客户端开发
生产者就是负责向kafka发送消息的应用程序。一个正常的生产逻辑的步骤为:
-
配置生产者客户端参数及创建相应的生产者实例。
-
构建待发送的消息。
-
发送消息。
-
关闭生产者实例。
在创建真正的生产者实例前需要配置相应的参数,比如需要连接的Kafka集群地址。在Kafka生产者客户端KafkaProducer中有3个参数是必填的:
-
bootstrap. servers: 该参数用来指定生产者客户端连接Kafka集群所需的broker地址清单。
-
key.serializer和value.serializer:这两个参数分别用来指定key和value 序列化操作的序列化器,参数无默认值。
在配置完参数之后,这样创建一个生产者实例:
KafkaProducer<String, String> producer = new KafkaProducer<>(props);接下来需要构建消息,也就是创建ProducerRecord对象。ProducerRecord类的定义属性如下:
-
topic //发往的主题
-
partition //发往消息的分区号
-
headers //消息头部
-
key //键
-
value //值
-
timestamp //消息的实践戳
消息以主题为单位进行分类,而这个key可以让消息再进行二次分类,同一个key会被划分到同一个分区。
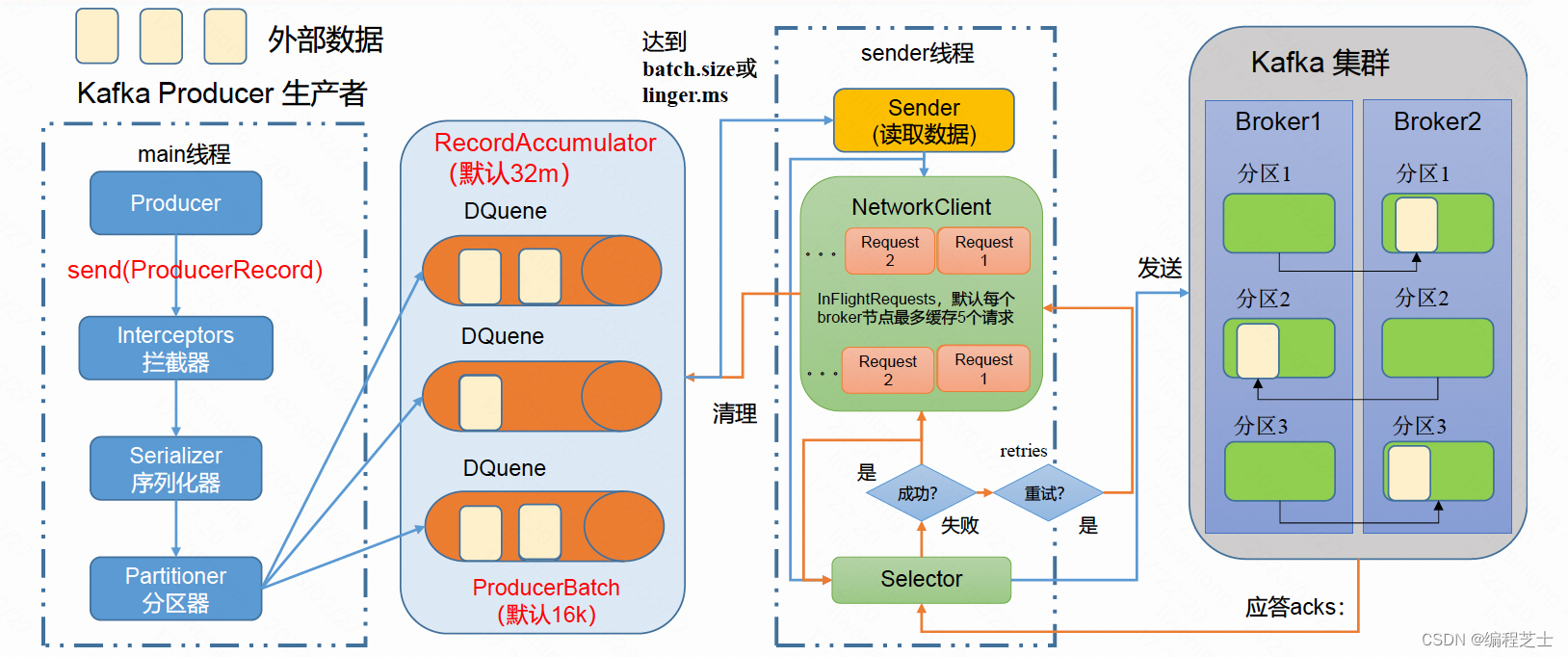
消息分区
1. 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
2. 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
生产者发送消息的分区策略:
1. 指明partition的情况下,直接将指明的值作为partition值; 例如partition=0,所有数据写入分区0。
2. 没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1 对应的value1写入1号分区,key2对应的value2写入0号分区。
3. 既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)。
ACK应答机制

Kafka的Producer有三种ack机制,参数值有0、1 和 -1
acks = 0: 相当于异步操作,Producer 不需要Leader给予回复,发送完就认为成功,继续发送下一条消息。这个机制下延迟最低,但是持久性可靠性也最差,当服务器发生故障时,很可能发生数据丢失。
acks = 1: Kafka 默认的设置。表示 Producer 要 Leader 确认已成功接收数据才发送下一条消息。不过 Leader 宕机,Follower 尚未复制的情况下,数据就会丢失。这个机制提供了比较好的持久性和较低的延迟性。
acks = -1: Leader 接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都确认消息已同步,Producer 才发送下一条消息。此机制持久性可靠性最好,但延时性最差。
思考:Leader收到数据,所有Follower都开始同步数据,但有一个Follower,因为某种故障,迟迟不能与Leader进行同步,那这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set(ISR),意为和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,(leader:0, isr:0,1)。这样就不用等长期联系不上或者已经故障的节点。