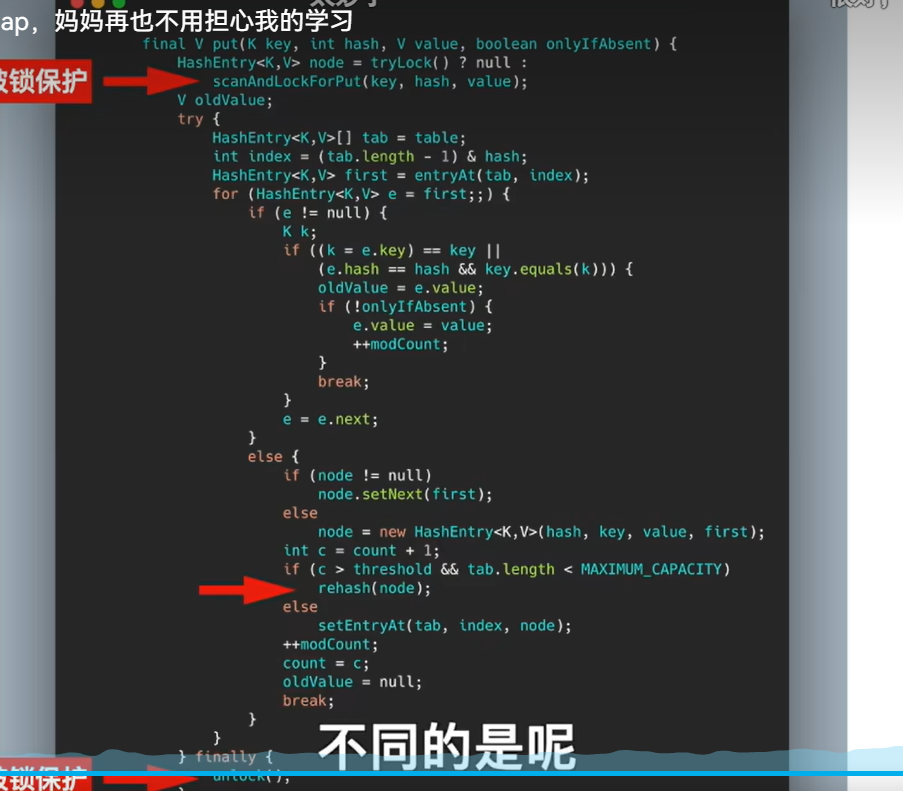
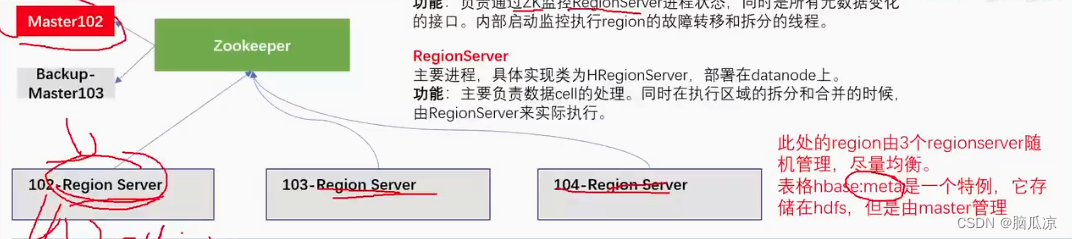
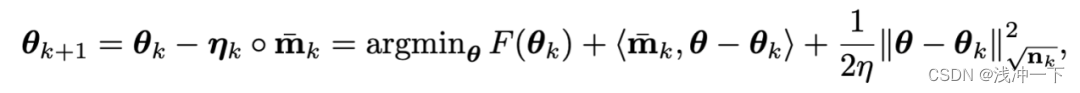- actor: 是policy network,通过生成动作概率分布,用来控制agent运动,类似“运动员”。
- critic: 是value network,用来给动作进行打分,类似“裁判”。
- 构造这两个网络,并通过environment奖励来学习这两个网络。
目录
1. Actor-Critic Introduction
1.1 review: state-value function approximation
1.2 Policy Network (Actor): π(a|s, θ)
1.3 Value Network (Critic): q(s, a; w)
2. Actor-Critic Algorithm
2.1 Train the networks
2.1.1 更新θ和w的目标是不同的
2.1.2 training process
2.2 update value network q using TD
2.3 update policy network π using policy gradient
2.4 summary of Algorithm
参考
1. Actor-Critic Introduction
1.1 review: state-value function approximation

π是policy function,可以用来计算动作的概率值,从而控制agent做运动。
Qπ是action-value function,可以用来评价动作的好坏程度。
可是π和Qπ这两个函数我们都不知道。
可以用两个神经网络分别近似这两个函数,然后用actor-critic method同时学习这两个神经网络。

--》
1.2 Policy Network (Actor): π(a|s, θ)

1.3 Value Network (Critic): q(s, a; w)
value network有两个输入:state s和action a。
最后输出一个实数q(s,a; w),这个分数说明--处在状态s下,做出动作a是好还是坏。

2. Actor-Critic Algorithm
同时训练policy network和value network,就是actor-critic method。
2.1 Train the networks

- θ是policy network的参数。
- w是value network的参数。
2.1.1 更新θ和w的目标是不同的

学习参数θ是为了让policy network预测更精准
critic是靠environment reward来改进自己的。
2.1.2 training process
对两个神经网络做一次更新需要经历5个步骤:

2.2 update value network q using TD

2.3 update policy network π using policy gradient
state-value function V(s; θ, w)相当于“运动员”所有动作的平均分 <--期望本质
梯度上升可以增加V函数的值

2.4 summary of Algorithm
Note that, agent在预测时,并没有执行这个动作。因为在算法的每一轮循环里面,agent只做一次动作。

用梯度上升来更新policy network,让运动员的平均分更高。
最后一步的qt * dθ,t是policy gradient 的monte-carlo approximation。
每一轮迭代都做这9个步骤,只做一次动作,观测一个奖励,更新一次神经网络的参数。
根据policy gradient algorithm的推导,算法用到了qt,这是critic给动作action打的分数。如果论文中把qt替换成了δt(TD error),这是policy gradient with baseline method,效果更好一点,它可以降低方差,让算法收敛更快,任何接近qt的数都可以作为baseline,但是这个baseline不能是动作at的函数,e.g.

参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html