基于telegraf进行自定义插件开发(二)
- 前言
- 正文
- 设计
- 开发过程
- 单个服务的处理
- 结构体同时定义了string和数值类型
- 适配本机服务或者多个ip来源
- 程序打包
- 结语
前言
书接上会,这次记录一下我基于telegraf进行的hdfs监控组件的开发工作,这其中也包括了开发完成后如何进行打包等事项。
我的应用场景是,依赖于telegraf去监控大数据组件,所以第一个开发的就是hdfs的采集插件。
正文
设计
开始写代码前,大概规划一下整体的目录,我的想法是,除去README.md和sample.conf文件以外,将Namenode、JournalNode、DataNode组件的个性指标获取方法分开存放,然后把指标的清单放在单独的文件中:

metrics.go中定义了全部的指标:
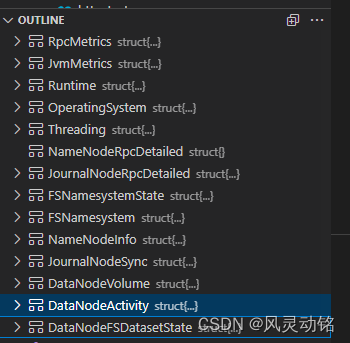
接下来是input的配置块部分,原先我考虑把组件拆分开来,后来觉得那样要整好几个目录,太麻烦,而且从设计的概念上来说,我希望在所有有服务的节点上都部署telegraf,所以每一个telegraf只需要负责自己本机的服务的指标采集,最终定义这样的HDFS结构体:
type HDFS struct {
Scheme string `toml:"scheme"`
ResponseTimeout config.Duration `toml:"response_timeout"`
NameNode *NameNode `toml:"namenode"`
JournalNode *JournalNode `toml:"journalnode"`
DataNode *DataNode `toml:"datanode"`
// tls option
tls.ClientConfig
// http client
client *http.Client
Log telegraf.Logger
}
type NameNode struct {
Servers []string `toml:"servers"`
HttpPort int `toml:"http_port"`
RpcPort int `toml:"rpc_port"`
}
三种角色的结构体和NameNode一致,只需要提供服务器清单、http端口和rpc端口即可。
开发过程
单个服务的处理
以Namenode指标数据的获取为例,其实就是通过jmx获取json数据,然后进行解析,以RPC指标为例,结构体细节如下:
type RpcMetrics struct {
ReceivedBytes float32 `json:"ReceivedBytes"`
SentBytes float32 `json:"SentBytes"`
RpcQueueTimeNumOps float32 `json:"RpcQueueTimeNumOps"`
RpcQueueTimeAvgTime float32 `json:"RpcQueueTimeAvgTime"`
RpcProcessingTimeNumOps float32 `json:"RpcProcessingTimeNumOps"`
RpcProcessingTimeAvgTime float32 `json:"RpcProcessingTimeAvgTime"`
RpcAuthenticationFailures float32 `json:"RpcAuthenticationFailures"`
RpcAuthenticationSuccesses float32 `json:"RpcAuthenticationSuccesses"`
RpcAuthorizationFailures float32 `json:"RpcAuthorizationFailures"`
RpcAuthorizationSuccesses float32 `json:"RpcAuthorizationSuccesses"`
NumActiveRpcHandler float32 `json:"NumActiveRpcHandler"`
RpcClientBackoff float32 `json:"RpcClientBackoff"`
RpcSlowCalls float32 `json:"RpcSlowCalls"`
NumOpenConnections float32 `json:"NumOpenConnections"`
CallQueueLength float32 `json:"CallQueueLength"`
NumDroppedConnections float32 `json:"NumDroppedConnections"`
}
每一块的指标数据都用单独的方法进行处理,这样方便进行代码的划分,处理rpc指标的方法在这里就是gatherRpcMetrics:
func (h *HDFS) gatherRpcMetrics(data map[string]interface{}, role string, acc telegraf.Accumulator, tags map[string]string, rpcMetrics *RpcMetrics) error {
if err := bindToStruct(rpcMetrics, data); err != nil {
return err
}
rpcFields, err := convertor.StructToMap(*rpcMetrics)
if err != nil {
return err
}
acc.AddGauge(fmt.Sprintf("hdfs_%s_rpc", role), rpcFields, tags)
return nil
}
传入的data数据就是指标数据,是个map,role变量是为了方法能够复用,hdfs的journanode、datanode、namenode都有rpc指标,在进行获取的时候打上role,acc和tags不用多说,是为了生成指标用的,rpcMetrics就是我们生成的一个空的结构体,rpc的指标比较特殊,全都是浮点型,所以可以借助lancet库的StructToMap方法直接把指标结构转成map,这样就省去了写field结构体的功夫了;
最后通过AddGauge方法把直接增加上,就完成了一个指标的获取、处理、注册了。
结构体同时定义了string和数值类型
在进行指标获取的过程中,遇到了一个问题,那就是指标结构体中既有string类型又有float32类型,因为我在把结构体转成map的时候,统一使用的StructToMap这个方法,虽然这个方法能够自动的也把string转化,但是这在telegraf的指标注册是会有问题,如下:
threadingField := map[string]interface{}{
"CurrentThreadCpuTime": "123123",
"CurrentThreadUserTime": 1
}
acc.AddGauge(fmt.Sprintf("hdfs_test_threading", role), threadingField, tags)
上面的这个指标,注册后会产生一个hdfs_test_threading{"CurrentThreadCpuTime"="123123"} 1的指标,字符串数据会被自动打成label,有这种特征的指标在进行结构体设计的时候要这样做:
FSNamesystem struct {
IsActive float32 `json:"IsActive"`
FSNamesystemMsg `json:",inline"`
}
FSNamesystemMsg struct {
ExpiredHeartbeats float32 `json:"ExpiredHeartbeats"`
TransactionsSinceLastCheckpoint float32 `json:"TransactionsSinceLastCheckpoint"`
TransactionsSinceLastLogRoll float32 `json:"TransactionsSinceLastLogRoll"`
LastWrittenTransactionId float32 `json:"LastWrittenTransactionId"`
LastCheckpointTime float32 `json:"LastCheckpointTime"`
CapacityTotal float32 `json:"CapacityTotal"`
CapacityTotalGB float32 `json:"CapacityTotalGB"`
}
把数值的指标放在一个结构体中,其他类型的放在上层里,在进行解析的时候就能正常的进行解析了。
适配本机服务或者多个ip来源
一开始在进行设计的时候,考虑到可能会在一个节点上采集多个其他节点的服务指标,所以就允许服务器信息写成list,比如servers = ["host01", "host02"],在进行指标获取时,直接启动协程进行操作:
if h.NameNode != nil {
servers := getNodeList(h.NameNode.Servers)
var wg sync.WaitGroup
wg.Add(len(servers))
for _, nn := range servers {
go func(namenode string) {
defer wg.Done()
conf := make(map[string]string)
var nameservice string
url := setConfUrl(h.Scheme, namenode, h.NameNode.HttpPort)
if err := h.getXml(url, conf); err == nil {
nameservice = conf["dfs.nameservices"]
}
tags := map[string]string{"nn": namenode, "nameservice": nameservice}
if err := h.gatherAllNamenodeMetrics(namenode, acc, tags); err != nil {
acc.AddGauge("hdfs_namenode_state", map[string]interface{}{"Healthy": 0}, tags)
acc.AddError(fmt.Errorf("can not get jmx data from namenode %s", namenode))
}
}(nn)
}
wg.Wait()
}
程序打包
telegraf提供了makefile文件进行打包操作,可以直接输入make help查看具体的使用方式,注意,打包文件中使用fpm命令作为打包工具,因此需要自己安装ruby语言环境和fpm工具,我的建议是安装尽量高版本的ruby,否则可能出现各种问题,原先我安装的2.3版本在执行fpm的时候就有问题,可以选择我用的2.6.5p114版本:
[root@bigdata-m-002 telegraf]# ruby --version
ruby 2.6.5p114 (2019-10-01 revision 67812) [x86_64-linux]
[root@bigdata-m-002 telegraf]# fpm -v
1.15.1
这里举个例子,比如我们准备编译成tag.gz包,使用以下命令:
make package include_packages="linux_amd64.tar.gz"
如果想要自定义一部分打包的操作,比如希望打包的tag.gz包中有自己增加的脚本文件,只需要在install部分进行增加:
.PHONY: install
install: $(buildbin)
@mkdir -pv $(DESTDIR)$(bindir)
@mkdir -pv $(DESTDIR)$(sysconfdir)
@mkdir -pv $(DESTDIR)$(localstatedir)
@if [ $(GOOS) != "windows" ]; then mkdir -pv $(DESTDIR)$(sysconfdir)/logrotate.d; fi
@if [ $(GOOS) != "windows" ]; then mkdir -pv $(DESTDIR)$(localstatedir)/log/telegraf; fi
@if [ $(GOOS) != "windows" ]; then mkdir -pv $(DESTDIR)$(sysconfdir)/telegraf/telegraf.d; fi
@cp -fv $(buildbin) $(DESTDIR)$(bindir)
@if [ $(GOOS) != "windows" ]; then cp -fv etc/telegraf.conf $(DESTDIR)$(sysconfdir)/telegraf/telegraf.conf$(conf_suffix); fi
@if [ $(GOOS) != "windows" ]; then cp -fv etc/logrotate.d/telegraf $(DESTDIR)$(sysconfdir)/logrotate.d; fi
@if [ $(GOOS) = "windows" ]; then cp -fv etc/telegraf_windows.conf $(DESTDIR)/telegraf.conf; fi
@if [ $(GOOS) = "linux" ]; then scripts/check-dynamic-glibc-versions.sh $(buildbin) $(glibc_version); fi
@if [ $(GOOS) = "linux" ]; then mkdir -pv $(DESTDIR)$(prefix)/lib/telegraf/scripts; fi
@if [ $(GOOS) = "linux" ]; then cp -fv scripts/telegraf.service $(DESTDIR)$(prefix)/lib/telegraf/scripts; fi
@if [ $(GOOS) = "linux" ]; then cp -fv scripts/init.sh $(DESTDIR)$(prefix)/lib/telegraf/scripts; fi
@if [ $(GOOS) = "linux" ]; then cp -fv scripts/install_telegraf_cs6.sh $(DESTDIR)$(prefix)/install_telegraf_cs6.sh; fi
如上,我添加了最后一个部分,增加了centos6的telegraf安装脚本,方便我的一键部署,接下来直接进行打包即可:
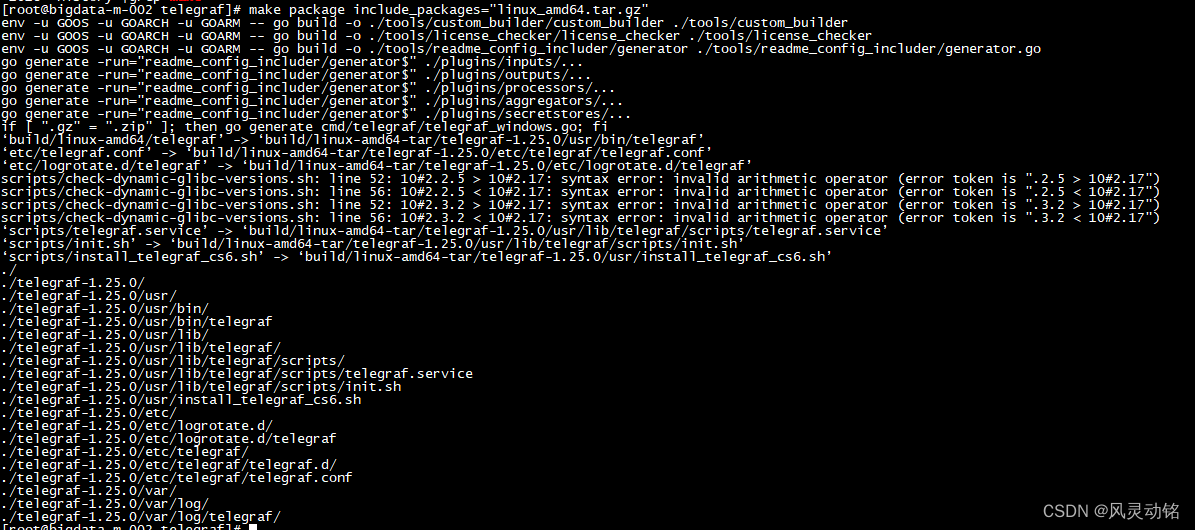
打包完成后,程序包会放在build/dist/下:

结语
本文介绍了基于telegraf实现了一个自己的hdfs指标采集器,下一次要面对将node-exporter采集的指标替换成telegraf的改造过程,完成整个平台的采集器all-in-one变革!