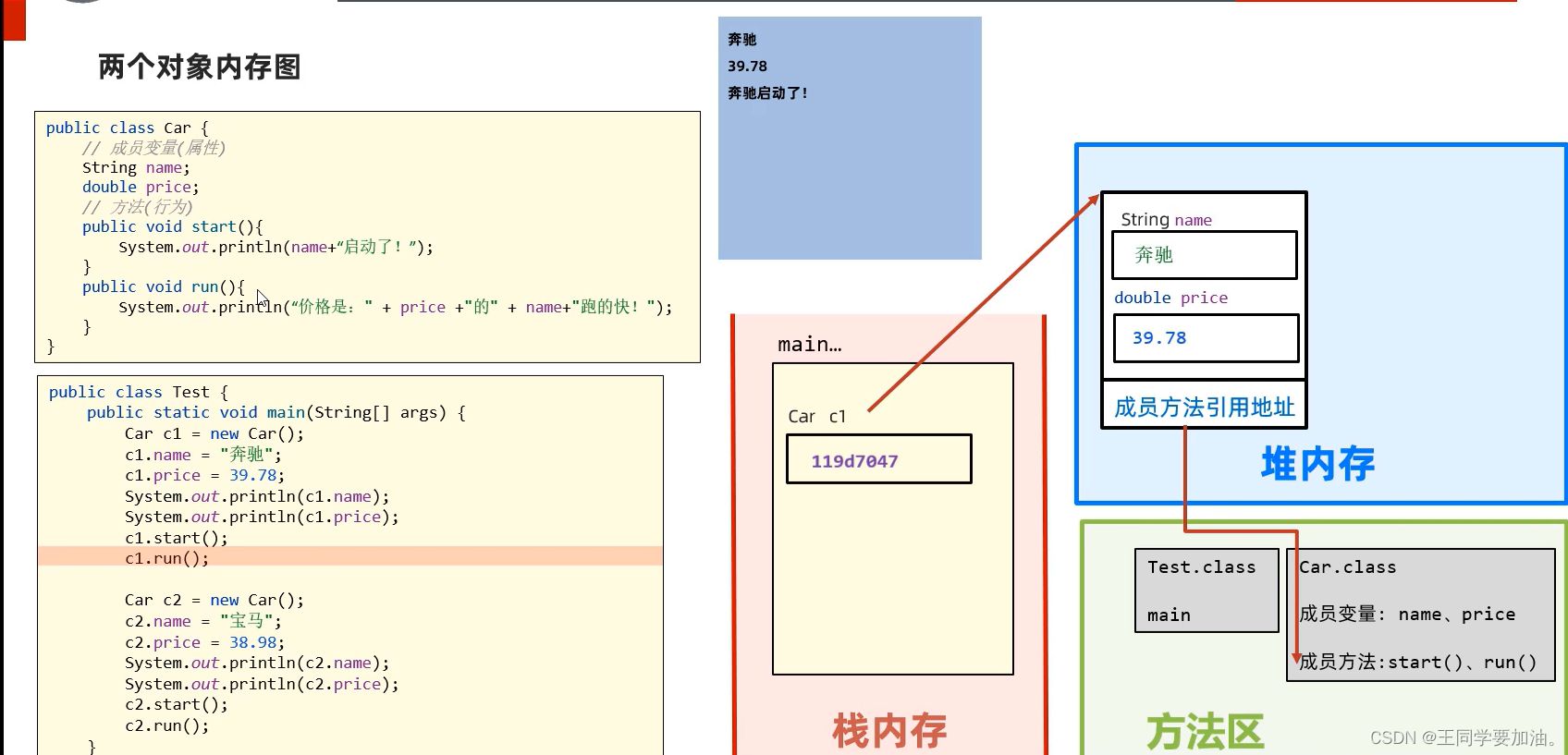
对于数据量很大的复杂系统,有时候会采用分库或者分表的减轻单台数据库服务器压力,截止目前有一些工具直接支持读写分离等,例如ShardingSphere,如果不采用工具框架,从编码出发,如何实现从多个数据库读写数据呢?本篇博客将介绍三种代码实现思路,并提供完整Demo。
方式一:将不同DB的操作存放到不同目录下来实现分库操作
通过该方式达到分库的操作,实际很简单,第一:在application.properties文件中通过不同的前缀区分不同的数据库,第二:为不同的database编写配置类,在配置类中定义了repository的目录,通过前缀创建不同的Database bean,第三,在不同的目录编写service,repository,controller.这样在不同controller调用service,service再调用repository时,因为不同的数据库配置的repository目录不同,故调用不同controller时,实际使用的是不同的数据库。这种实现思路,本质实现的目标是将不同的表放入不同Database中,并不是将相同的表放入不同的数据库,例如读写分离。完整代码可查看Demo1。

方式二:通过切面编程实现读写分离
实际业务场景中,为了提升数据库处理数据能力,可能需要进行读写分离,即同一张表,写操作在一个数据库,读操作在另外一个数据库,这两个数据库存放了相同的表数据。那如何编写代码实现这一目标呢?如下图所示,首先在application.properties文件中,通过不同的前缀来区分数据库,在配置文件类中定义不同DataSource bean,接着在切面代码中,如果方法是以find,select,query,search等开头,那么去查询slave数据库,否则从master数据库操作数据,这样就实现了读写分离。
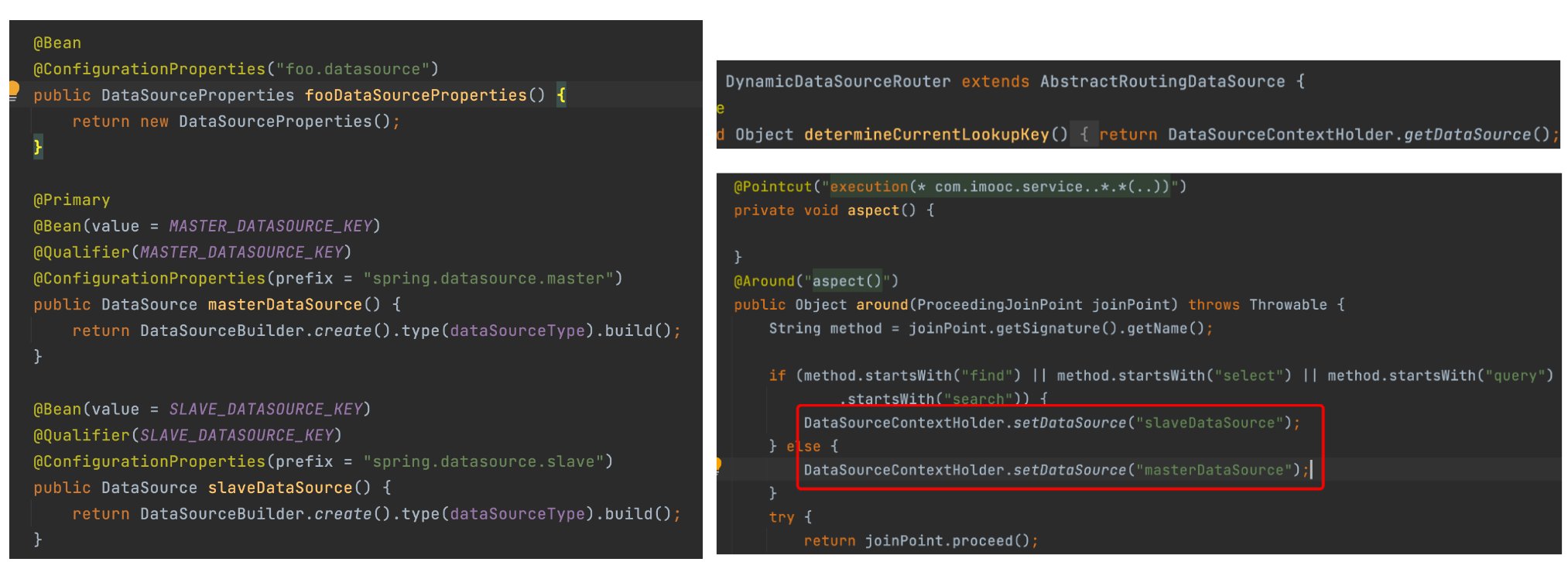
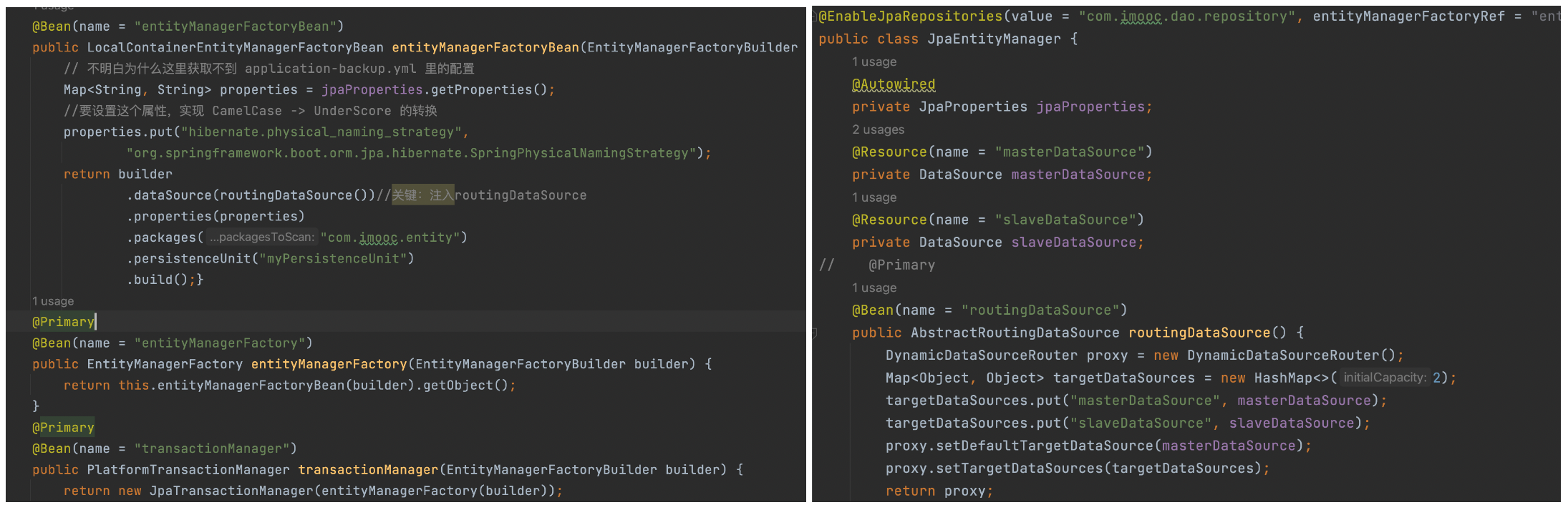
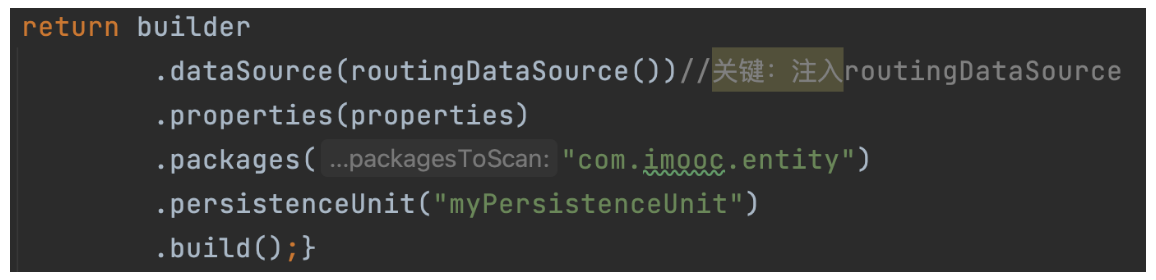
上面代码片段中本质是通过DataSourceContextHolder来切换数据库的?而DataSourceContextHolder本身只有一些get(),set()方法,背后是如何工作的呢?如下图代码所示,在定义EntityManagerFactoryBean的时候注入了routingDataSource,而RoutingDataSource默认会设置masterDataSource为默认的目标数据库,当通过DataSourceContextHolder重新设置目标数据库后,RoutingDataSource中的目标数据库会同步更新,而EntityManagerFactoryBean是通过routingDataSource构建出来的,所以,最终实现了不同数据库的切换操作。完整代码可查看Demo2。
方式三:通过切面编程实现分表
如下图所示,虽然都是通过切面编程的方式,但是这个切面是针对注解,当添加注解@SwithDataSource(value="xxdb")时,下面的repository都切换到了对应的数据库,右边图片是切面编程的部分代码,本质是调用AbstractRoutingDataSourceImpl.setDatabaseName(annotation.value())。
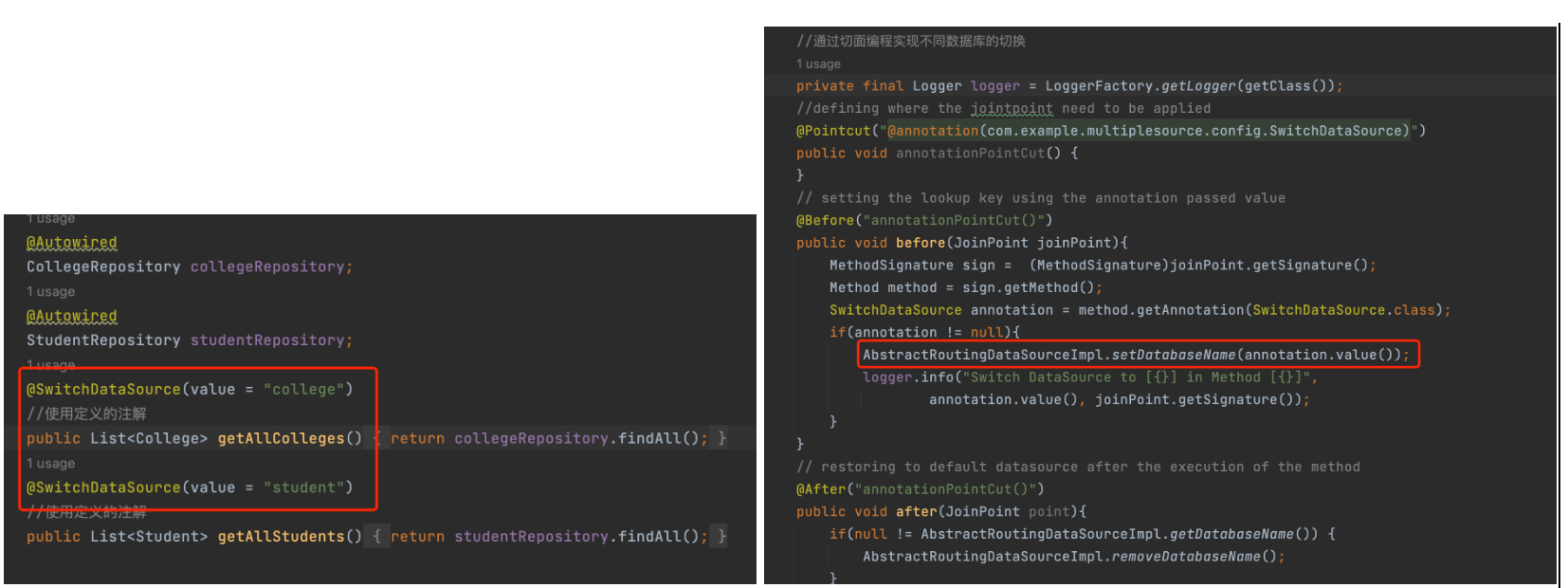
那AbstractRoutingDataSourceImpl是如何实现数据库切换的呢?查看AbstractRoutingDataSourceImpl的代码,overwrite中只有一些get(),set()方法。接着查看定义entityManagerFactoryBean的class,在这个class中定义了entityManagerFactoryBean,dataSource()这个bean中设置了默认default的database,当设置新的database后,完成数据库的切换。完整代码细节可查看demo3.


从前面的三个例子看,使用多个数据源时,Entity和Repository不用修改。只要设置好@EnableJpaRepositories,就能让Repository找到正确的数据源,自动装配。其中主要的两个参数是创建Entity的entityManagerFactoryRef和创建Repository的transactionManagerRef。为了创建EntityManagerFactory,我们需要借助DataSourceProperties创建DataSource对象。而使用@ConfigurationProperties,可以自动从配置文件生成DataSourceProperties。创建TransactionManager则需要指定SQL方言。方言类名可以通过Environment从配置中读取。从上面例子中可以看到,都是通过EntityManagerFactoryBuilder创建了LocalContainerEntityManagerFactoryBean,那LocalContainerEntityManagerFactoryBean的作用是什么呢?实际JPA 定义了两种类型的实体管理器:
应用程序管理类型(Application-managed):当应用程序向实体管理器工厂直接请求实体管理器时,工厂会创建一个实体管理器。在这种模式下,程序要负责打开或关闭实体管理器并在事务中对其进行控制。这种方式的实体管理器适合于不运行在 Java EE 容器中的独立应用程序。
容器管理类型(Container-managed):实体管理器由 Java EE 创建和管理。应用程序根本不与实体管理器工厂打交道。相反,实体管理器直接通过注入或 JNDI 来获取。容器负责配置实体管理器工厂。这种类型的实体管理器最适用于 Java EE 容器,在这种情况下会希望在 persistence.xml 指定的 JPA 配置之外保持一些自己对 JPA 的控制。
这对想使用 JPA 的 Spring 开发者来说又意味着什么呢?其实这并没太大的关系。不管你希望使用哪种 EntityManagerFactory,Spring 都会负责管理 EntityManager。如果你使用的是应用程序管理类型的实体管理器,Spring 承担了应用程序的角色并以透明的方式处理 EntityManager。在容器管理的场景下,Spring 会担当容器的角色。这两种实体管理器工厂分别由对应的 Spring 工厂 Bean 创建:
LocalEntityManagerFactoryBean 生成应用程序管理类型的 EntityManagerFactory;
LocalContainerEntityManagerFactoryBean 生成容器管理类型的 EntityManagerFactory。
EntityManagerFactoryBuilder采用构造者模式,传说数据库连接相关信息,即可完成对数据库的访问。
实现数据源切换用到了AbstractRoutingDataSource,该class包含的常见的属性以及含义如下:
targetDataSources是目标数据源集合
defaultTargetDataSource是默认数据源
resolvedDataSources是解析后的数据源集合
resolvedDefaultDataSource是解析后的默认数据源
要实现数据源切换,实际是自定义一个类扩展AbstractRoutingDataSource抽象类,相当于数据源DataSourcer的路由中介,可以实现在项目运行时根据相应key值切换到对应的数据源DataSource上。先看看AbstractRoutingDataSource的源码:
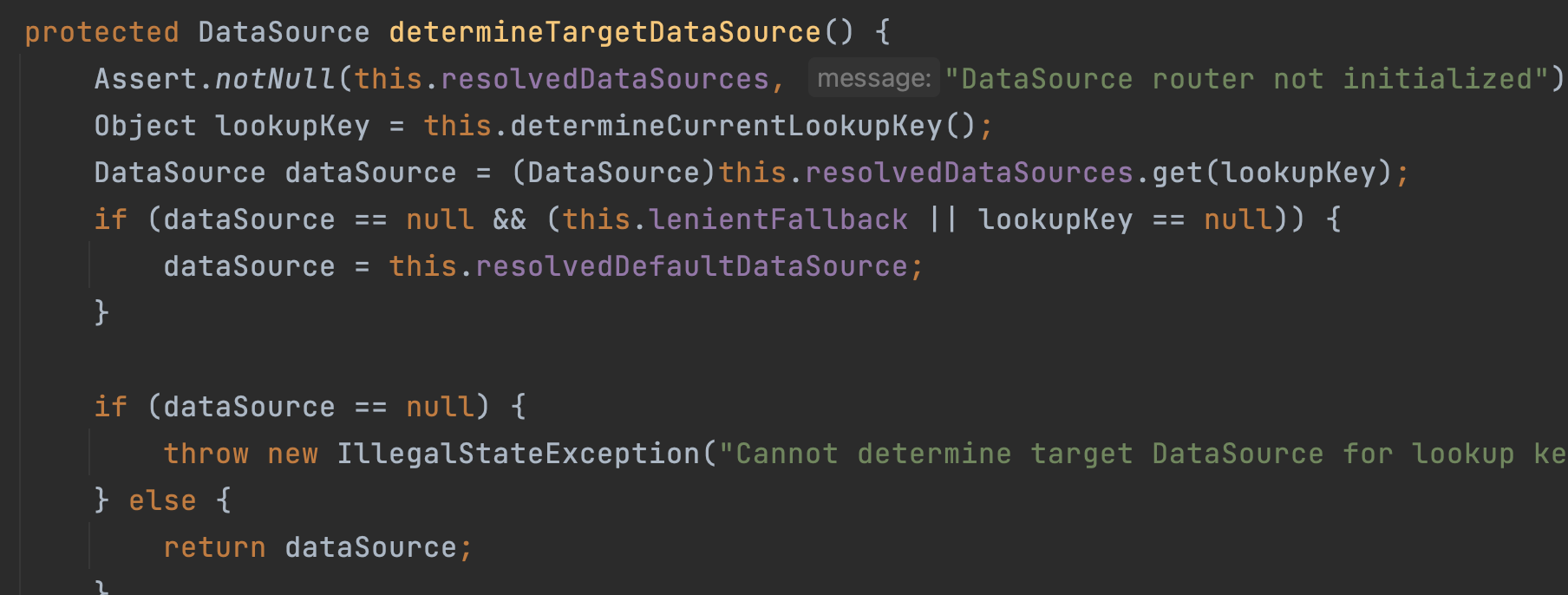
从源码可以看出AbstractRoutingDataSource继承了AbstractDataSource并实现了InitializingBean,AbstractRoutingDataSource的getConnection()方法调用了determineTargetDataSource()的该方法,这里重点看determineTargetDataSource()方法代码,方法里使用到了determineCurrentLookupKey()方法,它是AbstractRoutingDataSource类的抽象方法,也是实现数据源切换要扩展的方法,该方法的返回值就是项目中所要用的DataSource的key值,拿到该key后就可以在resolvedDataSource中取出对应的DataSource,如果key找不到对应的DataSource就使用默认的数据源。
自定义类扩展AbstractRoutingDataSource类时就是要重写determineCurrentLookupKey()方法来实现数据源切换功能,具体代码如下所示:

以上就是对于多数据库切换的介绍。