RDD Cache
当同一个 RDD 被引用多次时,就可以考虑进行 Cache,从而提升作业的执行效率
// 用 cache 对 wordCounts 加缓存
wordCounts.cache
// cache 后要用 action 才能触发 RDD 内存物化
wordCounts.count
// 自定义 Cache 的存储介质、存储形式、副本数量
wordCounts.persist(MEMORY_ONLY)
Spark 的 Cache 机制 :
- 缓存的存储级别:限定了数据缓存的存储介质,如 : 内存、磁盘
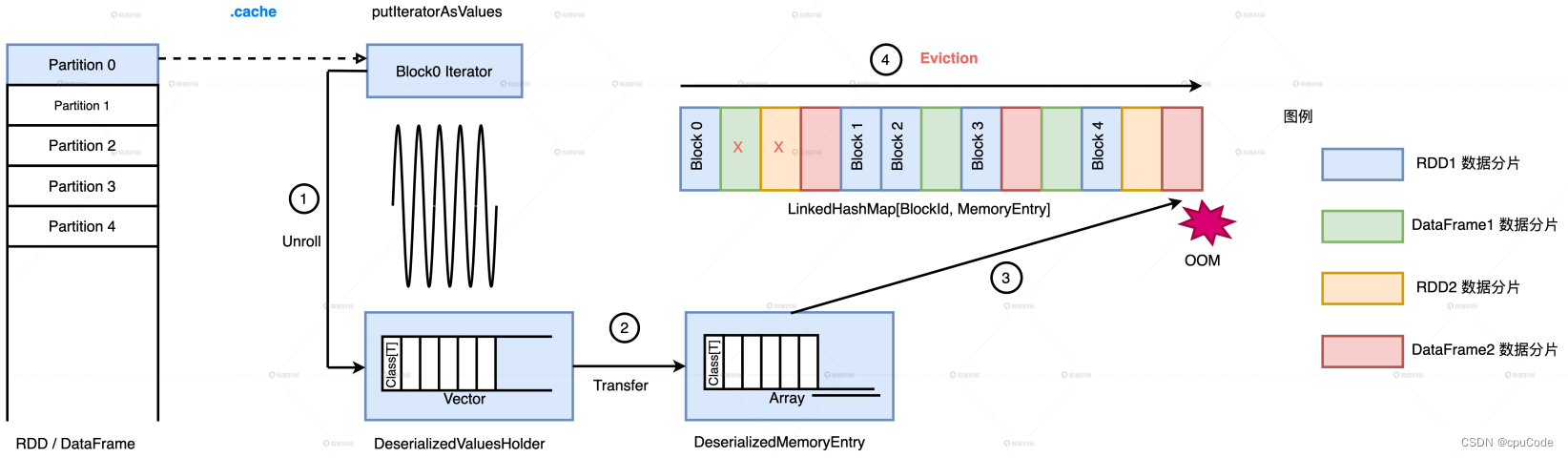
- 缓存的计算过程:从 RDD 展开到分片 (Block),存储于内存或磁盘的过程
- 缓存的销毁过程:缓存数据主动或被动删除的内存或磁盘的过程
存储级别
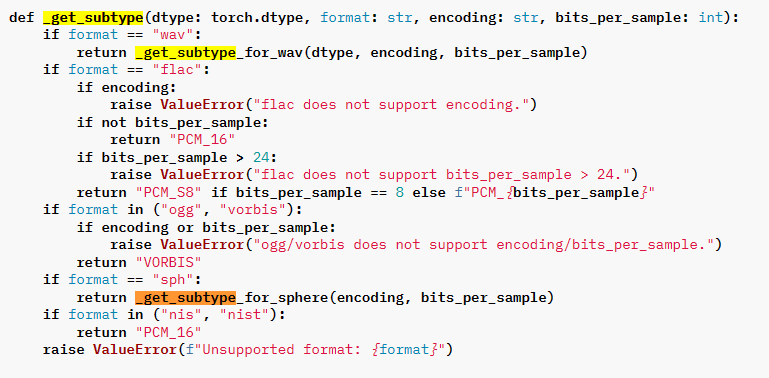
Spark 支持的存储级别:
- RDD 缓存的默认存储级别:MEMORY_ONLY
- DataFrame 缓存的默认存储级别:MEMORY_AND_DISK
| 存储级别 | 存储介质 | 存储形式 | 副本设置 | |||
|---|---|---|---|---|---|---|
| 内存 | 磁盘 | 对象值 | 序列化 | |||
| MEMORY_ONLY | √ | √ | 1 | |||
| MEMORY_ONLY_2 | √ | √ | 2 | |||
| MEMORY_ONLY_SER | √ | √ | 1 | |||
| MEMORY_ONLY_SER_2 | √ | √ | 2 | |||
| DISK_ONLY | √ | √ | 1 | |||
| DISK_ONLY_2 | √ | √ | 2 | |||
| DISK_ONLY_3 | √ | √ | 3 | |||
| MEMORY_AND_DISK | √ | √ | √ | √ | 1 | 内存以对象值存储,磁盘以序列化 |
| MEMORY_AND_DISK_2 | √ | √ | √ | √ | 2 | |
| MEMORY_AND_DISK_SER | √ | √ | √ | 1 | 内存/磁盘都以序列化的字节数组存储 | |
| MEMORY_AND_DISK_SER2 | √ | √ | √ | 2 |
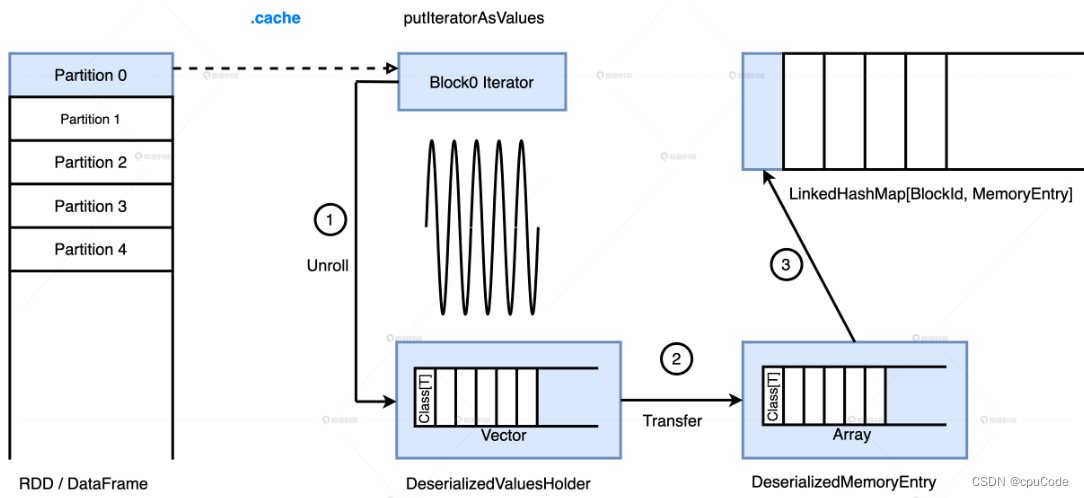
计算过程
缓存的计算过程 :
- MEMORY_AND_DISK :先把数据集全部缓存到内存,内存不足时,才把剩余的数据落磁盘
- MEMORY_ONLY :只把数据往内存里塞
内存中的存储过程 :
销毁过程
缓存的销毁过程 :
- 缓存抢占 Execution Memory 空间,会进行缓存释放
Spark 清除缓存的原则:
- LRU:按元素的访问顺序,优先清除那些最近最少访问的 BlockId、MemoryEntry 键值对
- 在清除时,同属一个 RDD 的 MemoryEntry 不会清除
Spark 实现 LRU 的数据结构:LinkedHashMap , 内部有两个数据结构
- HashMap : 用于快速访问,根据指定的 BlockId,O(1) 返回 MemoryEntry
- 双向链表 : 用于维护元素(BlockId 和 MemoryEntry 键值对)的访问顺序
Spark 会释放 LRU 的 MemoryEntry :
Cache 注意点
用 Cache 的基本原则 :
- 当
RDD/DataFrame/Dataset的引用数为 1,坚决不用 Cache - 当引用数大于 1,且运行成本超过 30%,就考虑用 Cache
运行成本占比 : 计算某个分布式数据集要消耗的总时间与作业执行时间的比值
- 端到端的执行时间为 1 小时
- DataFrame 被引用了 2 次
- 从读取数据源到生成该 DataFrame 花了 12 分钟
- 该 DataFrame 的运行成本占比 =
12*2/60 = 40%
用 noop 计算 DataFrame 运行时间 :
df.write
.format("noop")
.save()
.cache 是惰性操作,在调用 .cache后,要先用 count 才能触发缓存的完全物化
Cache 要遵循最小公共子集原则 :
val filePath: String = _
val df: DataFrame = spark.read.parquet(filePath)
//Cache方式一
val cachedDF = df.cache
//数据分析
cachedDF.filter(col2 > 0).select(col1, col2)
cachedDF.select(col1, col2).filter(col2 > 100)
两个查询的 Analyzed Logical Plan 不一致,无法缓存复用
//Cache方式二
df.select(col1, col2).filter(col2 > 0).cache
//数据分析
df.filter(col2 > 0).select(col1, col2)
df.select(col1, col2).filter(col2 > 100)
Analyzed Logical Plan 完全一致,能缓存复用
//Cache方式三
val cachedDF = df.select(col1, col2).cache
//数据分析
cachedDF.filter(col2 > 0).select(col1, col2)
cachedDF.select(col1, col2).filter(col2 > 100)
及时清理 Cache :
- 异步模式 (常用):调用 unpersist() 或 unpersist(False)
- 同步模式:调用 unpersist(True)
OOM
OOM的具体区域 :
- 发生 OOM 的 LOC(Line Of Code),代码位置
- OOM 发生在 Driver 端,还是在 Executor 端
- 在 Executor 端的哪片内存区域
Driver OOM
Driver 端的 OOM 位置 :
- 创建小规模的分布式数据集:使用 parallelize、createDataFrame 创建数据集
- 收集计算结果:通过 take、show、collect 把结果收集到 Driver 端
Driver 端的 OOM 原因:
- 创建的数据集超过内存上限
- 收集的结果集超过内存上限
广播变量的创建与分发 :
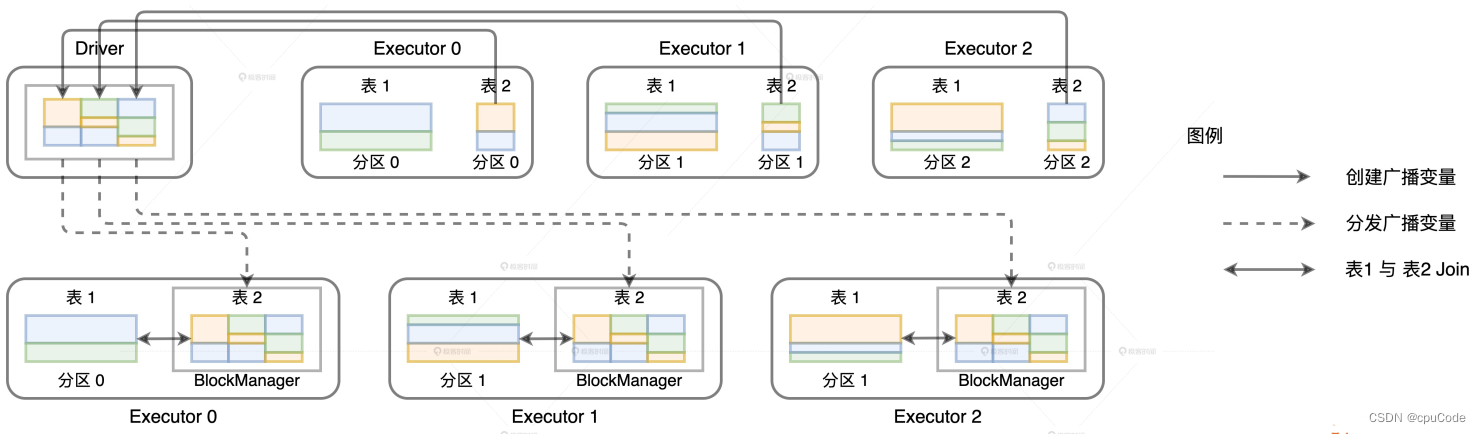
广播变量的数据拉取就是用 collect 。当数据总大小超过 Driver 端内存时 , 就报 OOM :
java.lang.OutOfMemoryError: Not enough memory to build and broadcast
对结果集尺寸预估,适当增加 Driver 内存配置
- Driver 内存大小 :
spark.driver.memory
查看执行计划 :
val df: DataFrame = _
df.cache.count
val plan = df.queryExecution.logical
val estimated: BigInt = spark
.sessionState
.executePlan(plan)
.optimizedPlan
.stats
.sizeInBytes
Executor OOM
当 Executors OOM 时,定位 Execution Memory 和 User Memory
User Memory OOM
User Memory 用于存储用户自定义的数据结构,如: 数组、列表、字典
当自定义数据结构的总大小超出 User Memory 上限时,就会报错
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf
java.lang.OutOfMemoryError: Java heap space at java.lang.reflect.Array.newInstance
计算 User Memory 消耗时,要考虑 Executor 的线程池大小
- 当 dict 大小为
#size, Executor 线程池大小为#threads - dict 对 User Memory 的总消耗:
#size * #threads - 当总消耗超出 User Memory 上限,就会 OOM
val dict = List("spark", "tune")
val words = spark.sparkContext.textFile("~/words.csv")
val keywords = words.filter(word => dict.contains(word))
keywords.map((_, 1)).reduceByKey(_ + _).collect
自定义数据分发 :
- 自定义的列表 dict 会随着 Task 分发到所有 Executors
- 多个 Task 的 dict 会对 User Memory 产生重复消耗
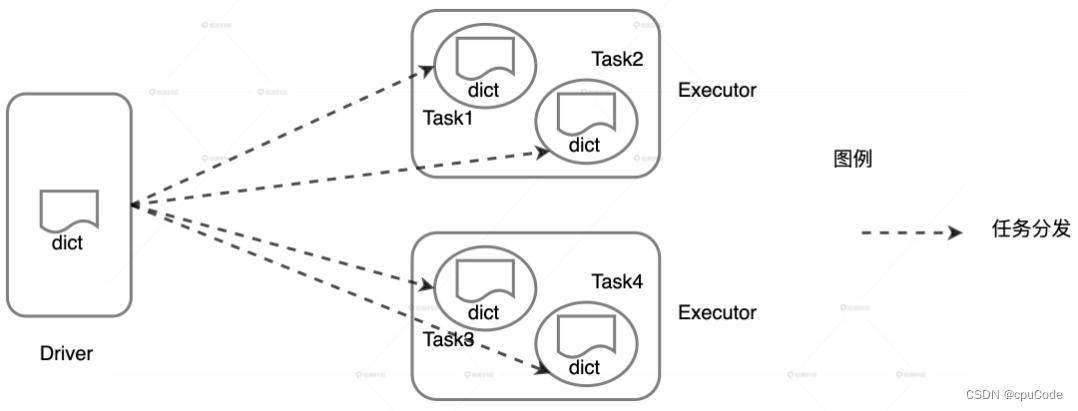
解决 User Memory OOM 的思路 :
- 先对数据结构的消耗进行预估
- 相应地扩大 User Memory
UserMemory 总大小 = spark.executor.memory * (1 - spark.memory.fraction)
Execution Memory OOM
Execution Memory OOM 常见实例:数据倾斜和 数据膨胀
配置说明:
- 2 个 CPU core,每个 core 有两个线程,内存大小为 1GB
- spark.executor.cores = 3,spark.executor.memory = 900MB
- Execution Memory = 180MB
- Storage Memory = 180MB
- Execution Memory 上限 = 360MB
数据倾斜
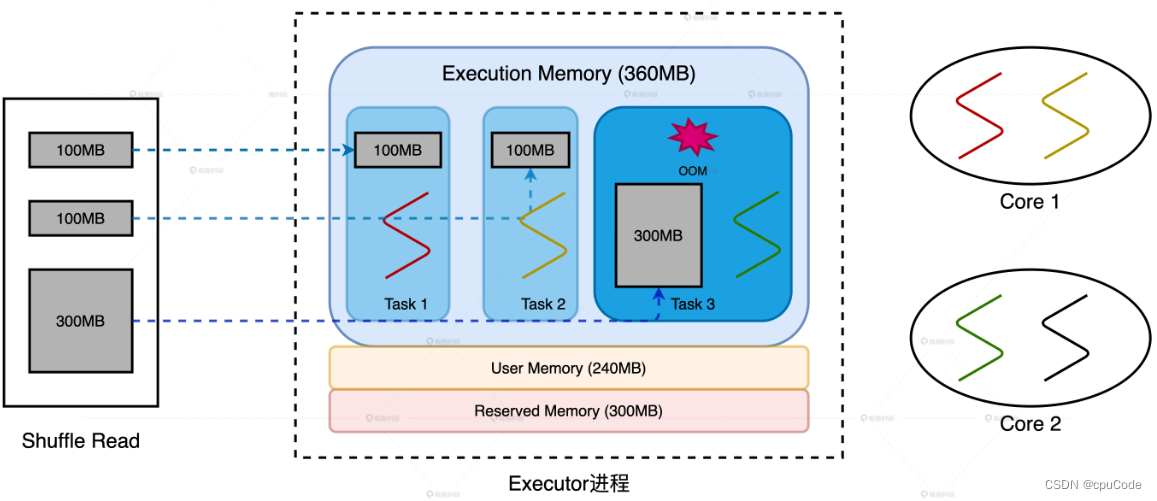
3 个 Reduce Task 对应的数据分片大小分别是 100MB , 100MB , 300MB
- 当 Executor 线程池大小为 3,所以每个 Reduce Task 最多 360MB * 1/3 = 120MB
数据倾斜导致OOM :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NHRj4w40-1677761995168)(…/…/png/%E5%86%85%E5%AD%98%E8%BF%90%E7%94%A8/image-20230209210919876.png)]
2 种调优思路:
- 消除数据倾斜,让所有的数据分片尺寸都小于 100MB
- 调整 Executor 线程池、内存、并行度等相关配置,提高 1/N 上限到 300MB
在 CPU 利用率高下解决 OOM :
- 维持并发度、并行度不变,增大执行内存设置,提高 1/N 上限到 300MB
- 维持并发度、执行内存不变,提升并行度把数据打散,将所有的数据分片尺寸都缩小到 100MB 内
数据膨胀
3 个 Map Task 对应的数据分片大小都是 100MB
数据膨胀导致OOM :
2 种调优思路:
- 把数据打散,提高数据分片数量、降低数据粒度,让膨胀后的数据量降到 100MB 左右
- 加大内存配置,结合 Executor 线程池调整,提高 1/N 上限到 300MB