知识要点
-
estimater 有点没理解透
-
数据集是泰坦尼克号人员幸存数据.
-
读取数据:train_df = pd.read_csv('./data/titanic/train.csv')
-
显示数据特征:train_df.info()
-
显示开头部分数据:train_df.head()
-
提取目标特征:y_train = train_df.pop('survived')
-
显示数据分布:train_df.describe()
-
柱状图显示:train_df.age.hist(bins = 20)
-
横向柱状图: train_df.sex.value_counts().plot(kind = 'barh')
-
pd.concat([train_df, y_train], axis = 1).groupby('sex').survived.mean().plot(kind = 'barh') # 根据幸存率查看各类型的均值
-
提取不同特征的统计: train_df.embark_town.value_counts()
-
提取特征: vocab = train_df[categorical_column].unique()
-
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)) # one_hot 编码
-
dataset批次设置: dataset = dataset.repeat(epochs).batch(batch_size)
1 导包
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2 数据导入
train_df = pd.read_csv('./data/titanic/train.csv')
eval_df = pd.read_csv('./data/titanic/eval.csv') # eval 评估 # 数据
print(train_df.info())
print(eval_df.info())
train_df.head()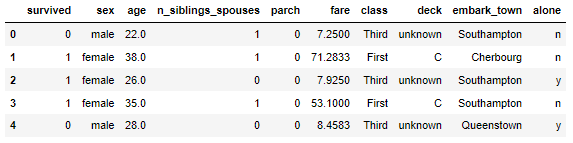
3 目标值获取
y_train = train_df.pop('survived')
y_eval = eval_df.pop('survived')
print(train_df.head())
print(eval_df.head())
print(y_train.head())
print(y_eval.head())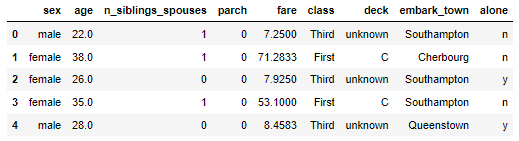
4 特征处理
train_df.describe()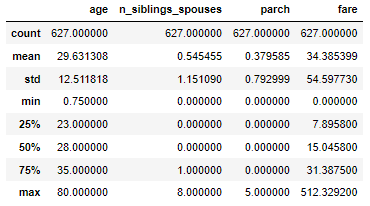
# 观察年龄的数据分布
train_df.age.hist(bins = 20)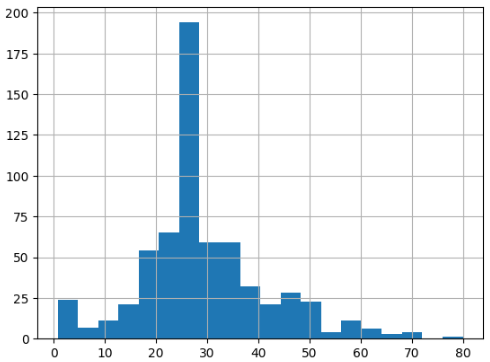
# 观察男女比例, 性别数量对比
train_df.sex.value_counts().plot(kind = 'barh')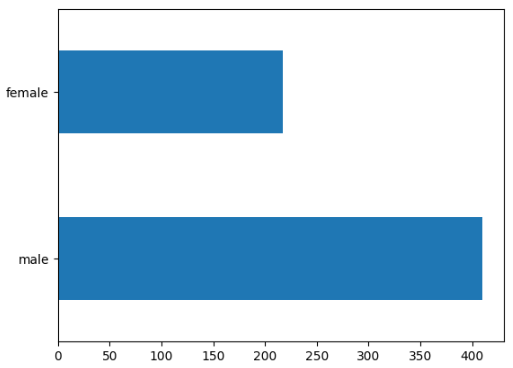
# 仓位对比, 船舱类型
train_df['class'].value_counts().plot(kind = 'barh')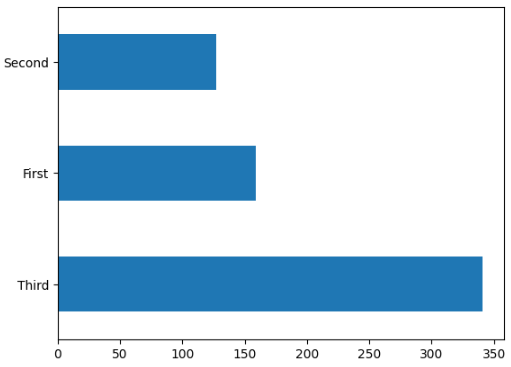
# 看港口人数
train_df['embark_town'].value_counts().plot(kind = 'barh')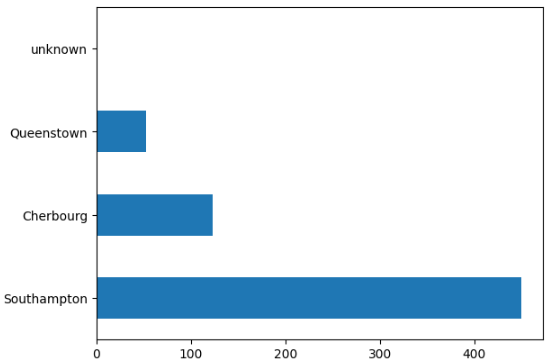
pd.concat([train_df, y_train], axis = 1).groupby('sex').survived.mean().plot(kind = 'barh')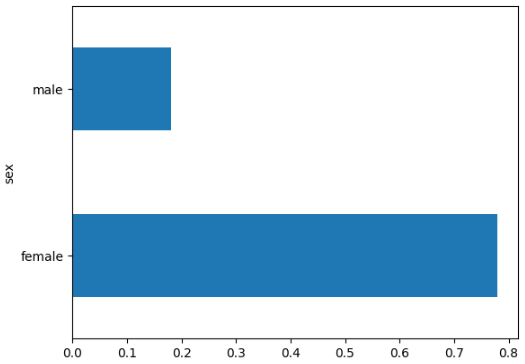
train_df.embark_town.value_counts()
'''Southampton 450
Cherbourg 123
Queenstown 53
unknown 1
Name: embark_town, dtype: int64'''# 区分离散特征和连续特征
categorical_columns = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck', 'embark_town', 'alone'] # 离散特征
numeric_columns = ['age', 'fare']
# 接受特征
feature_columns = []
for categorical_column in categorical_columns:
vocab = train_df[categorical_column].unique() # 取出特征值
print(vocab)
# print(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)) # 创建vocabulary 的API
# 将离散特征转换为one_hot形式的编码
num = tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab))
feature_columns.append(num)
# 数据类型转换
for numeric_column in numeric_columns:
feature_columns.append(tf.feature_column.numeric_column(numeric_column, dtype = tf.float32))5 dataset
# 创建生成dataset的方法
def make_dataset(data_df, label_df, epochs = 10, shuffle = True, batch_size = 32):
dataset = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
dataset = dataset.shuffle(10000) # 打乱, 洗牌
dataset = dataset.repeat(epochs).batch(batch_size)
return dataset
train_dataset = make_dataset(train_df, y_train, batch_size = 5)# baseline_model
import os
output_dir = 'baseline_model'
if not os.path.exists(output_dir):
os.mkdir(output_dir)
baseline_estimator = tf.compat.v1.estimator.BaselineClassifier(model_dir = output_dir, n_classes= 2)
# input_fn要求没有输入参数, 要求返回元组(x, y)或者可以返回(x, y)的dataset
baseline_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs = 100))# baseline 是随机参数, 所以结果很差
baseline_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1,
shuffle = False, batch_size = 20))# linear_model
linear_output_dir = 'linear_model'
if not os.path.exists(linear_output_dir):
os.mkdir(linear_output_dir)
linear_estimator = tf.estimator.LinearClassifier(feature_columns = feature_columns,
model_dir = linear_output_dir)
linear_estimator.train(input_fn = lambda :make_dataset(train_df, y_train, epochs = 100))# baseline 是随机参数, 所以结果很差
linear_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1, shuffle = False,
batch_size = 20))dnn_output_dir = './dnn_model'
if not os.path.exists(dnn_output_dir):
os.mkdir(dnn_output_dir)
dnn_estimator = tf.estimator.DNNClassifier(model_dir = dnn_output_dir, # 存储地址
n_classes= 2, # 二分类
feature_columns = feature_columns,
hidden_units = [128, 128], # 隐藏层
activation_fn = tf.nn.relu, # 算法
optimizer = 'Adam') # 损失函数, 优化:optimizer
# dnn_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs = 100))
dnn_estimator.train(input_fn = lambda :make_dataset(train_df, y_train, epochs = 100))dnn_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1,
shuffle = False, batch_size = 20))