在学习得到的模型投放使用之前,通常需要对其进行性能评估。为此,需使用一个“测试集”(testing set)来测试模型对新样本的泛化能力,然后以测试集上的“测试误差( tootino error)作为泛化误差的近似。
我们假设测试集是从样本真实分布中独立采样获得,所以测试集要和训练集中的样本尽量互斥。
给定一个已知的数据集,将数据集拆分成训练集S和测试集T,通常的做法包括留出法、交叉验证法、自助法。
留出法:
√直接将数据集划分为两个互斥集合
√训练/测试集划分要尽可能保持数据分布的一致性
√一般若干次随机划分、重复实验取平均值
√训练/测试样本比例通常为2:1~4:1
交叉验证法:
将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试集,最终返回k个测试结果的均值,k最常用的取值是10。
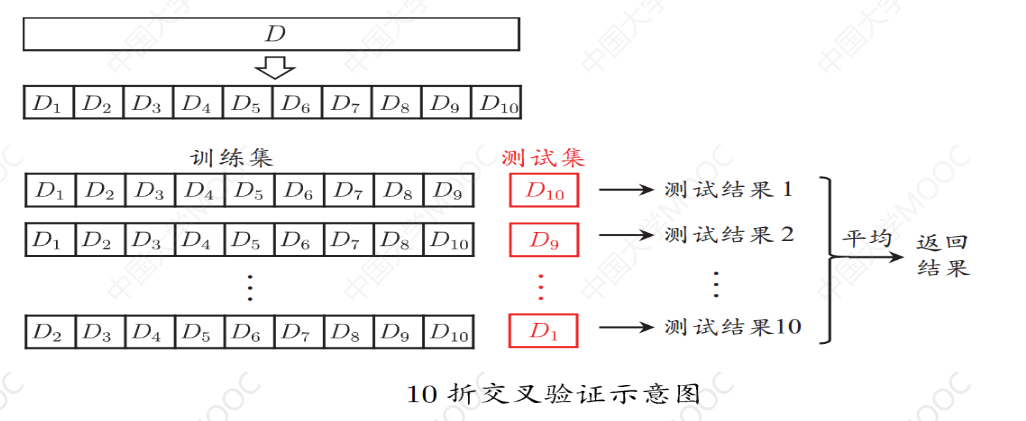
交叉验证法:
将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试集,最终返回k个测试结果的均值,k最常用的取值是10。
与留出法类似,将数据集D划分为k个子集同样存在多种
划分方式,为了减小内样本划分→丹八的左A折交叉验证通常随机使用不同的划分重复p次,最终的
评估结果是这p次k折交叉验证结果的均值,例如常见的“10次10折交叉验证”。
自助法:
以自助采样法为基础,对数据集D有放回采样m次得到训练集D',D \D'用做测试集
√实际模型与预期模型都使用m个训练样本
√约有1/3的样本没在训练集中出现,用作测试集√从初始数据集中产生多个不同的训练集,对集成学习有很大的好处
√自助法在数据集较小、难以有效划分训练/测试集时很有用;
由于改变了数据集分布可能引入估计偏差,在数据量足够时,留出法和交叉验证法更常用。
所谓评估指标就是衡量稳型之化能力分1的广向的步仕结果任务需求;
使用不同的评估指标往往会导致不同的评估结果。
在分类预测任务中,给定测试样例集,评估分类模型的性能就是把对每一个待测样本的分类结果和它的真实标记比较。
因此,准确率和错误率是最常用的两种评估指标:
√准确率就是分对样本占测试样本总数的比例
√错误率就是分错样本占测试样本总数的比例
由于准确率和错误率将每个类看的同等重要,因此不适合用来分析类不平衡数据集。在类不平衡数据集中,正确分类稀有类比正确分类多数类更有意义。此时查准率和查全率比准确率和错误率更适合。对于二分类问题,稀有类样本通常记为正例,而多数类样本记为负例。统计真实标记和预测结果的组合可以得到如下所示的混淆矩阵:
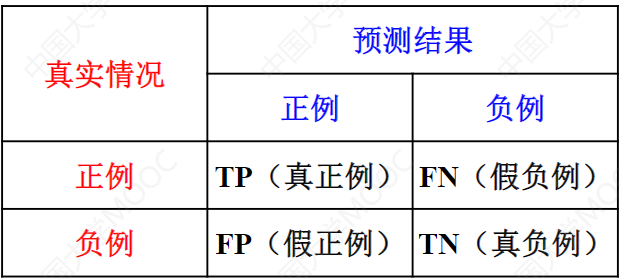
查准率(P)就是被分为正类的样本中实际为正类的样本比例:
P=TP/(TP+FP)
查全率(R)就是实际为正类的样本中被分为正类的样本比例:
R=TP/(TP+FN)
可见,查准率是被分类器分为正类的样本中实际为正类的比例;而查全率是被分类器正确分类为正类的比例。二者通常是矛盾的。查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。为综合考虑查准率和查全率,它们的调和均值F1度量被提出︰


β=1∶标准的F1
β>1∶偏重查全率
β<1∶偏重查准率
真正率(TPR)就是被分为正类的正样本比例:
TPR=TP/(TP+FN)
假正率(FPR)就是被分为正类的负样本比例:
FPR=FP/(FP+TN)

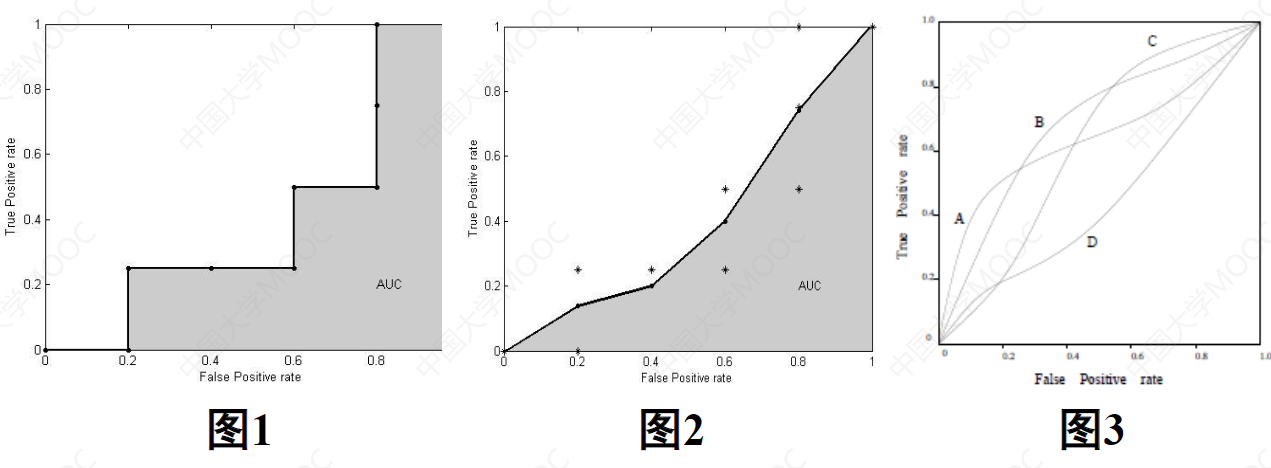
若某个分类器的ROC曲线被另一个分类器的曲线“包住”,则后者性能优于前者;否则如果曲线交叉,可以根据ROC曲线下面积的大小进行比较,即AUC (AreaUnder ROC Curve)
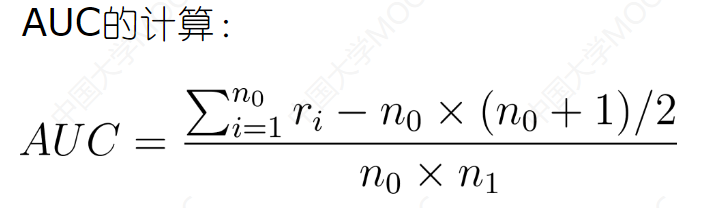
其中,n0和n1分别表示反例和正例的个数,ri分别为第i个反例(-)在整个测试样例中的排序。
AUC度量了分类器预测样本排序的性能。
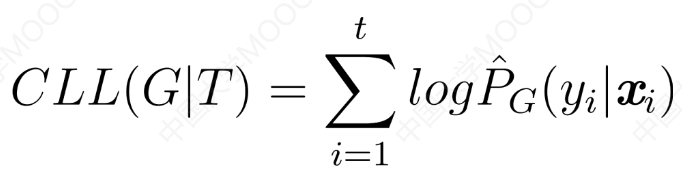
CLL度量了分类器预测样本类成员概率的性能。
关于性能比较:
√测试性能并不等于泛化性能
√测试性能会随着测试集的变化而变化
√很多机器学习算法本身有一定的随机性
直接选取相应评估方法在相应度量下比大小的方法不可取!



![[Android Studio] Android Studio使用keytool工具读取Debug 调试版数字证书以及release 发布版数字证书](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)