1 随机梯度下降法SGD

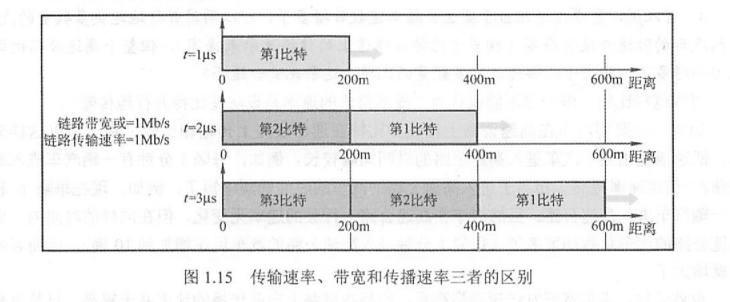
随机梯度下降法每次迭代取梯度下降最大的方向更新。这一方法实现简单,但是在很多函数中,梯度下降的方向不一定指向函数最低点,这使得梯度下降呈现“之”字形,其效率较低

class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
2 Momentum

momentum即动量。该方法设置变量v代表梯度下降的速度,其中dL/dW(梯度值)代表改变速度的“受力”,而α则作为“阻力”,限制v变化。该方法进行梯度下降可以类比一个小球在三维平面上滚动。
在下面的示例中,可以看到虽然迭代方向还是呈“之”字形,但是在x方向,虽然梯度较小,但是由于受力始终在一个方向,速度逐渐加快。在y方向,虽然梯度大,但上下受力相反,使得y方向不会有很大偏移

class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
在程序里一开始v设为None,在第一次调用update时会将v更新为和各权重形状一样的0矩阵
3 AdaGrad

AdaGrad的思路是根据上一轮迭代的变化量动态调整每一个权重的学习率。一个权重在迭代中变化量越大,其在下一轮中学习率就会减少更多。
在公式中,我们用h记录过去所有梯度的平方和(⊙代表矩阵元素相乘),在更新权重时之前变化较大的权重值变化量会变小。
由于h是不断累加的平方和,如果学习一直持续下去,W更新率会不断趋于0,要改善这一问题可以参考RMSProp,该方法会对较早更新的梯度逐渐“遗忘”,而更多反应新更新的状态
AdaGrad
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
在这里注意我们在h的每个元素中加上了微小的1e-7,这是为了防止h中有元素为0时,作为除数会报错。
RMSProp
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
RMSProp的方法和AdaGrad类似,除了每一轮迭代时会将h乘上一个decay_rate(大小在0-1)以减小之前梯度对h的影响

如图,一开始由于y方向梯度变化大,所以更新快,但因此y方向上学习率也减小较快,使得网络在后期逐渐沿x方向更新
Adam
Adam类似于momentum和AdaGrad两种方法的结合,其具体原理较为复杂,可以找原论文http://arxiv.org/abs/1412.6980v8
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
利用mnist数据集对几种训练方式进行比较:
在该测试程序中,我们使用5层神经网络,每层神经元个数100。利用SGD, momentum, AdaGrad, Adam, RMSProp分别进行2000次迭代,并比较最终各网络的总损失
# coding: utf-8
import os
import sys
sys.path.append("D:\AI learning source code") # 为了导入父目录的文件而进行的设定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *
# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1:进行实验的设置==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
optimizers['RMSprop'] = RMSprop()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(
input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
# 2:开始训练==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print( "===========" + "iteration:" + str(i) + "===========")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3.绘制图形==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D", "RMSprop": "v"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()
实验结果如下



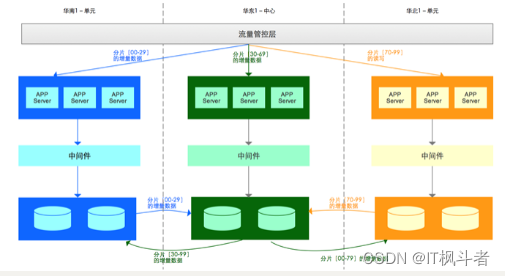




![封装小程序request请求[接口函数]](https://img-blog.csdnimg.cn/ac0c1c93e1f440e087f50e13c240523a.png)