github链接:https://github.com/kaonashi-tyc/Rewrite
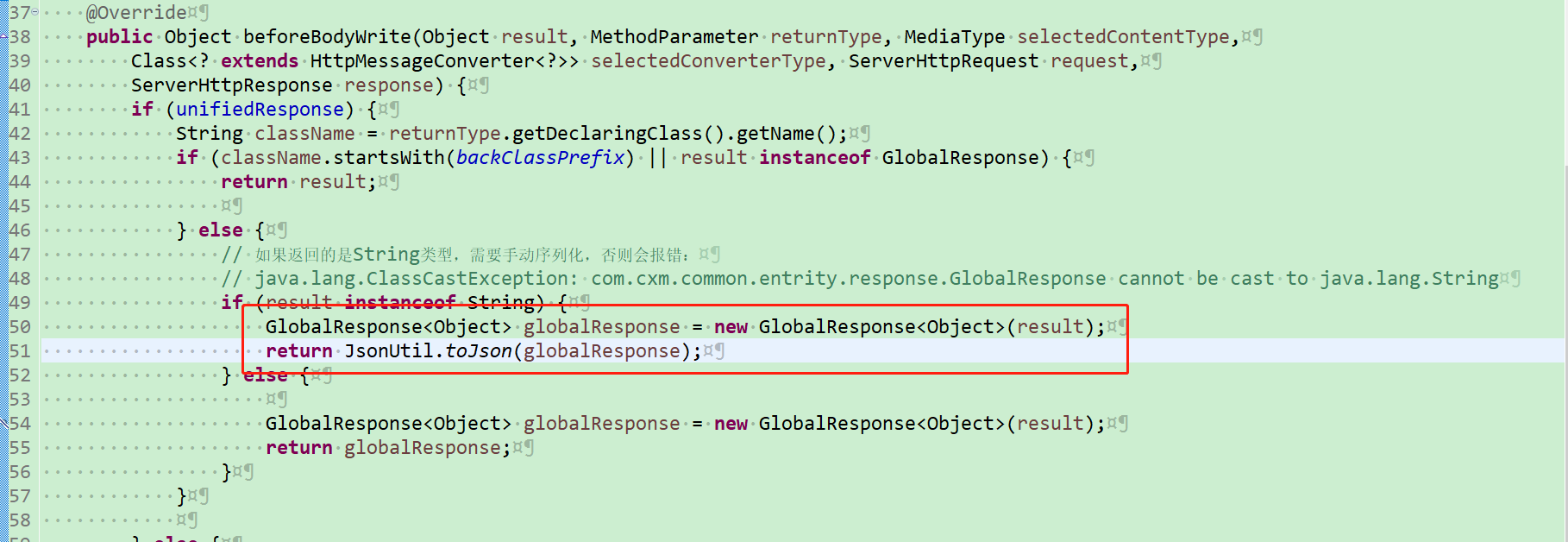
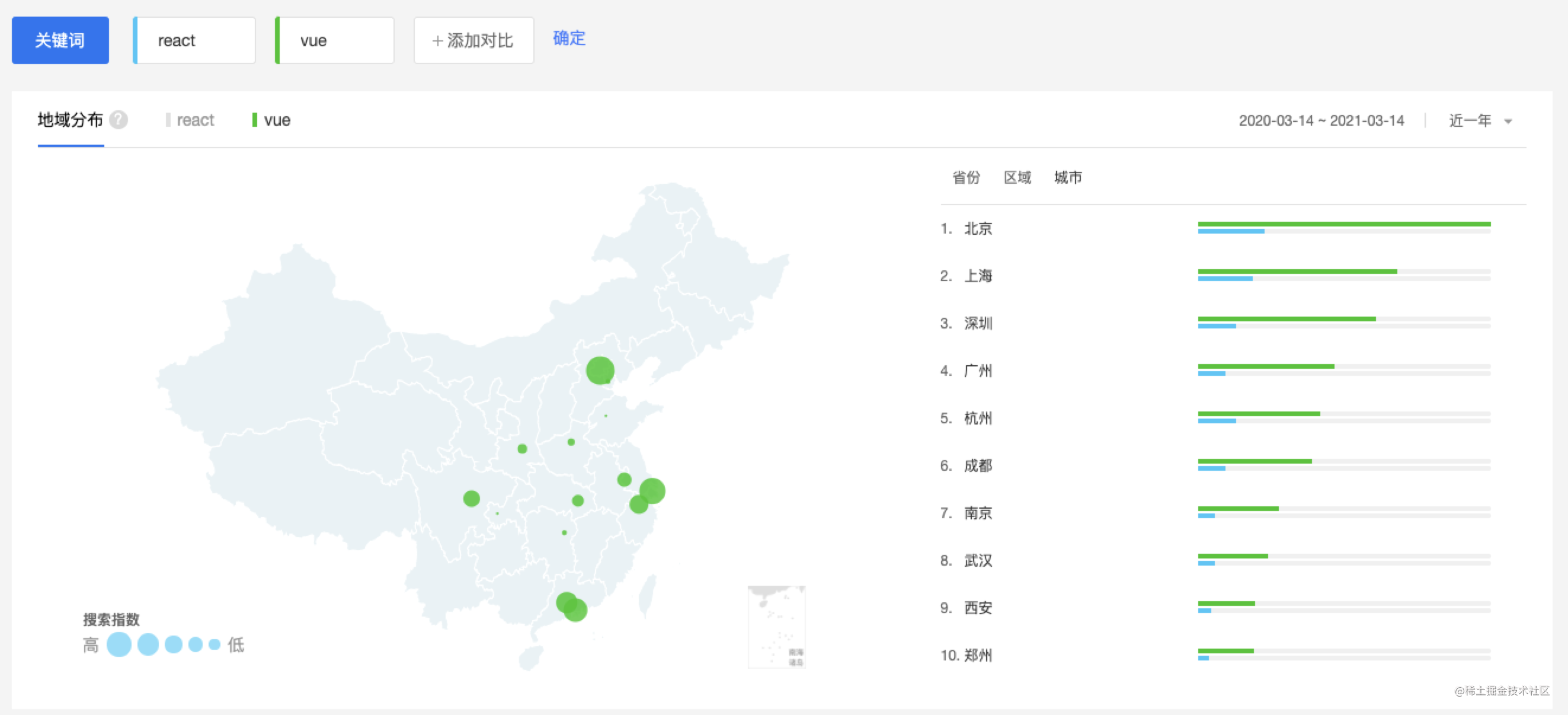
网络的结构框架以及相关参数:

每个卷积层后面是一个批处理归一化层,然后是一个ReLu层,一直到零填充。
正如Erik的博客中提到的,该网络针对预测输出和地面真相之间的像素级MAE(平均绝对误差)最小化,而不是更常用的MSE(均方误差)。MAE往往会产生更清晰、更清晰的图像,而MSE则会产生更模糊和偏灰的图像。同时,利用全变差损失来提高图像的平滑度。
层数n是可配置的,n越大,输出越详细,越干净,但需要更长的训练时间,通常选择在[2,4]之间。大于4的选项似乎达到了收益递减的点,增加了运行时间,但对损失或输出都没有明显的改善。
为了更好的细节,大的卷积。在我的实验中,我开始使用直接堆叠的普通3x3卷积,但它最终表现很差,或者在更困难和奇异的字体上没有收敛。所以我最终得到了这个向下延伸的形状架构,在不同的层上有不同大小的卷积,每个卷积包含大约相同数量的参数,所以网络可以在不同的层次上捕捉细节。
Dropout是收敛的必要条件。如果没有它,网络就会放弃或陷入琐碎的解决方案,就像所有的白色或黑色图像一样。
Erik和Shumeet的工作中使用的全连接层对汉字的效果不太好,产生更嘈杂和不稳定的输出。我的猜测是,汉字的结构要复杂得多,本质上更接近图像,而不是字母,所以