消息中间件的作用
1.正向作用
应用解耦/事件驱动
异步通信
流量削峰
2.反向作用
系统可用性降低
系统复杂性提高
一致性问题
---------------------------------------------------------------------------------------------------------------------------------
ActiveMQ【Java JMS】
java开发
jms协议
Apache ActiveMQ是Apache软体基金会所研发的开放原始码讯息中间件;由于ActiveMQ是一个纯Java程式,因此只需要作业系统支持Java虚拟机,ActiveMQ便可执行。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
作用原理
Activemq 的作用就是系统之间进行通信,原理就是生产者生产消息, 把消息发送给activemq, Activemq 接收到消息, 然后查看有多少个消费者,然后把消息转发给消费者, 此过程中生产者无需参与。 消费者接收到消息后做相应的处理和生产者没有任何关系。
通信方式
publish-subscribe(发布-订阅方式)
point-to-point(点对点)
消息持久化机制【activemq.xml】
JDBC: 持久化到数据库
AMQ :日志文件
KahaDB : AMQ基础上改进【默认】
LevelDB :谷歌K/V数据库
消息确认机制
AUTO_ACKNOWLEDGE = 1 自动确认
CLIENT_ACKNOWLEDGE = 2 客户端手动确认
DUPS_OK_ACKNOWLEDGE = 3 自动批量确认
SESSION_TRANSACTED = 0 事务提交并确认
INDIVIDUAL_ACKNOWLEDGE = 4 单条消息确认
高可用
单节点部署【不支持高可用】
Master-Slave部署方式【主从模式-支持高可用】
Broker-Cluster部署方式【负载均衡-支持高可用】
消息丢失问题
1.生产者丢失消息的问题可以通过消息重投、重试机制来解决
2.ActiveMQ丢失消息的问题需要通过ActiveMQ消息持久化机制+高可用解决。
3.消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
消息顺序问题
ActiveMQ因为默认是单queue 队列,所以它模式就是保证消息顺序性消费的。
---------------------------------------------------------------------------------------------------------------------------------
RabbitMQ【Erlang AMQP】
erlang开发
AMQP协议
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
作用原理
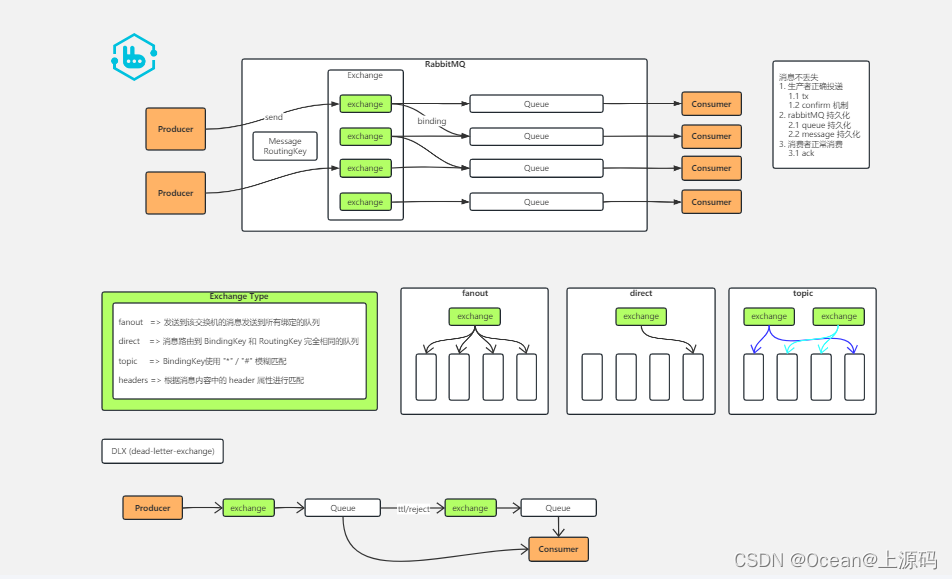
组件
| 组件 | 说明 |
| Channel(信道) | 消息推送使用的通道 |
| Producer(消息生产者) | 向消息队列发布消息的客户端 |
| Consumer(消息消费者) | 从消息队列获取消息的客户端 |
| Message(消息) | 消息队列中存放的内容(消息头+消息体) |
| Routing Key(路由键) | 消息头中的属性,标记消息路由规则,决定交换机转发路径 |
| Queue(消息队列) | 存储生产者发布的消息 |
| Exchange(交换器路由器) | 提供Producer到Queue的匹配 |
| Binding(绑定) | 建立Exchange与Queue的关联 |
| Binding Key(绑定健) | 建立Exchange与Queue的关联(Routing Key) |
| Broker(服务主体) | RabbitMq的服务器实体 |
通信方式
简单队列(一对一)
一个消息生产者,一个消息消费者,一个队列。
工作队列模式(一对多)
一个消息生产者,一个交换器,一个消息队列,多个消费者。
发布订阅模式(Pulish/Subscribe)
一个消息生产者,一个交换机(交换机类型为fanout),多个消息队列,多个消费者;生产者只需把消息发送到交换机,绑定这个交换机的队列都会获得一份一样的数据。
路由模式(Routing)
在发布/订阅模式的基础上,有选择的接收消息,也就是通过 routing 路由进行匹配条件是否满足接收消息。
主题模式(Topic)
topics(主题)模式跟routing路由模式类似,只不过路由模式是指定固定的路由键 routingKey,而主题模式是可以模糊匹配路由键 routingKey,类似于SQL中 = 和 like 的关系。
RPC模式
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的处理业务,处理完后然后在A服务器继续执行下去,把异步的消息以同步的方式执行。

消息持久化机制【activemq.xml】
Queue(消息队列)的持久化是通过durable=true来实现的。
Message(消息)的持久化 ,通过设置消息是持久化的标识。
Exchange(交换机)的持久化 。
消息确认机制
confirm机制:确认消息是否成功发送到Exchange
ack机制:确认消息是否被消费者成功消费
AcknowledgeMode.NONE:自动确认
AcknowledgeMode.AUTO:根据情况确认
AcknowledgeMode.MANUAL:手动确认
消高可用
单机模式【不支持高可用】
普通集群模式【不支持高可用】
镜像集群模式【支持高可用】
消息丢失问题
1.生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制。
2.RabbitMQ丢失消息的问题需要通过RabbitMQ消息持久化机制+高可用来解决。
3.消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
消息顺序问题
将RabbitMQ拆分多个 queue,每个 queue 一个 consumer,保证消息的顺序性。一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
---------------------------------------------------------------------------------------------------------------------------------
RocketMQ【java NameServer】
java开发
nameServer无状态节点
RocketMQ 是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给 Apache 软件基金会,并于2017年9月25日成为 Apache 的顶级项目。作为经历过多次阿里巴巴双十一的洗礼并有稳定出色表现的国产中间件,以其高性能、低延时和高可靠等特性近年来已经也被越来越多的企业使用。
作用原理
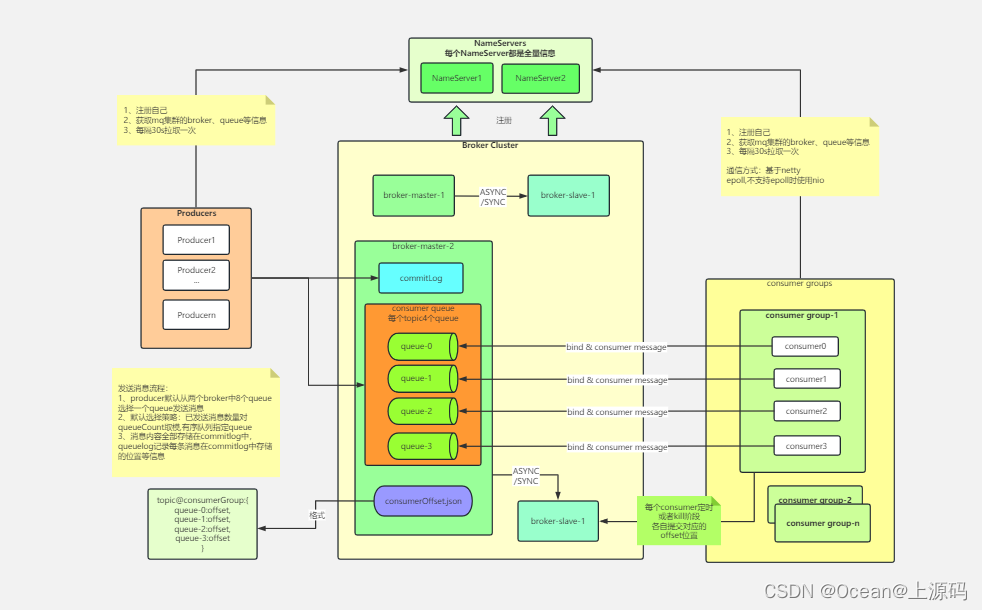
组件
| 组件 | 说明 |
| Producer | 消息生产者 |
| Producer Group | 生产者组 |
| Consumer | 消息消费者 |
| Consumer Group | 消费者组 |
| Topic | 消息主题,生产者将消费发送到Topic,消费者订阅Topic |
| Message | 消息 |
| Tag | Topic的细化,标签 |
| Broker | 接收消息、存储消息 |
| Queue | 一个Topic对应多个Queue(负载均衡) |
| Offset | Topic下Queue的索引,Offset存在当前Queue中 |
| NameServer | 注册中心 |
通信方式
集群模式和广播模式
集群模式:消费者组收到消息后,只有其中的一台机器会接收到消息。
广播模式:消费者组内的每台机器都会收到这条消息。
Push模式和 Pull模式
Push(MQPushConsumer)和Pull模式(MQPullConsumer)本质都是采用消费端主动拉取的方式,即consumer轮询从broker拉取消息
消息持久化机制
exchange持久化
queue持久化
message持久化
消息确认机制
confirm机制:确认消息是否成功发送到Exchange
ack机制:确认消息是否被消费者成功消费
高可用
单节点模式【不支持高可用】
多节点模式【多Master模式【不支持高可用】、多Master多Slave模式【异步复制-支持高可用】、多Master多Slave模式【同步双写-支持高可用】】
消息丢失问题
1.生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制。
2.RocketMQ丢失消息的问题需要通过RocketMQ消息持久化机制+高可用来解决。
3.消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
消息顺序问题
RocketMQ保证消息顺序性方法与Kafka大致相同。一个 topic,一个 queue,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
---------------------------------------------------------------------------------------------------------------------------------
Kafka【Scala ZK注册中心】
Scala(java)开发
ZK注册中心
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
作用原理
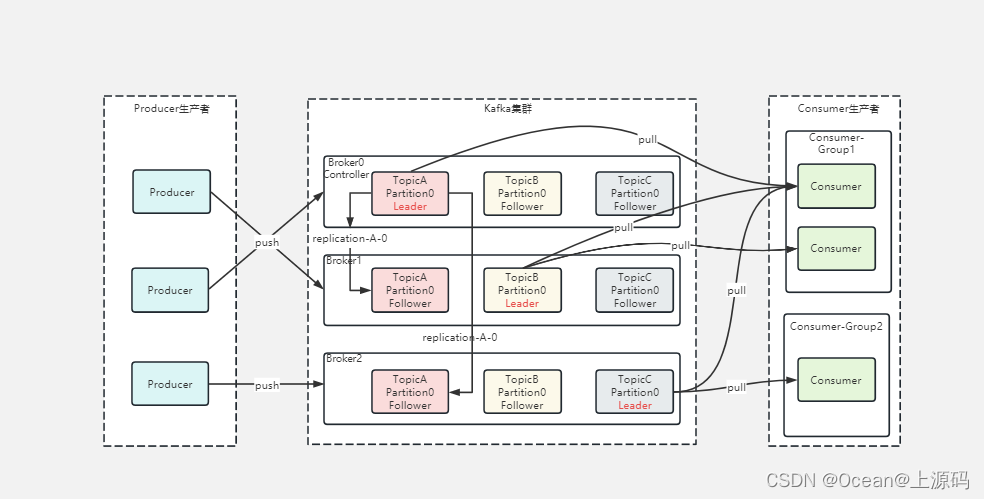
组件
| 组件 | 说明 |
| Producer | 生产者 |
| Consumer | 消费者 |
| Consumer Group | 消费者组 |
| Broker | 一个kafka服务器就是一个broker,一个集群由多个broker组成,一个broker中包含多个topic |
| Topic | 一个消息队列,生产者和消费者都对应一个Topic |
| Partition | 一个Partition一个有序队列,Partition是Topic中存储数据和消息所使用队列的容器 |
| Replica | 副本 |
| Leader | 主分区,生成者生产数据的对象,消费组消费数据的对象 |
| Follower | 副分区 |
通信方式
生产者发送模式
1.发后即忘(fire-and-forget):只管往Kafka中发送消息而并不关心消息是否正确到达
2.同步(sync):一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。
3.异步(async):send()方法会返回Futrue对象,通过调用Futrue对象的get()方法,等待直到结果返回
消费者消费模式
1.At-most-once(最多一次):在每一条消息commit成功之后,再进行消费处理;设置自动提交为false,接收到消息之后,首先commit,然后再进行消费。
2.At-least-once(最少一次):在每一条消息处理成功之后,再进行commit;设置自动提交为false;消息处理成功之后,手动进行commit。
3.Exactly-once(正好一次):将offset作为唯一id与消息同时处理,并且保证处理的原子性;设置自动提交为false;消息处理成功之后再提交。
消息持久化机制
Kafka直接将数据写入到日志文件中,以追加的形式写入
消息确认机制
confirm机制:确认消息是否成功发送
ack机制:确认消息是否被消费者成功消费
高可用
单broke节点【不支持高可用】
单机多broker模式【支持高可用】
多机多broker模式【支持高可用】
消息丢失问题
1.生产者消息丢失,通过confirm机制来确认消息发送,然后进行相应的消息重投、重试机制。
2.Kafka直接将数据写入到日志文件中,以追加的形式写入。
3.消费者丢失消息通过ack机制来解决,消息者进行业务处理后,再进行ack确认,避免消息丢失。
消息顺序问题
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
---------------------------------------------------------------------------------------------------------------------------------
终极消息丢失问题
在处理生产者消息丢失问题、消息丢失问题、消费者丢失问题后,并不能100%保证消息丢失问题,可以添加数据库辅助记录:生产者发送消息时同步发送一条消息到数据库中,消费者拿到消息并完成业务处理后,从数据库删除对应的记录。
MQ终极问题
原理,高可用,重复消息,顺序读写,数据丢失几个方面开展。




![[C++]继承](https://img-blog.csdnimg.cn/f91213794c95402b80f94acf77a9b4e0.png)