知识要点
- wide&deep: 模型构建中, 卷积后数据和原始数据结合进行输出.
- fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target,所有属性值均为number,详情可调用fetch_california_housing()['DESCR']了解每个属性的具体含义;目标值为连续值
- wide&deep结合: concat = keras.layers.concatenate([input, hidden2]) # 将卷积后的结果和原始的输入值进行结合
- mse: 均方误差
- 多输入wide&deep模型: concat = keras.layers.concatenate([input_wide, hidden2]) # 定义两个输入创建模型, 然后其中一个进行深度卷积, 另一个直接用来结合卷积后的结果. 同时注意需要对输入特征数据进行调整.
- model = keras.models.Model(inputs=[input_wide,input_deep],outputs =[output,output2]) # 多输入输出
- 定义模型回调函数: # log_dir 文件夹目录
callbacks = [
keras.callbacks.TensorBoard(log_dir),
keras.callbacks.ModelCheckpoint(output_model_file, save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]- 函数式实现wide&deep的方法:
# 子类API的写法, pytch
class WideDeepModel(keras.models.Model):
def __init__(self):
'''定义模型的层次'''
super().__init__()
self.hidden1 = keras.layers.Dense(32, activation = 'relu')
self.hidden2 = keras.layers.Dense(32, activation = 'relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
'''完成模型的正向传播'''
hidden1 = self.hidden1(input)
hidden2 = self.hidden2(hidden1)
# 拼接
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return output
'''定义实例对象'''
model = WideDeepModel()
model.build(input_shape = (None, 8))1 wide and deep模型
1.1 背景
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
1.2 网络结构原理
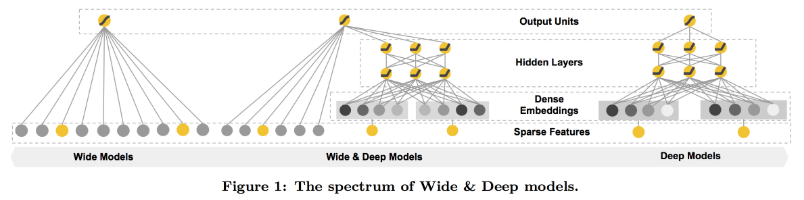
1.3 稀疏特征
离散值特征: 只能从N个值中选择一个
-
比如性别, 只能是男女
-
one-hot编码表示的离散特征, 我们就认为是稀疏特征.
-
Eg: 专业= {计算机, 人文, 其他}, 人文 = [0, 1, 0]
-
Eg: 词表 = {人工智能,深度学习,你, 我, 他 , ..} 他= [0, 0, 0, 0, 1, 0, ...]
-
叉乘 = {(计算机, 人工智能), (计算机, 你)...}
-
叉乘可以用来精确刻画样本, 实现记忆效果.
-
优点:
-
有效, 广泛用于工业界, 比如广告点击率预估(谷歌, 百度的主要业务), 推荐算法.
-
-
缺点:
-
需要人工设计.
-
叉乘过度, 可能过拟合, 所有特征都叉乘, 相当于记住了每一个样本.
-
泛化能力差, 没出现过就不会起效果
-
密集特征
-
向量表达
-
Eg: 词表 = {人工智能, 我们, 他}
-
他 = [0.3, 0.2, 0.6, ...(n维向量)]
-
每个词都可以用一个密集向量表示, 那么词和词之间就可以计算距离.
-
-
Word2vec工具可以方便的将词语转化为向量.
-
男 - 女 = 国王 - 王后
-
-
优点:
-
带有语义信息, 不同向量之间有相关性.
-
兼容没有出现过的特征组合.
-
更少人工参与
-
-
缺点:
-
过度泛化, 比如推荐不怎么相关的产品.
-
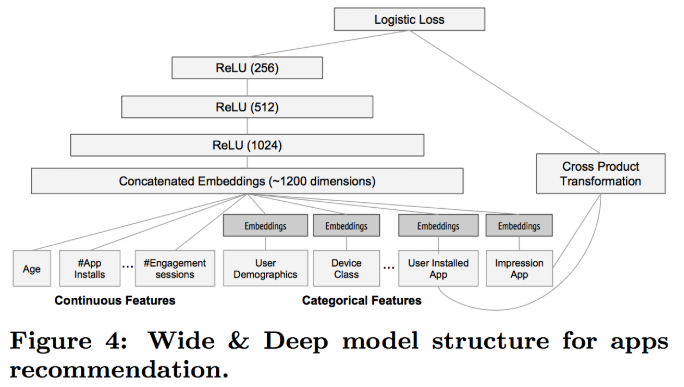
1.4 简单神经网络实现回归任务 (加利福尼亚州房价数据)
- concat = keras.layers.concatenate([input, hidden2])
1.4.1 导包
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split1.4.2 加利福尼亚州房价数据导入
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data,
housing.target,
random_state= 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all,
random_state = 11)1.4.3 标准化数据
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler =StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)1.4.4 基础神经网络 实现回归任务
# 定义网络
model = keras.models.Sequential([
# input_dim是传入数据, input_shape一定要是元组
keras.layers.Dense(128, activation = 'relu', input_shape = x_train.shape[1:]),
keras.layers.Dense(64, activation = 'tanh'),
keras.layers.Dense(1)])
1.4.5 配置和训练模型
# 配置
model.compile(loss = 'mean_squared_error', optimizer = 'sgd', metrics = ['mse'])
# epochs 迭代次数
history = model.fit(x_train_scaled, y_train, validation_data = (x_valid_scaled, y_valid), epochs = 30)
1.4.6 图文显示
# 定义画图函数, 看是否过拟合
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
1.5 定义回调函数
- 回调函数中添加保存最佳参数的模型
- 定义提前停止的条件 # 连续多少次变化幅度小于某值时停止训练
log_dir = './callback'
if not os.path.exists(log_dir): # 如果没有直接创建
os.mkdir(log_dir)
# 模型文件保存格式, 一般为h5, 会保存层级
output_model_file = os.path.join(log_dir, 'model.h5')
callbacks = [
keras.callbacks.TensorBoard(log_dir),
keras.callbacks.ModelCheckpoint(output_model_file, save_best_only = True),
keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
# epochs 迭代次数
history = model.fit(x_train_scaled,y_train,validation_data =(x_valid_scaled,y_valid),
epochs = 50, callbacks = callbacks)
2 多输入 wide&deep模型
2.1 wide&deep模型 (内部进行结合)
input = keras.layers.Input(shape = x_train.shape[1:]) # (11610, 8)
hidden1 = keras.layers.Dense(32, activation = 'relu')(input)
hidden2 = keras.layers.Dense(32, activation = 'relu')(hidden1)
concat = keras.layers.concatenate([input, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input], outputs = output)
model.compile(loss = 'mean_squared_error', optimizer = 'Adam', metrics= ['mse'])
history = model.fit(x_train_scaled, y_train,
validation_data = (x_valid_scaled, y_valid),
epochs= 20)
import pandas as pd
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)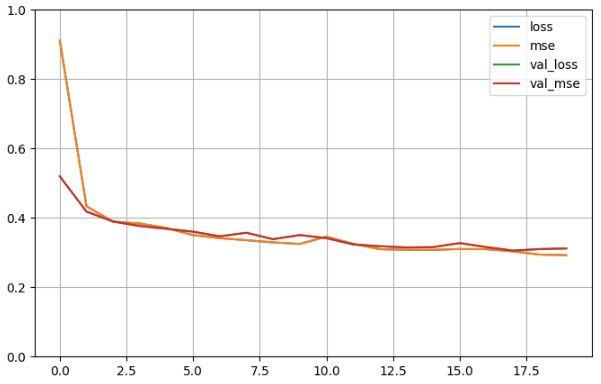
2.2 wide&deep方式二 (多输入)
- 定义两个输入创建模型
# 多输入
# 定义两个输入
input_wide = keras.layers.Input(shape = [5])
input_deep = keras.layers.Input(shape = [6])
hidden1 = keras.layers.Dense(30, activation = 'relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation = 'relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input_wide, input_deep], outputs =[output])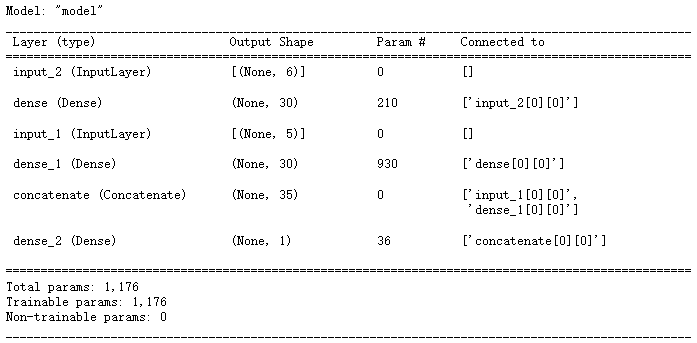
# 对输入数据进行修改
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]
x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]
x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]
history = model.fit([x_train_scaled_wide, x_train_scaled_deep],
y_train, validation_data = ([x_valid_scaled_wide, x_valid_scaled_deep], y_valid), epochs= 20)
2.3 wide&deep方式三 (多输出)
- 双输入双输出
# 多输出 # 定义两个输入
input_wide = keras.layers.Input(shape = [5])
input_deep = keras.layers.Input(shape = [6])
hidden1 = keras.layers.Dense(30, activation = 'relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation = 'relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])
output = keras.layers.Dense(1)(concat)
output2 = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs=[input_wide,input_deep],outputs =[output,output2])
# 对输入数据进行修改
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]
x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]
x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]
history = model.fit([x_train_scaled_wide, x_train_scaled_deep],
[y_train, y_train], validation_data = ([x_valid_scaled_wide, x_valid_scaled_deep], [y_valid, y_valid]), epochs= 20)
- 在该模型的效果一般
3 子类API 实现wide&deep模型
3.1 函数构建模型
- 卷积后的结果结合原始输入进行运算
# 子类API的写法, pytch
class WideDeepModel(keras.models.Model):
def __init__(self):
'''定义模型的层次'''
super().__init__()
self.hidden1 = keras.layers.Dense(32, activation = 'relu')
self.hidden2 = keras.layers.Dense(32, activation = 'relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
'''完成模型的正向传播'''
hidden1 = self.hidden1(input)
hidden2 = self.hidden2(hidden1)
# 拼接
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return output
'''定义实例对象'''
model = WideDeepModel()
model.build(input_shape = (None, 8))
# 配置
model.compile(loss = 'mse', optimizer = 'adam', metrics = ['mse'])
history = model.fit(x_train_scaled, y_train, validation_data = (x_valid_scaled, y_valid), epochs= 20)










![封装小程序request请求[接口函数]](https://img-blog.csdnimg.cn/ac0c1c93e1f440e087f50e13c240523a.png)