前言
代码来自github项目 neo4j-python-pandas-py2neo-v3,项目作者为Skyelbin。我记录一下运行该项目的一些过程文字以及遇到的问题和解决办法。
一、提取excel中的数据转换为DataFrame三元组格式
from dataToNeo4jClass.DataToNeo4jClass import DataToNeo4j
import os
import pandas as pd
# 提取excel表格中数据,将其转换成dateframe类型,dateframe相当于表格
# os.chdir('xxxx') 这块我注释掉了,没有什么用还报错
invoice_data = pd.read_excel('./Invoice_data_Demo.xls', header=0) # 用excel中的第一行作为表头
print(invoice_data)
def data_extraction():
"""节点数据抽取"""
# 取出发票名称到list
node_list_key = []
for i in range(0, len(invoice_data)): # len(invoice_data)是表格包含的数据总行数,表头一行不算入
node_list_key.append(invoice_data['发票名称'][i])
# 去除重复的发票名称
node_list_key = list(set(node_list_key))
# value抽出作node
node_list_value = []
for i in range(0, len(invoice_data)):
for n in range(1, len(invoice_data.columns)): # invoice_data.columns 返回所有列标签组成的列表
# 取出表头名称invoice_data.columns[n]
node_list_value.append(invoice_data[invoice_data.columns[n]][i]) # node_list_value存储除了发票名称外的所有行
# 去重
node_list_value = list(set(node_list_value))
# 将list中浮点及整数类型全部转成string类型
node_list_value = [str(i) for i in node_list_value]
return node_list_key, node_list_value
def relation_extraction():
"""关系数据抽取"""
links_dict = {}
name_list = []
relation_list = []
name2_list = []
for i in range(0, len(invoice_data)):
m = 0
name_node = invoice_data[invoice_data.columns[m]][i] #依次取第一列的发片名称值
# 将发票相关的26个属性值存储起来
while m < len(invoice_data.columns)-1:
relation_list.append(invoice_data.columns[m+1])
name2_list.append(invoice_data[invoice_data.columns[m+1]][i])
name_list.append(name_node)
m += 1
# 将数据中int类型全部转成string
name_list = [str(i) for i in name_list]
name2_list = [str(i) for i in name2_list]
# 整合数据,将三个list整合成一个dict,类似三元组形式
links_dict['name'] = name_list
links_dict['relation'] = relation_list
links_dict['name2'] = name2_list
# 将数据转成DataFrame
df_data = pd.DataFrame(links_dict)
return df_data
# 实例化对象
data_extraction()
relation_extraction()
create_data = DataToNeo4j()
create_data.create_node(data_extraction()[0], data_extraction()[1]) # 获取 node_list_key 和 node_list_value
create_data.create_relation(relation_extraction())
invoice_data 如下:
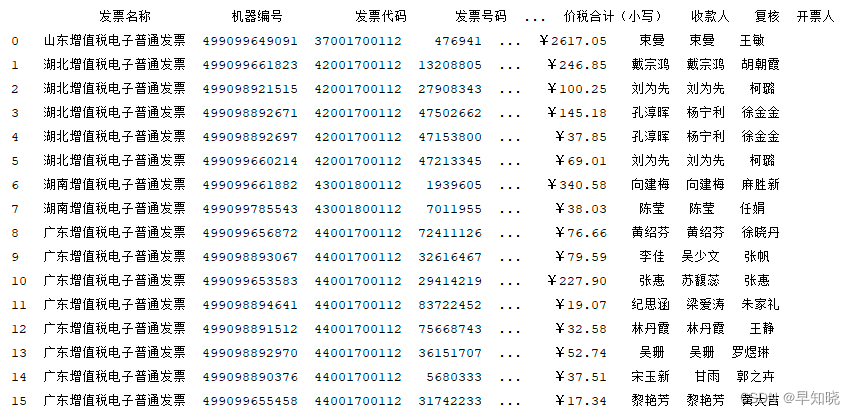
node_list_key 如下:

node_list_value 如下:
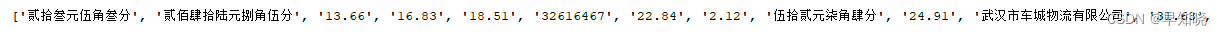
df_data 如下:

二、利用三元组在neo4j中构建节点和关系,形成可视化知识图谱
from py2neo import Node, Graph, Relationship
class DataToNeo4j(object):
"""将excel中数据存入neo4j"""
def __init__(self):
"""Graph实例化,建立数据库连接"""
link = Graph("http://localhost:7474", username="neo4j", password="neo4j") # 填写neo4j数据库账户和密码,默认都是neo4j
self.graph = link
# 定义label
self.invoice_name = '发票名称'
self.invoice_value = '发票值'
self.graph.delete_all() # 删除所有图
def create_node(self, node_list_key, node_list_value):
"""建立节点"""
for name in node_list_key:
name_node = Node(self.invoice_name, name=name) # 定义节点
self.graph.create(name_node)
for name in node_list_value:
value_node = Node(self.invoice_value, name=name)
self.graph.create(value_node)
def create_relation(self, df_data):
"""建立联系"""
m = 0
for m in range(0, len(df_data)):
try:
rel = Relationship(self.graph.find_one(label=self.invoice_name, property_key='name', property_value=df_data['name'][m]),
df_data['relation'][m], self.graph.find_one(label=self.invoice_value, property_key='name',
property_value=df_data['name2'][m]))
self.graph.create(rel) # 创建35个关系
except AttributeError as e:
print(e, m)
构建的知识图谱如下所示:

压缩包里其他文件说明(个人理解):
- jieba_code 文件夹:是实现 jieba 分词的,要用到 mysql 数据库;
- neo4j_matrix.py:将知识图谱转化为矩阵,为其他算法做数据基础;
- neo4j_to_dataframe.py:在知识图谱中查询节点,利用基本的Cypher语句实现。
因为我只需要学习构建知识图谱,所以其他的内容并未运行,想要简单了解的小伙伴可以跑起来试试~
总结
基于存储在excel中的半结构化数据构建知识图谱的大致流程:将excel中的数据转换为dataframe格式的数据,此处需要注意excel中每行数据都要转化为多个三元组,此时已经获取三元组数据了,然后在neo4j中构建节点和关系就建立起基本的知识图谱啦~
原创说明
博文作者:早知晓
博文链接:Click here
转载请注明出处,谢谢合作~
祝大家都走在前进的路上,一路鲜花掌声。