compose
题目描述:实现一个 compose 函数
// 用法如下:
function fn1(x) {
return x + 1;
}
function fn2(x) {
return x + 2;
}
function fn3(x) {
return x + 3;
}
function fn4(x) {
return x + 4;
}
const a = compose(fn1, fn2, fn3, fn4);
console.log(a(1)); // 1+4+3+2+1=11
实现代码如下:
function compose(...fn) {
if (!fn.length) return (v) => v;
if (fn.length === 1) return fn[0];
return fn.reduce(
(pre, cur) =>
(...args) =>
pre(cur(...args))
);
}
如何判断一个对象是否属于某个类?
- 第一种方式,使用 instanceof 运算符来判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
- 第二种方式,通过对象的 constructor 属性来判断,对象的 constructor 属性指向该对象的构造函数,但是这种方式不是很安全,因为 constructor 属性可以被改写。
- 第三种方式,如果需要判断的是某个内置的引用类型的话,可以使用 Object.prototype.toString() 方法来打印对象的[[Class]] 属性来进行判断。
缓存机制
1. 首先得明确 http 缓存的好处
- 减少了冗余的数据传输,减少网费
- 减少服务器端的压力
Web缓存能够减少延迟与网络阻塞,进而减少显示某个资源所用的时间- 加快客户端加载网页的速度
2. 常见 http 缓存的类型
- 私有缓存(一般为本地浏览器缓存)
- 代理缓存
3. 然后谈谈本地缓存
本地缓存是指浏览器请求资源时命中了浏览器本地的缓存资源,浏览器并不会发送真正的请求给服务器了。它的执行过程是
- 第一次浏览器发送请求给服务器时,此时浏览器还没有本地缓存副本,服务器返回资源给浏览器,响应码是
200 OK,浏览器收到资源后,把资源和对应的响应头一起缓存下来 - 第二次浏览器准备发送请求给服务器时候,浏览器会先检查上一次服务端返回的响应头信息中的
Cache-Control,它的值是一个相对值,单位为秒,表示资源在客户端缓存的最大有效期,过期时间为第一次请求的时间减去Cache-Control的值,过期时间跟当前的请求时间比较,如果本地缓存资源没过期,那么命中缓存,不再请求服务器 - 如果没有命中,浏览器就会把请求发送给服务器,进入缓存协商阶段。
与本地缓存相关的头有:
Cache-Control、Expires,Cache-Control有多个可选值代表不同的意义,而Expires就是一个日期格式的绝对值。
3.1 Cache-Control
Cache-Control是HTPP缓存策略中最重要的头,它是HTTP/1.1中出现的,它由如下几个值
no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。max-age:从当前请求开始,允许获取的响应被重用的最长时间(秒)。must-revalidate,当缓存过期时,需要去服务端校验缓存的有效性。
Cache-Control: public, max-age=1000
注意,虽然你可能在其他资料中看到可以使用 meta 标签来设置缓存,比如像下面的形式:
<meta http-equiv="expires" content="Wed, 20 Jun 2021 22:33:00 GMT"
但在 HTML5 规范中,并不支持这种方式,所以尽量不要使用 meta 标签来设置缓存。
3.2 Expires
Expires是HTTP/1.0出现的头信息,同样是用于决定本地缓存策略的头,它是一个绝对时间,时间格式是如Mon, 10 Jun 2015 21:31:12 GMT,只要发送请求时间是在Expires之前,那么本地缓存始终有效,否则就会去服务器发送请求获取新的资源。如果同时出现Cache-Control:max-age和Expires,那么max-age优先级更高。他们可以这样组合使用
Cache-Control: public
Expires: Wed, Jan 10 2018 00:27:04 GMT
3.3 所谓的缓存协商
当第一次请求时服务器返回的响应头中存在以下情况时
- 没有
Cache-Control和Expires Cache-Control和Expires过期了Cache-Control的属性设置为no-cache时
那么浏览器第二次请求时就会与服务器进行协商,询问浏览器中的缓存资源是不是旧版本,需不需要更新,此时,服务器就会做出判断,如果缓存和服务端资源的最新版本是一致的,那么就无需再次下载该资源,服务端直接返回
304 Not Modified状态码,如果服务器发现浏览器中的缓存已经是旧版本了,那么服务器就会把最新资源的完整内容返回给浏览器,状态码就是200 Ok,那么服务端是根据什么来判断浏览器的缓存是不是最新的呢?其实是根据HTTP的另外两组头信息,分别是:Last-Modified/If-Modified-Since与ETag/If-None-Match。
Last-Modified 与 If-Modified-Since
具体工作流程如下:
- 浏览器第一次请求资源时,服务器会把资源的最新修改时间
Last-Modified:Thu, 29 Dec 2011 18:23:55 GMT放在响应头中返回给浏览器 - 第二次请求时,浏览器就会把上一次服务器返回的修改时间放在请求头
If-Modified-Since:Thu, 29 Dec 2011 18:23:55发送给服务器,服务器就会拿这个时间跟服务器上的资源的最新修改时间进行对比 - 服务端再次收到请求,根据请求头
If-Modified-Since的值,判断相关资源是否有变化,如果没有,则返回304 Not Modified,并且不返回资源内容,浏览器使用资源缓存值;否则正常返回资源内容,且更新Last-Modified响应头内容。
如果两者相等或者大于服务器上的最新修改时间,那么表示浏览器的缓存是有效的,此时缓存会命中,服务器就不再返回内容给浏览器了,同时
Last-Modified头也不会返回,因为资源没被修改,返回了也没什么意义。如果没命中缓存则最新修改的资源连同Last-Modified头一起返回
这种方式虽然能判断缓存是否失效,但也存在两个问题:
- 精度问题 ,
Last-Modified的时间精度为秒,如果在1秒内发生修改,那么缓存判断可能会失效; - 准度问题 ,考虑这样一种情况,如果一个文件被修改,然后又被还原,内容并没有发生变化,在这种情况下,浏览器的缓存还可以继续使用,但因为修改时间发生变化,也会重新返回重复的内容。
Expires: Fri, Jan 12 2018 00:27:04 GMT
Last-Modified: Wed, Jan 10 2018 00:27:04 GMT
这组头信息是基于资源的修改时间来判断资源有没有更新,另一种方式就是根据资源的内容来判断,就是接下来要讨论的
ETag与If-None-Match
ETag与If-None-Match
为了解决精度问题和准度问题,HTTP 提供了另一种不依赖于修改时间,而依赖于文件哈希值的精确判断缓存的方式,那就是响应头部字段 ETag 和请求头部字段 If-None-Match。
ETag/If-None-Match与Last-Modified/If-Modified-Since的流程其实是类似的,唯一的区别是它基于资源的内容的摘要信息(比如MD5 hash)来判断
浏览器发送第二次请求时,会把第一次的响应头信息
ETag的值放在If-None-Match的请求头中发送到服务器,与最新的资源的摘要信息对比,如果相等,取浏览器缓存,否则内容有更新,最新的资源连同最新的摘要信息返回。用ETag的好处是如果因为某种原因到时资源的修改时间没改变,那么用ETag就能区分资源是不是有被更新。
具体工作流程如下:
- 浏览器第一次请求资源,服务端在返响应头中加入
Etag字段,Etag字段值为该资源的哈希值 - 当浏览器再次跟服务端请求这个资源时,在请求头上加上
If-None-Match,值为之前响应头部字段ETag的值; - 服务端再次收到请求,将请求头
If-None-Match字段的值和响应资源的哈希值进行比对,如果两个值相同,则说明资源没有变化,返回304 Not Modified;否则就正常返回资源内容,无论是否发生变化,都会将计算出的哈希值放入响应头部的ETag字段中
这种缓存比较的方式也会存在一些问题,具体表现在以下两个方面。
- 计算成本 。生成哈希值相对于读取文件修改时间而言是一个开销比较大的操作,尤其是对于大文件而言。如果要精确计算则需读取完整的文件内容,如果从性能方面考虑,只读取文件部分内容,又容易判断出错。
- 计算误差 。HTTP 并没有规定哈希值的计算方法,所以不同服务端可能会采用不同的哈希值计算方式。这样带来的问题是,同一个资源,在两台服务端产生的 Etag 可能是不相同的,所以对于使用服务器集群来处理请求的网站来说,使用 Etag 的缓存命中率会有所降低。
需要注意的是,
强制缓存的优先级高于协商缓存,在协商缓存中,Etag 优先级比 Last-Modified高
Cache-Control: public, max-age=31536000
ETag: "15f0fff99ed5aae4edffdd6496d7131f"
If-None-Match: "15f0fff99ed5aae4edffdd6496d7131f"
缓存位置
浏览器缓存的位置的话,可以分为四种,优先级从高到低排列分别👇
Service WorkerMemory CacheDisk CachePush Cache
Service Worker
这个应用场景比如PWA,它借鉴了Web Worker思路,由于它脱离了浏览器的窗体,因此无法直接访问DOM。它能完成的功能比如:
离线缓存、消息推送和网络代理,其中离线缓存就是 Service Worker Cache 。
Memory Cache
指的是内存缓存,从效率上讲它是最快的,从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache
存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,优势在于存储容量和存储时长。
Disk Cache VS Memory Cache
两者对比,主要的策略👇
- 内容使用率高的话,文件优先进入磁盘
- 比较大的JS,CSS文件会直接放入磁盘,反之放入内存。
Push Cache
推送缓存,这算是浏览器中最后一道防线吧,它是
HTTP/2的内容
浏览器缓存总结
浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流程如下
- 先根据这个资源的一些 http header 判断它是否命中强缓存,先检查
Cache-Control,如果命中,则直接从本地获取缓存资源,不会发请求到服务器; - 当强缓存没有命中时,客户端会发送请求到服务器,服务器通过另一些request header验证这个资源是否命中协商缓存,称为http再验证,如果命中,服务器将请求返回,但不返回资源,而是返回304告诉客户端直接从缓存中获取,客户端收到返回后就会从缓存中获取资源;(服务器通过请求头中的
If-Modified-Since或者If-None-Match字段检查资源是否更新) - 强缓存和协商缓存共同之处在于,如果命中缓存,服务器都不会返回资源; 区别是,强缓存不对发送请求到服务器,但协商缓存会。
- 当协商缓存也没命中时,服务器就会将资源发送回客户端。
- 当 ctrl+f5 强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存;
- 当 f5刷新网页时,跳过强缓存,但是会检查协商缓存;
强缓存
- Expires(该字段是 http1.0 时的规范,值为一个绝对时间的 GMT 格式的时间字符串,代表缓存资源的过期时间)
- Cache-Control:max-age(该字段是 http1.1的规范,强缓存利用其 max-age 值来判断缓存资源的最大生命周期,它的值单位为秒)
协商缓
- Last-Modified(值为资源最后更新时间,随服务器response返回,即使文件改回去,日期也会变化)
- If-Modified-Since(通过比较两个时间来判断资源在两次请求期间是否有过修改,如果没有修改,则命中协商缓存)
- ETag(表示资源内容的唯一标识,随服务器response返回,仅根据文件内容是否变化判断)
- If-None-Match(服务器通过比较请求头部的If-None-Match与当前资源的ETag是否一致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存)
受控组件和非受控组件
<FInput value = {x} onChange = {fn} />
// 上面的是受控组件 下面的是非受控组件
<FInput defaultValue = {x} />
- 当你一个组件同时传递一个value以及onChange事件时,它就是一个受控组件,收入输出都是我来控制的。
- 第二个只是传递了默认的初时值,并没有传onchange事件,
- 非受控组件是一种反模式,它的值不受组件自身的state或props控制
介绍一下Rollup
Rollup 是一款 ES Modules 打包器。它也可以将项目中散落的细小模块打包为整块代码,从而使得这些划分的模块可以更好地运行在浏览器环境或者 Node.js 环境。
Rollup优势:
- 输出结果更加扁平,执行效率更高;
- 自动移除未引用代码;
- 打包结果依然完全可读。
缺点
- 加载非 ESM 的第三方模块比较复杂;
- 因为模块最终都被打包到全局中,所以无法实现
HMR; - 浏览器环境中,代码拆分功能必须使用
Require.js这样的AMD库
- 我们发现如果我们开发的是一个应用程序,需要大量引用第三方模块,同时还需要 HMR 提升开发体验,而且应用过大就必须要分包。那这些需求 Rollup 都无法满足。
- 如果我们是开发一个 JavaScript 框架或者库,那这些优点就特别有必要,而缺点呢几乎也都可以忽略,所以在很多像 React 或者 Vue 之类的框架中都是使用的 Rollup 作为模块打包器,而并非 Webpack
总结一下 :Webpack 大而全,Rollup 小而美。
在对它们的选择上,我的基本原则是:应用开发使用 Webpack,类库或者框架开发使用 Rollup。
不过这并不是绝对的标准,只是经验法则。因为 Rollup 也可用于构建绝大多数应用程序,而 Webpack 同样也可以构建类库或者框架。

computed 的实现原理
computed本质是一个惰性求值的观察者computed watcher。其内部通过this.dirty属性标记计算属性是否需要重新求值。
- 当 computed 的依赖状态发生改变时,就会通知这个惰性的 watcher,
computed watcher通过this.dep.subs.length判断有没有订阅者, - 有的话,会重新计算,然后对比新旧值,如果变化了,会重新渲染。 (Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性
最终计算的值发生变化时才会触发渲染 watcher重新渲染,本质上是一种优化。) - 没有的话,仅仅把
this.dirty = true(当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备 lazy(懒计算)特性。)
参考 前端进阶面试题详细解答
工程化
介绍一下 webpack 的构建流程
核心概念
entry:入口。webpack是基于模块的,使用webpack首先需要指定模块解析入口(entry),webpack从入口开始根据模块间依赖关系递归解析和处理所有资源文件。output:输出。源代码经过webpack处理之后的最终产物。loader:模块转换器。本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。plugin:扩展插件。基于事件流框架Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。module:模块。除了js范畴内的es module、commonJs、AMD等,css @import、url(...)、图片、字体等在webpack中都被视为模块。
解释几个 webpack 中的术语
module:指在模块化编程中我们把应用程序分割成的独立功能的代码模块chunk:指模块间按照引用关系组合成的代码块,一个chunk中可以包含多个modulechunk group:指通过配置入口点(entry point)区分的块组,一个chunk group中可包含一到多个 chunkbundling:webpack 打包的过程asset/bundle:打包产物
webpack 的打包思想可以简化为 3 点:
- 一切源代码文件均可通过各种
Loader转换为 JS 模块 (module),模块之间可以互相引用。 - webpack 通过入口点(
entry point)递归处理各模块引用关系,最后输出为一个或多个产物包js(bundle)文件。 - 每一个入口点都是一个块组(
chunk group),在不考虑分包的情况下,一个chunk group中只有一个chunk,该 chunk 包含递归分析后的所有模块。每一个chunk都有对应的一个打包后的输出文件(asset/bundle)
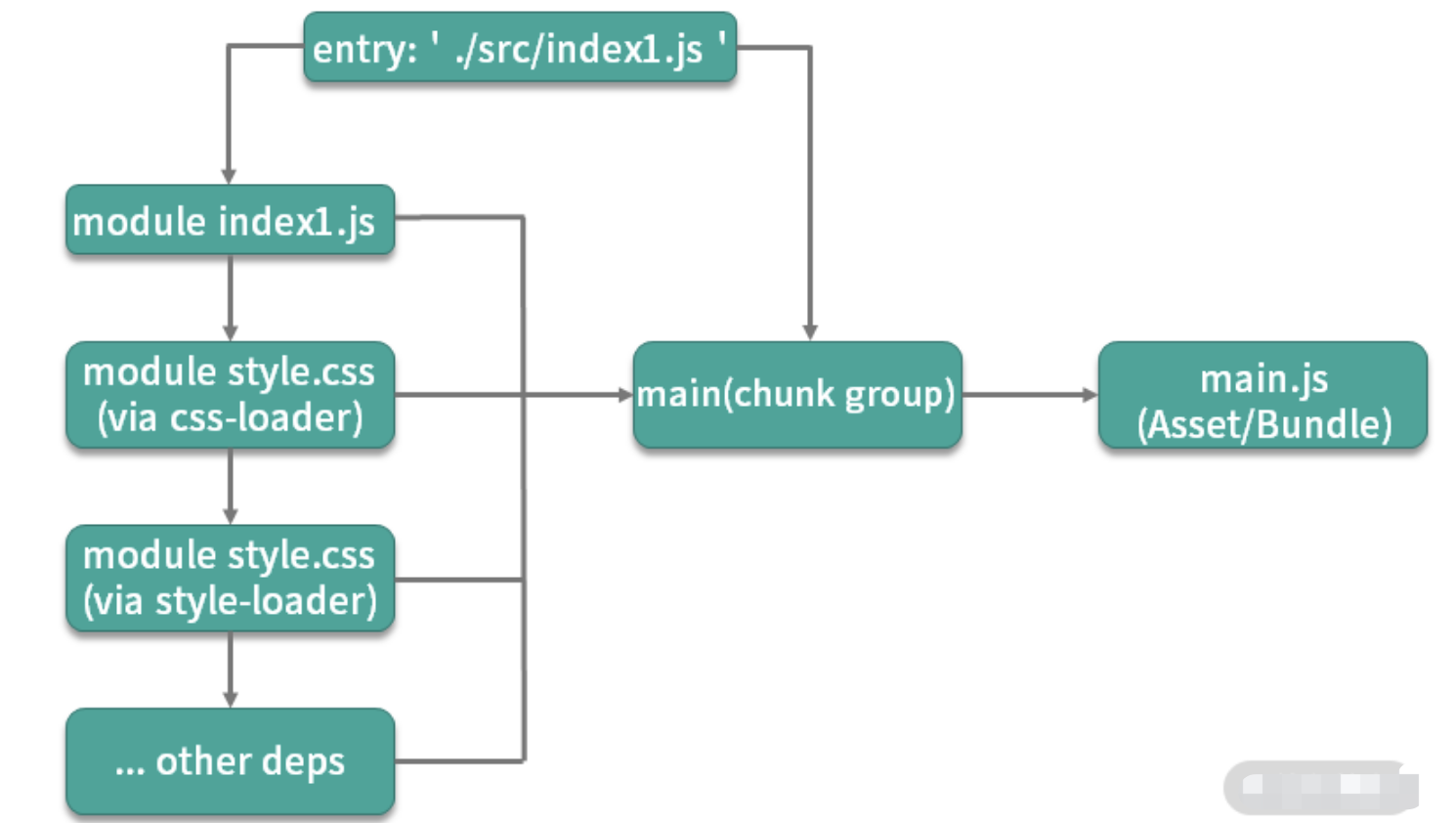
打包流程
- 初始化参数:从配置文件和 Shell 语句中读取并合并参数,得出最终的配置参数。
- 开始编译:从上一步得到的参数初始化
Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译。 - 确定入口:根据配置中的
entry找出所有的入口文件。 - 编译模块:从入口文件出发,调用所有配置的
loader对模块进行翻译,再找出该模块依赖的模块,这个步骤是递归执行的,直至所有入口依赖的模块文件都经过本步骤的处理。 - 完成模块编译:经过第 4 步使用 loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。
- 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
chunk,再把每个chunk转换成一个单独的文件加入到输出列表,这一步是可以修改输出内容的最后机会。 - 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
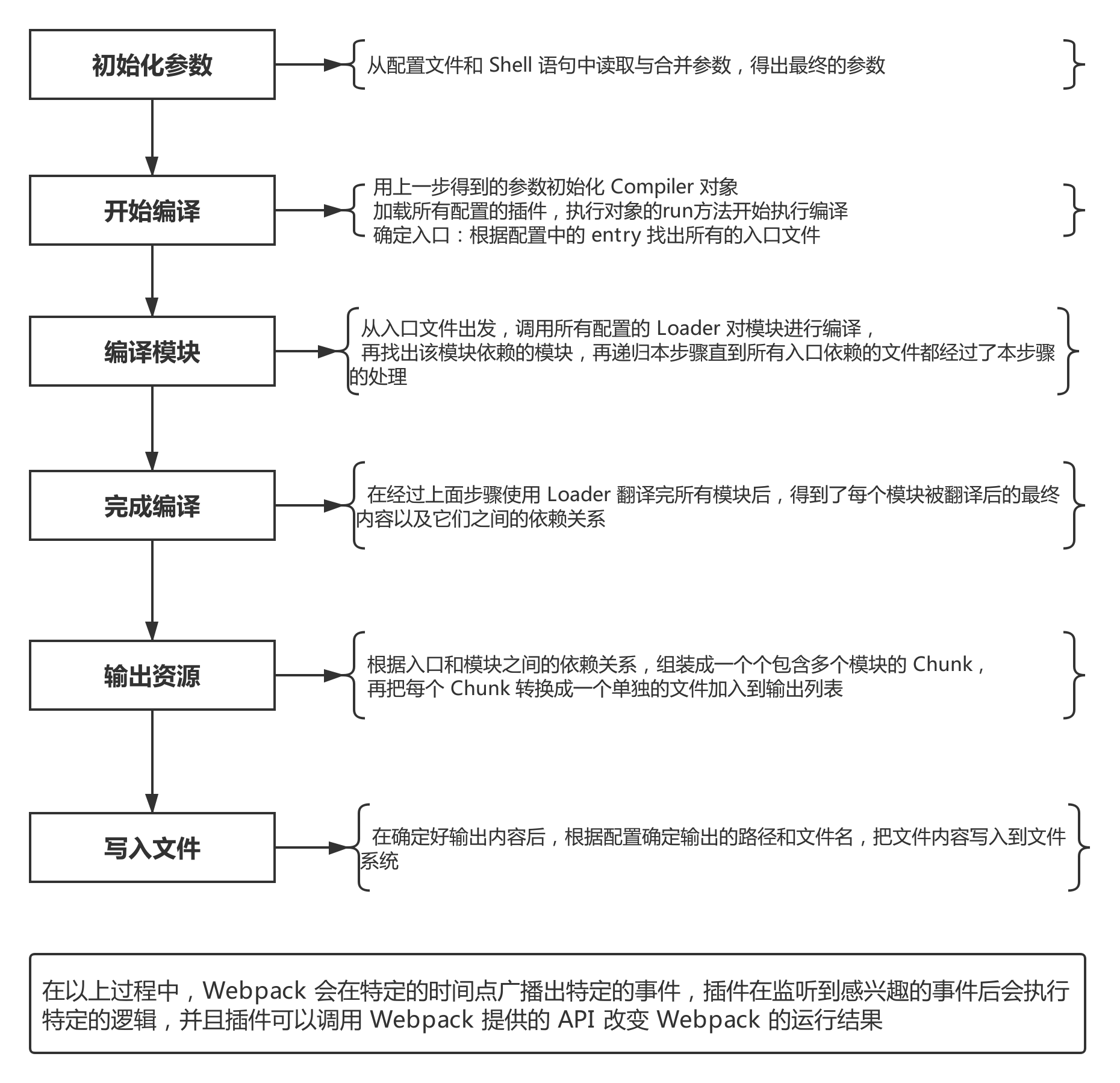
简版
- Webpack CLI 启动打包流程;
- 载入 Webpack 核心模块,创建
Compiler对象; - 使用
Compiler对象开始编译整个项目; - 从入口文件开始,解析模块依赖,形成依赖关系树;
- 递归依赖树,将每个模块交给对应的 Loader 处理;
- 合并 Loader 处理完的结果,将打包结果输出到 dist 目录。
在以上过程中,
Webpack 会在特定的时间点广播出特定的事件,插件在监听到相关事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果
构建流程核心概念:
Tapable:一个基于发布订阅的事件流工具类,Compiler和Compilation对象都继承于TapableCompiler:compiler对象是一个全局单例,他负责把控整个webpack打包的构建流程。在编译初始化阶段被创建的全局单例,包含完整配置信息、loaders、plugins以及各种工具方法Compilation:代表一次 webpack 构建和生成编译资源的的过程,在watch模式下每一次文件变更触发的重新编译都会生成新的Compilation对象,包含了当前编译的模块module, 编译生成的资源,变化的文件, 依赖的状态等- 而每个模块间的依赖关系,则依赖于
AST语法树。每个模块文件在通过Loader解析完成之后,会通过acorn库生成模块代码的AST语法树,通过语法树就可以分析这个模块是否还有依赖的模块,进而继续循环执行下一个模块的编译解析。
最终Webpack打包出来的bundle文件是一个IIFE的执行函数。
// webpack 5 打包的bundle文件内容
(() => { // webpackBootstrap
var __webpack_modules__ = ({
'file-A-path': ((modules) => { // ... })
'index-file-path': ((__unused_webpack_module, __unused_webpack_exports, __webpack_require__) => { // ... })
})
// The module cache
var __webpack_module_cache__ = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
var cachedModule = __webpack_module_cache__[moduleId];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// Create a new module (and put it into the cache)
var module = __webpack_module_cache__[moduleId] = {
// no module.id needed
// no module.loaded needed
exports: {}
};
// Execute the module function
__webpack_modules__[moduleId](module, module.exports, __webpack_require__);
// Return the exports of the module
return module.exports;
}
// startup
// Load entry module and return exports
// This entry module can't be inlined because the eval devtool is used.
var __webpack_exports__ = __webpack_require__("./src/index.js");
})
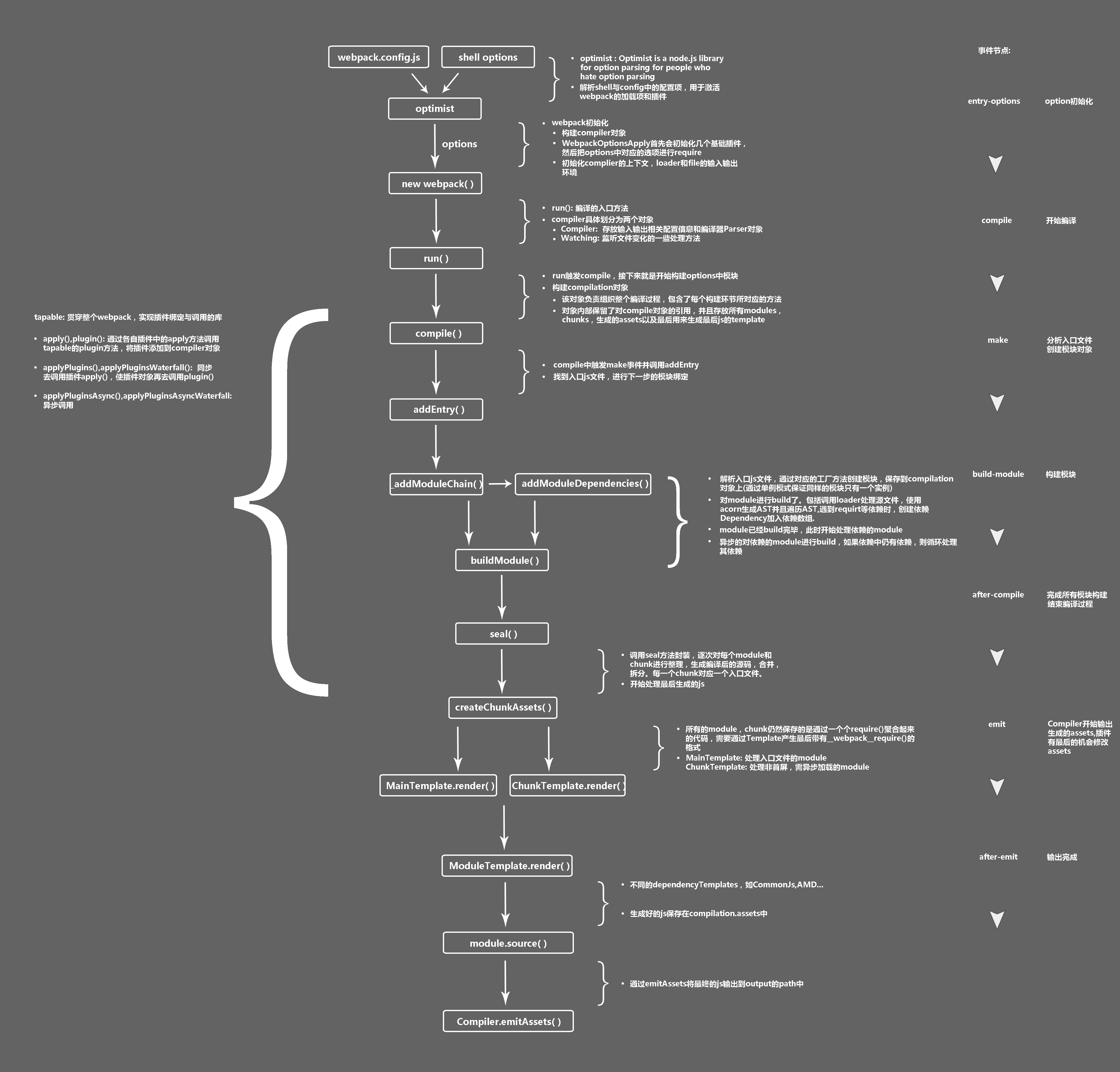
webpack详细工作流程
map和weakMap的区别
(1)Map map本质上就是键值对的集合,但是普通的Object中的键值对中的键只能是字符串。而ES6提供的Map数据结构类似于对象,但是它的键不限制范围,可以是任意类型,是一种更加完善的Hash结构。如果Map的键是一个原始数据类型,只要两个键严格相同,就视为是同一个键。
实际上Map是一个数组,它的每一个数据也都是一个数组,其形式如下:
const map = [
["name","张三"],
["age",18],
]
Map数据结构有以下操作方法:
- size:
map.size返回Map结构的成员总数。 - set(key,value):设置键名key对应的键值value,然后返回整个Map结构,如果key已经有值,则键值会被更新,否则就新生成该键。(因为返回的是当前Map对象,所以可以链式调用)
- get(key):该方法读取key对应的键值,如果找不到key,返回undefined。
- has(key):该方法返回一个布尔值,表示某个键是否在当前Map对象中。
- delete(key):该方法删除某个键,返回true,如果删除失败,返回false。
- clear():map.clear()清除所有成员,没有返回值。
Map结构原生提供是三个遍历器生成函数和一个遍历方法
- keys():返回键名的遍历器。
- values():返回键值的遍历器。
- entries():返回所有成员的遍历器。
- forEach():遍历Map的所有成员。
const map = new Map([
["foo",1],
["bar",2],
])
for(let key of map.keys()){
console.log(key); // foo bar
}
for(let value of map.values()){
console.log(value); // 1 2
}
for(let items of map.entries()){
console.log(items); // ["foo",1] ["bar",2]
}
map.forEach( (value,key,map) => {
console.log(key,value); // foo 1 bar 2
})
(2)WeakMap WeakMap 对象也是一组键值对的集合,其中的键是弱引用的。其键必须是对象,原始数据类型不能作为key值,而值可以是任意的。
该对象也有以下几种方法:
- set(key,value):设置键名key对应的键值value,然后返回整个Map结构,如果key已经有值,则键值会被更新,否则就新生成该键。(因为返回的是当前Map对象,所以可以链式调用)
- get(key):该方法读取key对应的键值,如果找不到key,返回undefined。
- has(key):该方法返回一个布尔值,表示某个键是否在当前Map对象中。
- delete(key):该方法删除某个键,返回true,如果删除失败,返回false。
其clear()方法已经被弃用,所以可以通过创建一个空的WeakMap并替换原对象来实现清除。
WeakMap的设计目的在于,有时想在某个对象上面存放一些数据,但是这会形成对于这个对象的引用。一旦不再需要这两个对象,就必须手动删除这个引用,否则垃圾回收机制就不会释放对象占用的内存。
而WeakMap的键名所引用的对象都是弱引用,即垃圾回收机制不将该引用考虑在内。因此,只要所引用的对象的其他引用都被清除,垃圾回收机制就会释放该对象所占用的内存。也就是说,一旦不再需要,WeakMap 里面的键名对象和所对应的键值对会自动消失,不用手动删除引用。
总结:
- Map 数据结构。它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
- WeakMap 结构与 Map 结构类似,也是用于生成键值对的集合。但是 WeakMap 只接受对象作为键名( null 除外),不接受其他类型的值作为键名。而且 WeakMap 的键名所指向的对象,不计入垃圾回收机制。
diff算法是怎么运作
每一种节点类型有自己的属性,也就是prop,每次进行diff的时候,react会先比较该节点类型,假如节点类型不一样,那么react会直接删除该节点,然后直接创建新的节点插入到其中,假如节点类型一样,那么会比较prop是否有更新,假如有prop不一样,那么react会判定该节点有更新,那么重渲染该节点,然后在对其子节点进行比较,一层一层往下,直到没有子节点
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的
key属性,方便比较。 React只会匹配相同class的component(这里面的class指的是组件的名字)- 合并操作,调用
component的setState方法的时候,React将其标记为 -dirty.到每一个事件循环结束,React检查所有标记dirty的component重新绘制. - 选择性子树渲染。开发人员可以重写
shouldComponentUpdate提高diff的性能
优化⬇️
为了降低算法复杂度,
React的diff会预设三个限制:
- 只对同级元素进行
Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。 - 两个不同类型的元素会产生出不同的树。如果元素由
div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。 - 开发者可以通过
key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
Diff的思路
该如何设计算法呢?如果让我设计一个Diff算法,我首先想到的方案是:
- 判断当前节点的更新属于哪种情况
- 如果是
新增,执行新增逻辑 - 如果是
删除,执行删除逻辑 - 如果是
更新,执行更新逻辑
- 按这个方案,其实有个隐含的前提——不同操作的优先级是相同的
- 但是
React团队发现,在日常开发中,相较于新增和删除,更新组件发生的频率更高。所以Diff会优先判断当前节点是否属于更新。
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
- 第一轮遍历:处理
更新的节点。 - 第二轮遍历:处理剩下的不属于
更新的节点。
diff算法的作用
计算出Virtual DOM中真正变化的部分,并只针对该部分进行原生DOM操作,而非重新渲染整个页面。
传统diff算法
通过循环递归对节点进行依次对比,算法复杂度达到
O(n^3),n是树的节点数,这个有多可怕呢?——如果要展示1000个节点,得执行上亿次比较。。即便是CPU快能执行30亿条命令,也很难在一秒内计算出差异。
React的diff算法
- 什么是调和?
将Virtual DOM树转换成actual DOM树的最少操作的过程 称为 调和 。
- 什么是React diff算法?
diff算法是调和的具体实现。
diff策略
React用 三大策略 将O(n^3)复杂度 转化为 O(n)复杂度
策略一(tree diff):
- Web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
策略二(component diff):
- 拥有相同类的两个组件 生成相似的树形结构,
- 拥有不同类的两个组件 生成不同的树形结构。
策略三(element diff):
对于同一层级的一组子节点,通过唯一id区分。
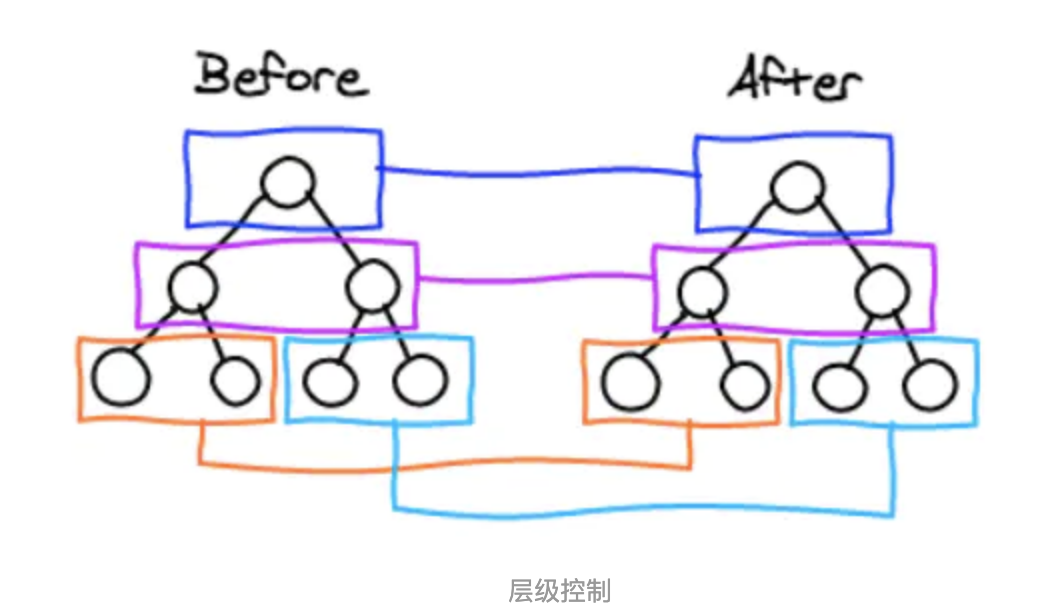
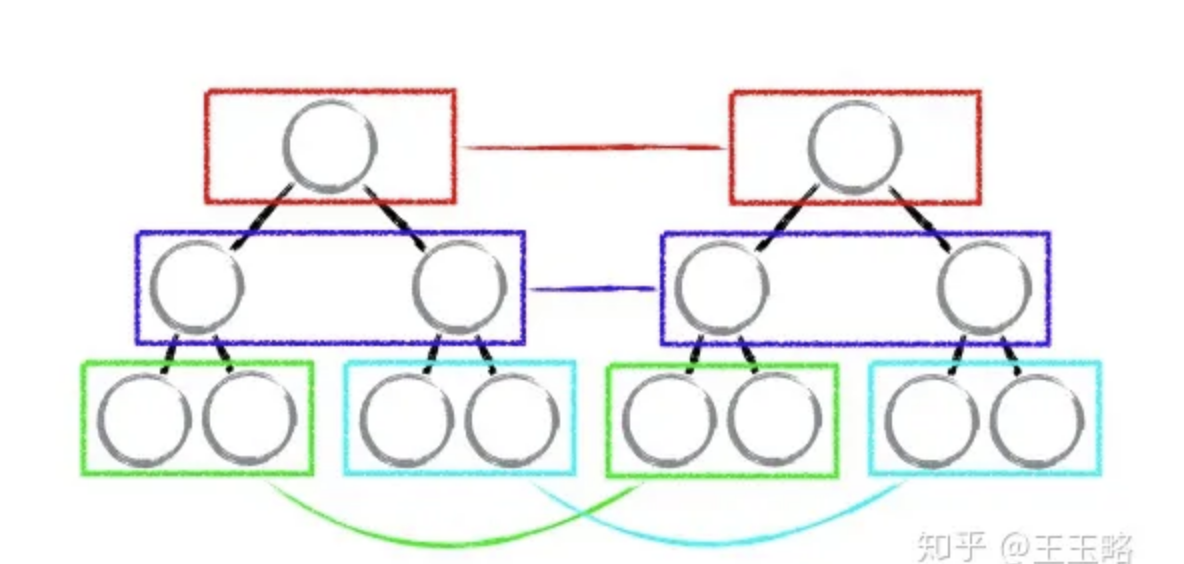
tree diff
- React通过updateDepth对Virtual DOM树进行层级控制。
- 对树分层比较,两棵树 只对同一层次节点 进行比较。如果该节点不存在时,则该节点及其子节点会被完全删除,不会再进一步比较。
- 只需遍历一次,就能完成整棵DOM树的比较。
那么问题来了,如果DOM节点出现了跨层级操作,diff会咋办呢?
答:diff只简单考虑同层级的节点位置变换,如果是跨层级的话,只有创建节点和删除节点的操作。
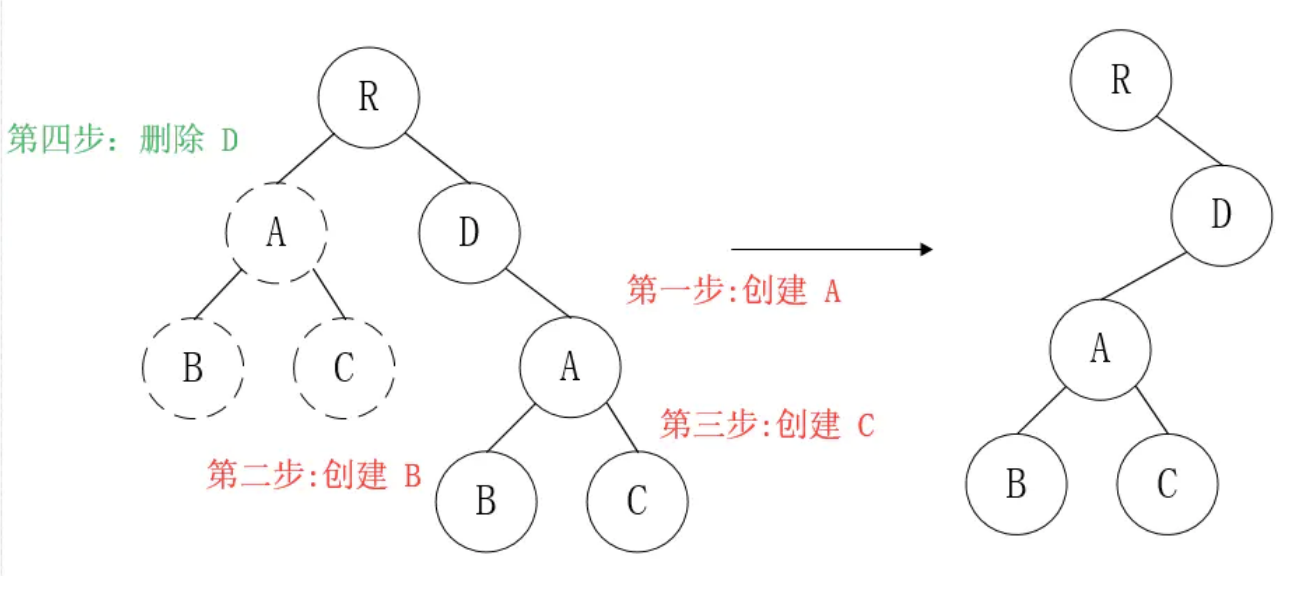
如上图所示,以A为根节点的整棵树会被重新创建,而不是移动,因此 官方建议不要进行DOM节点跨层级操作,可以通过CSS隐藏、显示节点,而不是真正地移除、添加DOM节点
component diff
React对不同的组件间的比较,有三种策略
- 同一类型的两个组件,按原策略(层级比较)继续比较Virtual DOM树即可。
- 同一类型的两个组件,组件A变化为组件B时,可能Virtual DOM没有任何变化,如果知道这点(变换的过程中,Virtual DOM没有改变),可节省大量计算时间,所以 用户 可以通过
shouldComponentUpdate()来判断是否需要 判断计算。 - 不同类型的组件,将一个(将被改变的)组件判断为
dirty component(脏组件),从而替换 整个组件的所有节点。
注意:如果组件D和组件G的结构相似,但是 React判断是 不同类型的组件,则不会比较其结构,而是删除 组件D及其子节点,创建组件G及其子节点。
element diff
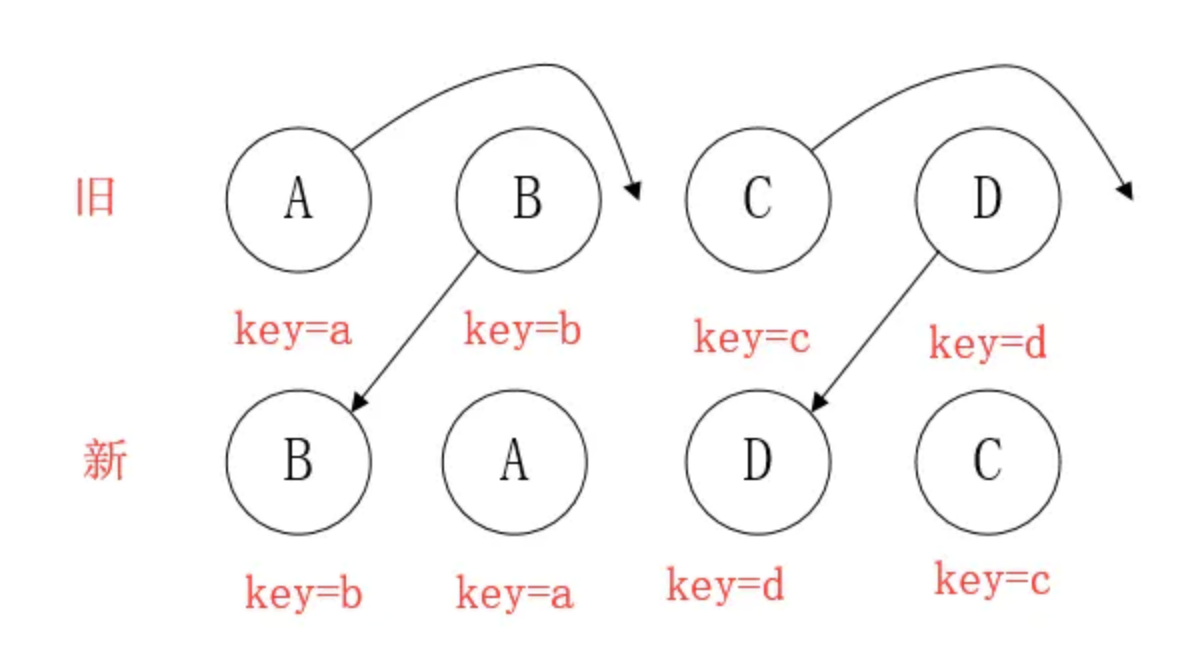
当节点处于同一层级时,diff提供三种节点操作:删除、插入、移动。
- 插入:组件 C 不在集合(A,B)中,需要插入
- 删除:
- 组件 D 在集合(A,B,D)中,但 D的节点已经更改,不能复用和更新,所以需要删除 旧的 D ,再创建新的。
- 组件 D 之前在 集合(A,B,D)中,但集合变成新的集合(A,B)了,D 就需要被删除。
- 移动:组件D已经在集合(A,B,C,D)里了,且集合更新时,D没有发生更新,只是位置改变,如新集合(A,D,B,C),D在第二个,无须像传统diff,让旧集合的第二个B和新集合的第二个D 比较,并且删除第二个位置的B,再在第二个位置插入D,而是 (对同一层级的同组子节点) 添加唯一key进行区分,移动即��。
总结
tree diff:只对比同一层的 dom 节点,忽略 dom 节点的跨层级移动
如下图,react 只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。
这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
这就意味着,如果 dom 节点发生了跨层级移动,react 会删除旧的节点,生成新的节点,而不会复用。
component diff:如果不是同一类型的组件,会删除旧的组件,创建新的组件
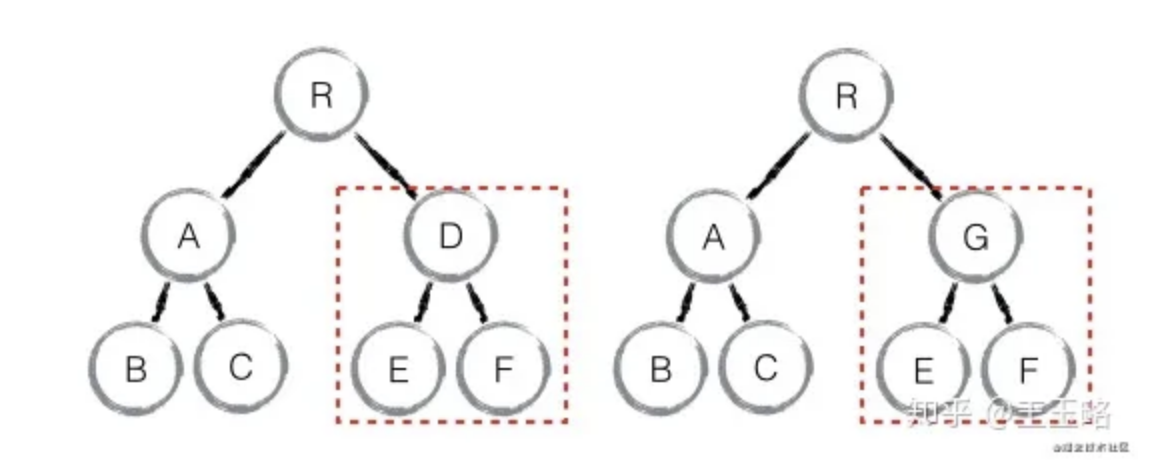
element diff:对于同一层级的一组子节点,需要通过唯一 id 进行来区分
- 如果没有 id 来进行区分,一旦有插入动作,会导致插入位置之后的列表全部重新渲染
- 这也是为什么渲染列表时为什么要使用唯一的 key。
diff的不足与待优化的地方
尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能
与其他框架相比,React 的 diff 算法有何不同?
diff 算法探讨的就是虚拟 DOM 树发生变化后,生成 DOM 树更新补丁的方式。它通过对比新旧两株虚拟 DOM 树的变更差异,将更新补丁作用于真实 DOM,以最小成本完成视图更新
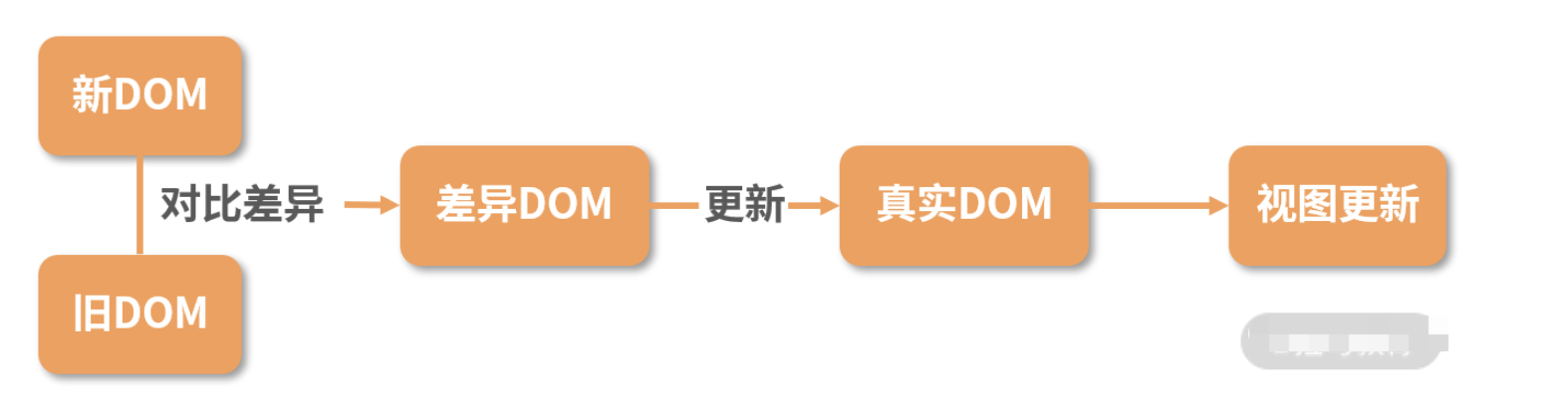
具体的流程是这样的:
- 真实 DOM 与虚拟 DOM 之间存在一个映射关系。这个映射关系依靠初始化时的 JSX 建立完成;
- 当虚拟 DOM 发生变化后,就会根据差距计算生成 patch,这个 patch 是一个结构化的数据,内容包含了增加、更新、移除等;
- 最后再根据 patch 去更新真实的 DOM,反馈到用户的界面上。
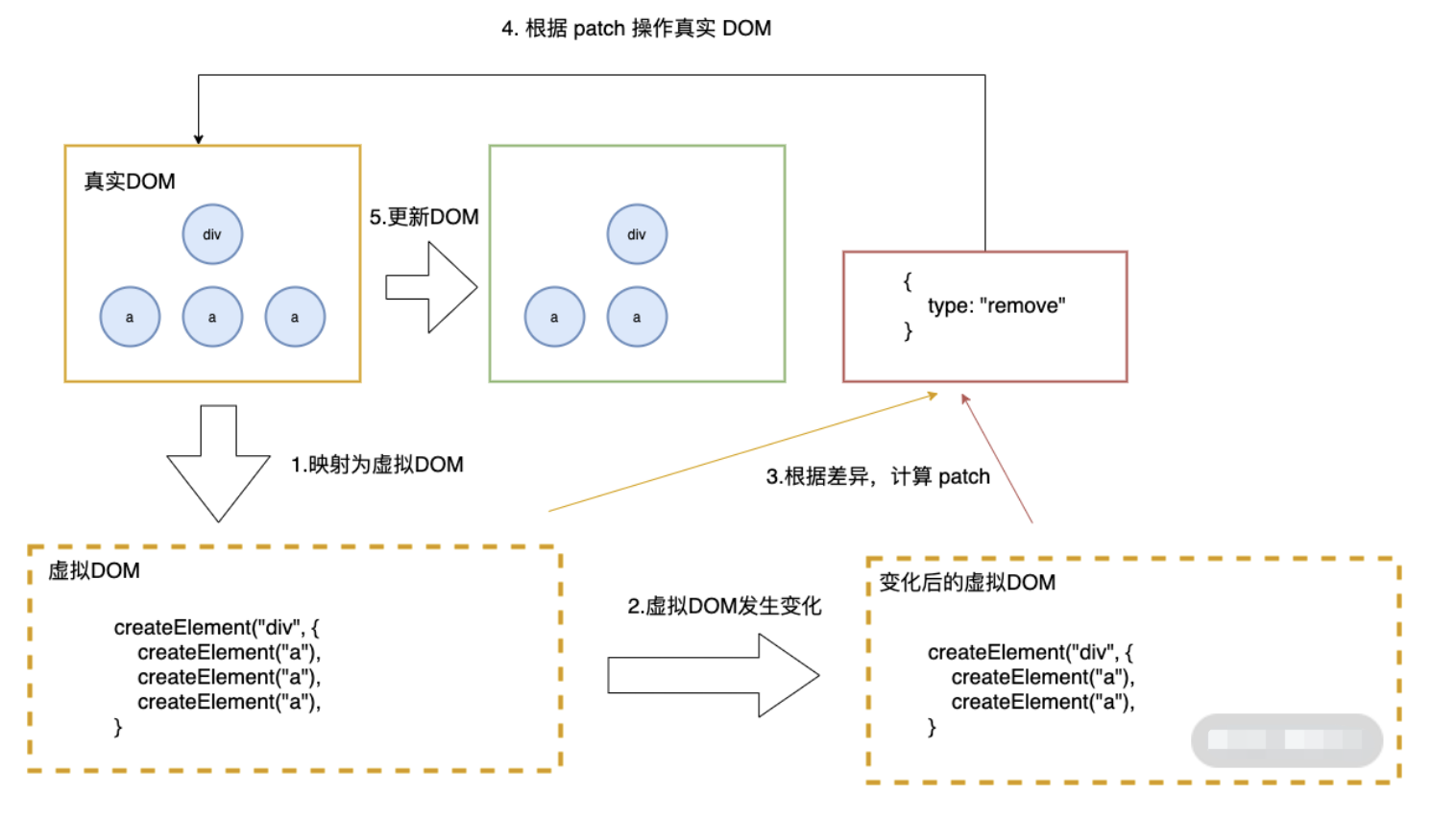
在回答有何不同之前,首先需要说明下什么是 diff 算法。
diff 算法是指生成更新补丁的方式,主要应用于虚拟 DOM 树变化后,更新真实 DOM。所以 diff 算法一定存在这样一个过程:触发更新 → 生成补丁 → 应用补丁- React 的 diff 算法,触发更新的时机主要在 state 变化与 hooks 调用之后。此时触发虚拟 DOM 树变更遍历,采用了深度优先遍历算法。但传统的遍历方式,效率较低。为了优化效率,使用了分治的方式。
将单一节点比对转化为了 3 种类型节点的比对,分别是树、组件及元素,以此提升效率。树比对:由于网页视图中较少有跨层级节点移动,两株虚拟 DOM 树只对同一层次的节点进行比较。组件比对:如果组件是同一类型,则进行树比对,如果不是,则直接放入到补丁中。元素比对:主要发生在同层级中,通过标记节点操作生成补丁,节点操作对应真实的 DOM 剪裁操作。同一层级的子节点,可以通过标记 key 的方式进行列表对比。
- 以上是经典的 React diff 算法内容。
自 React 16 起,引入了 Fiber 架构。为了使整个更新过程可随时暂停恢复,节点与树分别采用了FiberNode 与 FiberTree 进行重构。fiberNode 使用了双链表的结构,可以直接找到兄弟节点与子节点 - 然后拿 Vue 和 Preact 与 React 的 diff 算法进行对比
Preact的Diff算法相较于React,整体设计思路相似,但最底层的元素采用了真实DOM对比操作,也没有采用Fiber设计。Vue 的Diff算法整体也与React相似,同样未实现Fiber设计
- 然后进行横向比较,
React 拥有完整的 Diff 算法策略,且拥有随时中断更新的时间切片能力,在大批量节点更新的极端情况下,拥有更友好的交互体验。 - Preact 可以在一些对性能要求不高,仅需要渲染框架的简单场景下应用。
- Vue 的整体
diff 策略与 React 对齐,虽然缺乏时间切片能力,但这并不意味着 Vue 的性能更差,因为在 Vue 3 初期引入过,后期因为收益不高移除掉了。除了高帧率动画,在 Vue 中其他的场景几乎都可以使用防抖和节流去提高响应性能。
**学习原理的目的就是应用。那如何根据 React diff 算法原理优化代码呢?**这个问题其实按优化方式逆向回答即可。
- 根据
diff算法的设计原则,应尽量避免跨层级节点移动。 - 通过设置唯一
key进行优化,尽量减少组件层级深度。因为过深的层级会加深遍历深度,带来性能问题。 - 设置
shouldComponentUpdate或者React.pureComponet减少diff次数。
原型链指向
p.__proto__ // Person.prototype
Person.prototype.__proto__ // Object.prototype
p.__proto__.__proto__ //Object.prototype
p.__proto__.constructor.prototype.__proto__ // Object.prototype
Person.prototype.constructor.prototype.__proto__ // Object.prototype
p1.__proto__.constructor // Person
Person.prototype.constructor // Person
常见的DOM操作有哪些
1)DOM 节点的获取
DOM 节点的获取的API及使用:
getElementById // 按照 id 查询
getElementsByTagName // 按照标签名查询
getElementsByClassName // 按照类名查询
querySelectorAll // 按照 css 选择器查询
// 按照 id 查询
var imooc = document.getElementById('imooc') // 查询到 id 为 imooc 的元素
// 按照标签名查询
var pList = document.getElementsByTagName('p') // 查询到标签为 p 的集合
console.log(divList.length)
console.log(divList[0])
// 按照类名查询
var moocList = document.getElementsByClassName('mooc') // 查询到类名为 mooc 的集合
// 按照 css 选择器查询
var pList = document.querySelectorAll('.mooc') // 查询到类名为 mooc 的集合
2)DOM 节点的创建
创建一个新节点,并把它添加到指定节点的后面。 已知的 HTML 结构如下:
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container">
<h1 id="title">我是标题</h1>
</div>
</body>
</html>
要求添加一个有内容的 span 节点到 id 为 title 的节点后面,做法就是:
// 首先获取父节点
var container = document.getElementById('container')
// 创建新节点
var targetSpan = document.createElement('span')
// 设置 span 节点的内容
targetSpan.innerHTML = 'hello world'
// 把新创建的元素塞进父节点里去
container.appendChild(targetSpan)
3)DOM 节点的删除
删除指定的 DOM 节点, 已知的 HTML 结构如下:
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container"> <h1 id="title">我是标题</h1>
</div> </body>
</html>
需要删除 id 为 title 的元素,做法是:
// 获取目标元素的父元素
var container = document.getElementById('container')
// 获取目标元素
var targetNode = document.getElementById('title')
// 删除目标元素
container.removeChild(targetNode)
或者通过子节点数组来完成删除:
// 获取目标元素的父元素var container = document.getElementById('container')// 获取目标元素var targetNode = container.childNodes[1]// 删除目标元素container.removeChild(targetNode)
4)修改 DOM 元素
修改 DOM 元素这个动作可以分很多维度,比如说移动 DOM 元素的位置,修改 DOM 元素的属性等。
将指定的两个 DOM 元素交换位置, 已知的 HTML 结构如下:
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container"> <h1 id="title">我是标题</h1>
<p id="content">我是内容</p>
</div> </body>
</html>
现在需要调换 title 和 content 的位置,可以考虑 insertBefore 或者 appendChild:
// 获取父元素
var container = document.getElementById('container')
// 获取两个需要被交换的元素
var title = document.getElementById('title')
var content = document.getElementById('content')
// 交换两个元素,把 content 置于 title 前面
container.insertBefore(content, title)
CSS 优化和提高性能的方法有哪些?
加载性能:
(1)css压缩:将写好的css进行打包压缩,可以减小文件体积。
(2)css单一样式:当需要下边距和左边距的时候,很多时候会选择使用 margin:top 0 bottom 0;但margin-bottom:bottom;margin-left:left;执行效率会更高。
(3)减少使用@import,建议使用link,因为后者在页面加载时一起加载,前者是等待页面加载完成之后再进行加载。
选择器性能:
(1)关键选择器(key selector)。选择器的最后面的部分为关键选择器(即用来匹配目标元素的部分)。CSS选择符是从右到左进行匹配的。当使用后代选择器的时候,浏览器会遍历所有子元素来确定是否是指定的元素等等;
(2)如果规则拥有ID选择器作为其关键选择器,则不要为规则增加标签。过滤掉无关的规则(这样样式系统就不会浪费时间去匹配它们了)。
(3)避免使用通配规则,如*{}计算次数惊人,只对需要用到的元素进行选择。
(4)尽量少的去对标签进行选择,而是用class。
(5)尽量少的去使用后代选择器,降低选择器的权重值。后代选择器的开销是最高的,尽量将选择器的深度降到最低,最高不要超过三层,更多的使用类来关联每一个标签元素。
(6)了解哪些属性是可以通过继承而来的,然后避免对这些属性重复指定规则。
渲染性能:
(1)慎重使用高性能属性:浮动、定位。
(2)尽量减少页面重排、重绘。
(3)去除空规则:{}。空规则的产生原因一般来说是为了预留样式。去除这些空规则无疑能减少css文档体积。
(4)属性值为0时,不加单位。
(5)属性值为浮动小数0.**,可以省略小数点之前的0。
(6)标准化各种浏览器前缀:带浏览器前缀的在前。标准属性在后。
(7)不使用@import前缀,它会影响css的加载速度。
(8)选择器优化嵌套,尽量避免层级过深。
(9)css雪碧图,同一页面相近部分的小图标,方便使用,减少页面的请求次数,但是同时图片本身会变大,使用时,优劣考虑清楚,再使用。
(10)正确使用display的属性,由于display的作用,某些样式组合会无效,徒增样式体积的同时也影响解析性能。
(11)不滥用web字体。对于中文网站来说WebFonts可能很陌生,国外却很流行。web fonts通常体积庞大,而且一些浏览器在下载web fonts时会阻塞页面渲染损伤性能。
可维护性、健壮性:
(1)将具有相同属性的样式抽离出来,整合并通过class在页面中进行使用,提高css的可维护性。
(2)样式与内容分离:将css代码定义到外部css中。
setTimeout 模拟 setInterval
描述:使用setTimeout模拟实现setInterval的功能。
实现:
const mySetInterval(fn, time) {
let timer = null;
const interval = () => {
timer = setTimeout(() => {
fn(); // time 时间之后会执行真正的函数fn
interval(); // 同时再次调用interval本身
}, time)
}
interval(); // 开始执行
// 返回用于关闭定时器的函数
return () => clearTimeout(timer);
}
// 测试
const cancel = mySetInterval(() => console.log(1), 400);
setTimeout(() => {
cancel();
}, 1000);
// 打印两次1
代码输出结果
var obj = {
say: function() {
var f1 = () => {
console.log("1111", this);
}
f1();
},
pro: {
getPro:() => {
console.log(this);
}
}
}
var o = obj.say;
o();
obj.say();
obj.pro.getPro();
输出结果:
1111 window对象
1111 obj对象
window对象
解析:
- o(),o是在全局执行的,而f1是箭头函数,它是没有绑定this的,它的this指向其父级的this,其父级say方法的this指向的是全局作用域,所以会打印出window;
- obj.say(),谁调用say,say 的this就指向谁,所以此时this指向的是obj对象;
- obj.pro.getPro(),我们知道,箭头函数时不绑定this的,getPro处于pro中,而对象不构成单独的作用域,所以箭头的函数的this就指向了全局作用域window。
React Fiber架构
最主要的思想就是将任务拆分 。
- DOM需要渲染时暂停,空闲时恢复。
window.requestIdleCallback- React内部实现的机制
React 追求的是 “快速响应”,那么,“快速响应“的制约因素都有什么呢
CPU的瓶颈:当项目变得庞大、组件数量繁多、遇到大计算量的操作或者设备性能不足使得页面掉帧,导致卡顿。IO的瓶颈:发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应。
fiber架构主要就是用来解决CPU和网络的问题,这两个问题一直也是最影响前端开发体验的地方,一个会造成卡顿,一个会造成白屏。为此 react 为前端引入了两个新概念:Time Slicing时间分片和Suspense。
1. React 都做过哪些优化
- React渲染页面的两个阶段
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
Virtual DOM,然后通过Diff算法,快速找出需要更新的元素,放到更新队列中去,得到新的更新队列。 - 渲染阶段(commit):这个阶段 React 会遍历更新队列,将其所有的变更一次性更新到DOM上
- 调度阶段(reconciliation):在这个阶段 React 会更新数据生成新的
- React 15 架构
- React15架构可以分为两层
- Reconciler(协调器)—— 负责找出变化的组件;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上;
- React15架构可以分为两层
- 在React15及以前,Reconciler采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,递归更新时间超过了16ms,用户交互就会卡顿。
- 为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
- React 16 架构
- 为了解决同步更新长时间占用线程导致页面卡顿的问题,也为了探索运行时优化的更多可能,React开始重构并一直持续至今。重构的目标是实现Concurrent Mode(并发模式)。
- 从v15到v16,React团队花了两年时间将源码架构中的Stack Reconciler重构为Fiber Reconciler
React16架构可以分为三层:- Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler;
- Reconciler(协调器)—— 负责找出变化的组件:更新工作从递归变成了可以中断的循环过程。Reconciler内部采用了Fiber的架构;
- Renderer(渲染器)—— 负责将变化的组件渲染到页面上。
- React 17 优化
- 使用Lane来管理任务的优先级。Lane用二进制位表示任务的优先级,方便优先级的计算(位运算),不同优先级占用不同位置的“赛道”,而且存在批的概念,优先级越低,“赛道”越多。高优先级打断低优先级,新建的任务需要赋予什么优先级等问题都是Lane所要解决的问题。
- Concurrent Mode的目的是实现一套可中断/恢复的更新机制。其由两部分组成:
- 一套协程架构:Fiber Reconciler
- 基于协程架构的启发式更新算法:控制协程架构工作方式的算法
2. 浏览器一帧都会干些什么以及requestIdleCallback的启示
我们都知道,页面的内容都是一帧一帧绘制出来的,浏览器刷新率代表浏览器一秒绘制多少帧。原则上说 1s 内绘制的帧数也多,画面表现就也细腻。目前浏览器大多是 60Hz(60帧/s),每一帧耗时也就是在 16.6ms 左右。那么在这一帧的(16.6ms) 过程中浏览器又干了些什么呢

通过上面这张图可以清楚的知道,浏览器一帧会经过下面这几个过程:
- 接受输入事件
- 执行事件回调
- 开始一帧
- 执行 RAF (RequestAnimationFrame)
- 页面布局,样式计算
- 绘制渲染
- 执行 RIC (RequestIdelCallback)
第七步的 RIC 事件不是每一帧结束都会执行,只有在一帧的 16.6ms 中做完了前面 6 件事儿且还有剩余时间,才会执行。如果一帧执行结束后还有时间执行 RIC 事件,那么下一帧需要在事件执行结束才能继续渲染,所以 RIC 执行不要超过 30ms,如果长时间不将控制权交还给浏览器,会影响下一帧的渲染,导致页面出现卡顿和事件响应不及时。
requestIdleCallback 的启示:我们以浏览器是否有剩余时间作微任务中断的标准,那么我们需要一种机制,当浏览器有剩余时间时通知我们。
requestIdleCallback((deadline) => {
// deadline 有两个参数
// timeRemaining(): 当前帧还剩下多少时间
// didTimeout: 是否超时
// 另外 requestIdleCallback 后如果跟上第二个参数 {timeout: ...} 则会强制浏览器在当前帧执行完后执行。
if (deadline.timeRemaining() > 0) {
// TODO
} else {
requestIdleCallback(otherTasks);
}
});
// 用法示例
var tasksNum = 10000
requestIdleCallback(unImportWork)
function unImportWork(deadline) {
while (deadline.timeRemaining() && tasksNum > 0) {
console.log(`执行了${10000 - tasksNum + 1}个任务`)
tasksNum--
}
if (tasksNum > 0) { // 在未来的帧中继续执行
requestIdleCallback(unImportWork)
}
}
其实部分浏览器已经实现了这个API,这就是requestIdleCallback。但是由于以下因素,Facebook 抛弃了
requestIdleCallback的原生 API:
- 浏览器兼容性;
- 触发频率不稳定,受很多因素影响。比如当我们的浏览器切换tab后,之前tab注册的
requestIdleCallback触发的频率会变得很低。
基于以上原因,在React中实现了功能更完备的
requestIdleCallbackpolyfill,这就是Scheduler。除了在空闲时触发回调的功能外,Scheduler还提供了多种调度优先级供任务设置
3. React Fiber是什么
React Fiber是对核心算法的一次重新实现。React Fiber把更新过程碎片化,把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会
- 在
React Fiber中,一次更新过程会分成多个分片完成,所以完全有可能一个更新任务还没有完成,就被另一个更高优先级的更新过程打断,这时候,优先级高的更新任务会优先处理完,而低优先级更新任务所做的工作则会完全作废,然后等待机会重头再来 - 因为一个更新过程可能被打断,所以
React Fiber一个更新过程被分为两个阶段(Phase):第一个阶段Reconciliation Phase和第二阶段Commit Phase - 在第一阶段
Reconciliation Phase,React Fiber会找出需要更新哪些DOM,这个阶段是可以被打断的;但是到了第二阶段Commit Phase,那就一鼓作气把DOM更新完,绝不会被打断 - 这两个阶段大部分工作都是
React Fiber做,和我们相关的也就是生命周期函数
React Fiber改变了之前react的组件渲染机制,新的架构使原来同步渲染的组件现在可以异步化,可中途中断渲染,执行更高优先级的任务。释放浏览器主线程
关键特性
- 增量渲染(把渲染任务拆分成块,匀到多帧)
- 更新时能够暂停,终止,复用渲染任务
- 给不同类型的更新赋予优先级
- 并发方面新的基础能力
增量渲染用来解决掉帧的问题,渲染任务拆分之后,每次只做一小段,做完一段就把时间控制权交还给主线程,而不像之前长时间占用
4. 组件的渲染顺序
假如有A,B,C,D组件,层级结构为:

我们知道组件的生命周期为:
挂载阶段 :
constructor()componentWillMount()render()componentDidMount()
更新阶段为 :
componentWillReceiveProps()shouldComponentUpdate()componentWillUpdate()render()componentDidUpdate
那么在挂载阶段,
A,B,C,D的生命周期渲染顺序是如何的呢?
那么在挂载阶段,A,B,C,D的生命周期渲染顺序是如何的呢?
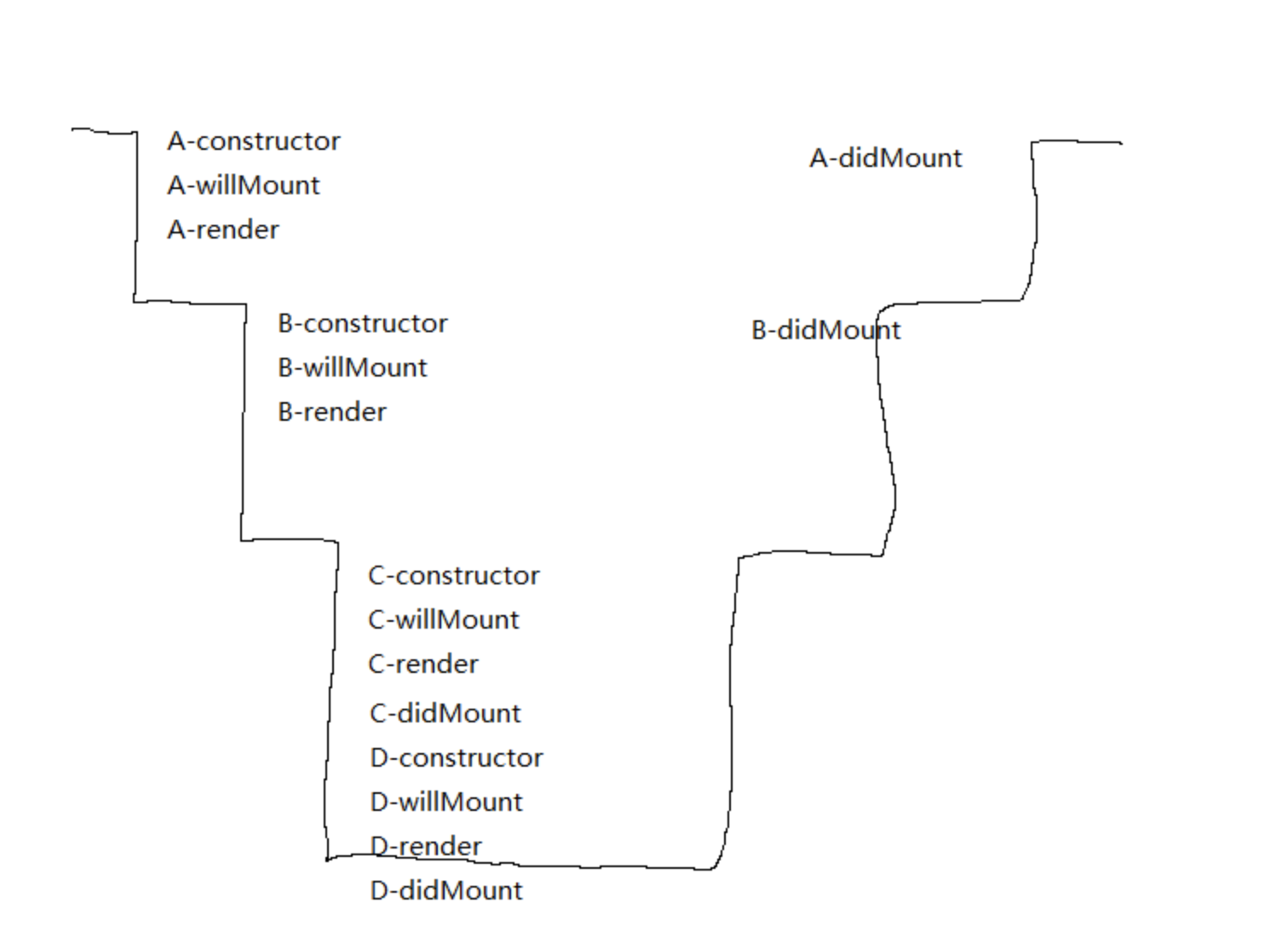
以
render()函数为分界线。从顶层组件开始,一直往下,直至最底层子组件。然后再往上
组件update阶段同理
前面是react16以前的组建渲染方式。这就存在一个问题
如果这是一个很大,层级很深的组件,
react渲染它需要几十甚至几百毫秒,在这期间,react会一直占用浏览器主线程,任何其他的操作(包括用户的点击,鼠标移动等操作)都无法执行
Fiber架构就是为了解决这个问题
看一下fiber架构 组建的渲染顺序
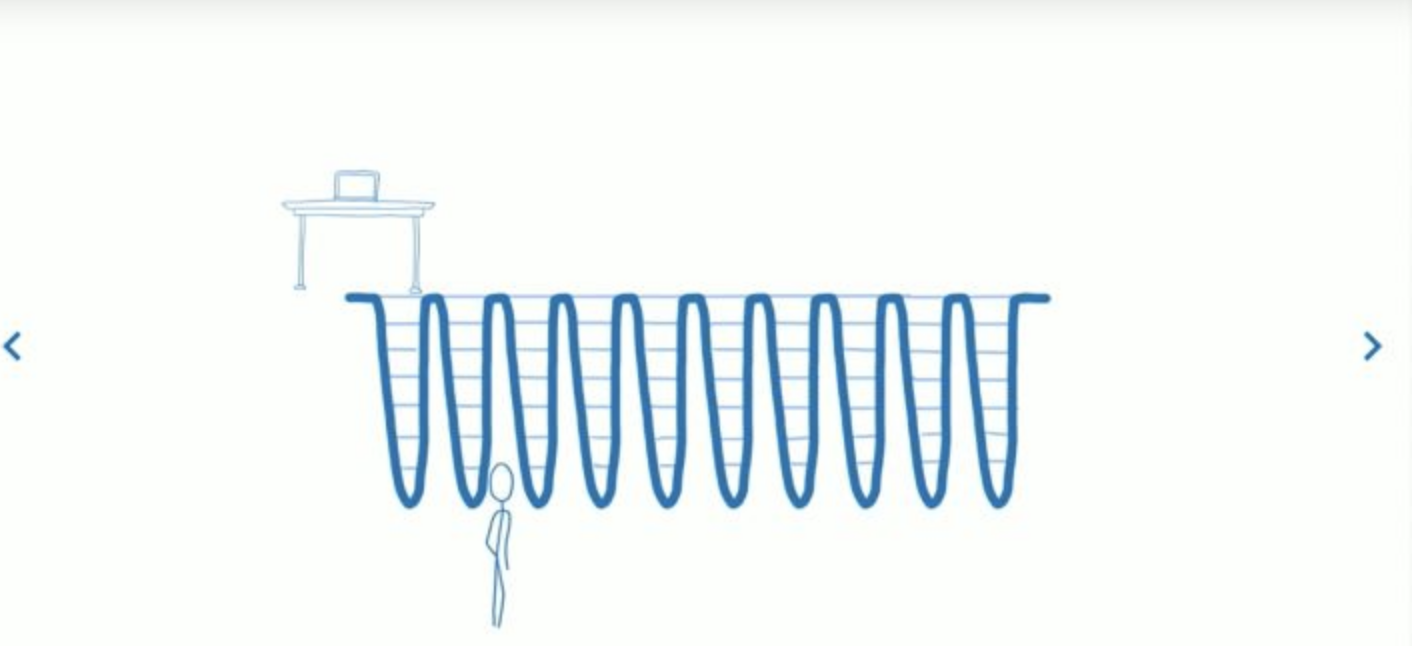
加入
fiber的react将组件更新分为两个时期
这两个时期以render为分界
render前的生命周期为phase1,render后的生命周期为phase2
phase1的生命周期是可以被打断的,每隔一段时间它会跳出当前渲染进程,去确定是否有其他更重要的任务。此过程,React在workingProgressTree(并不是真实的virtualDomTree)上复用current上的Fiber数据结构来一步地(通过requestIdleCallback)来构建新的 tree,标记处需要更新的节点,放入队列中phase2的生命周期是不可被打断的,React将其所有的变更一次性更新到DOM上
这里最重要的是phase1这是时期所做的事。因此我们需要具体了解phase1的机制
- 如果不被打断,那么
phase1执行完会直接进入render函数,构建真实的virtualDomTree - 如果组件再
phase1过程中被打断,即当前组件只渲染到一半(也许是在willMount,也许是willUpdate~反正是在render之前的生命周期),那么react会怎么干呢?react会放弃当前组件所有干到一半的事情,去做更高优先级更重要的任务(当然,也可能是用户鼠标移动,或者其他react监听之外的任务),当所有高优先级任务执行完之后,react通过callback回到之前渲染到一半的组件,从头开始渲染。(看起来放弃已经渲染完的生命周期,会有点不合理,反而会增加渲染时长,但是react确实是这么干的)
所有phase1的生命周期函数都可能被执行多次,因为可能会被打断重来
这样的话,就和
react16版本之前有很大区别了,因为可能会被执行多次,那么我们最好就得保证phase1的生命周期每一次执行的结果都是一样的,否则就会有问题,因此,最好都是纯函数
- 如果高优先级的任务一直存在,那么低优先级的任务则永远无法进行,组件永远无法继续渲染。这个问题facebook目前好像还没解决
- 所以,facebook在
react16增加fiber结构,其实并不是为了减少组件的渲染时间,事实上也并不会减少,最重要的是现在可以使得一些更高优先级的任务,如用户的操作能够优先执行,提高用户的体验,至少用户不会感觉到卡顿
5 React Fiber架构总结
React Fiber如何性能优化
- 更新的两个阶段
- 调度算法阶段-执行diff算法,纯js计算
- Commit阶段-将diff结果渲染dom
- 可能会有性能问题
- JS是单线程的,且和DOM渲染公用一个线程
- 当组件足够复杂,组件更新时计算和渲染压力都大
- 同时再有DOM操作需求(动画、鼠标拖拽等),将卡顿
- 解决方案fiber
- 将调度算法阶段阶段任务拆分(Commit无法拆分)
- DOM需要渲染时暂停,空闲时恢复
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
React 的核心流程可以分为两个部分:
reconciliation(调度算法,也可称为render)- 更新
state与props; - 调用生命周期钩子;
- 生成
virtual dom- 这里应该称为
Fiber Tree更为符合;
- 这里应该称为
- 通过新旧 vdom 进行 diff 算法,获取 vdom change
- 确定是否需要重新渲染
- 更新
commit- 如需要,则操作
dom节点更新
- 如需要,则操作
要了解 Fiber,我们首先来看为什么需要它
- 问题 : 随着应用变得越来越庞大,整个更新渲染的过程开始变得吃力,大量的组件渲染会导致主进程长时间被占用,导致一些动画或高频操作出现卡顿和掉帧的情况。而关键点,便是 同步阻塞。在之前的调度算法中,React 需要实例化每个类组件,生成一颗组件树,使用 同步递归 的方式进行遍历渲染,而这个过程最大的问题就是无法 暂停和恢复。
- 解决方案: 解决同步阻塞的方法,通常有两种: 异步 与 任务分割。而 React Fiber 便是为了实现任务分割而诞生的
- 简述
- 在
React V16将调度算法进行了重构, 将之前的stack reconciler重构成新版的 fiberreconciler,变成了具有链表和指针的 单链表树遍历算法。通过指针映射,每个单元都记录着遍历当下的上一步与下一步,从而使遍历变得可以被暂停和重启 - 这里我理解为是一种 任务分割调度算法,主要是 将原先同步更新渲染的任务分割成一个个独立的 小任务单位,根据不同的优先级,将小任务分散到浏览器的空闲时间执行,充分利用主进程的事件循环机制
- 在
- 核心
Fiber这里可以具象为一个 数据结构
class Fiber {
constructor(instance) {
this.instance = instance
// 指向第一个 child 节点
this.child = child
// 指向父节点
this.return = parent
// 指向第一个兄弟节点
this.sibling = previous
}
}
- 链表树遍历算法 : 通过 节点保存与映射,便能够随时地进行 停止和重启,这样便能达到实现任务分割的基本前提
- 首先通过不断遍历子节点,到树末尾;
- 开始通过
sibling遍历兄弟节点; - return 返回父节点,继续执行2;
- 直到 root 节点后,跳出遍历;
- 任务分割 ,React 中的渲染更新可以分成两个阶段
- reconciliation 阶段 : vdom 的数据对比,是个适合拆分的阶段,比如对比一部分树后,先暂停执行个动画调用,待完成后再回来继续比对
- Commit 阶段 : 将 change list 更新到 dom 上,并不适合拆分,才能保持数据与 UI 的同步。否则可能由于阻塞 UI 更新,而导致数据更新和 UI 不一致的情况
- 分散执行: 任务分割后,就可以把小任务单元分散到浏览器的空闲期间去排队执行,而实现的关键是两个新API:
requestIdleCallback与requestAnimationFrame- 低优先级的任务交给
requestIdleCallback处理,这是个浏览器提供的事件循环空闲期的回调函数,需要pollyfill,而且拥有deadline参数,限制执行事件,以继续切分任务; - 高优先级的任务交给
requestAnimationFrame处理;
- 低优先级的任务交给
// 类似于这样的方式
requestIdleCallback((deadline) => {
// 当有空闲时间时,我们执行一个组件渲染;
// 把任务塞到一个个碎片时间中去;
while ((deadline.timeRemaining() > 0 || deadline.didTimeout) && nextComponent) {
nextComponent = performWork(nextComponent);
}
});
- 优先级策略: 文本框输入 > 本次调度结束需完成的任务 > 动画过渡 > 交互反馈 > 数据更新 > 不会显示但以防将来会显示的任务
- Fiber 其实可以算是一种编程思想,在其它语言中也有许多应用(Ruby Fiber)。
- 核心思想是 任务拆分和协同,主动把执行权交给主线程,使主线程有时间空挡处理其他高优先级任务。
- 当遇到进程阻塞的问题时,任务分割、异步调用 和 缓存策略 是三个显著的解决思路。
类数组转化为数组的方法
题目描述:类数组拥有 length 属性 可以使用下标来访问元素 但是不能使用数组的方法 如何把类数组转化为数组?
实现代码如下:
const arrayLike=document.querySelectorAll('div')
// 1.扩展运算符
[...arrayLike]
// 2.Array.from
Array.from(arrayLike)
// 3.Array.prototype.slice
Array.prototype.slice.call(arrayLike)
// 4.Array.apply
Array.apply(null, arrayLike)
// 5.Array.prototype.concat
Array.prototype.concat.apply([], arrayLike)
为什么需要浏览器缓存?
对于浏览器的缓存,主要针对的是前端的静态资源,最好的效果就是,在发起请求之后,拉取相应的静态资源,并保存在本地。如果服务器的静态资源没有更新,那么在下次请求的时候,就直接从本地读取即可,如果服务器的静态资源已经更新,那么我们再次请求的时候,就到服务器拉取新的资源,并保存在本地。这样就大大的减少了请求的次数,提高了网站的性能。这就要用到浏览器的缓存策略了。
所谓的浏览器缓存指的是浏览器将用户请求过的静态资源,存储到电脑本地磁盘中,当浏览器再次访问时,就可以直接从本地加载,不需要再去服务端请求了。
使用浏览器缓存,有以下优点:
- 减少了服务器的负担,提高了网站的性能
- 加快了客户端网页的加载速度
- 减少了多余网络数据传输
script标签中defer和async的区别
如果没有defer或async属性,浏览器会立即加载并执行相应的脚本。它不会等待后续加载的文档元素,读取到就会开始加载和执行,这样就阻塞了后续文档的加载。
defer 和 async属性都是去异步加载外部的JS脚本文件,它们都不会阻塞页面的解析,其区别如下:
- 执行顺序: 多个带async属性的标签,不能保证加载的顺序;多个带defer属性的标签,按照加载顺序执行;
- 脚本是否并行执行:async属性,表示后续文档的加载和执行与js脚本的加载和执行是并行进行的,即异步执行;defer属性,加载后续文档的过程和js脚本的加载(此时仅加载不执行)是并行进行的(异步),js脚本需要等到文档所有元素解析完成之后才执行,DOMContentLoaded事件触发执行之前。
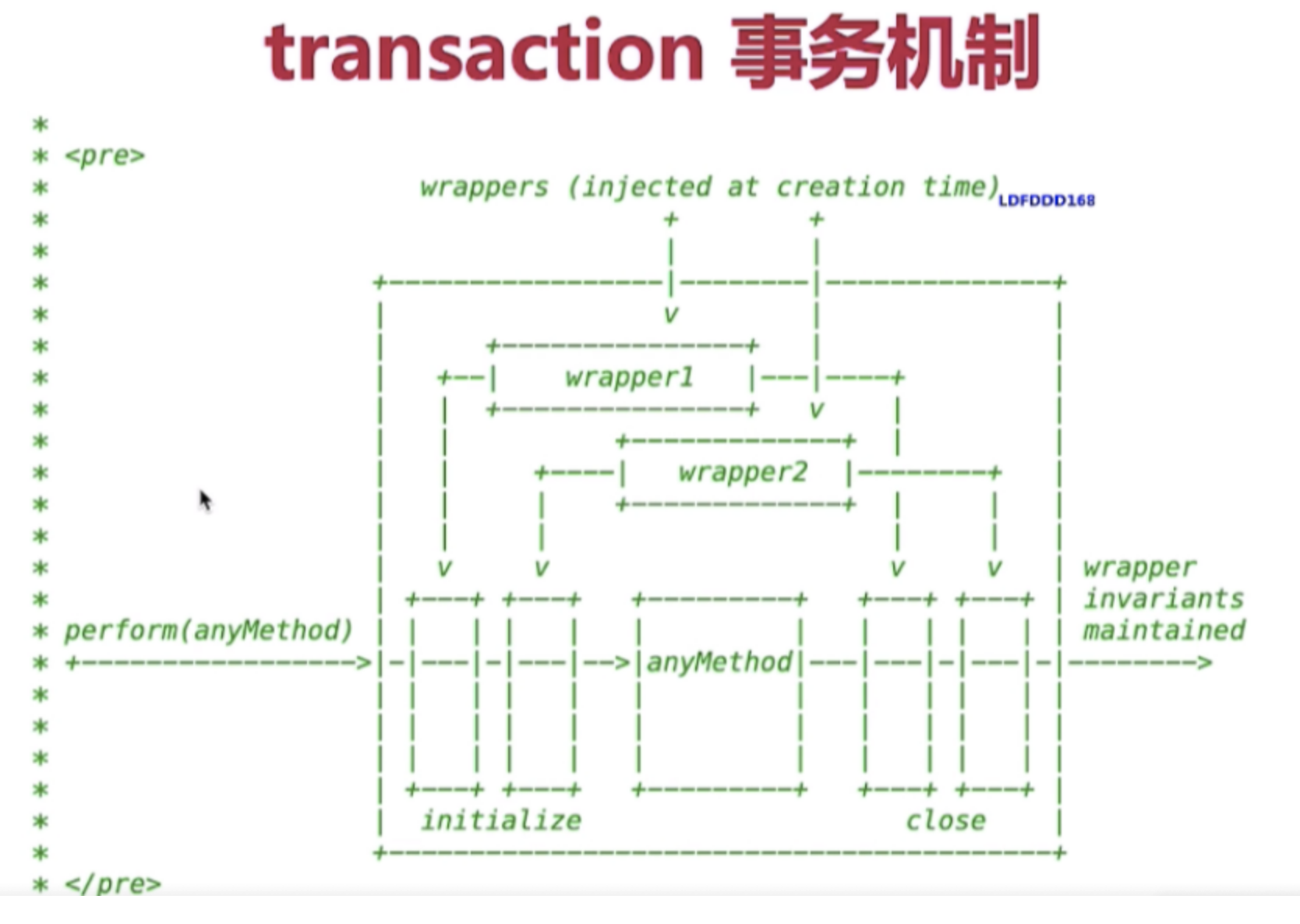
React事务机制

事件总线(发布订阅模式)
class EventEmitter {
constructor() {
this.cache = {}
}
on(name, fn) {
if (this.cache[name]) {
this.cache[name].push(fn)
} else {
this.cache[name] = [fn]
}
}
off(name, fn) {
let tasks = this.cache[name]
if (tasks) {
const index = tasks.findIndex(f => f === fn || f.callback === fn)
if (index >= 0) {
tasks.splice(index, 1)
}
}
}
emit(name, once = false, ...args) {
if (this.cache[name]) {
// 创建副本,如果回调函数内继续注册相同事件,会造成死循环
let tasks = this.cache[name].slice()
for (let fn of tasks) {
fn(...args)
}
if (once) {
delete this.cache[name]
}
}
}
}
// 测试
let eventBus = new EventEmitter()
let fn1 = function(name, age) {
console.log(`${name} ${age}`)
}
let fn2 = function(name, age) {
console.log(`hello, ${name} ${age}`)
}
eventBus.on('aaa', fn1)
eventBus.on('aaa', fn2)
eventBus.emit('aaa', false, '布兰', 12)
// '布兰 12'
// 'hello, 布兰 12'