Introduction 简介
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink可以运行在常见集群环境如YARN Kubernetes Mesos,内存级别的速度和任意的扩展
Unbounded streams 无界数据流
无界数据流有开始但是没有结束,需要持续不断的处理.处理无界数据通常需要一个特定的顺序,如事件的发生顺序,来判断数据处理的完整性
Bounded streams 有界数据流
有界数据流是开始也有结束的,有界数据可以计算处理之前获取到所有的输入数据.有界数据流中在数据集合总是会被排序,所以数据输入有序的并不是必须的.有界数据流的处理也可以称为批处理.
Deploy Applications Anywhere 可部署到任意地方
Flink是分布式系统,需要资源来进行执行计算任务.Flink集成了常见的集群资源管理平台如 Hadoop YARN Kubernetes也可以运行使用flink自带的stand-alone集群模式
Run Applications at any Scale 可任意扩展伸缩
Flink被设计为成实现任意规模的集群运行有状态数据流应用.应用可以被拆分上千的任务被分发到不同的节点上并行执行.应用也可以限制CPU 主存 磁盘网络IO.Flink可以很容易维护大型应用的状态.通过异步增量的checkpoint算法保证尽可能小的延迟并且保证exactly-once状态一致性.
Leverage In-Memory Performance 利用内存性能
有状态Flink程序基于本地的状态进行优化.任务状态总是在内存维护,如果状态超过了内存限制,会以高效的数据结构存储在磁盘中.因此,任务通过访问本地(通常在内存中)状态进行计算的延迟非常小.Flink利用了定期异步的checkpoint机制持久化本地状态,从而保证了exactly-once(精准一次性)状态一致性
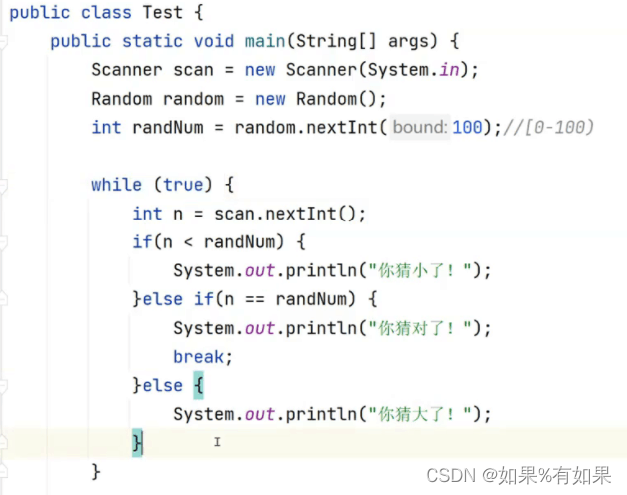
Flink Runtime Framework 运行时架构
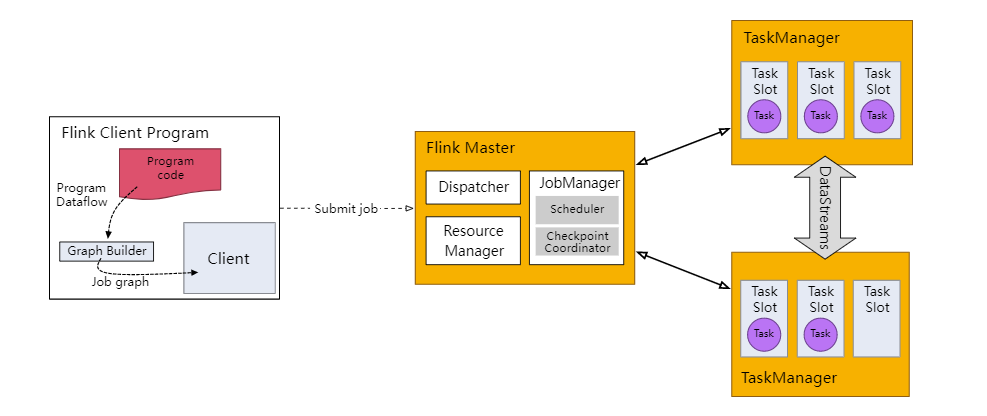
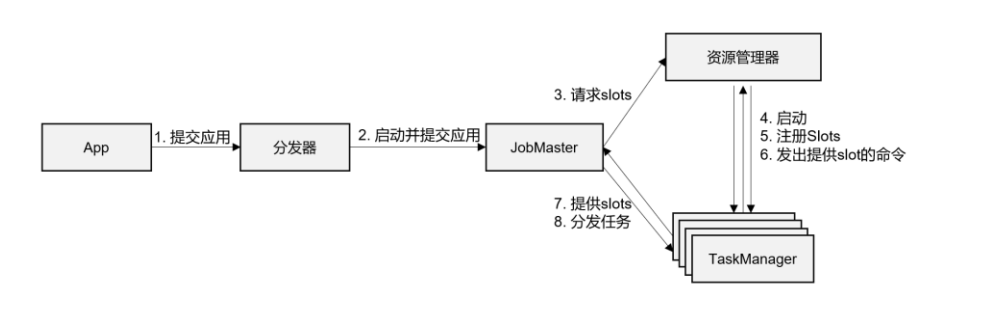
- 客户端通过分发器Dispatcher上传jar包
- 分发器Dispatcher启动JobMaster并提交作业图Job Graph
- JobMaster解析作业图Job Graph成执行图Execution Graph,解析出所需的资源数量和slot像集群的资源管理器ResourceManger发起申请
- ResourceManager查看集群是否有足够资源,尝试启动新的TaskManager
- TaskManager启动之后会向集群中的ResourceManager注册Slot相关的资源信息
- ResourceManager向TaskManager通知提供slot资源命令
- TaskManager向JobMaster提供slot资源
- JobMaster向TaskManager分发Task任务
- TaskManager进行任务的执行其中可能会存在数据的交互
- 不同的资源管理平台执行流程略有差异其中一些步骤可能会省略,常见的资源管理平台比如Yarn K8S或者不同的集群环境略有不同
Job Manager
The JobManager is the orchestrator of a Flink Cluster. It contains three distinct components: Flink Resource Manager, Flink Dispatcher and one Flink JobMaster per running Flink Job.
JobManager作业管理器是Flink集群的核心组件充当协调者的角色.主要包括三大模块:
- Flink ResourceManger 资源管理器 负责与TaskManager资源管理slot分配等
- Flink Dispatcher 分发器 用于任务提交,UI界面 可省略
- Flink JobMaster 任务管理器 每一个任务用独有一个JobMaster 用于将客户端提交的逻辑图转成执行图
Task Manager
TaskManagers are the worker processes of a Flink Cluster. Tasks are scheduled to TaskManagers for execution. They communicate with each other to exchange data between subsequent Tasks.
Task Manager 任务管理器是Flink集群中负责程序执行的work. 任务会被TaskManager负责调度执行.不同的SubTask子任务之间可以进行数据交互
Task 与 SubTask
Task
是一个实际执行的物理图.一个task是一个flink运行时work的最基本的单元. Task封装了一个并行的Operator算子或者一个Operator Chain算子链
SubTask
A Sub-Task is a Task responsible for processing a partition of the data stream. The term “Sub-Task” emphasizes that there are multiple parallel Tasks for the same Operator or Operator Chain.
SubTask子任务是负责处理一部分数据流任务.Sub-Task强调的是并行执行相同的Operator或者Operator Chain
Graph
Flink 中的执行图可以分成四层:StreamGraph ->JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
parallelism
parallelism并行度 把一个算子操作,“复制”多份到多个节点, 数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的 “子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算.
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并 行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。 一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中, 不同的算子可能具有不同的并行度。
设置并行度的四种方式
- 在代码中的Operator中调用setParallelism(int) 方法设置
- 在代码中执行环境env中调用setParallelism 方法
- 在通过flink提交任务加入 -p 参数指定并行度 或 WEB-UI中显示指定的并行度
- 在flink配置文件中指定的默认并行度parallelism.default: 1
- 优先级从上到下 建议采用在代码中特定的Operator显式调用setParallelism方法
slot
在执行任务的时候,不是每一个任务都需要启动一个TaskManager,可以让TaskManager进行多线程执行任务.但是TM的资源是有限的,并行的任务越多每个并行的任务分配的资源就会更少.为了控制并发量需要在TM中每个任务运行时占用资源进行划分,此时就出现了Task Slot的概念.可以通过参数taskmanager.numberOfTaskSlots
每一个Slot 表示在TM上一个固定大小的计算资源,用来处理独立的子任务,如TM的slot为3,TM会将资源平均分配成3份,每个slot独占一份,不需要跟其他的作业进行竞争内存资源.
Slot仅仅用来隔离内存,不会涉及CPU级别的隔离.具体应用的时候可以将slot数量设置为CPU核数尽量避免不同slot之间的CPU竞争.默认并行度为CPU核数
Slot共享
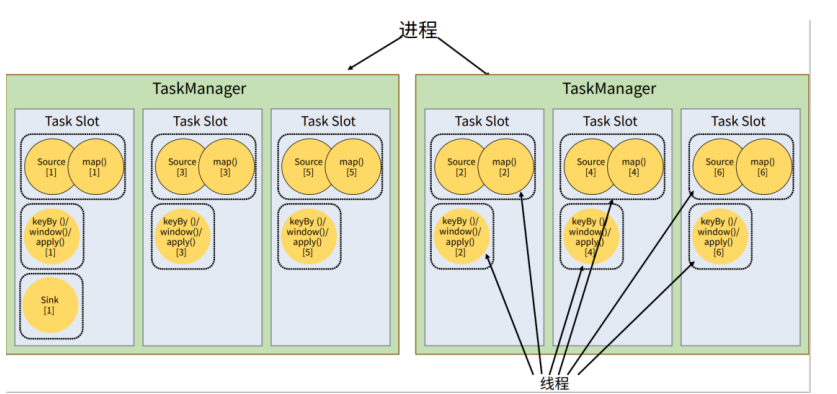
默认情况下,Flink 是允许子任务共享 slot 的。如图所示, 只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个 slot 上执行。 所以对于第一个任务节点 source→map,它的 6 个并行子任务必须分到不同的 slot 上(如果在 同一 slot 就没法数据并行了),而第二个任务节点 keyBy/window/apply 的并行子任务却可以和 第一个任务节点共享 slot。
Slot的共享有一个好处在于,不同的任务可能耗时不一样,如果每一个任务独占一个slot,可能某一个任务只是简单的接受数据,而另一个任务是对数据的加工处理,此时单纯接收数据的任务会浪费slot中的资源,也会导致下游任务的积压.忙的忙死,闲的闲死.此时利用了slot共享的机制可以避免资源的浪费.slot 共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个 TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
Slot 与 parallelism的关系
task slot是静态的概念 ,是指TaskManager具有的并发执行能力 ,可以通过参数taskmanager.numberOfTaskSlots 进行配置;而并行度(parallelism)是动态概念,也就是TaskManager 运行程序时实际使用的并发能力,可以通过参数 parallelism.default 进行配置。并行度如果小于等于集群中可用 slot 的总数,程序是可以正常执行的,因为 slot 不一 定要全部占用,有十分力气可以只用八分;而如果并行度大于可用 slot 总数并且根据Operator合并和slot共用分析之后,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
Operator 与 Operator Chain
Operator
Node of a Logical Graph. An Operator performs a certain operation, which is usually executed by a Function. Sources and Sinks are special Operators for data ingestion and data egress.
一个逻辑图节点.一个Operator算子代表一个具体的操作,通常被Function执行.Sources 和 Sink 是一种特殊的Operator主要数据的收集和输出.Operator算子在Flink中存在代码的实现,如XXXOperator.在编写Flink代码的时候会接触到各种各样的Operator
Operator Chain
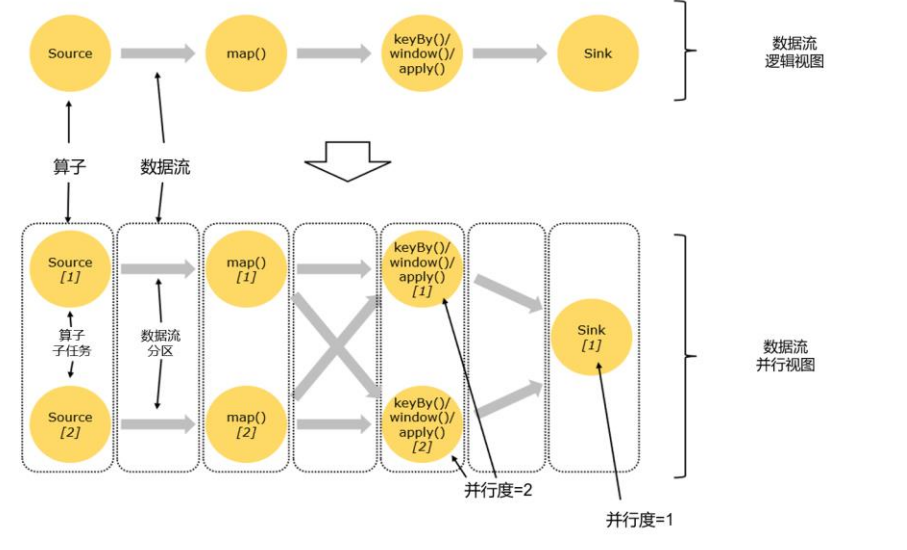
An Operator Chain consists of two or more consecutive Operators without any repartitioning in between. Operators within the same Operator Chain forward records to each other directly without going through serialization or Flink’s network stack.
Operator Chain包含了两个以上的Operator.相同名称的Operator Chain通过直连forward数据传递的方式在同一个节点直接进行计算,不需要通过进行Flink之间的网络传输.
合并Operator称为一个Operator Chain 有两个必要的条件
- Operator 并行度必须一直 不能出现reblance
- one-to-one 操作的Operator数据流维护数据的顺序与分区,上游算子的操作可以直接流入下游算子
- 比如source 与 map 算子在source算子接受到数据之后可以直接传递给map算子进行操作
- 如果输入的Socket Source Operator的并行度只能是1,下一个map的算子如果并行度不是1会导致reblance就不能合并成一个Operator Chain
- keyBy/Windows算子与Sink算子之间因为keyBy会产生重分区Redistribution,当并行度发生改变时,传输方式可能会出现再平衡reblance此时就不能合并成一个Operator Chain