目录
- 背景
- 常用分布式ID生成系统介绍
- UUID
- Snowflake
背景
在大多数复杂的分布式系统中,往往需要对大量的数据和消息进行唯一标识。而对分布式系统后台数据库的分库分表后需要有一个唯一的ID来表示一条数据或者是消息。那么我们分布式系统ID一般都有哪些需求呢?
- 全局唯一性:唯一标识。
- 趋势递增:由于绝大多数关系型DBMS使用B+Tree的数据结构来存储索引数据,在主键的选择中我们应该尽量要选择有序的主键来保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,这个和上面的趋势递增差不多,又具有区别。
- 信息安全:如果ID是连续的,那么恶意用户爬取工作就非常容易做了。所以在一些应用场景下,会需要ID不规则、无规则。
上述的第三点和第四点我们无法在同时满足,因为他们是互斥的。
除了对ID自身的要求之外,我们的业务还是对我们ID的生成系统有较高的要求,我们可以想象一下,如果我们的ID生成系统瘫痪,那么我们整个系统的,订单、支付、结账等业务都无法进行,那么结果我们可想而知。
所以一个好的分布式ID生成系统还需要有以下几点要求:
-
QPS要高
-
保证HA。
-
平均延迟要尽可能低。
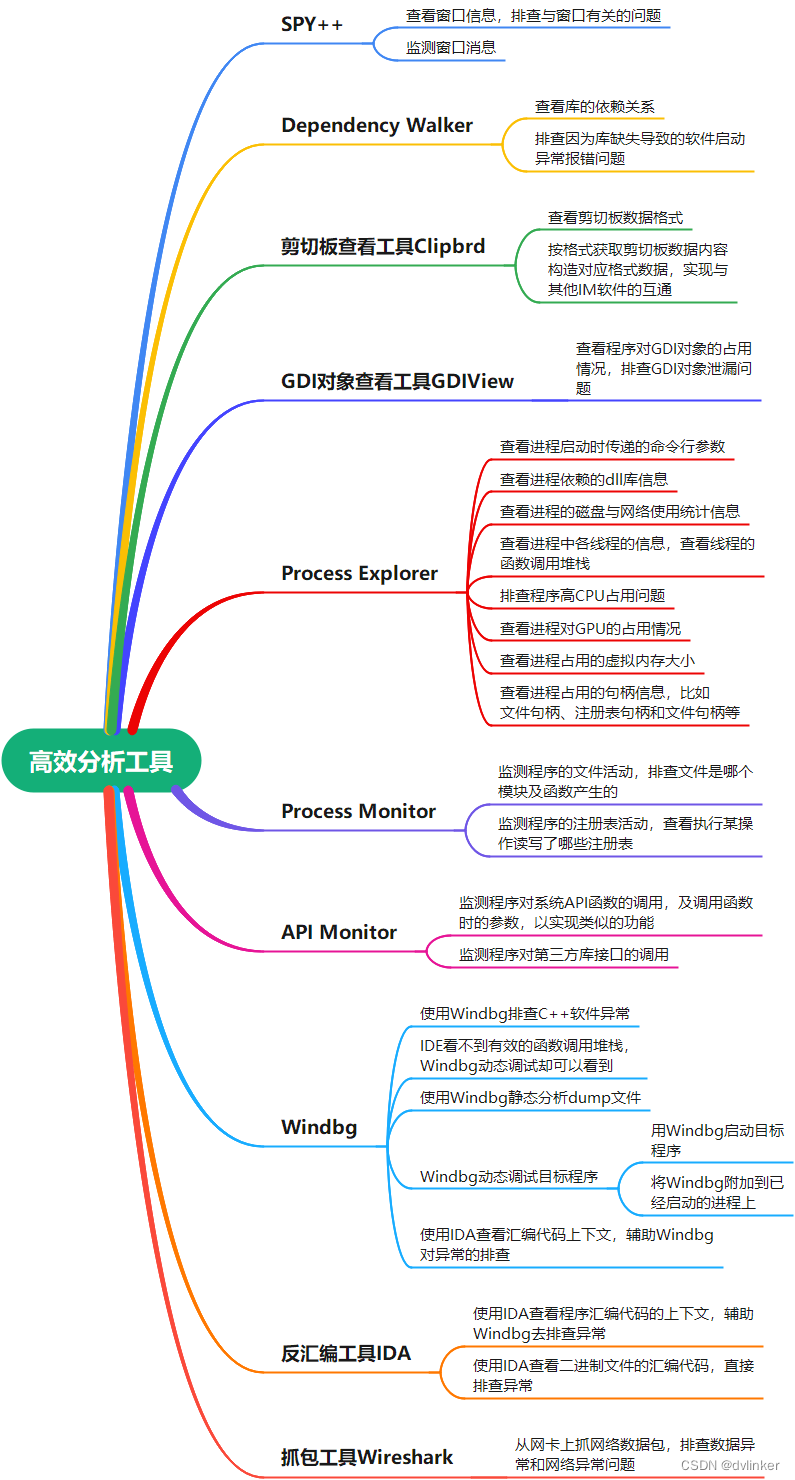
常用分布式ID生成系统介绍
UUID
UUID包含32个16进制数字,以连字符分为5段,形式是8-4-4-4-12的36个字符,如:550e8400-e29b-41d4-a716-446655440000。
UUID的优点
- 因为是在本地生成的,所以性能较高。
UUID缺点
1)浪费存储空间:UUID能保证全局唯一,但是需要36个字符的长度,浪费了不少的存储空间。
2)信息不安全:基于MAC地址生成的UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒作者的位置。
3)UUID非常不适用于主键ID:(我们就以MySQL为例)
(1)MySQL官网有明确主键越短越好,而UUID占用36个字符的长度,显然不符合要求。
在MYSQL官网中有如下说明:除了主键索引之外的非主键索引都属于二级索引。在InooDB中,二级索引中的每条记录都包含该行的主键列,以及二级索引所指定的列,所以如果主键的很长,二级索引会占用更多空间。
(2)对索引不利,UUID是无序的,在InnoDB下,UUID的无序可能会引起数据位置的频繁变动,严重影响性能。
Snowflake
Snowflake雪花算法,把64-bit划分为多段,其中包含 41-bit 时间戳、10-bit 工作机器、12-bit 序列号、1-bit不用。如果对IDC有要求(IDC表示互联网数据中心,可以指特点的设备网络),那么可以将10-bit的工作机器分5-bit给IDC。雪花算法这种分配方案可以保证在任何一台机器上任意毫秒内生成的ID都是不同的。
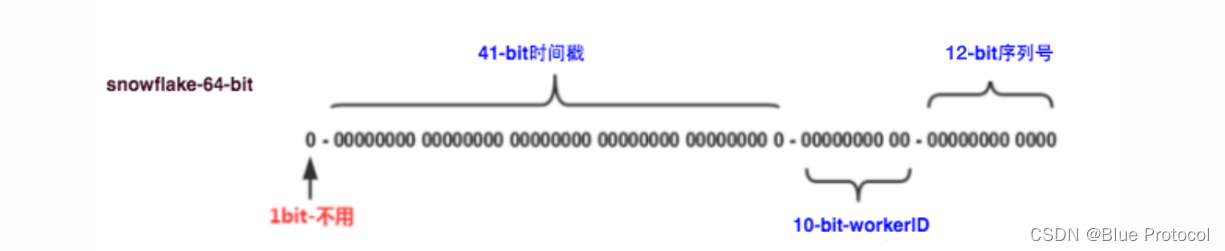
Snowflake的优点
- 时间戳在高位、序列号在低位,整个ID是趋势递增的。
- 可以根据业务来分配bit位,比较灵活。
- 不依赖于第三方系统,稳定性高,生成ID的性能也高。
Snowflake缺点
依赖于机器的时钟,如果机器时钟回拨,那么可能会出现ID重复的情况。
其他的分布式ID生成系统可能在之后会继续更新,此次先简述UUID和Snowflake。