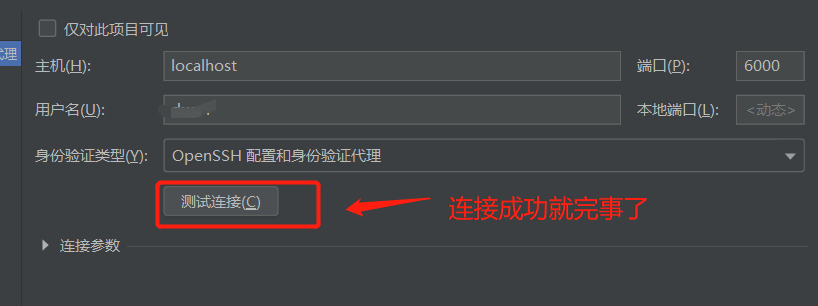
微博被称为中文版的 Twitter。
微博上的用户既可能有很多关注者,也可能关注很多其他用户。
因此,形成了一种基于这些关注关系的社交网络。
当用户在微博上发布帖子时,他/她的所有关注者都可以查看并转发他/她的帖子,然后这些人的关注者可以对内容再次转发…
现在给定一个社交网络,假设只考虑 L 层关注者,请你计算某些用户的帖子的最大可能转发量。
补充
如果 B 是 A 的关注者,C 是 B 的关注者,那么 A 的第一层关注者是 B,第二层关注者是 C。
输入格式
第一行包含两个整数,N 表示用户数量,L 表示需要考虑的关注者的层数。
假设,所有的用户的编号为 1∼N。
接下来 N 行,每行包含一个用户的关注信息,格式如下:
M[i] user_list[i]
M[i] 是第 i 名用户关注的总人数,user_list[i] 是第 i 名用户关注的 M[i] 个用户的编号列表。
最后一行首先包含一个整数 K,表示询问次数,然后包含 K 个用户编号,表示询问这些人的帖子的最大可能转发量。
输出格式
按顺序,每行输出一个被询问人的帖子最大可能转发量。
假设每名用户初次看到帖子时,都会转发帖子,只考虑 L 层关注者。
数据范围
1≤N≤1000
1≤L≤6
1≤M[i]≤100,
1≤K≤N
输入样例:
7 3
3 2 3 4
0
2 5 6
2 3 1
2 3 4
1 4
1 5
2 2 6
输出样例:
4
5
| 难度:中等 |
| 时/空限制:3s / 64MB |
| 总通过数:1184 |
| 总尝试数:2664 |
| 来源:PAT甲级真题1076 |
| 算法标签 |
认真读题
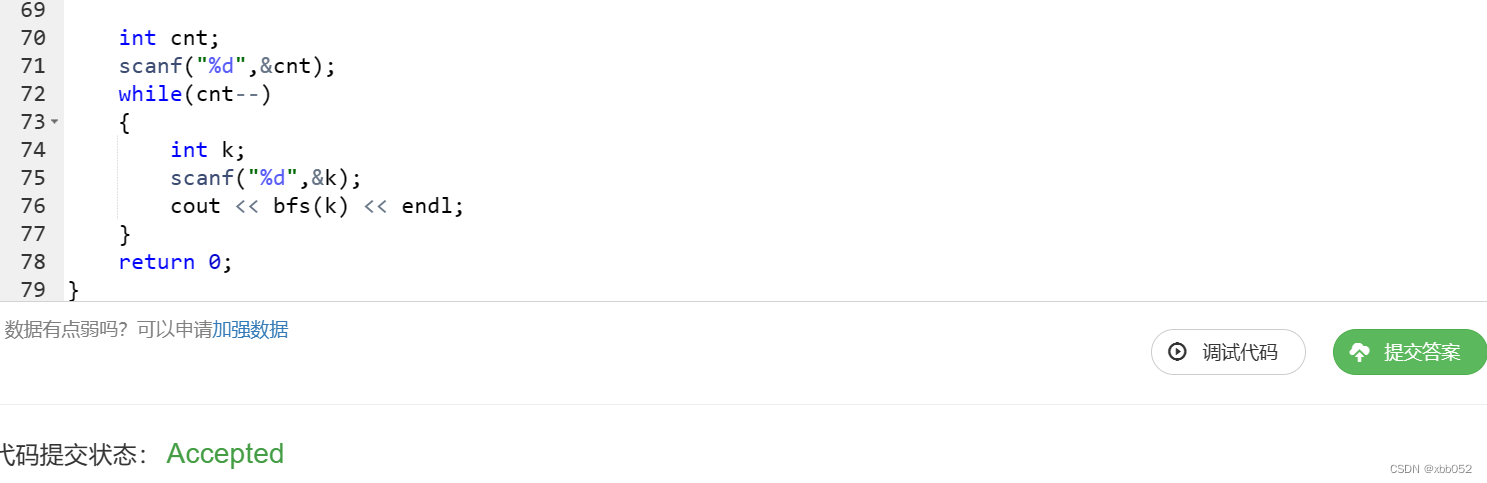
用到宽度优先搜索,以该点为根节点每次向下搜一层,即搜完该点的所有子树个数,一共搜索m层,难点在于如何实现只搜索m层?
可以预先声明一个变量sz,存储前三次搜索时入队的个数,即队列里面的元素个数,最后相加,
前三次搜索中第一次入队的是该点(根节点),意思是第m层只入队并没有出队,所以最后bfs返回的是res+q.size()-1.
一定要将判重的st数组首先memset,位置放到后面也会答案错误,这一点不清楚,懂的大佬可以解释一下