文章目录
- 1. 认识URL
- 2. urlencode和urldecode
- 3. HTTP协议格式
- 3-1. HTTP请求
- 3-1. HTTP响应
- 4. HTTP的方法
- 5. HTTP的状态码
- 6. TTP常见Header
- 7. 最简单的HTTP服务器
虽然我们说, 应用层协议是我们程序猿自己定的但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一。
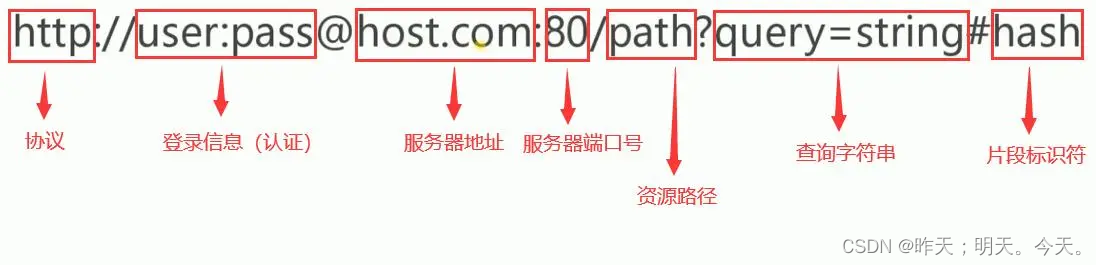
1. 认识URL
- 平时我们俗称的 “网址” 其实就是说的UR
2. urlencode和urldecode
- 像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.。
- 比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义。
转义的规则如下:
- 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
例如:
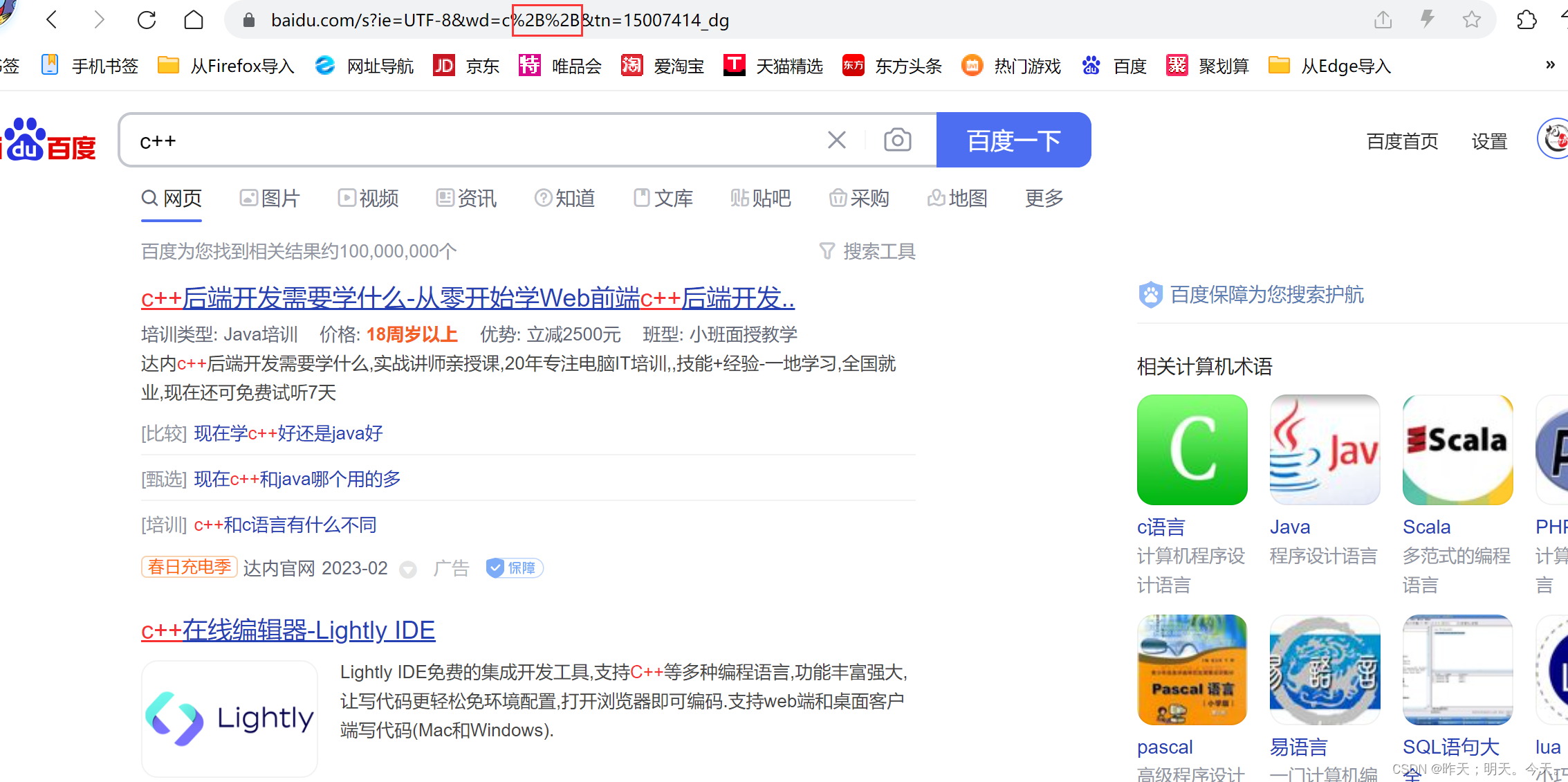
“+” 被转义成了 “%2B” urldecode就是urlencode的逆过程。
3. HTTP协议格式
- 定位互联网中唯一的一个资源,url,统一资源定位符
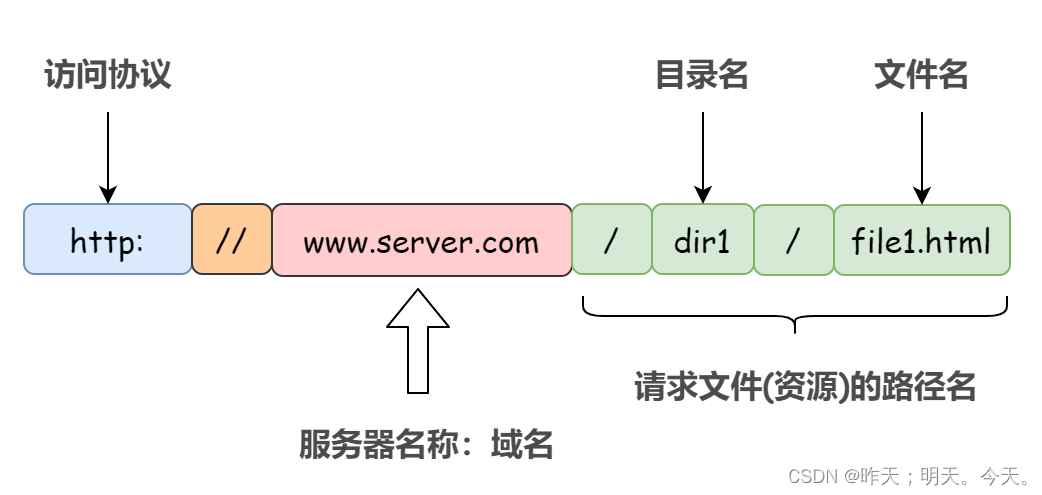
- www. 称万维网
- 所有的资源:全球范围内,只要找到它的url就能访问该资源!
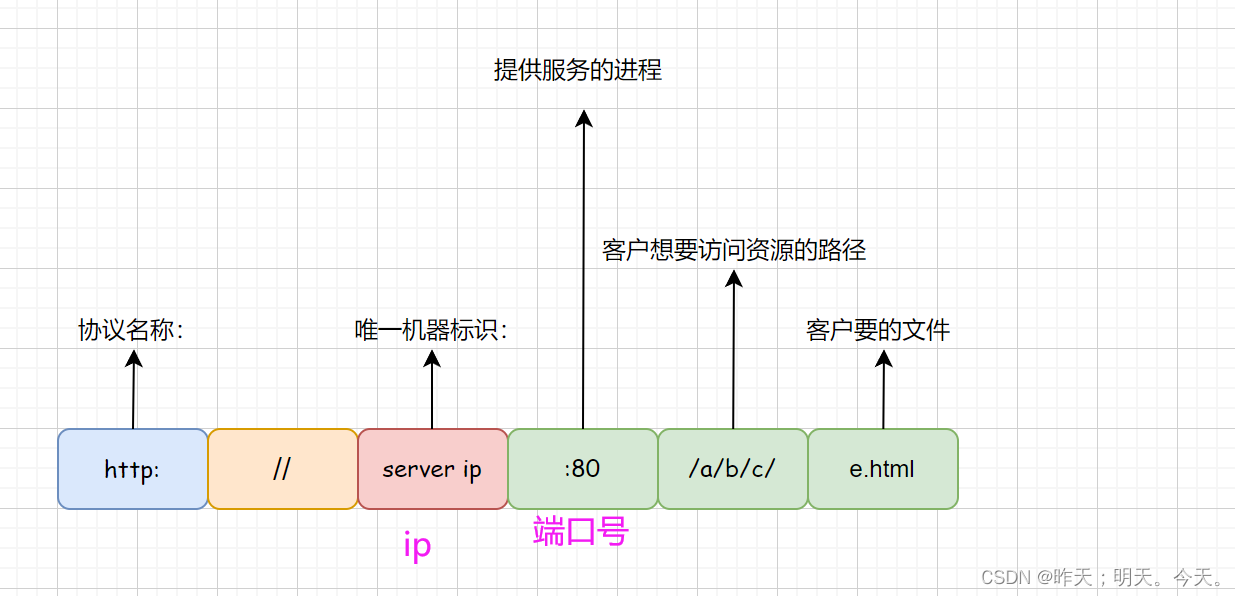
如下图:
3-1. HTTP请求
---GET / HTTP/1.1
---Host: 1.15.234.247:8082
---Connection: keep-alive
---Cache-Control: max-age=0
---Upgrade-Insecure-Requests: 1
---User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.1171 SLBChan/11
---Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
---Accept-Encoding: gzip, deflate
---Accept-Language: zh-CN,zh;q=0.9
---
- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束。
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个
Content-Length属性来标识Body的长度;
什么意思呐?
看图!!!
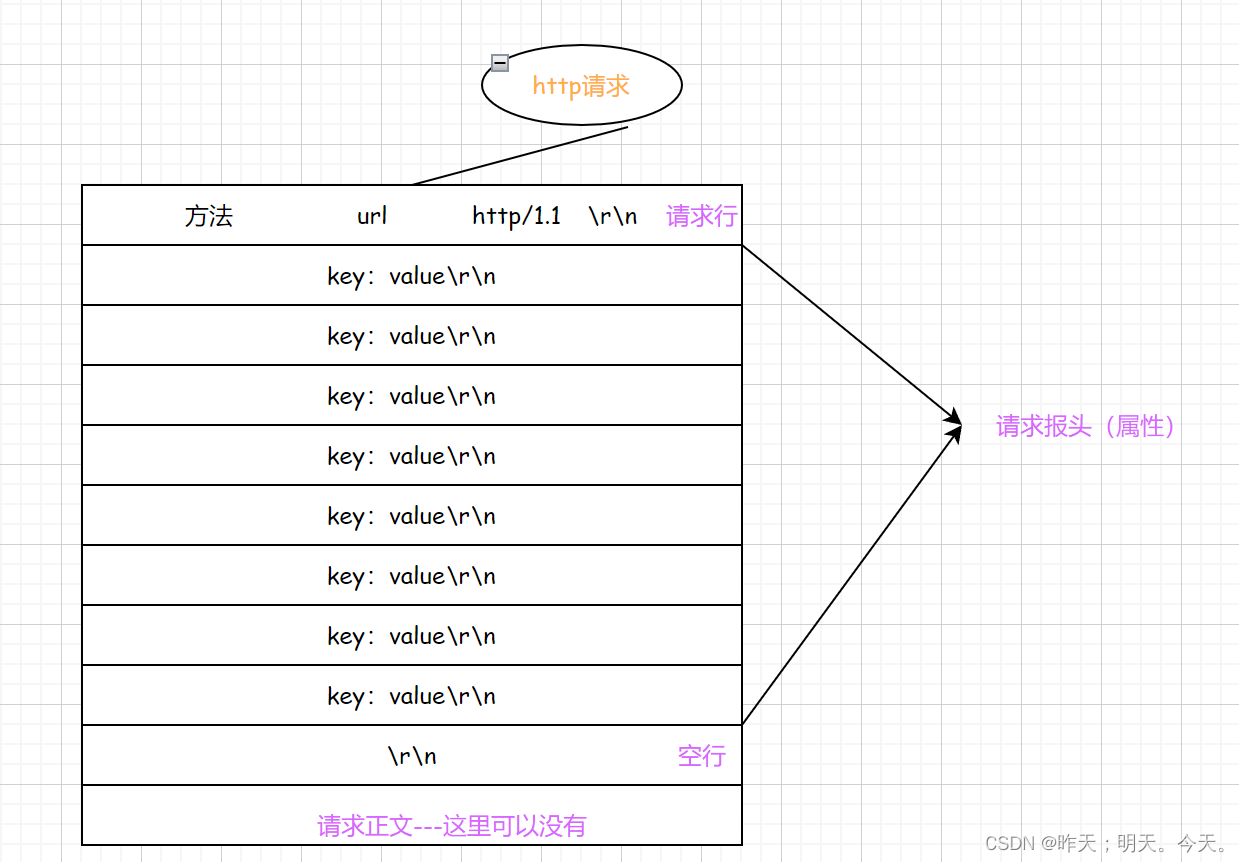
怎么理解??就是一个以/r/n为分割符的线性结构(vector)
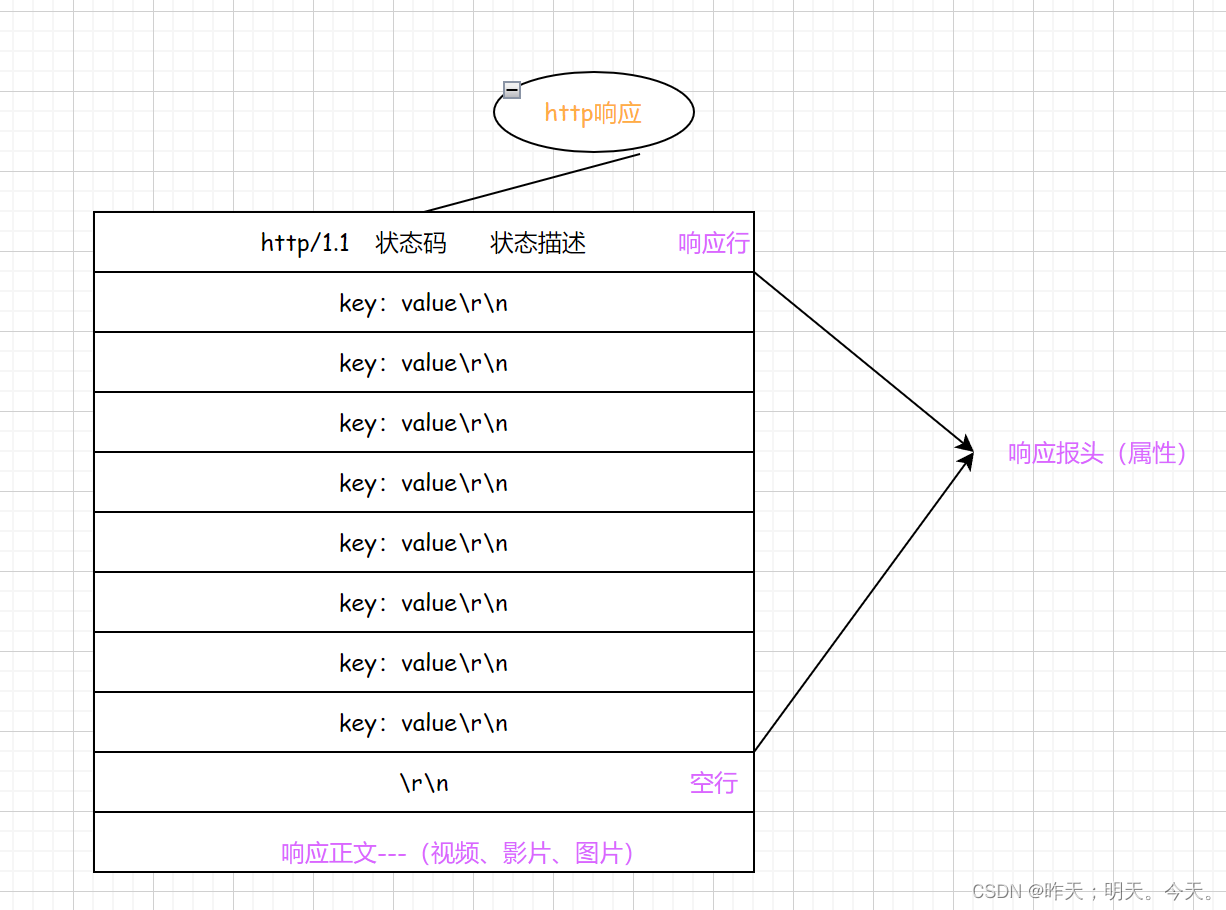
3-1. HTTP响应
HTTP/1.1 200 OK
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>小丁同学的课程</title>
</head>
<body>
<h3>这是一个Linux课程</h3>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
<p>我是一个Linux的学习者, 我正在进行http的测试工作! ! </p>
</body>
</html>
上面模拟的响应我没写响应报头。
- 首行: [版本号] + [状态码] + [状态码解释];
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束;
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中。
老样子
看图!!!**
4. HTTP的方法
其中最常用的就是GET方法和POST方法.
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用⒆道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
其中最常用的就是GET方法和POST方法.
5. HTTP的状态码
| - | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
最常见的状态码:200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
6. TTP常见Header
- Content-Type: 数据类型(text/html等);
- Content-Length: Body的长度;
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
7. 最简单的HTTP服务器
-
实现一个最简单的HTTP服务器, 只在网页上输出 “hello world”; 只要我们按照HTTP协议的要求构造数据, 就很容易能做到。
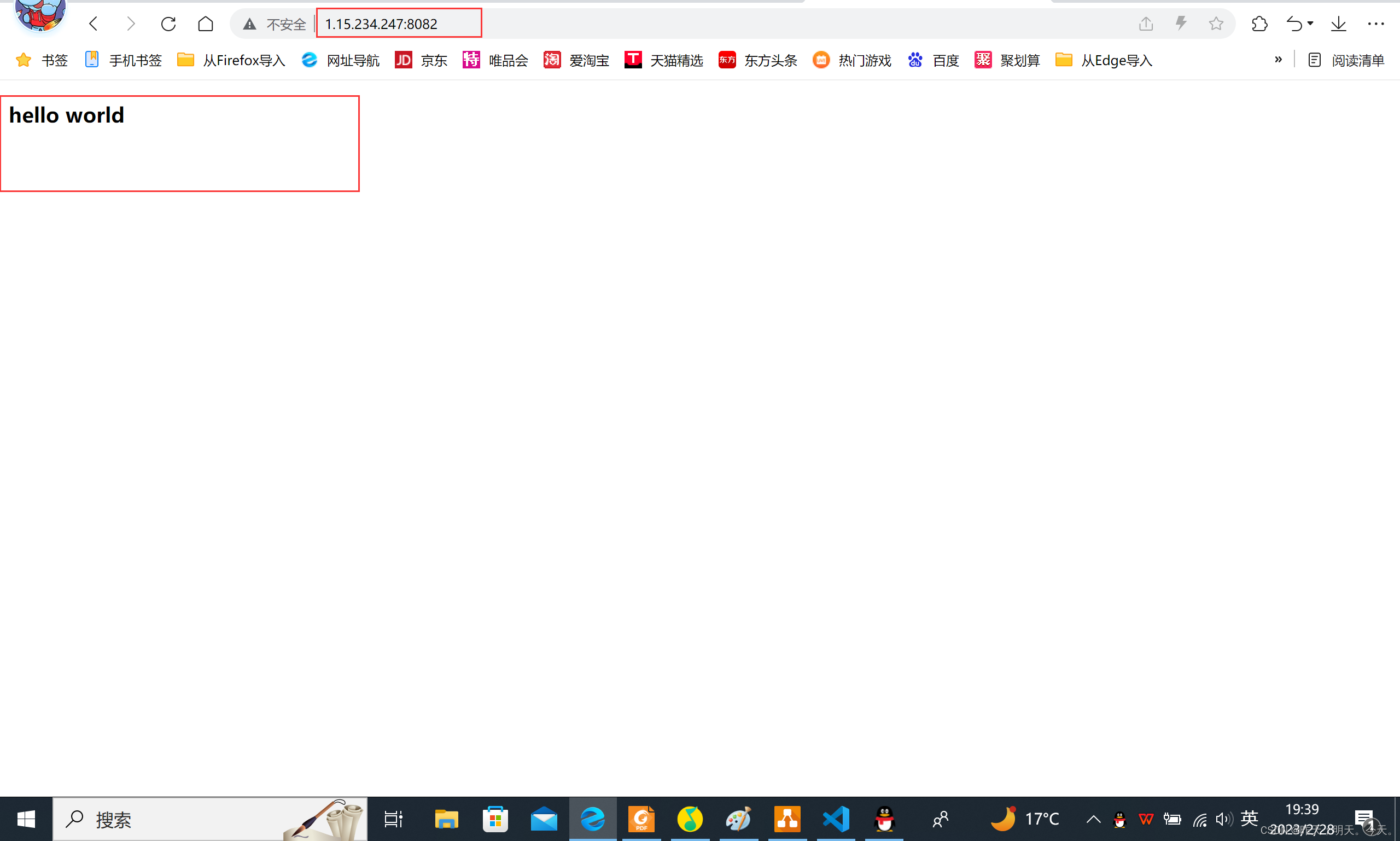
编译, 启动服务. 在浏览器中输入 http://[ip]:[port], 就能看到显示的结果 “Hello World” -
代码链接我放到git仓库里了哈~
https://gitee.com/ding-xushengyun/linux__cpp/tree/master/http_demo