深信服面经---云计算高级开发
- 一、一面问题概览
- 二、实操相关
- 三、复盘对问题答案进行整理(查漏补缺)
- 3.1、go语言简单了解
- 3.2、项目中成就感最大或挑战最大的地方
- 3.3、项目问题---协议头引入之后,包的大小增加了多少
- 3.4、如何建立缓存
- 3.5、cache中间件更新机制
- 3.6、redis缓存的写策略
- 3.7、redis缓存热点数据,在什么场景下会产生脏数据
- 3.8、在CRUD中如果操作主数据库和缓存数据库
- 3.9、内存泄漏怎么检测?
- 3.10、socket句柄比较多,怎么分析和解决?
- 3.11、什么是零拷贝?
- 3.12、协程、线程、进程三者的关系和区别
- 3.13、父子进程在资源上有什么区别?
- 3.14、C++中map数据结构,底层为什么不使用高度平衡二叉树?
- 3.15、消息队列存在的价值
- 3.16、引入消息队列会带来什么问题?
- 四、面向stack overflow编程
- 五、算法题
- 总结
- 参考
一、一面问题概览
1、先做一下的自我介绍。
2、是否了解go语言?
3、项目中成就感最大的是哪个?
4、协议头引入之后,包的大小增加了多少(根据项目问的)?
5、redis缓存问题,如何建立缓存(根据项目问的)?
6、cache中间件更新机制是怎么样的(根据项目问的)?
7、为什么更新数据的时候不是用写的方式而是使用删除的方式(根据项目问的)?
8、redis缓存热点数据,具体在什么场景下会产生脏数据?
9、在CRUD中,你的后台服务是先处理数据库还是先处理缓存(redis)?这四个操作分别是怎么处理的?
10、缓存方案中,先删除缓存数据,再更新数据库,最后再同步(写),这种方式在高并发下会产生什么问题 ?数据一致性会不会有问题?(或者说同时出现并发读和并发写的情况,会发生什么?)
11、还知道其他的缓存更新模式吗?
12、内存泄漏怎么检测?
13、如果一个服务的句柄(文件句柄或socket句柄)一直增加没有下降,怎么分析?是什么问题?
14、系统下调大句柄数量的命令是什么?ulimit。
15、socket句柄比较多,怎么分析和解决?这种现象在什么情况下是正常的?在什么场景下是不正常的?
16、服务非常多,接口也非常多,现在不知道在内存或socket句柄在何处泄漏的,怎么分析?
17、什么是零拷贝?
18、哪些技术可以做到零拷贝?
19、什么是Direct IO?
20、操作系统上,说一下协程、线程、进程三者的关系?在资源上面有什么差别?
21、父子进程在资源上有什么区别?(可以从fork的写时复制来说明)
22、C++中map数据结构,底层为什么不使用高度平衡二叉树来做?(https://blog.csdn.net/weixin_61207303/article/details/123402294)
23、对windows上的程序开发是怎么理解的?
24、window开发客户端最头疼的问题是什么?
25、windows用户界面库有哪些?(qt、duilibUI)
26、消息队列存在的价值是什么?主要解决什么问题?
27、引入消息队列会带来什么问题?
28、说一下消息队列的优缺点
二、实操相关
1、面向google编程,面向stack overflow编程,画出流程图。
1)Google不到代码怎么办?
2)如果google到的代码最后验证不是想要或合适的(验证失败),怎么办?
2、算法题,给一个数组root[]={6,3,5,3,6,7,8,-1,-1,5,6},构建二叉树,然后中序遍历输出二叉树。
小结:
- 回答方式有待提升,需要拓展讲述技术,切忌一问一答(应该就问的知识点进行扩展讲述)。
- 回答需清晰贯通,尽量避免停顿。
- 语速平和,逻辑要清晰。
三、复盘对问题答案进行整理(查漏补缺)
3.1、go语言简单了解
大厂后端高并发程序 / 服务基本都有引入golang语言来开发,所以需要了解一下golang语言。
golang为高并发而生,由google在2009年正式发布,golang从语言级别支持并发,通过轻量协程goroutine实现程序并发运行。
golang语言是google推出的具有强类型,原生支持并发,且具有垃圾回收(GC)功能的编译型语言。Go 语言语法与 C 相近,但功能上有:内存安全,GC(垃圾回收),结构形态及 CSP-style 并发计算。
golang的轻量主要体现在:
- 上下文切换代价小。goroutine上下文切换只涉及三个寄存器(计数寄存器PC、堆栈指针寄存器SP、数据寄存器DX)的值修改,而对比线程的上下文切换则需要涉及模式切换(从用户态切换到内核态)、以及 超过16 个寄存器的刷新。
- 内存占用少。线程栈空间是2M,goroutine的栈空间最小只有2K。
Golang 程序中可以轻松支持10w 级别的 Goroutine 运行,而线程数量达到 1k 时,内存占用就已经达到 2G。
go调度器模型通常称为G-P-M模型,它包括四个重要结构:G、P、M、Sched。go程序通过调度器来调度goroutine在内核线程上的执行,但是G(goroutine)并不直接绑定OS线程M(Machine)运行,而是由goroutine scheduler中的P(processor,逻辑处理器)来作为获取内核线程资源的中介。
Go 调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ);每个 P 都有一个 LRQ,用于管理分配给在 P 的上下文中执行的 Goroutines,这些 Goroutine 轮流被和 P 绑定的 M 进行上下文切换。GRQ 适用于尚未分配给 P 的 Goroutines。
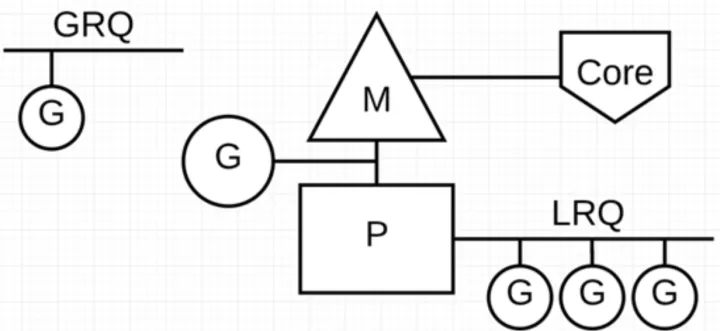
(1)G:Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
(2)P: Processor,表示逻辑处理器,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P 才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态,任务队列等。P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。P 的数量由用户设置的 GoMAXPROCS 决定,但是不论 GoMAXPROCS 设置为多大,P 的数量最大为 256。
(3)M: Machine,OS 内核线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取。M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
(4)Sched:Go 调度器,它维护有存储 M 和 G 的队列以及调度器的一些状态信息等。调度器循环的机制大致是从各种队列、P 的本地队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 Go exit 做清理工作并回到 M,如此反复。
Go 程序可以利用少量的内核级线程来支撑大量 Goroutine 的并发。多个 Goroutine 通过用户级别的上下文切换来共享内核线程 M 的计算资源,但对于操作系统来说并没有线程上下文切换产生的性能损耗。
为了更加充分利用线程的计算资源,Go 调度器采取了以下几种调度策略:
(1)任务窃取(work-stealing)。当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ,或者其他 P 的 LRQ 中获取 G 执行。
(2)减少阻塞。在 Go 里面阻塞主要分为一下 4 种场景:
- 由于原子、互斥量或通道操作调用导致 Goroutine 阻塞,调度器将把当前阻塞的 Goroutine 切换出去,重新调度 LRQ 上的其他 Goroutine。
- 由于网络请求和 IO 操作导致 Goroutine 阻塞,Go 程序提供了网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台实现 IO 多路复用。通过使用 NetPoller 进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞 M。这可以让 M 执行 P 的 LRQ 中其他的 Goroutines,而不需要创建新的 M;有助于减少操作系统上的调度负载。实现了 goroutine-per-connection 简单的网络编程模式(但是大量的 Goroutine 也会带来额外的问题,比如栈内存增加和调度器负担加重)。
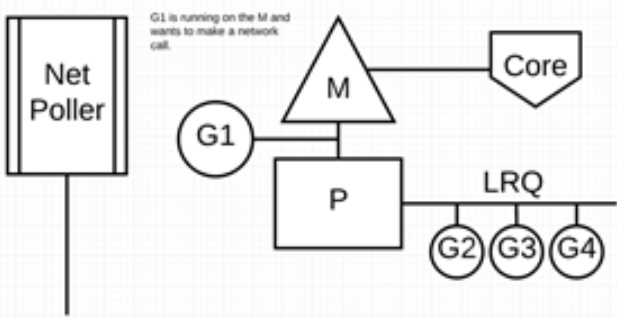
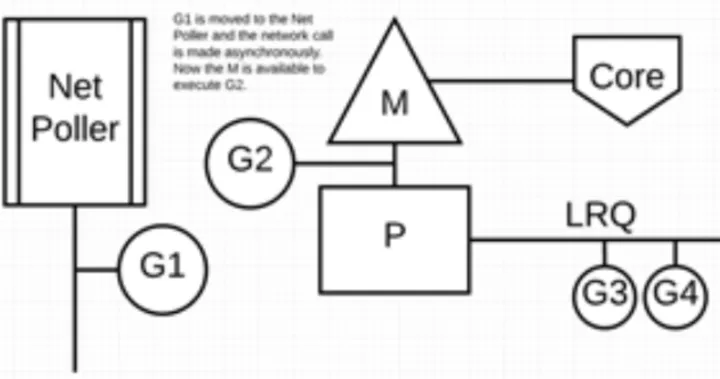
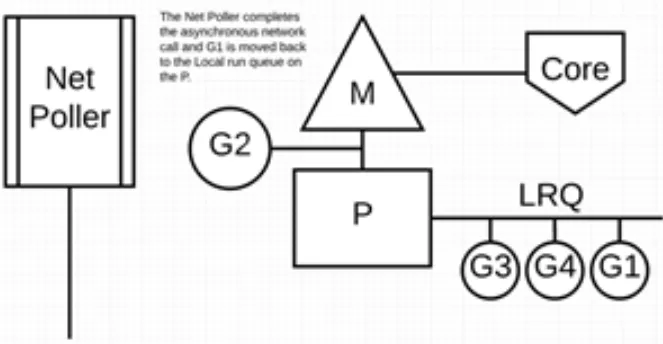
- 当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞,这种情况下,网络轮询器(NetPoller)无法使用,而进行系统调用的 Goroutine 将阻塞当前 M。调度器将 M1 与 P 分离,同时也将 G1 带走。然后调度器引入新的 M2 来服务 P。此时,可以从 LRQ 中选择 G2 并在 M2 上进行上下文切换。阻塞的系统调用完成后,G1 可以移回 LRQ 并再次由 P 执行。如果这种情况再次发生,M1 将被放在旁边以备将来重复使用。
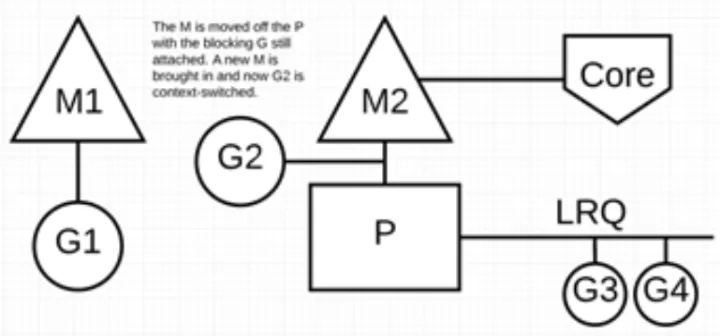
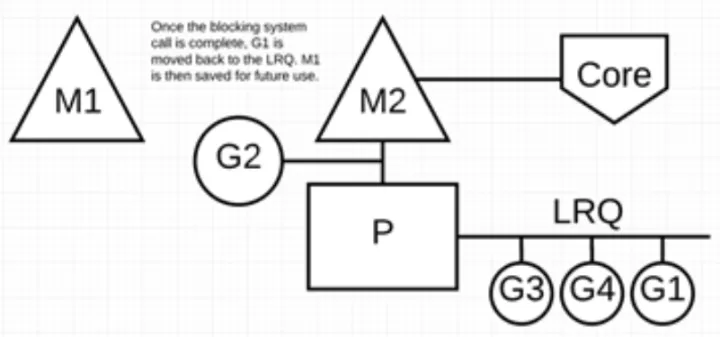
- 如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。只要下次这个 Goroutine 进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入 P 的本地队列里面等待下次执行。
3.2、项目中成就感最大或挑战最大的地方
没有有挑战的项目可以考虑项目用到的技术栈有哪些风险,然后针对存在的风险,给出一套完美的解决方案。
有好项目的可以从系统设计的层面上讲述。
比如我的项目中,要设计开发一个局域网内高效的后台服务器程序,最大的成就是设计了一个高效网络传输协议,为集中式并发提供高效应答(或者,最大的挑战是如何设计出一个高效的网络模型和通信协议,实现高并发应答),项目中,客户端只知道服务端开放的端口,第一个版本中为了保证数据的可靠性,主要使用TCP传输数据,但是因为不知道服务器的IP,所以先使用UDP发送广播来探寻服务器,获得服务器IP后转为TCP来传输数据;后来经过验证,传输的数据大部分都比较小,而且在局域网内UDP丢失数据的概率极低,因此转为UDP为主进行应答,因为UDP 具有较好的实时性,工作效率比 TCP 高,应答效率和数据传输效率提高了一倍。
这个过程,不仅仅体现出你排查解决问题的能力,另一方面也突出你的沉淀和自我思考能力。
3.3、项目问题—协议头引入之后,包的大小增加了多少
在我的项目中,引入了这样的协议头:
1 byte 1 byte 6 bytes
+--------+--------+-----------------------------------------------------+
| opcode | pl_len | src_ip |
+-----------------------------------------------------------------------+
| src_ip |
+-----------------+-----------------------------------------------------+
| src_ip | src_mac |
+-----------------+-----------------+-----------------------------------+
| src_mac | src_port | des_ip |
+-----------------------------------------------------------------------+
| des_ip |
+-----------------------------------+-----------------------------------+
| des_ip | des_mac |
+-----------------------------------+-----------------+-----------------+
| des_mac | des_port | preload |
+-----------------------------------------------------------------------+
| ... |
| preload |
| ... |
+-----------------------------------------------------------------------+
7*8-2=54字节,所以最大多出了54字节,最少22字节(只有头、MAC地址以及端口)其中有一个字节包含了可能存在的分片预留位。
3.4、如何建立缓存
采用redis nosql数据库作为Mysql数据库的缓存,在查找的时候,首先查找redis缓存,如果找到则返回结果;如果在redis中没有找到,那么查找Mysql数据库,找到的话则返回结果并且更新redis;如果没有找到则返回空。对于写入的情况,直接写入mysql数据库,mysql数据库通过触发器及UDF机制自动把变更的内容更新到redis中。
3.5、cache中间件更新机制
同步方案可以有:
(1)伪装从数据库。比如阿里开源的canal方案、kafka、go-mysql-transfer等。
(2)MySQL的触发器+udf。udf全称User-defined function,是MySQL提供的一种可扩展代码。UDF不具备事务,不能回滚;而且效率较低。
3.6、redis缓存的写策略
以MySQL为主,保证缓存不可用,整个系统依然要保持正常工作;mysql 不可用的话,系统停摆,停止对外提供服务。
(1)从安全优先方面考虑;先删除缓存,再写 mysql,后面数据同步交由 go-mysql-transfer 等中间件处理。先删除缓存,为了避免其他服务读取旧的数据;也是告知系统这个数据已经不是最新,建议从 mysql 获取数据。
(2)从效率优先方面考虑;先写缓存,并设置过期时间(如 200ms),再写mysql,后面数据同步交由其他中间件处理。这里设置的过期时间是预估时间,大致上是 mysql 到缓存同步的时间。在写的过程中如果 mysql 停止服务,或数据没写入 mysql,则200 ms 内提供了脏数据服务;但仅仅只有 200ms 的数据错乱,即效率优先的写策略也有安全性的问题,但只会影响200ms。
3.7、redis缓存热点数据,在什么场景下会产生脏数据
所谓产生脏数据,就是主数据库与缓存数据库的数据不一致,这种情况一般在效率优先的写策略中会产生,但因为设置了过期时间,所以只会影响一定时间。
3.8、在CRUD中如果操作主数据库和缓存数据库
(1)C,创建一条数据:从安全优先考虑,先写入MySQL,然后通过中间件go-mysql-transfer更新缓存数据库redis;从效率优先考虑,先写入redis并设置过期时间,再写入mysql。
(2)R,查询数据:先查询redis,如果有则直接返回,如果没有再访问mysql查询,mysql中也没有就返回空,mysql中有就返回数据,并通过中间键更新redis缓存。
(3)U,更新数据:先删除redis的数据,再写数据库,然后通过中间件go-mysql-transfer更新缓存数据库redis。
(4)D,删除数据:先删除redis的数据,再删除mysql的数据。
3.9、内存泄漏怎么检测?
debug版本,通过VLD库或CRT库分析内存泄漏,但是服务器有很多问题需要在线上并发压力情况下才出现,因此讨论Debug版调试方法意义不大。
对于release版本:
(1)静态方式检测。使用cppcheck、BEAM等工具检测代码文件是否有内存泄漏隐患。
(2)入侵式检测。实现内存泄漏检测组件,嵌入代码中,比如hook住分配内存的函数、mtrace追踪内存分配、对象计数方式;C++还可以重载内存分配和释放函数 new 和 delete。这种方式的缺点是要修改原代码,而且对于第三方库、STL容器、脚本泄漏等因无法修改代码而无法定位。
(3)已经上线的服务器程序,可以使用Valgrind、AddressSanitizer等工具定位到具体的内存泄漏位置。
3.10、socket句柄比较多,怎么分析和解决?
(1)查看当前socket使用状态。
# 方法一
cat /proc/net/sockstat
# 方法二
ss -s
(2)如果是FIN_WAIT和TIME_WAIT的,可以调整fin超时时间或者其他内核参数来解决。
(3)如果是出现大量CLOSING状态,基本上业务上要处理的逻辑过多,导致一直在CLOSING状态;可以使用异步,将网络层和业务层分离,单独处理。
3.11、什么是零拷贝?
零拷贝技术就是绕过用户态,用户缓存区不参与数据拷贝;避免了内核态和用户态的冗余数据拷贝,减少上下文切换。
linux系统提供两个零拷贝接口:mmap和sendfile:
- mmap通过DMA将磁盘数据拷贝到内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不用将内核缓冲区的数据拷贝到用户缓冲区,应用程序调用send或者write时,系统直接将内核缓冲区的内容拷贝到socket缓冲区,然后发送出去。使用mmap至少减少了一次数据拷贝,但是仍然会有用户空间和内核空间的上下文切换。
- sendfile的数据传输只发生在内核态,应用程序调用sendfile,系统会将数据拷贝到page cache,然后拷贝到socket buffer,再通过网卡发送出去。这种发送不仅减少了数据拷贝的次数,还减少了上下文切换。如果网卡支持SG-DMA,还可以再去除 Socket 缓冲区的拷贝,这样一共只有 2 次内存拷贝。
此外,还有一个direct io技术,绕过内核缓冲区,在用户空间和磁盘之间传输数据,减少内核缓冲区和用户数据的复制次数。降低了文件读写所带来的CPU负载能力和内存带宽的占用率。
3.12、协程、线程、进程三者的关系和区别
进程:是一个运行程序,有自己独立的内存空间,是系统资源分配的最小单位。进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程:是一个轻量级的进程,一个进程至少包含一个线程,同一个进程中的线程组共享内存空间,是操作系统调度执行的最小单位。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相⽐进程不够稳定容易丢失数据。
协程:一个用户态的轻量级线程,协程的调度完全由应用程序控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
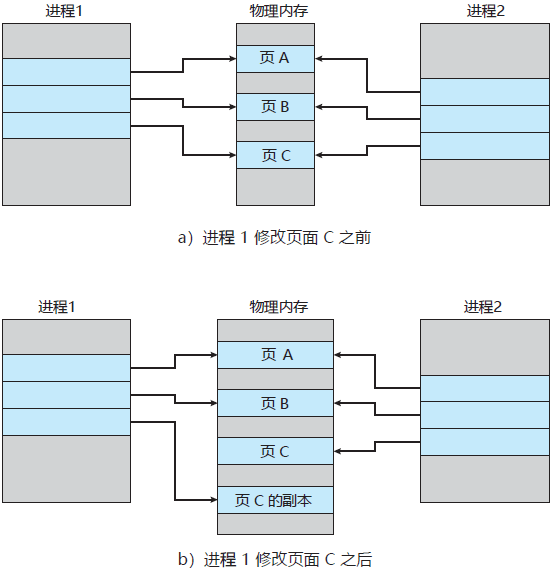
3.13、父子进程在资源上有什么区别?
父进程通过fork创建子进程,刚开始时两者都没有对内存作出改动,父子进程共享内存资源。内核fork()时并不复制整个进程地址空间,而是让父子进程共享一个地址空间,只有在需要写入时,数据才会被复制,从而使各个进程拥有各自的拷贝数据。也就是说,只有在需要写入的时候才复制资源,在此之前,以只读方式共享。
3.14、C++中map数据结构,底层为什么不使用高度平衡二叉树?
最常见的两种自平衡树算法是红黑树和AVL树。为了在插入/更新后平衡树,两种算法都使用旋转的概念,其中树的节点被旋转以实现重新平衡。
AVL的左右子树高度差不能超过1,每次进行插入或删除操作时几乎都需要通过旋转操作保持平衡,在频繁插入或删除的场景中,频繁的旋转操作使得AVL的性能大打折扣。
红黑树的红黑规则只需要保证黑色节点高度一样(黑高),通过牺牲严格的平衡,换取插入、删除时少量的旋转操作,整体性能优于AVL。红黑树插入的不平衡,不超过两次旋转就可以解决;删除时的不平衡,不超过三次旋转就能解决。
虽然在这两种算法中,插入/删除操作都是 O ( l o g 2 n ) O(log_2^n) O(log2n),但在红黑树重新平衡旋转的情况下是 O(1) 操作,而在 AVL 的情况下,这是一个 O ( l o g 2 n ) O(log_2^n) O(log2n)操作,这使得红黑树在重新平衡阶段的这一方面更有效,这也是它更常用的可能原因之一。
3.15、消息队列存在的价值
消息队列的优点:
- 解耦:允许独立的扩展或修改队列两边的处理过程。
- 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况。
- 灵活性和峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的访问压力。
- 异步通信:消息队列允许用户把消息放入队列但不立即处理它。
3.16、引入消息队列会带来什么问题?
- 消息队列会降低系统的可用性。
- 会提高系统复杂度。
- 需要考虑一致性问题。
四、面向stack overflow编程
五、算法题
给一个数组root[]={6,3,5,3,6,7,8,-1,-1,5,6},构建二叉树,然后中序遍历输出二叉树。
#include <vector>
#include <string>
#include <queue>
#include <iostream>
using namespace std;
//二叉树结点结构
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode() :val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) :val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode* left, TreeNode* right) :val(x), left(left), right(right) {}
};
TreeNode* createBinaryTree(vector<int> nodes) {
int len = nodes.size();
if (len == 0) {
return NULL;
}
if (nodes[0] == -1) {
return nullptr;
}
TreeNode* root;
//建立结点队列并将根节点入队
queue<TreeNode*> nodesQue;
root = new TreeNode(nodes[0]);
nodesQue.push(root);
//loc遍历数组,每次取两个结点
for (int loc = 1; loc < len; loc = loc + 2) {
//获取结点并出队
TreeNode* node = nodesQue.front();
nodesQue.pop();
//获取队头结点的左右结点
int left = nodes[loc];
int right = nodes[loc + 1];
//赋予左右结点
if (left == -1) {
node->left = nullptr;
}
else {
node->left = new TreeNode(left);
nodesQue.push(node->left);
}
if (right == -1) {
node->right = nullptr;
}
else {
node->right = new TreeNode(right);
nodesQue.push(node->right);
}
}
return root;
}
void dfs(TreeNode* root)
{
if(root==nullptr)
{
cout<<"null"<<endl;
return;
}
cout<<root->val<<endl;
dfs(root->left);
dfs(root->right);
}
int main()
{
vector<int> root={6,3,5,3,6,7,8,-1,-1,5,6};
TreeNode* cur= createBinaryTree(root);
dfs(cur);
return 0;
}
总结
- 从 Go 调度器架构层面上介绍了 G-P-M 模型,通过该模型怎样实现少量内核线程支撑大量 Goroutine 的并发运行。以及通过 NetPoller、sysmon 等帮助 Go 程序减少线程阻塞,充分利用已有的计算资源,从而最大限度提高 Go 程序的运行效率。
- 消息队列带来的好处:解耦、削峰、异步,提高系统响应速度和稳定性。
参考
- 腾讯技术
- MySQL缓存策略
- Go语言详解
- DMA,Direct IO和零拷贝
- C++ SLT map和unorder_map底层原理


![[算法与数据结构]--贪心算法初识](https://img-blog.csdnimg.cn/e48f3734a3d746b3929b4333b7eaebe9.png)