关于棋类相关的项目在我之前的博文里面都有做过,如下:
《yolov5s融合SPD-Conv用于提升小目标和低分辨率图像检测性能实践五子棋检测识别》
《YOLOV5融合SE注意力机制和SwinTransformer模块开发实践的中国象棋检测识别分析系统》
《基于yolov5s实践国际象棋目标检测模型开发》
细心的话可以看到我其实之前就已经做过了中国象棋检测的项目了,但是由于之前的数据集是我基于数据仿真生成的显得跟实际差距很大,所以最近重新找时间基于真实的数据集重构了一版模型,这里的数据来源于网络视频或者游戏网站录屏手工标注所得,说实在的标注中国象棋这种种类繁多且相对较为密集的数据集来说真的是挺痛苦的。。。
闲话就说到这里,接下来看下效果:

好在是实际做出来后效果很好,算是一种慰藉吧。
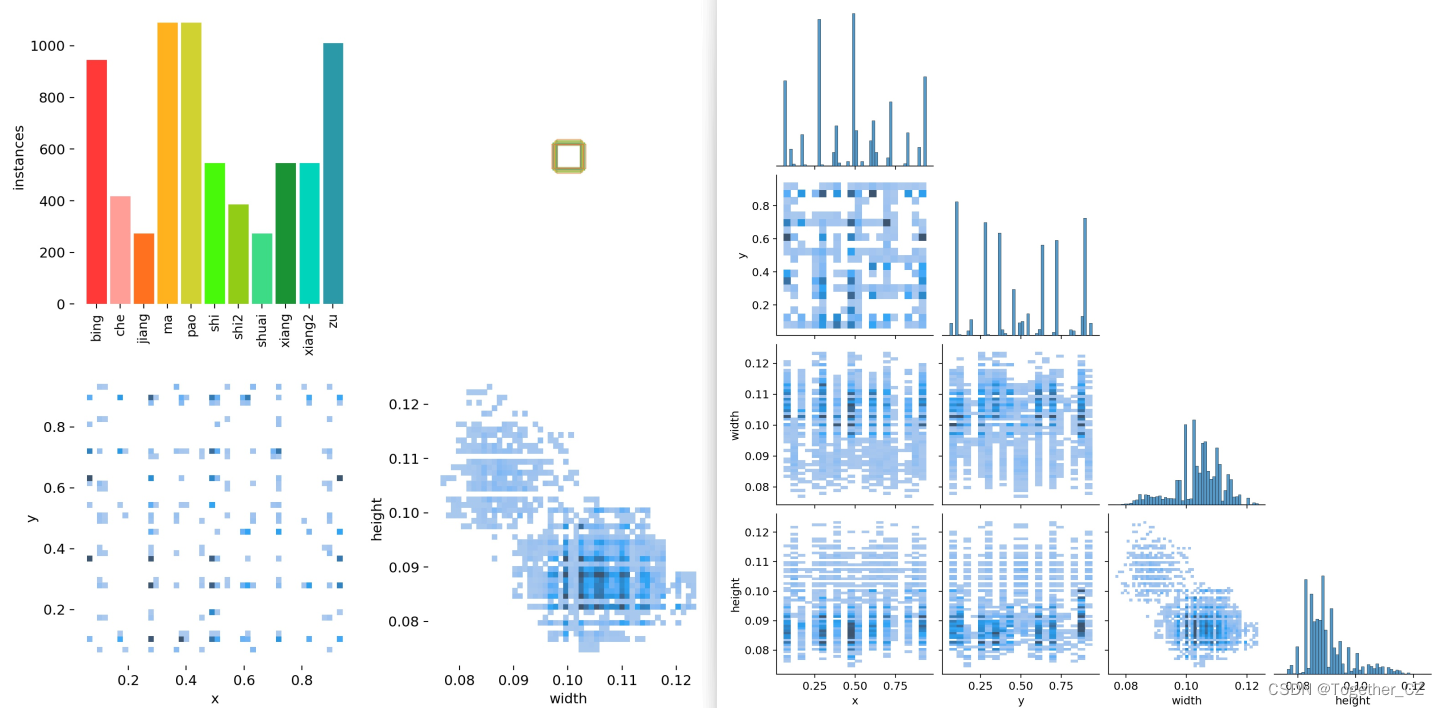
接下来看下数据集:

YOLO格式数据标注文件如下:
实例标注内容如下:
1 0.170139 0.104206 0.097222 0.083178
1 0.933449 0.102336 0.114583 0.086916
8 0.27662 0.102804 0.101852 0.084112
8 0.714699 0.105607 0.116898 0.091589
5 0.387731 0.102336 0.099537 0.086916
5 0.603588 0.101402 0.107639 0.094393
7 0.501157 0.106075 0.097222 0.092523
3 0.280671 0.277103 0.112269 0.079439
3 0.929398 0.276168 0.106481 0.090654
3 0.173611 0.890187 0.113426 0.1
3 0.819444 0.88972 0.101852 0.097196
0 0.064815 0.37243 0.104167 0.096262
0 0.280093 0.365421 0.113426 0.085981
0 0.496528 0.366355 0.108796 0.082243
0 0.929977 0.369626 0.109954 0.088785
4 0.820023 0.281776 0.107639 0.086916
4 0.5 0.277103 0.106481 0.086916
4 0.715278 0.715421 0.099537 0.090654
4 0.174769 0.718692 0.111111 0.084112
10 0.060764 0.628037 0.103009 0.08972
10 0.282407 0.626168 0.111111 0.085981
10 0.49537 0.631776 0.106481 0.08785
10 0.929398 0.628505 0.106481 0.094393
10 0.71412 0.450467 0.094907 0.08972
9 0.497685 0.720093 0.113426 0.096262
9 0.282986 0.892991 0.100694 0.092523
6 0.38831 0.891589 0.091435 0.08972
6 0.609375 0.890187 0.103009 0.086916
2 0.497106 0.894393 0.103009 0.091589VOC格式数据标注文件如下:
考虑到种类比较多,这里轻量级模型没有直接使用n系列的模型,而是使用了s系列的模型,如下:
#Parameters
nc: 11 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
#Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
#Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
默认是100次的迭代计算,日志输出如下:
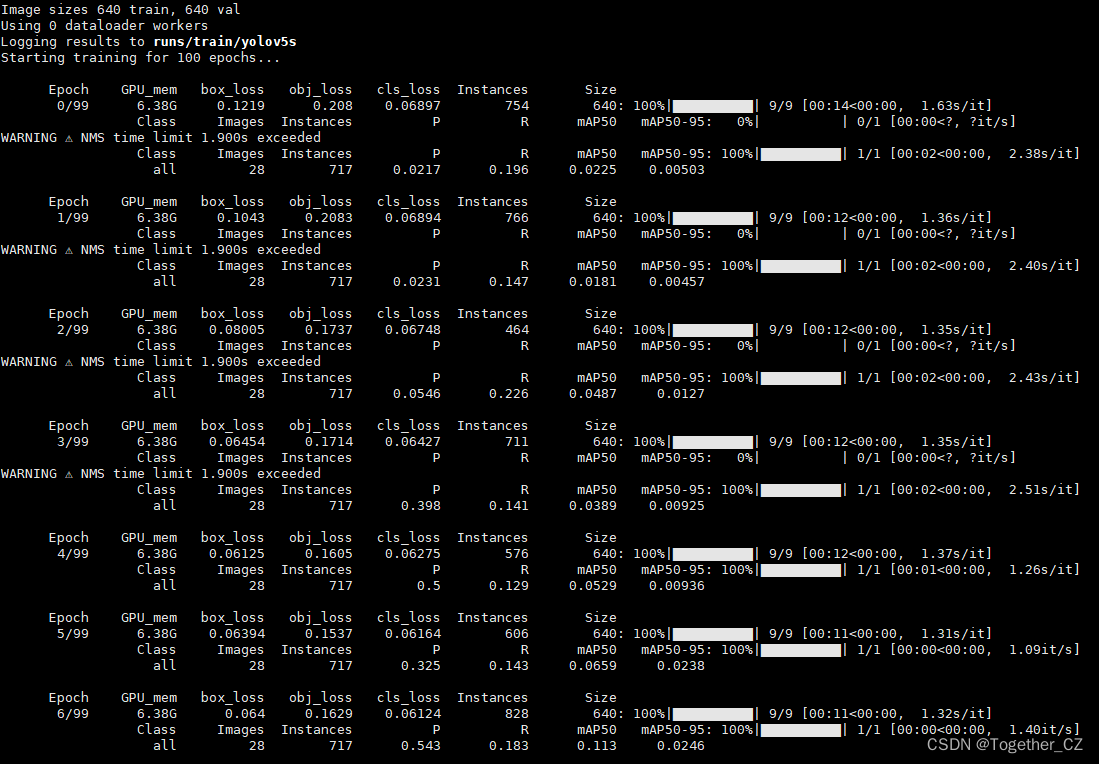
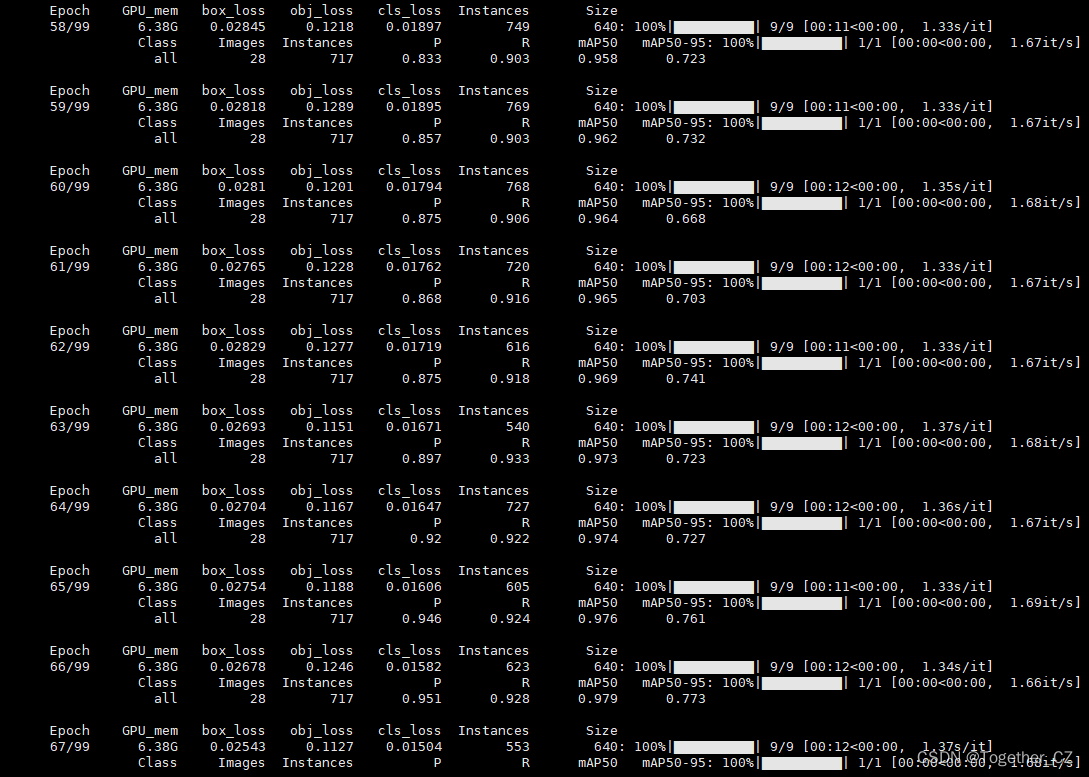

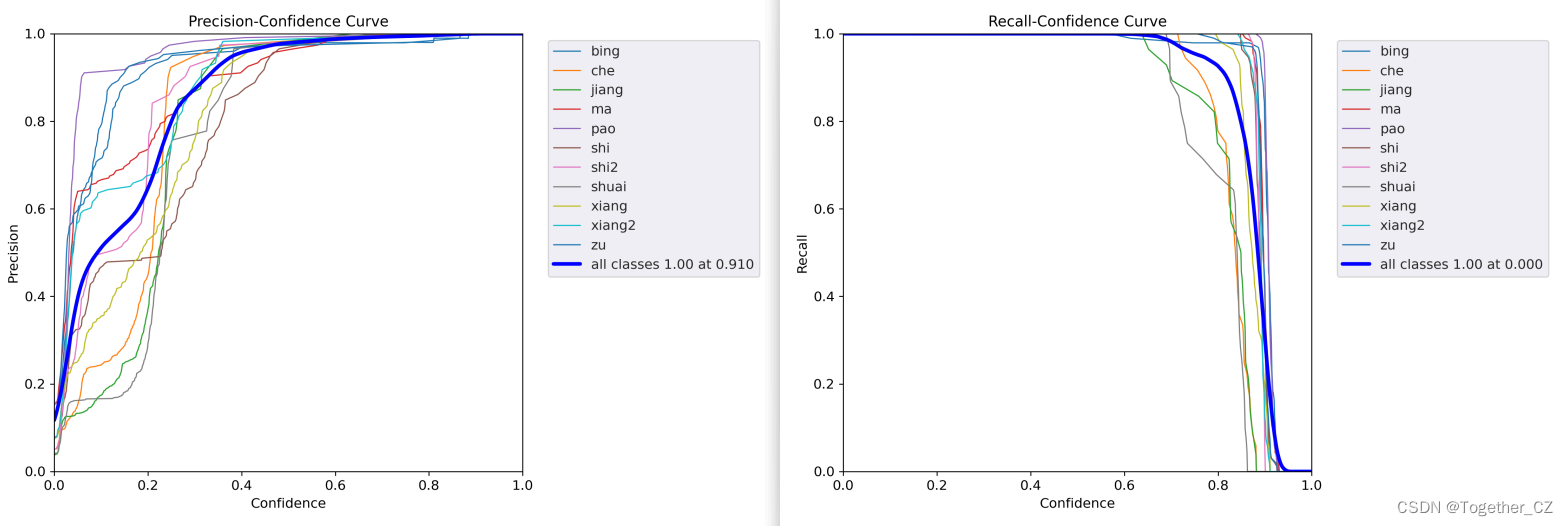
从评估结果上面来看检测识别的效果还是很好的。
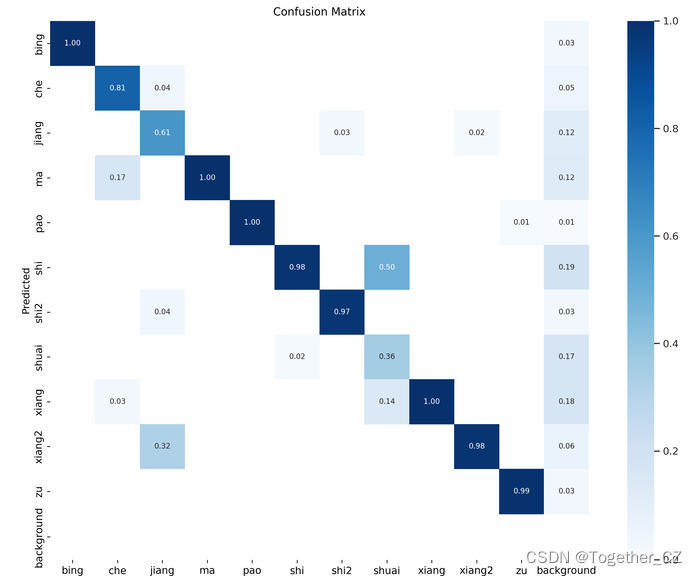
【混淆矩阵】
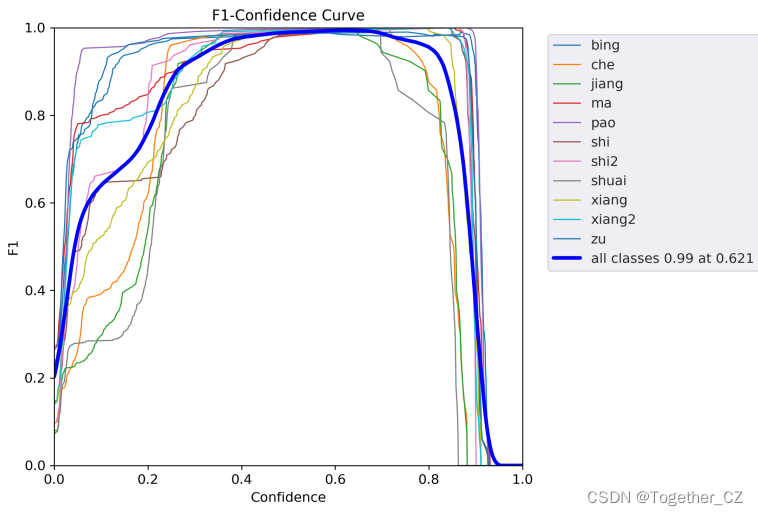
【F1值曲线】
【PR曲线】
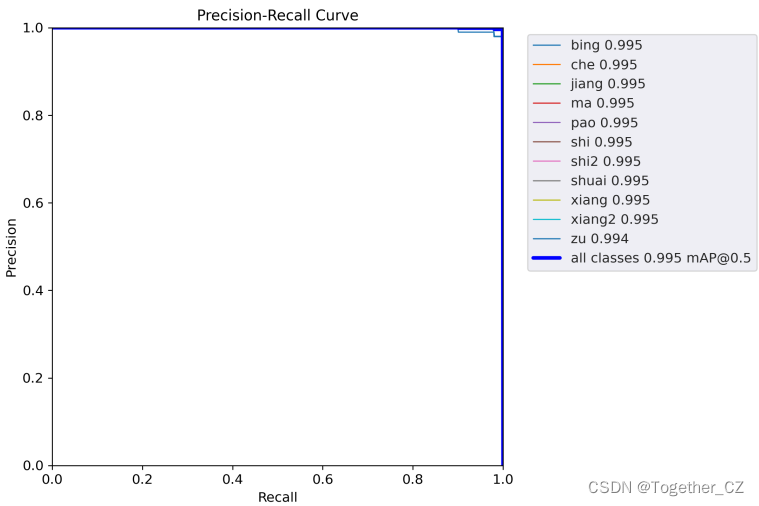
【精确率-召回率曲线】
【数据可视化】