文章目录
- 假设检验
- 假设检验的基本原理
- 提出假设
- 作出决策
- 表述决策结果
- 一个总体参数的检验
- 总体均值的检验
- 总体比例的检验
- 总体方差的检验
- 两个总体参数的检验
- 两个总体均值之差的检验
- 两个总体比例之差的检验
- 两个总体方差比的检验
- 总体分布的检验
- 正态性检验的图示法
- Shapiro-Wilk 和 K-S 正态性检验
- 总结
假设检验
假设检验的基本原理
提出假设
假设检验:先对总体提出某种假设(例如对总参数提出一个假设值),然后利用样本信息判断这一假设是否成立
原假设:也称零假设,通常是研究者想搜集证据予以推翻的假设,记为
H
0
H_{0}
H0 ;原假设表达的含义是指参数没有变化、变量之间没有联系或总体分布与一理论分布并无差异,所以常有
=
=
=。设参数的假设值为
μ
0
\mu_{0}
μ0,原假设常写成
H
0
:
μ
=
μ
0
;
H
0
:
μ
≥
μ
0
;
H
0
:
μ
≤
μ
0
H_{0}:\,\mu=\mu_{0};\,H_{0}:\,\mu\geq\mu_{0};\,H_{0}:\,\mu\leq\mu_{0}
H0:μ=μ0;H0:μ≥μ0;H0:μ≤μ0 。原假设最初被假设是成立的,之后根据样本数据确定是否有足够的证据拒绝原假设。
备则假设:通常是研究者想搜集证据予以支持的假设,记为
H
1
H_{1}
H1或
H
a
H_{a}
Ha;备则假设表达的含义是指参数有变化、变量之间有联系或总体分布与一理论分布有差异。因此备则假设常写成
H
1
:
μ
≠
μ
0
;
H
1
:
μ
>
μ
0
;
H
1
:
μ
<
μ
0
H_{1}:\mu\not=\mu_{0};\,H_{1}:\,\mu>\mu_{0};\,H_{1}:\,\mu<\mu_{0}
H1:μ=μ0;H1:μ>μ0;H1:μ<μ0。备则假设通常用于表达研究者自己倾向于支持的看法,然后就是想办法收集证据拒绝原假设,支持备则假设。
- 双侧检验:也称双尾检验,指没有特定方向性的备则假设,含有符号 ≠ \not= =
- 单侧检验:也称单尾检验,指有特定方向性的备则假设,含有符号
>
>
>(右侧检验)或
<
<
<(左侧检验)
(备则假设就是我们为什么要检验的理由,例如我们检验一个车间生产的零件是否符合标准,我们肯定是认为它不符合标准才需要检验,要是我们认为它标准的话就没必要检验了。因此原假设是符合标准,备择假设是不符合标准)
作出决策
两类错误:
- 第 I 类错误:也称为 α \alpha α 错误,原假设是正确的却拒绝了原假设,概率记为 α \alpha α
- 第 II 类错误:也称为 β \beta β 错误,原假设是错误的却没有拒绝了原假设,概率记为 β \beta β
在样本量一定的情况下, α \alpha α 与 β \beta β 是负相关的;要是 α \alpha α 和 β \beta β 同时减小只能增大样本量。
显著性水平:即 α \alpha α,通常是人们事先指定的犯第一类错误的概率的最大允许值;一般情况下,人们认为第一类错误的后果更严重,因此会取一个较小的 α \alpha α 值,实际中常用 α = 0.01 \alpha=0.01 α=0.01 , α = 0.05 \alpha=0.05 α=0.05 和 α = 0.1 \alpha=0.1 α=0.1
① 用统计量决策:首先要根据样本观测结果计算对原假设作出决策的检验统计量。例如要检验总体均值,则可以对样本均值标准化(标准化检验统计量);然后根据实现确定好的显著性水平
α
\alpha
α 划定拒绝域:
标准化检验统计量
=
点估计
−
假设值
点估计量的标准差
标准化检验统计量=\frac{点估计-假设值}{点估计量的标准差}
标准化检验统计量=点估计量的标准差点估计−假设值
决策准则:
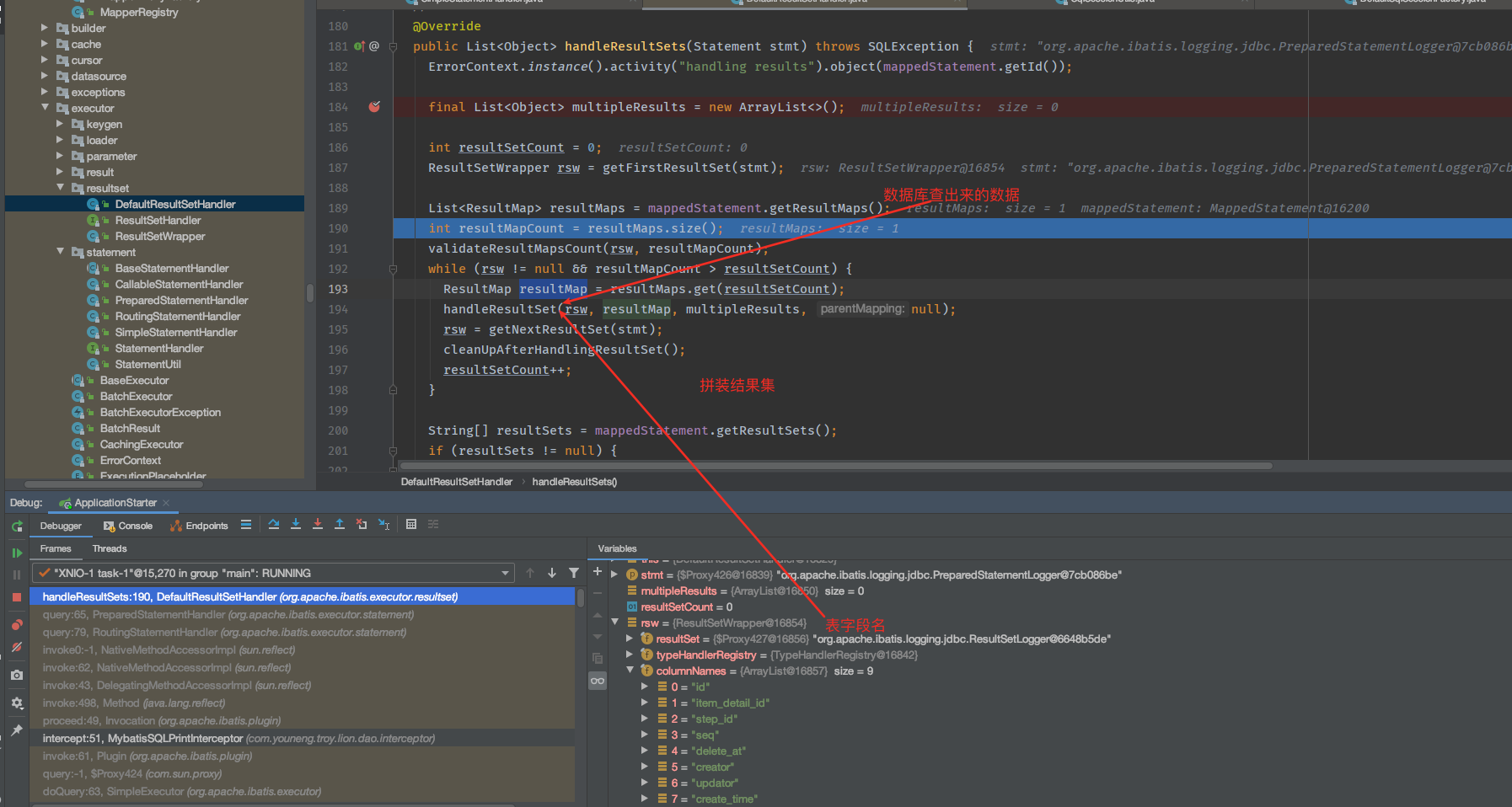
- 双侧检验:|统计量|>临界值,拒绝原假设
- 左侧检验:统计量的值<-临界值,拒绝原假设
- 右侧检验:统计量的值>临界值,拒绝原假设
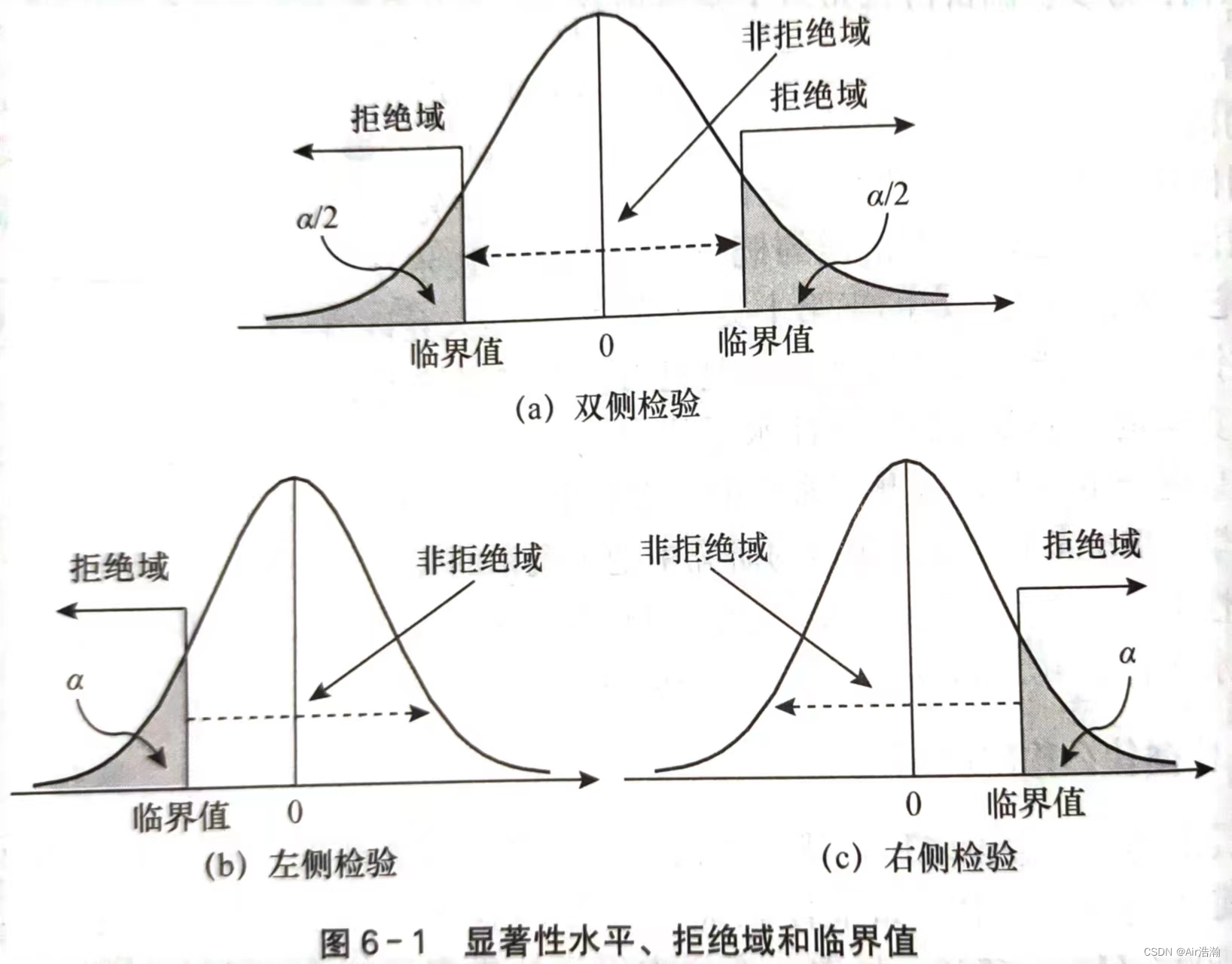
② 用 P P P 值决策:如果原假设是正确的,所得到的样本结果会像实际观测结果那么极端或者更极端的概率称为 P P P 值 ,也称观察到的显著性水平。
决策准则:
- 如果 P < α P\lt\alpha P<α ,则拒绝 H 0 H_0 H0
- 如果 P > α P>\alpha P>α ,则不拒绝 H 0 H_0 H0
注意:
- P P P 值是关于数据的概率,与原假设对错的概率无关; P P P 值反映的是某个总体的所有样本中某一类数据出现的经常程度。就是说当原假设是正确时, P P P 值就是得到目前这个样本的概率。
(书上解释的跟屎一样;比如我们要检验全小学生月平均生活支出是否为 2000 2000 2000 元, H 0 : μ = 2000 H_0:\,\mu=2000 H0:μ=2000 ,我们统计出来 X ˉ = 1750 \bar{X}=1750 Xˉ=1750 , P = 0.02 P=0.02 P=0.02, α = 0.05 \alpha=0.05 α=0.05 ,说明如果平均支出真的是 2000 2000 2000 的话,那么我们抽到 1750 1750 1750 的概率只有 0.02 0.02 0.02,太小了,所以可以拒绝原假设)
- P P P 值不一定要和显著性水平 α \alpha α 进行比较,我们可以认为 P P P 值越小,拒绝原假设的理由就越充分,一般要求 P P P 不大于 0.1 0.1 0.1
- P P P 值决策优于统计量决策, P P P 值其实是实际上犯 I 类错误的概率。
表述决策结果
- 假设检验不能证明原假设正确,“不拒绝”不代表“接受”,接受 H 0 H_0 H0 的风险由 β \beta β 衡量;
- 拒绝原假设时,称样本结果在“统计上是显著的”,“显著的”意思是“非偶然的”,但统计上显著不等于有实际意义
一个总体参数的检验
总体均值的检验
大样本的检验:样本均值经标准化后,可认为服从标准正态分布,因而采用正态分布的检验统计量:
- 当总体方差 σ 2 \sigma^2 σ2 已知时,总体均值检验统计量为:
Z = X ˉ − μ 0 σ / n Z=\frac{\bar{X}-\mu_0}{\sigma/\sqrt{n}} Z=σ/nXˉ−μ0
- 当总体方差 σ 2 \sigma^2 σ2 未知时,可以用样本方差 S 2 S^2 S2 代替,得到总体均值检验统计量为:
Z = X ˉ − μ 0 S / n Z=\frac{\bar{X}-\mu_0}{S/\sqrt{n}} Z=S/nXˉ−μ0
小样本的检验:
- 当总体方差 σ 2 \sigma^2 σ2 已知时,即使是在小样本的情况下,样本均值经标准化后仍然服从标准正态分布,总体均值检验统计量为:
Z = X ˉ − μ 0 σ / n Z=\frac{\bar{X}-\mu_0}{\sigma/\sqrt{n}}\ Z=σ/nXˉ−μ0
- 当总体方差未知时,检验统计量满足 t 分布(自由度为 n − 1 n-1 n−1 ),通常称为 t 检验
t = X ˉ − μ 0 S / n t=\frac{\bar{X}-\mu_0}{S/\sqrt{n}} t=S/nXˉ−μ0
总体比例的检验
大样本的检验:样本比例经过标准化后近似服从标准正态分布,因此总体比例检验统计量为:(
π
0
\pi_0
π0 可以是我们猜测的比例)
Z
=
p
−
π
0
π
0
(
1
−
π
0
)
n
Z=\frac{p-\pi_0}{\sqrt{\frac{\pi_0(1-\pi_0)}{n}}}
Z=nπ0(1−π0)p−π0
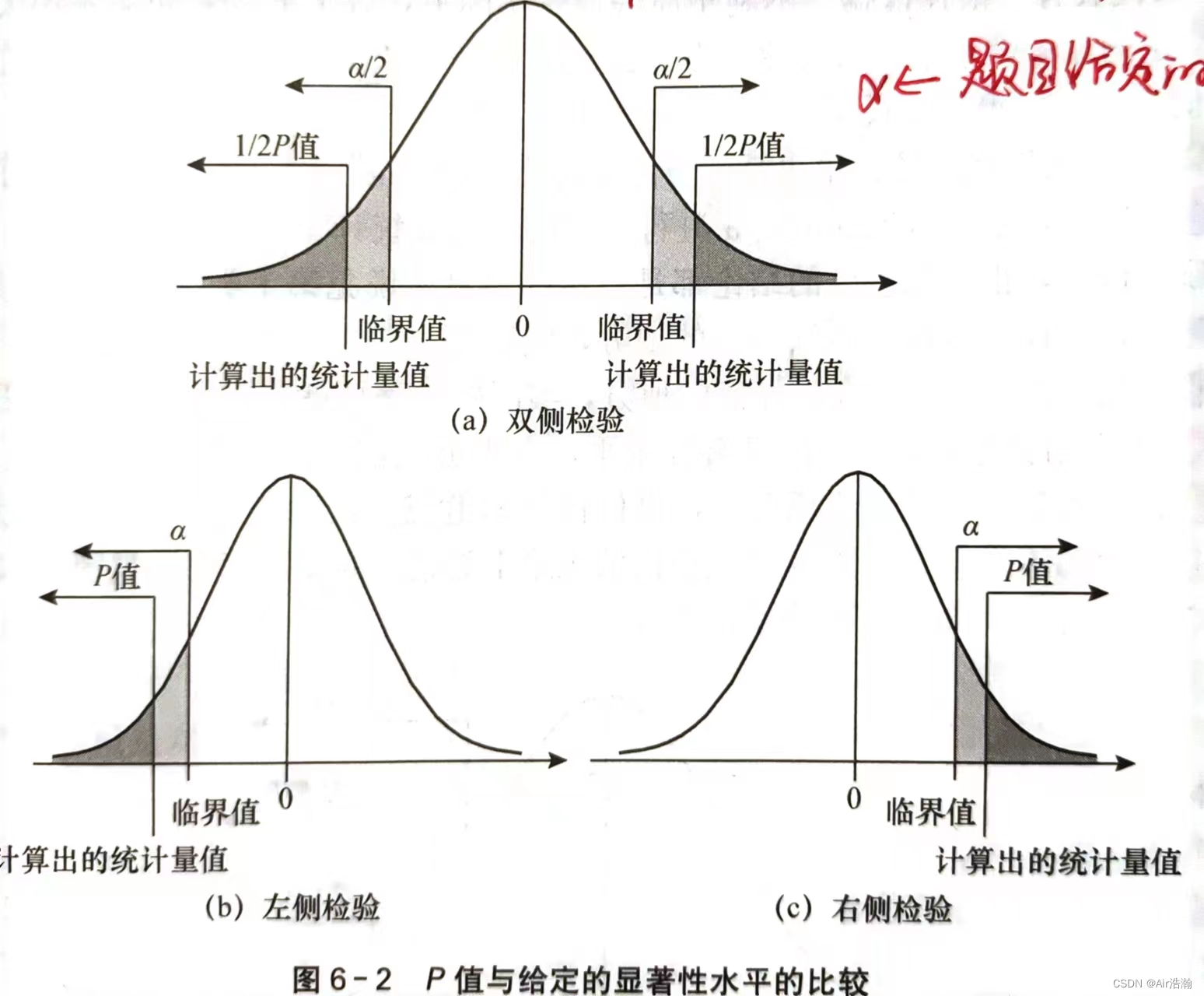
总体方差的检验
总体方差的检验,不论样本量
n
n
n 是大是小,都要求总体服从正态分布。总体方差检验统计量为:(
σ
0
\sigma_0
σ0 可以是我们猜测的方差)
χ
2
=
(
n
−
1
)
S
2
σ
0
2
\chi^2=\frac{(n-1)S^2}{\sigma_0^2}
χ2=σ02(n−1)S2
(
χ
2
\chi^2
χ2 自由度为
n
−
1
n-1
n−1 )由于是不对称分布,因此我们采取等尾区间:
两个总体参数的检验
两个总体均值之差的检验
(常用于比如比较两个相似环境下产生的结果是否相同,取 H 0 : ( μ 1 − μ 2 ) = 0 H_0:\,(\mu_1-\mu_2)=0 H0:(μ1−μ2)=0 )
独立大样本的检验:两样本均值之差经标准化后满足正态分布( ( μ 1 − μ 2 ) (\mu_1-\mu_2) (μ1−μ2) 为我们猜测的样本均值之差的值)
- 当总体方差 σ 1 2 \sigma_1^2 σ12 和 σ 2 2 \sigma_2^2 σ22 已知时,总体均值检验统计量为:
Z = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 Z=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}} Z=n1σ12+n2σ22(X1ˉ−X2ˉ)−(μ1−μ2)
- 当总体方差 σ 1 2 \sigma_1^2 σ12 和 σ 2 2 \sigma_2^2 σ22 已知时,分别使用样本方差 S 1 2 S_1^2 S12 和 S 2 2 S_2^2 S22 代替,总体均值检验统计量为:
Z = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) S 1 2 n 1 + S 2 2 n 2 Z=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{\sqrt{\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2}}} Z=n1S12+n2S22(X1ˉ−X2ˉ)−(μ1−μ2)
独立小样本的检验:
- 当总体方差 σ 1 2 \sigma_1^2 σ12 和 σ 2 2 \sigma_2^2 σ22 已知时,样本均值之差经标准化后仍然服从标准正态分布,总体均值之差检验统计量为:
Z = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 Z=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}} Z=n1σ12+n2σ22(X1ˉ−X2ˉ)−(μ1−μ2)
- 当总体方差 σ 1 2 \sigma_1^2 σ12 和 σ 2 2 \sigma_2^2 σ22 未知,但 σ 2 2 = σ 2 2 \sigma_2^2=\sigma_2^2 σ22=σ22 时,需要将两个样本数据组合在一起,组合后的样本方差 S p S_p Sp 为:
S p = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 + n 2 − 2 S_p=\frac{(n_1-1)S_1^2+(n_2-1)S_2^2}{n_1+n_2-2} Sp=n1+n2−2(n1−1)S12+(n2−1)S22
样本均值之差标准化后符合自由度为
n
1
+
n
2
−
2
n_1+n_2-2
n1+n2−2 的 t 分布,检验统计量为:
t
=
(
X
1
ˉ
−
X
2
ˉ
)
−
(
μ
1
−
μ
2
)
S
p
1
n
1
+
1
n
2
t=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{S_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}
t=Spn11+n21(X1ˉ−X2ˉ)−(μ1−μ2)
- 当总体方差 σ 1 2 \sigma_1^2 σ12 和 σ 2 2 \sigma_2^2 σ22 未知且 σ 2 2 ≠ σ 2 2 \sigma_2^2\not=\sigma_2^2 σ22=σ22 时,样本均值之差标准化后近似服从自由度为 v v v 的 t 分布,检验统计量为:
t = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) S 1 2 n 1 + S 2 2 n 2 t=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{\sqrt{\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2}}} t=n1S12+n2S22(X1ˉ−X2ˉ)−(μ1−μ2)
其中
v
v
v 为:(需要四舍五入求整数)
v
=
(
S
1
2
n
1
+
S
2
2
n
2
)
2
(
S
1
2
n
1
)
2
n
1
−
1
+
(
S
2
2
n
2
)
2
n
2
−
1
v=\frac{(\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2})^2}{\frac{(\frac{S_1^2}{n_1})^2}{n_1-1}+\frac{(\frac{S_2^2}{n_2})^2}{n_2-1}}
v=n1−1(n1S12)2+n2−1(n2S22)2(n1S12+n2S22)2
配对样本的检验:配对样本的检验需要假定两个总体配对差值构成的总体服从正态分布,且配对差是从差值总体中随机抽取的。对于小样本情形,配对差值经标准化后服从自由度为
n
−
1
n-1
n−1 的 t 分布,因此选择的检验统计量为:
t
=
d
ˉ
−
(
μ
1
−
μ
2
)
S
d
/
n
t=\frac{\bar{d}-(\mu_1-\mu_2)}{S_d/\sqrt{n}}
t=Sd/ndˉ−(μ1−μ2)
其中
d
ˉ
\bar{d}
dˉ 为配对差值的平均数,
S
d
S_d
Sd 为配对差值的标准差
两个总体比例之差的检验
独立大样本:要求两个样本都是大样本,即
n
1
p
1
n_1p_1
n1p1 ,
n
1
(
1
−
p
1
)
n_1(1-p_1)
n1(1−p1) ,
n
2
p
2
n_2p_2
n2p2 和
n
2
(
1
−
p
2
)
n_2(1-p_2)
n2(1−p2) 都大于等于
10
10
10 。根据两个样本比例之差的标准化的抽样分布,可以得到总体比例之差检验统计量为:
Z
=
(
p
1
−
p
2
)
−
(
π
1
−
π
2
)
σ
p
1
−
p
2
Z=\frac{(p_1-p_2)-(\pi_1-\pi_2)}{\sigma_{p_1-p_2}}
Z=σp1−p2(p1−p2)−(π1−π2)
其中
σ
p
1
−
p
2
=
π
1
(
1
−
π
1
)
n
1
+
π
2
(
1
−
π
2
)
n
2
\sigma_{p_1-p_2}=\sqrt{\frac{\pi_1(1-\pi_1)}{n_1}+\frac{\pi_2(1-\pi_2)}{n_2}}
σp1−p2=n1π1(1−π1)+n2π2(1−π2) 是两个样本比例之差抽样分布的标准差。但是你发现
π
1
\pi_1
π1 和
π
2
\pi_2
π2 事先都是不知道的,分为两种情况:
- 检验两个总体比例是否相等,即 H 0 : π 1 − π 2 = 0 H_0:\,\pi_1-\pi_2=0 H0:π1−π2=0 , H 1 : π 2 − π 2 ≠ 0 H_1:\,\pi_2-\pi_2\not=0 H1:π2−π2=0 ;此时 π 1 \pi_1 π1 和 π 2 \pi_2 π2 的最佳估计是将两个样本合并后得到的比例,为:
p = p 1 n 1 + p 2 n 2 n 1 + n 2 p=\frac{p_1n_1+p_2n_2}{n_1+n_2} p=n1+n2p1n1+p2n2
此时
σ
π
1
−
π
2
\sigma_{\pi_1-\pi_2}
σπ1−π2 的最佳估计量为:
σ
π
1
−
π
2
=
p
(
1
−
p
)
(
1
n
1
+
1
n
2
)
\sigma_{\pi_1-\pi_2}=\sqrt{p(1-p)(\frac{1}{n_1}+\frac{1}{n_2})}
σπ1−π2=p(1−p)(n11+n21)
代入得到两个总体比例之差的检验统计量为:
Z
=
p
1
−
p
2
p
(
1
−
p
)
(
1
n
1
+
1
n
2
)
Z=\frac{p_1-p_2}{\sqrt{p(1-p)(\frac{1}{n_1}+\frac{1}{n_2})}}
Z=p(1−p)(n11+n21)p1−p2
- 检验两个总体比例之差是否是个常数,即 H 0 : π 1 − π 2 = d 0 H_0:\,\pi_1-\pi_2=d_0 H0:π1−π2=d0 , H 1 : π 2 − π 2 ≠ d 0 H_1:\,\pi_2-\pi_2\not=d_0 H1:π2−π2=d0 ,这时可直接用两个样本的比例 p 1 p_1 p1 和 p 2 p_2 p2 作为两个总体比例 π 1 \pi_1 π1 和 π 2 \pi_2 π2 的估计,从而得到两个总体比例之差的检验统计量为:
Z = ( p 1 − p 2 ) − d 0 p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 Z=\frac{(p_1-p_2)-d_0}{\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}} Z=n1p1(1−p1)+n2p2(1−p2)(p1−p2)−d0
(也有可能是这样: H 0 : π 1 − π 2 ≥ 0 H_0:\,\pi_1-\pi_2\ge 0 H0:π1−π2≥0 , H 1 : π 1 − π 2 < 0 H_1:\,\pi_1-\pi_2<0 H1:π1−π2<0 或者 H 0 : π 1 − π 2 ≤ 0 H_0:\,\pi_1-\pi_2\le 0 H0:π1−π2≤0 , H 1 : π 1 − π 2 > 0 H_1:\,\pi_1-\pi_2>0 H1:π1−π2>0 ,都当作第一种来处理,要注意等号总是在原假设里)
两个总体方差比的检验
对总体方差比的假设通常是跟
1
1
1 相比,就是看两个总体谁的方差更大一些。由于两个样本方差之比
S
1
2
S
2
2
\frac{S_1^2}{S_2^2}
S22S12 是两个总体方差之比
σ
1
2
σ
2
2
\frac{\sigma_1^2}{\sigma_2^2}
σ22σ12 的理想估计量,故检验统计量为:(符合
F
(
n
1
,
n
2
)
F(n_1,\,n_2)
F(n1,n2) 分布)
F
=
S
1
2
S
2
2
F=\frac{S_1^2}{S_2^2}
F=S22S12
双侧检验通常是用较大的样本方差除以较小的样本方差,这样拒绝域总是发生在 F 分布的右侧。在左侧检验时,也可以安排为右侧检验。
总体分布的检验
总体正态性检验:根据样本数据检验总体上是否服从正态分布,检验方法有图示法和检验法。
正态性检验的图示法
正态概率图:有两种:
- Q − Q Q-Q Q−Q 图:根据观测值的实际分位数与理论分布(如正态分布)的分位数绘制的
- P − P P-P P−P 图:根据观测数据的累积概率与理论分布(如正态分布)的符合程度绘制的
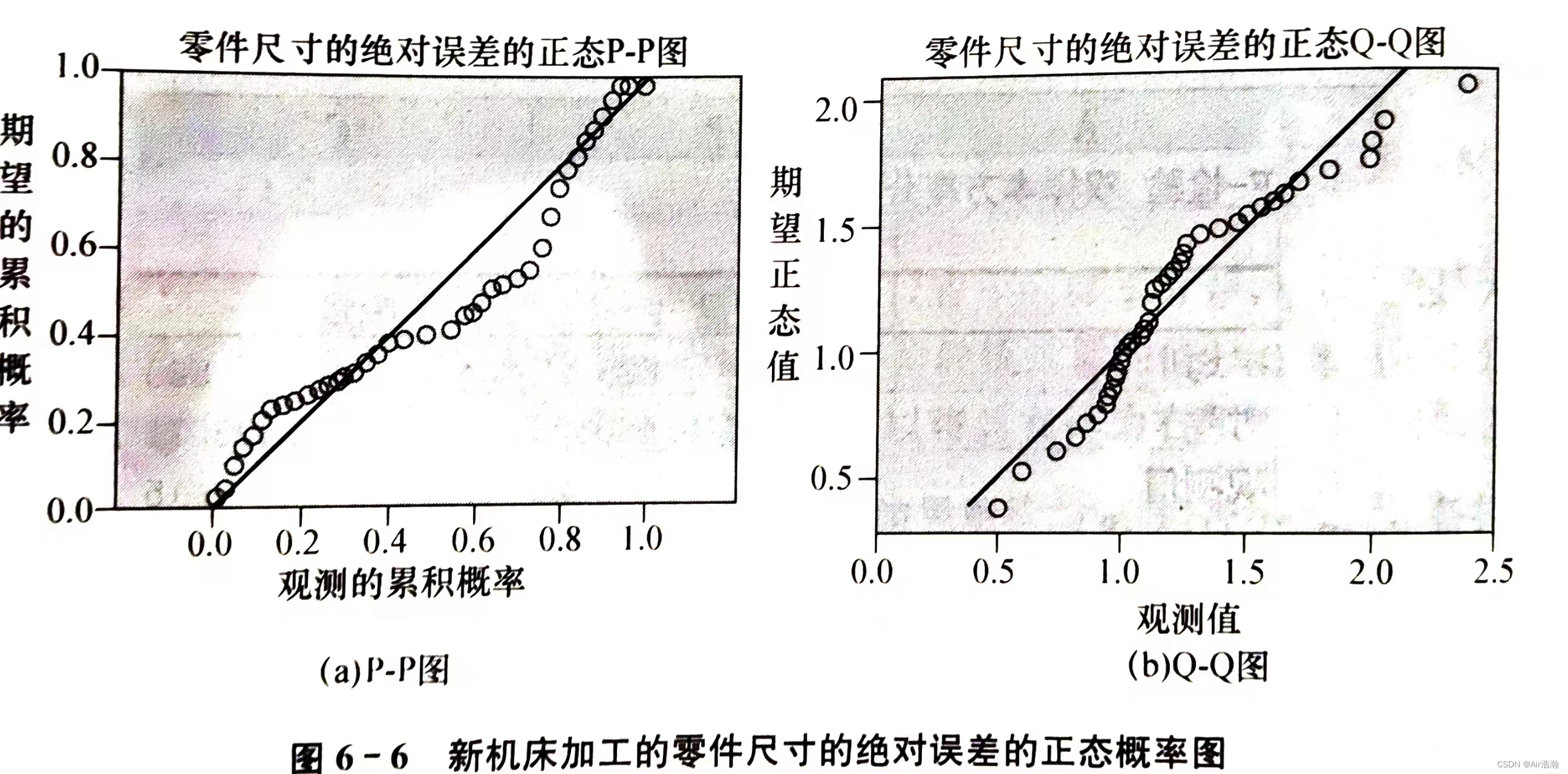
-
图中直线表示理论正态分布线,各观测点越靠近直线,且呈随机分布,表明数据越接近正态分布。
-
实际使用时并不一定要参考理论正态分布线,只要所有点都在一条直线的周围随机分布即可
-
由于正态概率图中的点很少,提供的正态性信息有限,适用于大样本量;
Shapiro-Wilk 和 K-S 正态性检验
当样本量较小时,可以使用标准的统计检验办法,即假设总体服从正态分布,如果检验获得的 P P P 值小于显著性水平 α \alpha α ,则拒绝原假设。
Shapiro-Wilk 方法:(适用于小样本)
H
0
H_0
H0 :总体服从正态分布,
H
1
H_1
H1 :总体不服从正态分布,然后计算检验统计量
W
W
W :
W
=
∑
a
i
y
i
2
∑
(
y
i
−
y
ˉ
)
2
W=\frac{\sum a_iy_i^2}{\sum(y_i-\bar{y})^2}
W=∑(yi−yˉ)2∑aiyi2
- y i y_i yi 为排序后的样本数据, y ˉ \bar{y} yˉ 是样本均值
- a i a_i ai 时样本量为 n n n 所对应的系数,通过:
[ a 1 , ⋯ , a n ] = m T V − 1 ∣ ∣ V − 1 m ∣ ∣ \begin{bmatrix}a_1,\cdots,a_n\end{bmatrix}=\frac{m^{T}V^{-1}}{||V^{-1}m||} [a1,⋯,an]=∣∣V−1m∣∣mTV−1
- V V V 是这些有序统计量的协方差
- m = [ m 1 , ⋯ , m n ] m=\begin{bmatrix}m_1,\cdots,m_n\end{bmatrix} m=[m1,⋯,mn] ,其中 m i m_i mi 是从一个标准的正态分布随机变量上采样的有序独立同分布的统计量的期望值
W W W 的最大值是 1 1 1 ,最小值是 n a 1 2 n = 1 \frac{na_1^2}{n=1} n=1na12 ,统计量越大表示越符合正态分布。当然,非正态分布的小样本数据也有可能有较大的 W W W 值,而且由于该统计量的分布是未知的,因此需要通过模拟或者查表来估计概率。
Kolmogorov-Smirnov 检验:既适合大样本,又适合小样本,而且不止可以检验正态分布。将实际频数和期望频数进行比较,检验其拟合程度。具体来说,是将某一变量的积累分布函数与特定的分布函数进行比较。设总体的积累分布函数为
F
(
x
)
F(x)
F(x) ,已知理论分布函数为
F
0
(
x
)
F_0(x)
F0(x) ,则:
H
0
:
F
(
x
)
=
F
0
(
x
)
;
H
1
:
F
(
x
)
≠
F
0
(
x
)
;
H_0:\,F(x)=F_0(x);\quad H_1:\,F(x)\not=F_0(x);
H0:F(x)=F0(x);H1:F(x)=F0(x);
各样本观察值的实际累计概率为
S
(
x
)
S(x)
S(x) ,实际累计概率与理论累计概率的差值为
D
(
x
)
D(x)
D(x) ,差值序列中最大的绝对差值:
D
=
m
a
x
(
∣
S
(
x
i
)
−
F
(
x
i
)
∣
)
D=max(|S(x_i)-F(x_i)|)
D=max(∣S(xi)−F(xi)∣)
实际累计概率肯定是离散值,因此可以修正为:
D
=
m
a
x
(
(
∣
S
(
x
i
)
−
F
(
x
i
)
∣
)
,
(
∣
S
(
x
i
−
1
)
−
F
(
x
i
)
∣
)
)
D=max((|S(x_i)-F(x_i)|),\,(|S(x_{i-1})-F(x_i)|))
D=max((∣S(xi)−F(xi)∣),(∣S(xi−1)−F(xi)∣))
在小样本情况下,统计量
D
D
D 服从 Kolmogorov 分布;在大样本情况下,则用正态分布近似,统计量为:
Z
=
n
D
Z=\sqrt{n}D
Z=nD
如果原假设成立,则每次抽样得到的
D
D
D 值应当不会偏离
0
0
0 太远。
K-S要求样本数据是连续的数值型数据,且要求理论分布已知。总体均值和方差未知时也可以用 X ˉ \bar{X} Xˉ 和 S 2 S^2 S2 代替。