本篇总结链表解题思路----快慢指针,其实也就是双指针,这个快慢并不单纯指“快慢”,它更多的可以表示,速度快慢,距离长度,时间大小等等,用法很有趣也很独特,理解它的思想,是很有必要的。
- 🍭1.链表的中间结点----'速度'
- 🍭2.链表中倒数第k个结点----'距离'
- 🍭3.移除链表元素
🍭1.链表的中间结点----‘速度’

要求返回链表中的中间结点;
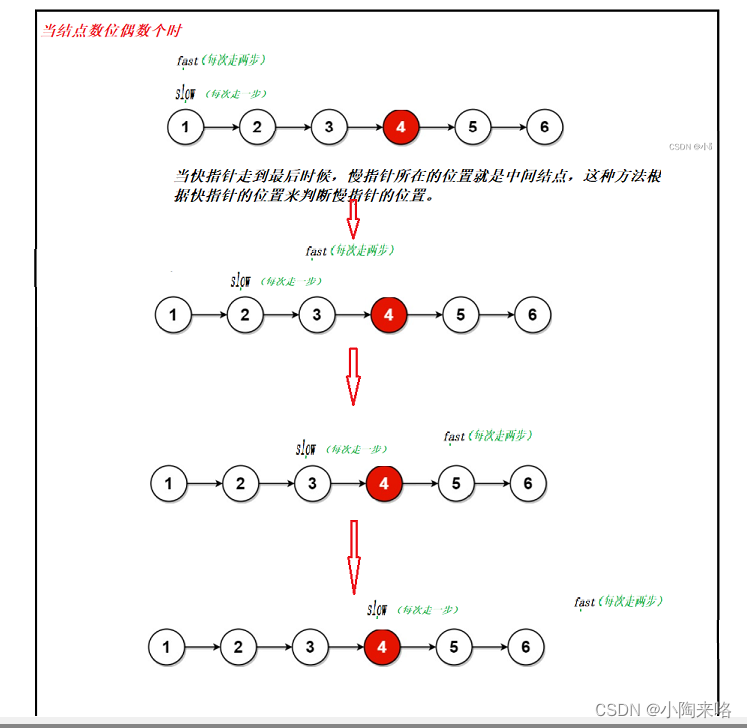
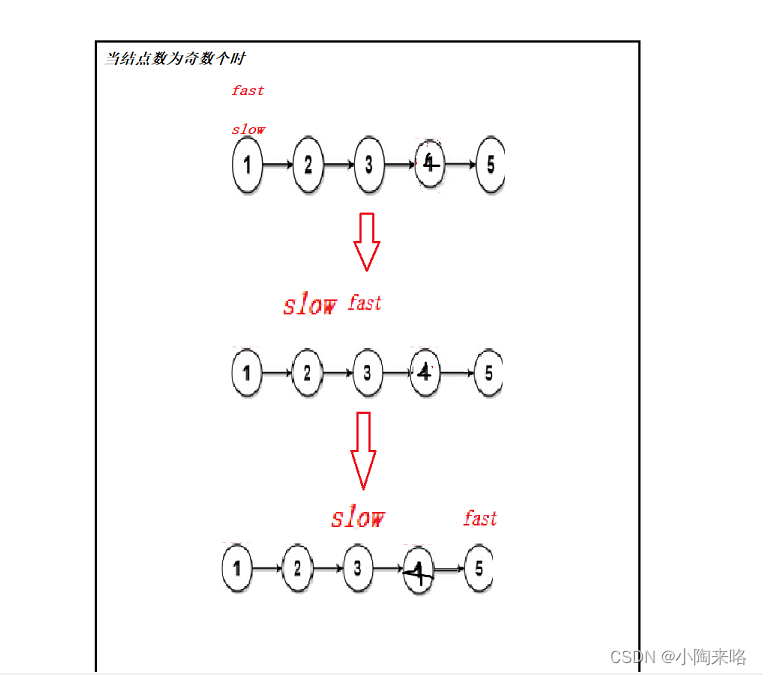
当有奇数个结点时,返回中间的结点,当有偶数个结点时,返回第二个中间结点。
传统的思想是遍历链表,算链表长度,然后再找中间值。
但如果只允许遍历一遍链表呢?这种方法就不好使了。
使用快慢指针,轻松解决。
什么叫快慢指针,就是让两个指针都指向链表同时往后走,一个指针每次走两步,称为快指针,一个指针每次走一步,称为慢指针。
当快指针走到尾时,而慢指针所指向的地方就是中间结点。
这种天才想法在后面的许多链表题中都有应用,对解题很棒。
本题需要注意一下奇数个和偶数个结点有什么不同,当结点为偶数时,fast走到了最后一个结点的后面,所以fast成为NULL,当结点为奇数时,fast走到最后一个结点停止,所以fast->next为NULL。所以这个循环的条件就是fast和fast->NULL都不为空时,快慢指针才能往后走。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode *fast,*slow;//设置两个指针
fast=slow=head;//让快慢指针同时从开头走
while(fast!=NULL&&fast->next!=NULL)//当fast不为NULL和fast->next不为空时,才可以正常走,一旦有一个为NULL,则说明两种情况中有一个完成。
{
slow=slow->next;//慢指针每次走一步
fast=fast->next->next;//快指针每次走两步
}
return slow;//最后不管结点是偶数个还是奇数个,返回值都是慢指针指向的位置
}

🍭2.链表中倒数第k个结点----‘距离’

先输入k,要求输出该链表的第k的位置上的结点。
传统思想,遍历链表,算出长度,然后用长度减k再加1即可。
那如果跟上面一样只给你遍历一遍链表那该怎么做呢?
同样方法,快慢指针
只不过这时比较的不是速度了,而是两个指针之间的距离。



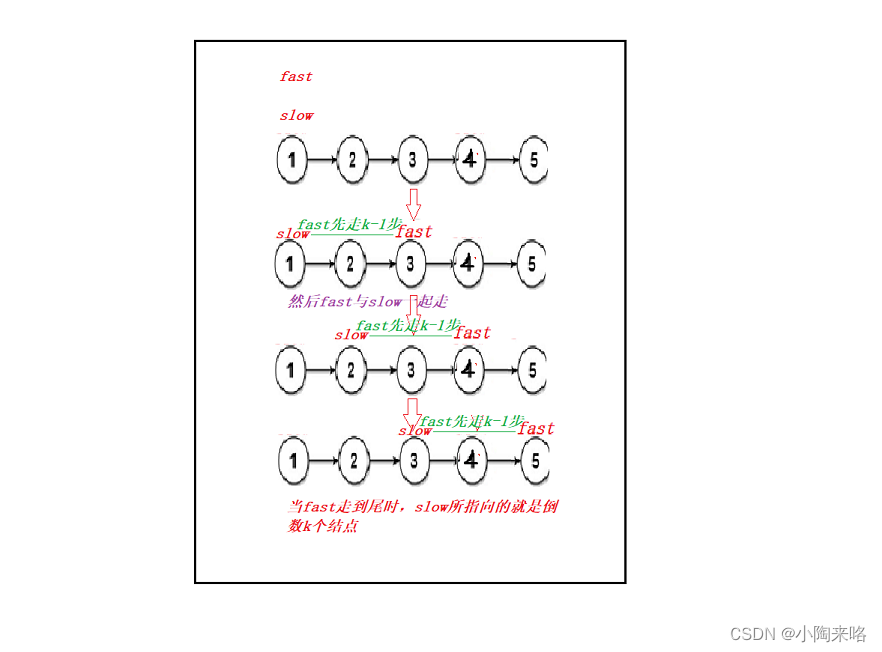
我们可以让快指针先走k-1步,然后再让慢指针开始走,当快指针走到最后一个结点时停止,慢指针指向的就是要输出的。
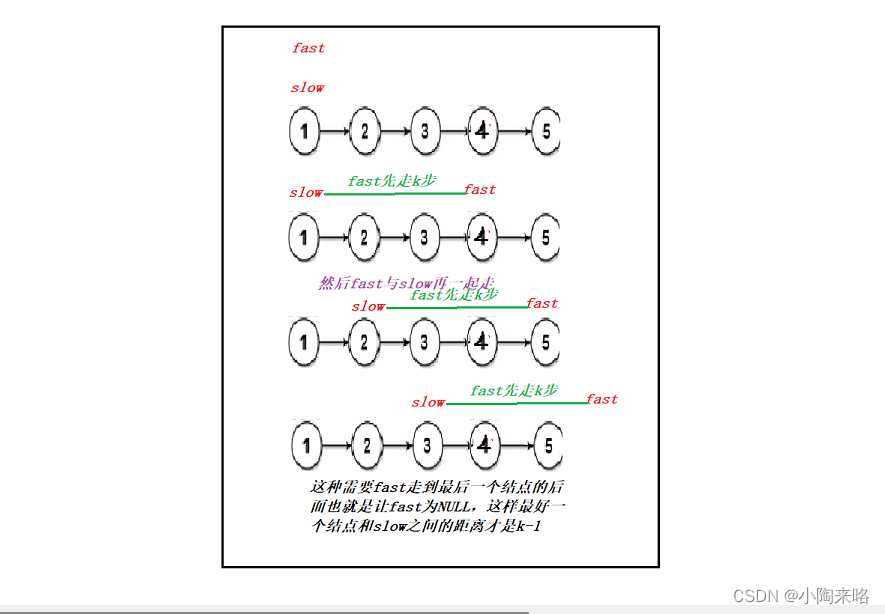
我们还可以让快指针先走k步,然后让慢指针开始走,这时,快慢指针之间的距离就变成了k,当快指针走到最后一个结点时,慢指针其实指向的是前面的结点,而要让慢指针指向后面的结点,让快指针再走一步就可以了。
代码如下:
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
struct ListNode *fast,*slow;//定义两个指针
fast=slow=pListHead;//一开始快慢指针都指向开头
if(fast==NULL)//如果链表为空链表则无法返回,返回NULL
return NULL;
int num=k-1;
if(k==0)//如果是倒数0个那么也返回NULL
{
return NULL;
}
while(num--)//先让快指针走k-1步
{
if(fast->next==NULL)//我们要确保k的大小不能大于链表的长度对吧,当k的长度大于链表时,就会让链表访问越界,所以先给fast往后走时,要注意不能越界了,如果fast->next为NULL,则表明k是大于链表长度的,之间返回NULL
{
return NULL;
}
fast=fast->next;
}
while(fast->next)//判断结束的条件是当fast->next为NULL时,结束,也就是fast走到最后一个结点时停止,这时快慢指针之间的距离为k-1,而最好一个结点与慢指针所指向的结点的距离就是k-1
{
slow=slow->next;//慢指针和快指针一起走
fast=fast->next;
}
return slow;//最后返回slow位置即可
}

第二种图解:
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
struct ListNode *fast,*slow;//定义两个指针
fast=slow=pListHead;
if(fast==NULL)//当链表为空时,返回NULL
return NULL;
while(k--)//快指针先走k步
{
//要考虑k如果大于链表本身长度时就非法
if(fast==NULL)
{
return NULL;
}
fast=fast->next;//
}
while(fast)//这个和快指针先走k-1的结束条件不一样喔,这个结束条件应该是快指针走到最后结点的后面,所以是fast为NULL循环结束
{
slow=slow->next;//快慢指针一起走
fast=fast->next;
}
return slow;//返回慢指针所在的位置
}
🍭3.移除链表元素
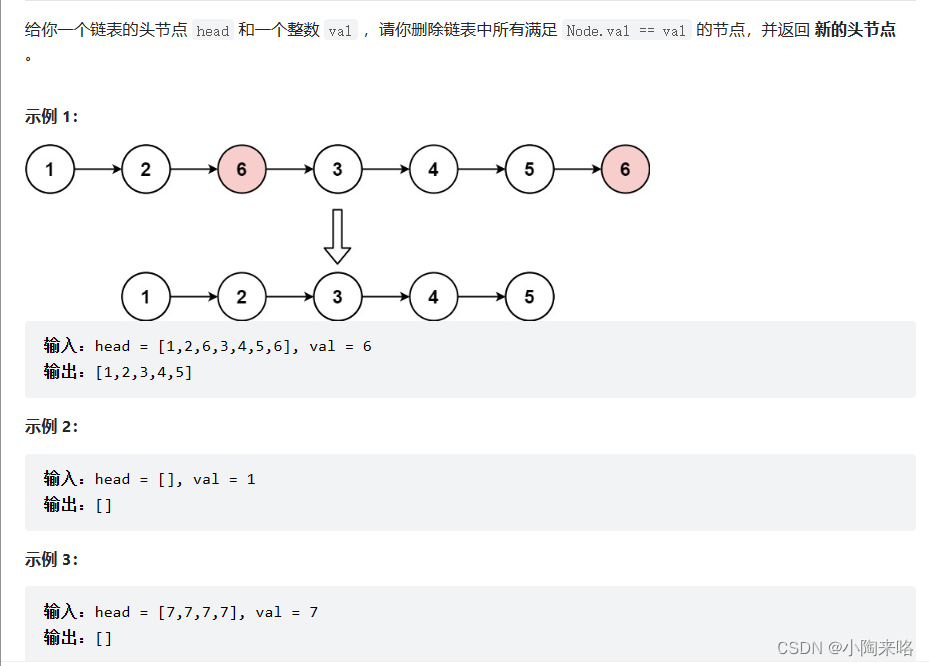
方法1:
我们可以按照传统单链表是如何删除来写。
单链表如何删除呢?
我们要删除这个结点,还要将前面的结点和后面的结点链接起来。这时我们就必须要记录下前面结点的地址了,不然单链表无法再找到前一个结点。
所以我们可以用双指针,一个是进行遍历的指针cur,另一个是用来记录它前面结点的位置的指针prev。
当cur->val!=val时,cur先赋值给prev记录这个位置,然后cur再往后走。
当cur->cal==val时,那么就要将前一个结点链接到后一个结点上。
pre->next=cur->next;
然后释放掉cur。
大体思路是这样,不过还有一些细节问题。
比如如果最后一个元素是要被删的,那么前面一个结点的next就变成野指针了。
所以我们需要将他置为NULL。
还有个问题,如果第一个就是要被删除的结点,那么prev->next就非法,所以要进行讨论
当prev= =NULL时,说明第一个结点就要被删除,相当于头删。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*cur=head;//cur用来遍历链表,首先指向最前面的
struct ListNode*prev=NULL;//一开始prev为空
while(cur)//利用cur进行遍历
{
if(cur->val!=val)//如果不等于
{
prev=cur;//让prev记录这个位置
cur=cur->next;//cur往后走
}
else//如果等于
{
if(prev==NULL)//要考虑是否是第一个要删除的,当prev==NULL时,就是删除第一个结点
{
head=cur->next;//将头结点与第二个结点链接
free(cur);//是否cur
cur=head;//cur往后走,也就是走到第二个结点位置
}
else
{
prev->next=cur->next;//将前面的与后面的链接
free(cur);//删除中间的
cur=prev->next;//cur往后走
}
}
}
return head;//返回头结点
}
方法2:
我们可以利用数组删除元素的思想来删除链表中的结点
在数组中我们是将不等于val的元素放入一个新的数组。
而在链表里我们也可以这样,当不等于val的结点我们就插入到一个新的链表上去,所以我们还需要创建一个新链表。
我们每次将新结点插入到新链表中时都需要找尾,非常烦人,我们可以定义一个尾指针tail,用来指向新插入结点的地址。
如果cur->val!=val那么就进行尾插,将新结点插入新链表
如果cur->val=val,那么cur 就往后走。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode*cur=head;
struct ListNode*tail=NULL,*newnode=NULL;//创建一个新结点
while(cur)//遍历链表
{
if(cur->val!=val)//如果不相同,就把不相同的结点插入到新的链表中
{
//尾插
if(newnode==NULL)//最初新链表肯定为空,可以直接将cur指向的不相同的结点放入到新链表中
{
newnode=tail=cur;
}
else
{
tail->next=cur;//cur所对应的结点插入到tail后面
tail=tail->next;//tial要往后走,记录下一个插入结点的位置
}
cur=cur->next;//cur也要往后走
}
else
{
struct ListNode*next=cur->next;//如果元素相同,那先把这个结点的下一个结点地址记录下来
free(cur);//释放这个要删除的结点
cur=next;//cur往后走
}
}
if(tail!=NULL)//当tail不为空时,我们需要将tail的next置为NULL
tail->next=NULL;
return newnode;
}