上一篇调研之后,还是没有思路,继续调研文献。
文章目录
- WEAKLY SUPERVISED EXPLAINABLE PHRASALREASONING WITH NEURAL FUZZY LOGIC
- 模型结构
- ASK ME ANYTHING: A SIMPLE STRATEGY FOR PROMPTING LANGUAGE MODELS
- Humanly Certifying Superhuman Classifiers
- HUMAN-GUIDED FAIR CLASSIFICATION FOR NATURAL LANGUAGE PROCESSING
- 模型的框架
- OPTIMIZING BI-ENCODER FOR NAMED ENTITY RECOGNITION VIA CONTRASTIVE LEARNING
- KNOWLEDGE-IN-CONTEXT: TOWARDS KNOWLEDGEABLE SEMI-PARAMETRIC LANGUAGE MODE
WEAKLY SUPERVISED EXPLAINABLE PHRASALREASONING WITH NEURAL FUZZY LOGIC
蕴含关系的分类问题,首先识别出句子中的短语块,软匹配到最接近的短语,然后,通过判断phrase之间的关系,进而得到句子的蕴含关系(可解释性会强一些)
在模型参数更新上,考虑使用adversary loss函数,使应该接近的更加靠近,应该疏远的短语彼此之间距离更远。
也许,相似函数与adversary Loss函数是绝配
我们通过弱监督短语逻辑推理来解决NLI的可解释性问题。
所以,使用phrase的软匹配,还是为了可解释性的问题。。。。短语是突破口,短语相似度是工具或者说方法
.我们的模型将短语作为语义单位,并通过嵌入相似性对相应的短语进行对齐。然后,我们为对齐的短语预测NLI标签(即Entailment, Contradiction, 和Neutral)。最后,我们建议以模糊逻辑的方式从短语标签中诱导出句子级别的标签(Zadeh, 1988; 1996)。
根据这段话,关键信息有:
1、研究单位是短语。
2、短语是soft matching
3、从短语之间的NLI过渡到句子之间的NLI,使用了逻辑规则。
模型结构
phrase detection and alignment, phrasal NLI prediction, and sentence label induction
短语块获取:在短语块获取上,是通过设计了语法规则做的捕捉,比如“[AUX] + [NOT] + VERB + [RP]” is treated as a verb phrase
短语块语义表示:对句子做embedding,然后将短语块中的所有token做mean-pool操作,作为短语块语义的global表示,对短语块做embedding,得到的表示作为短语块的local 表示。
soft matching:
phrase NLI prediction:在对短语块的蕴含关系进行推断时,考虑了中立。矛盾。蕴含。
使用的是MLP网络。
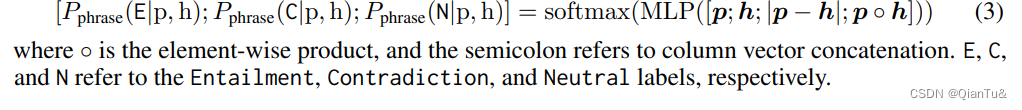
sentence label induction:
- 蕴含关系推断规则:
根据Bowman等人(2015)的观点,一个前提包含一个假设意味着,如果前提是真的,那么假设也一定是真的。我们发现,这往往可以转化为短语关系:如果所有配对的短语都有Entailment的标签,那么前提就会包含假设。
2. 矛盾规则。
如果存在(至少)一个标记为Contradiction的配对短语,那么两个句子就是矛盾的。
- 中性规则。
如果存在(至少)一个中性短语对,但不存在任何矛盾的短语对,那么两个句子就是中性的。
训练与推理:交叉熵损失函数
ASK ME ANYTHING: A SIMPLE STRATEGY FOR PROMPTING LANGUAGE MODELS
这一篇是关于提示工程的。
行文布局思路是发现的基础上,提出新的解决方案,对比性能。
研究出发点:提示不追求完美的情况下,能不能得到好的结果?
为了减轻提示所涉及的高度努力,我们反过来问,收集多个有效但不完美的提示,并将它们聚合起来,是否能导致高质量的提示策略。我们的观察促使我们提出了提示方法,即 "问我任何事 "提示法(AMA)。
新的发现:open question更有效
我们首先发展了对有效提示格式的理解,发现鼓励开放式生成的问题回答(QA)提示(“谁去了公园?”)往往优于那些限制模型输出的提示(“约翰去了公园。 输出真或假”)。我们的方法递归地使用LLM来将任务输入转化为有效的QA格式。我们应用这些提示,为输入的真实标签收集几个噪音投票。我们发现,这些提示可能有非常不同的准确性和复杂的依赖性,因此建议使用弱监督,即结合嘈杂的预测的程序,来产生最终的预测。
性能对比,证实方法有效
我们对AMA进行了跨开源模型系列(EleutherAI、BLOOM、OPT和T0)和规模(125M-175B参数)的评估,证明了比几张照片基线平均提升10.2%的性能。这个简单的策略使开源的GPT-J-6B模型在20个流行的基准中的15个上匹配并超过了少数几个GPT3-175B的性能。

方法的核心思路:Given a task input, each prompt produces a vote for the
input’s true label, and these votes are aggregated to produce a final prediction
论文发现的点:
1、open-ended 提示能够指导模型生成具有优势的答案。
在解释为神魔在开放类型的问题上,模型呈现出更好的结果时,是通过调研LLM的训练语料来说明这个问题的,发现开放式问题在语料中占比重高。
2、使用prompt chain的方式,指导LLM生成open ended 问题,并回答这个问题。
3、我们发现,不同链的预测所产生的误差会有很大的变化和关联性。虽然多数票(MV)在某些提示集上可能做得很好,但在上述情况下它的表现很差。AMA通过识别提示之间的依赖关系并使用WS来说明这些情况,WS是一种在没有任何标记数据的情况下对噪声预测进行建模和组合的程序[Ratner等人,2017,Varma等人,2019]。在这项工作中,我们首次将WS广泛地应用于提示,表明它提高了使用现成的LLM和没有进一步训练的提示的可靠性。 我们发现AMA比MV最多能实现8.7分的提升,在9个任务上,它能恢复提示之间的依赖关系,使性能最多提升9.6分。
AMA是最终结果的一种选择方式,不是使用的major voting 的方式
所以,AMA更像是论文的创新点?一种新的prompt的集成方式?
AMA这种prompt集成的方式提出的出发点,是直观的认为,当从不同的角度提出问题时,可能会得到答案相互补充的方面:
different questions (with our running example: “Who went to the park?”, “Did John go the park?”, “Where did John go?”) emphasize different aspects of the input and can provide complementary information towards reasoning about the answer
AMA constructs different prompt()-chains where each unique prompt()-chain is adifferent view of the task and can emphasize different aspects of x
在PrG,θ(y, P(x))上学习一个概率图形模型,并将聚合器定义为φWS(x) = arg maxy∈Y PrG,θ(y| P(x))。G=(V,E)是一个依赖图,其中V={y,P(x)},E是一个边集,其中(pi(x),pj(x))∈E iff pi(x)和pj(x)是有条件独立的,给定y;θ是P(x)的精度参数。由于我们缺乏标记的数据y,我们不能直接从D中估计G或θ,所以我们的程序如下

所以,这篇文章的创新点,是在对LLM擅长和不擅长的prompt分析的前提,设计了prompt-chain的方案,在对于prompt结果集成上,是使用了概率图。
Humanly Certifying Superhuman Classifiers
这篇文章是验证human 标注的结果是否可信这这一角度出发的。
人类注释经常被当作基础真理,这隐含地假定人类比任何根据人类注释训练的模型更有优势。在现实中,人类注释者可能会犯错误,而且是主观的。
focuses on paving a way towards evaluating models with potentially superhuman performance in classification
the accuracy of the predicted labels with regard to ground truth labels, which we call the oracle accuracy
在定义分类任务的准确率上,将平均标注者的平均 Oracle accuracy作为上界。将model 的准确率作为下界。
至于为什么选择这两个作为上下界,后续做了证明。
HUMAN-GUIDED FAIR CLASSIFICATION FOR NATURAL LANGUAGE PROCESSING
这篇文章是使用GPT3实现类似语料文本的生成。然后应该是提出了一种新的模型来分辨语句是否公平。
目前的方法是基于硬编码的单词替换,导致规范的表达能力有限,或者不能与人类的直觉完全一致(例如,在不对称的反事实情况下)。这项工作提出了新的方法,通过发现富有表现力和直观的个人公平规范来弥补这一差距。我们展示了如何利用无监督的风格转移和GPT-3的零点拍摄能力来自动生成具有表达力的语义相似的候选句子对,这些句子在敏感属性上有所不同。然后,我们通过一项广泛的众包研究来验证所生成的句子对,这证实了这些句子对在毒性分类的背景下与人类对公平性的直觉一致。最后,我们展示了如何利用有限的人类反馈来学习一个相似性规范,该规范可用于训练下游的公平意识模型。
模型的框架
原来在创建这类语料的时候,是通过Word replace这类比较简单的方式,这篇文章是通过GPT来完成这项工作的,之后通过人类来检验是不是符合标准。
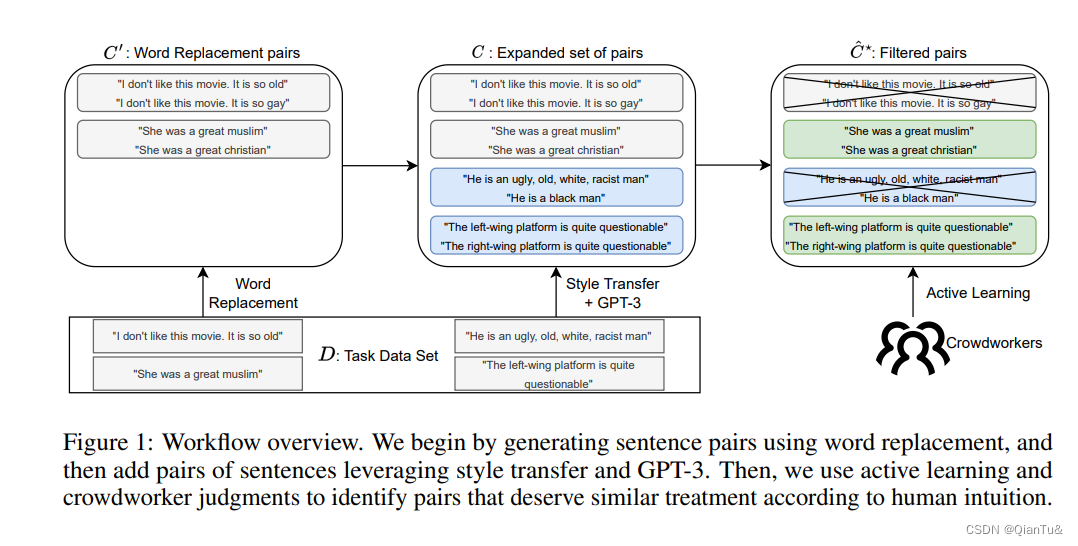
从一个train corpus开始
(可以使用GPT)通过取代现代无监督风格转移方法所使用的风格分类器,在句子s∈D中加入人口群体的标记,例如 “妇女”、"黑人 "或 “基督徒”。
贡献上:1、数据集的提出 2、classifier的训练 3、相似 ,大概意思是这种方式创新出的数据集更符合人类的直觉。
OPTIMIZING BI-ENCODER FOR NAMED ENTITY RECOGNITION VIA CONTRASTIVE LEARNING
实体识别任务的新方法,使用的相似度作为的判断。
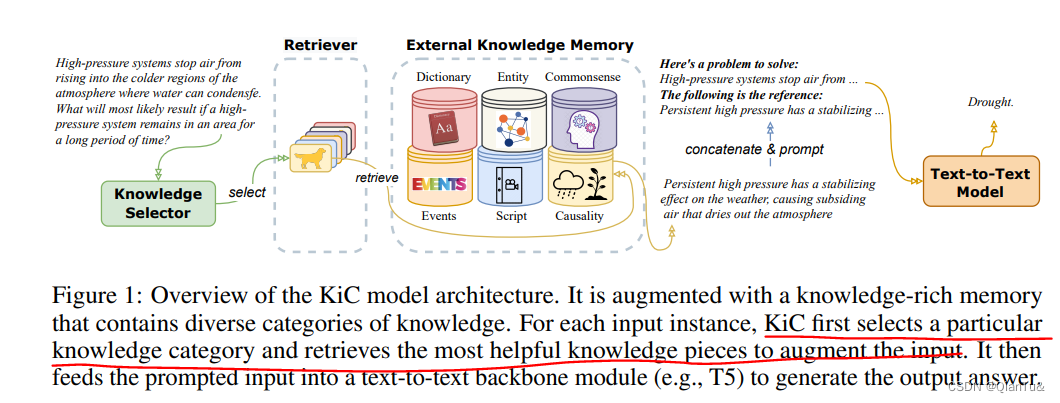
KNOWLEDGE-IN-CONTEXT: TOWARDS KNOWLEDGEABLE SEMI-PARAMETRIC LANGUAGE MODE
没有训练新的模型,是有一个外部知识存储库,从存储库中检索和instance最相关的信息,加入到prompt中,构成新的prompt,然后输入给model产生对应的输出。
知识库中六种知识形式:entity, dictionary, commonsense, event, script, and causality knowledge
instance-adaptive (context-dependent) knowledge augmentation is critical to the success of KiC model。
我觉得这个是最吸睛,就是从外部知识库中选择对当前文本最有用的知识作为增强知识。
有用和无用的评价上,是通过将原文本和知识文本构成key-value pair,然后通过sentence encoder,在计算maximum inner product search (MIPS)确定的。