有数据被写完,并解锁后,才能被其他事务使用。这个写操作加锁,可以降低并发程度,提高了隔离性。但是加锁,开锁需要时间,减低了效率。
【实质】在写的时候读,导致用到了无效的数据。

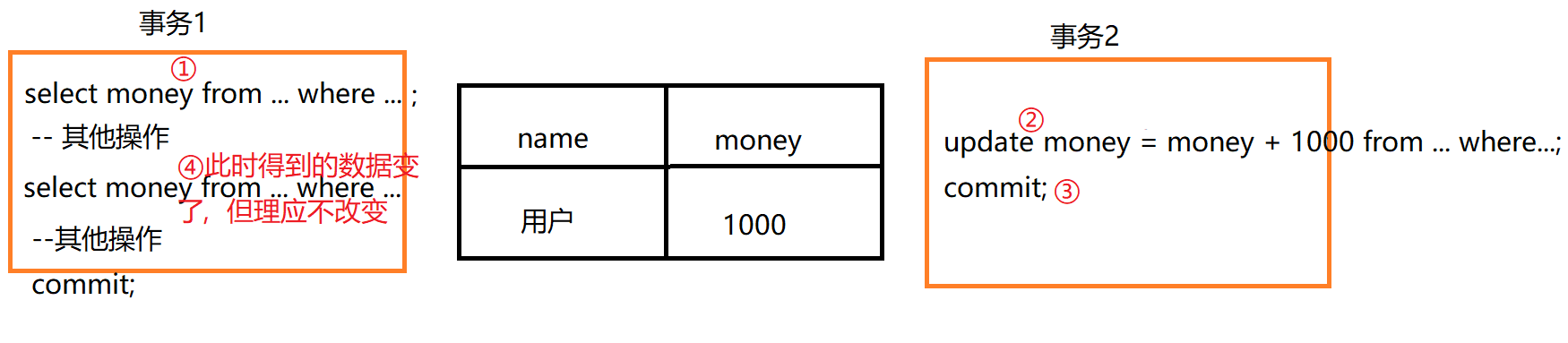
不可重复读
【形象的例子】当老师写完笔记后(记作版本1),同学也在阅读笔记。此时老师认为有些地方写的不好,需要修改,当老师再次提交到网上的时候,同学发现读着读着,笔记变了。就会造成不可重复度的问题。
【对应的实例】我们给游戏中2023.03.03 12:00:00中此时用户点卷达到1000的用户送10点卷,达到2000点卷的用户送20点卷。有个玩家在此时点卷数是1000,我们送给他10点卷(送10点卷的语句结束,送20点卷语句没执行,且处于同一业务)。此时此玩家充值了1000点卷,达到2000点卷,导致又送了20点卷给他。前后送了30点卷。我们应当以同一时刻下的点卷数为准,不应让数量得到修改。
【解决方法】对读加锁,在一个数据被读的时候,不能被写操作。这也会降低效率的,但是降低了并发程度。
【实质】在读的时候写,导致两次读的结果不一样。
幻读
当前已经约定对读加锁、对写加锁,解决了不可重复度和脏读问题。
【形象的例子】在事务A中我们在首先读取表A的所有数据时,得到了全部的数据。并删除了所有的数据。但是另一个事务突然向表中插入数据。然后事务A有读取整张表的数据,本应为空的表,有了数据,最后的到了不可预期的结果。
【本质】在操作一张表时,数据又进行了增删,导致数据量改变。