http
1.简介
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了HTTP超文本传输协议标准架构的发展根基。Ted Nelson组织协调万维网协会(World Wide Web Consortium)和互联网工程工作小组(Internet Engineering Task Force )共同合作研究,最终发布了一系列的RFC,其中著名的RFC 2616定义了HTTP 1.1。
超文本传输协议,是我们浏览网页、看在线视频、听在线音乐等必须遵循的规则。正是在这样的规则下,浏览器(万维网客户)才能向万维网服务器发送万维网文档请求,然后服务器会将请求的文档发送回浏览器。在浏览器和服务器之间的请求和响应的交互,必须按照规定的格式和规则,这些格式和规则就构成了超文本传输协议。
计算机系统中有一个专门为HTTP开放的80端口,主要用于万维网传输信息的协议。每个万维网网点(可以是计算机)都有一个服务器进程来监听TCP的80端口,一旦发现浏览器向它发出连接建立请求,继而建立TCP连接,浏览器就向万维网服务器发出浏览某个网页的请求,服务器就接着返回所请求的页面作为响应。最后,TCP连接被释放。
需要说明的是,HTTP协议是无状态的,也就是说同一个客户第二次访问同一个服务器上面的页面时,服务器的响应与第一次访问时的相同。服务器并不知道曾经访问过此客户,更不会记得此客户曾经被服务过多少次了。但是,在实际工作中一些万维网站点还是希望能够识别用户的。比如,你在某个购物网站上将某个产品加入购物车后,希望继续浏览并选购其它商品,这时服务器就需要记住用户的身份以便所有的商品可以一起结账。
HTTP中的Cookie提供了这种功能。Cookie是这样工作的:当用户(代号为User)访问某个使用Cookie的网站时,该网站就会为User产生一个唯一的识别码并以此作为索引在服务器的后端数据库中产生一个项目。接着在给User的HTTP响应报文(关于HTTP的报文结构附录会有介绍,读者可以先看那部分内容)中添加Set-cookie的首部行。这里的"首部字段名"为"Set-cookie",后面的"值"就是赋予该用户的"识别码"。例如这个首部行为:Set-cookie:09876543。
当User收到这个响应时,其浏览器就在它管理的特定Cookie文件中添加一行,其中包括这个服务器的主机名和Set-cookie后面给出的识别码。当User继续浏览这个网站时,每发送一个HTTP请求报文,其浏览器就会从其Cookie文件中取出这个网站的识别码并放到HTTP请求报文的Cookie首部行中:Cookie:09876543。于是这个网站就能够跟踪User在这个网站的活动,也就能够实现购买的商品一起付费了。服务器和用户的交集仅仅在于这个识别码,服务器不知道User的其它任何信息。

2. http版本
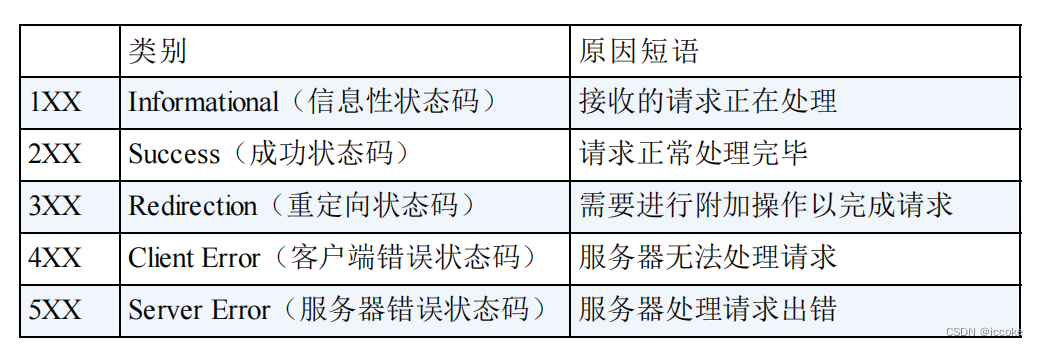
2xx
200表示成功
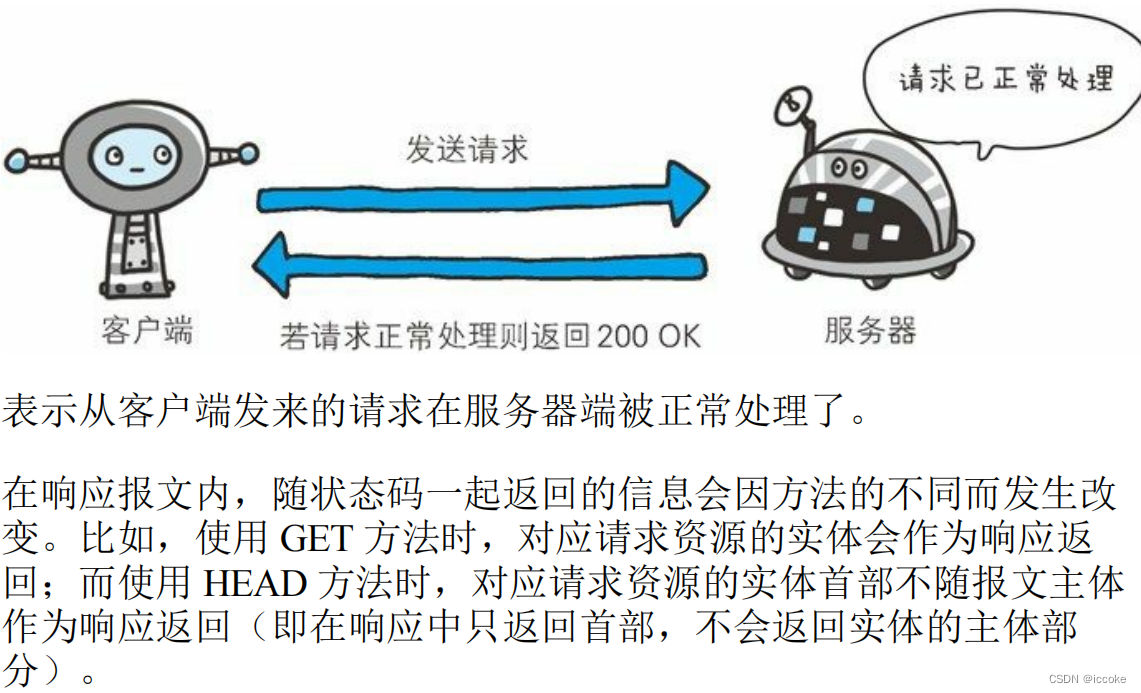
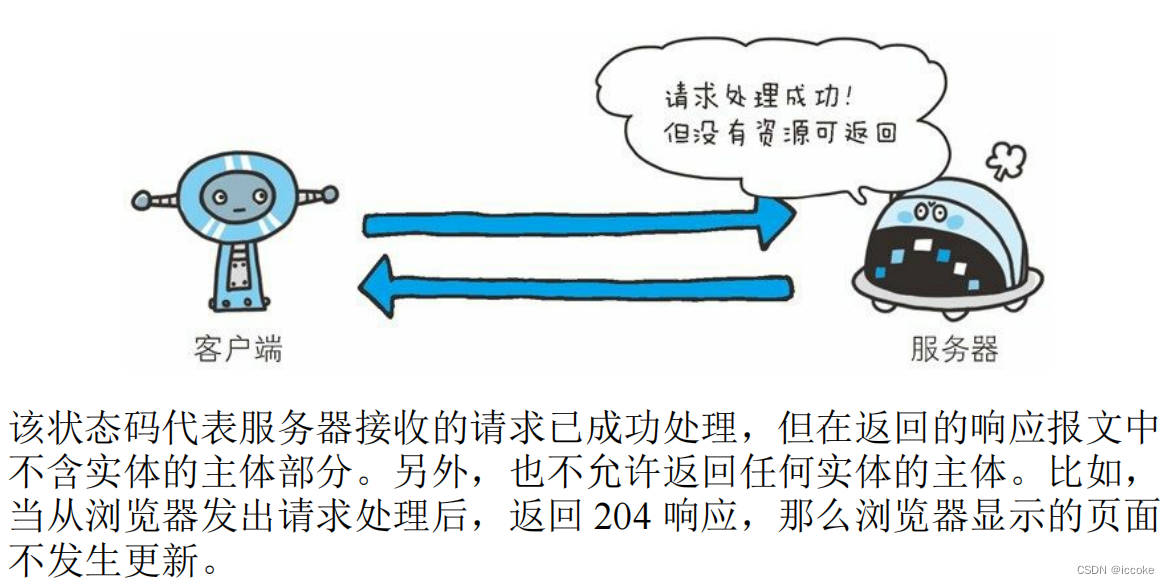
204表示该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分
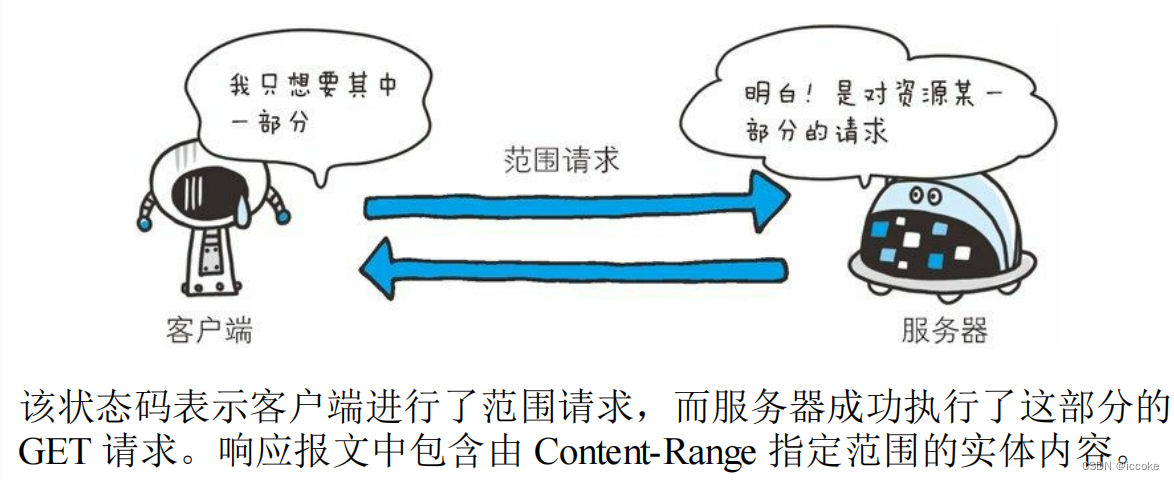
206表示对某一段范围的请求
3xx
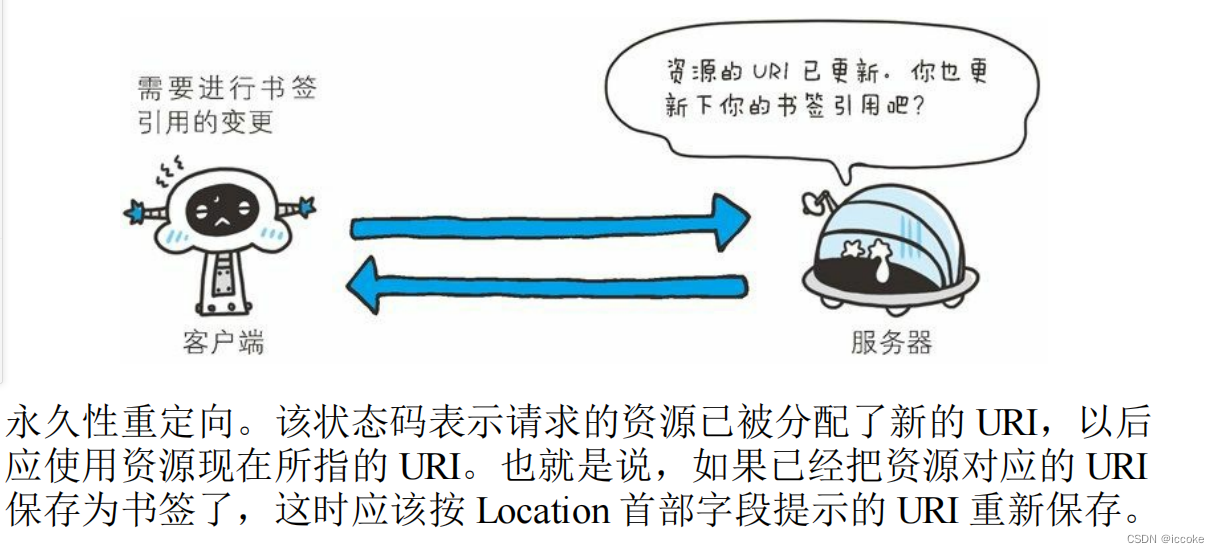
301资源已更新
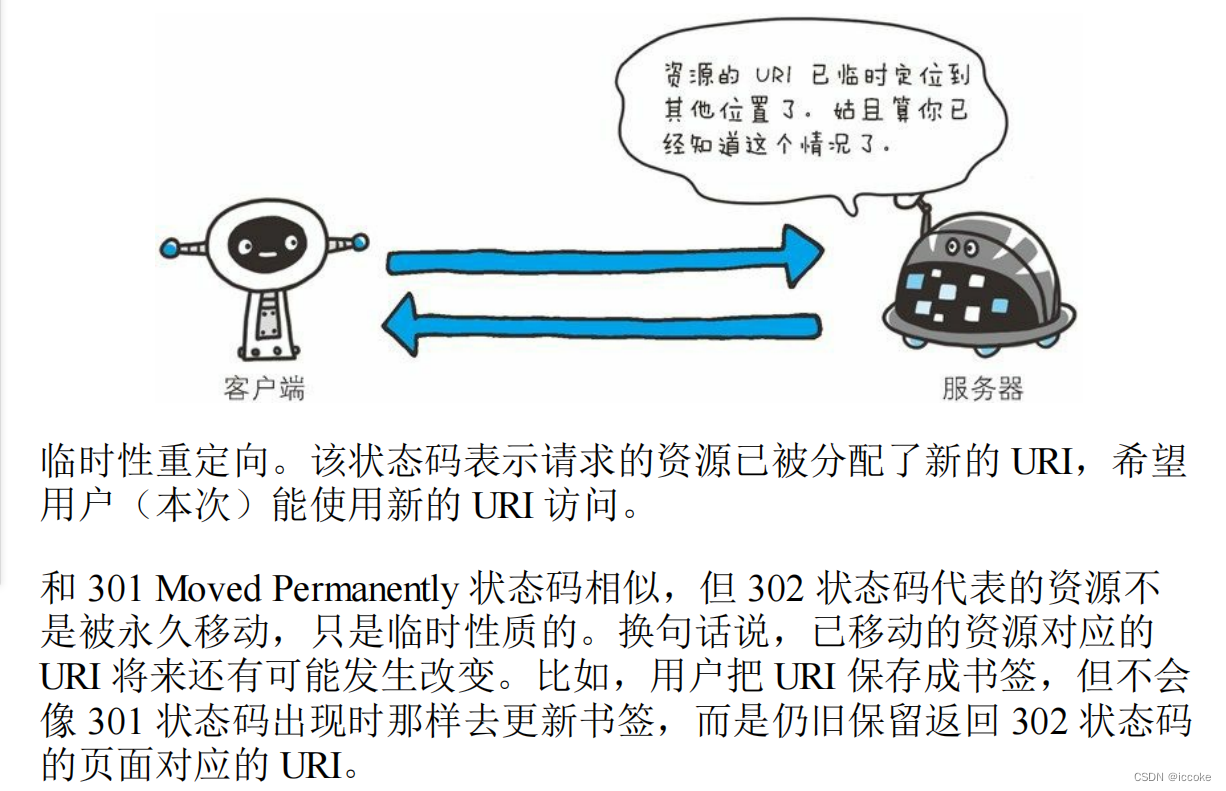
302资源临时重定向
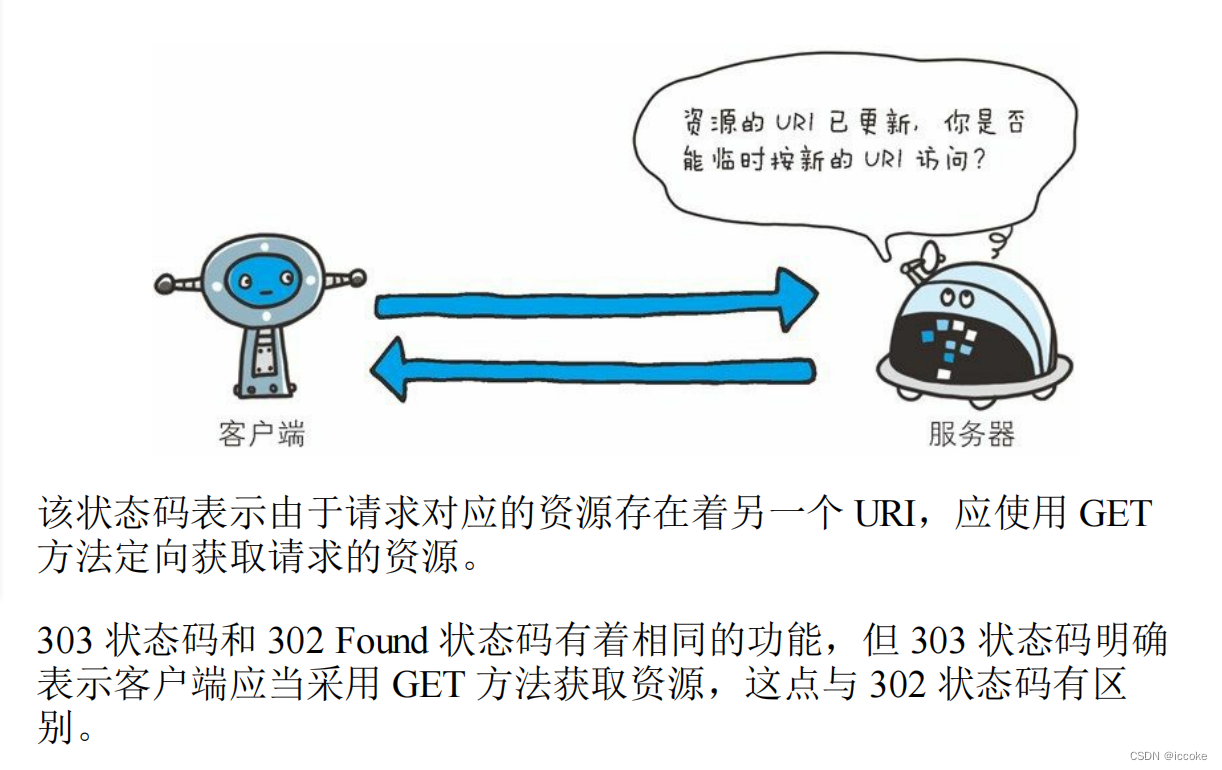
303访问的资源存在另外一个URL
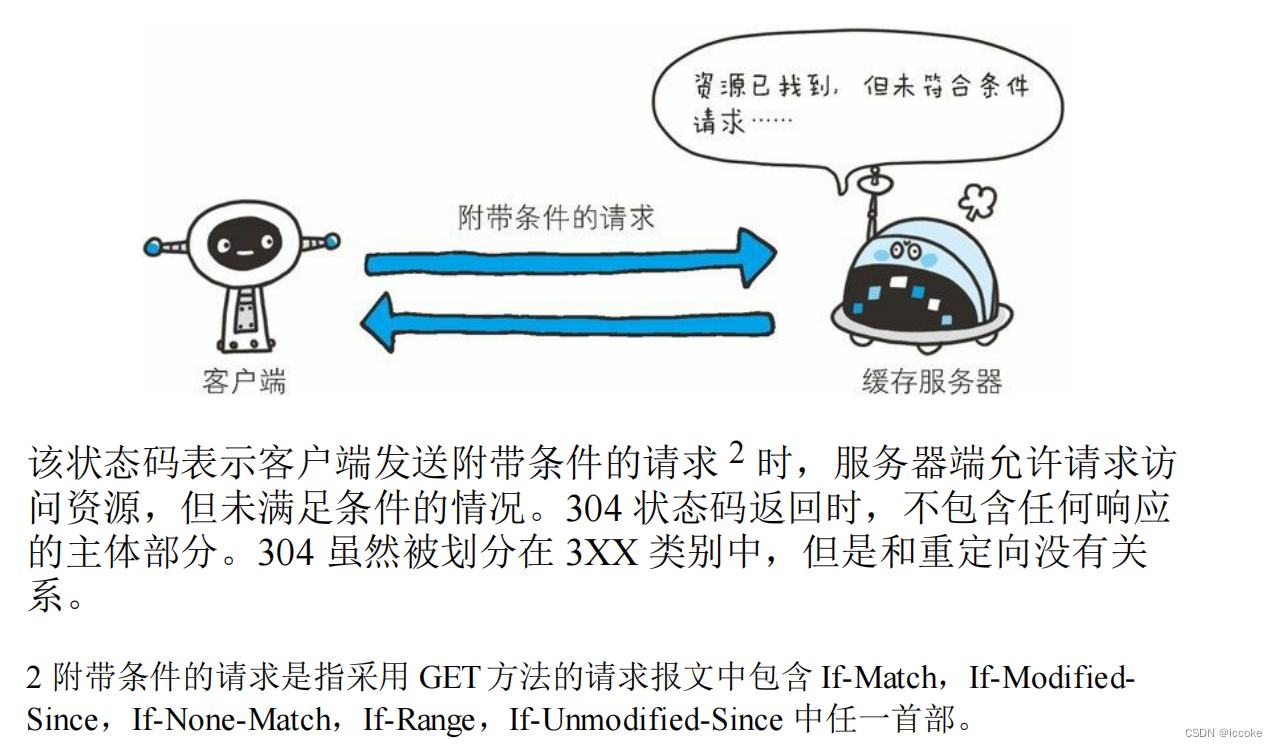
304资源找到但是不符合条件
307与302同样含义,307 会遵照浏览器标准,不会从 POST 变成 GET。但是,对于处理响 应时的行为,每种浏览器有可能出现不同的情况。
4xx
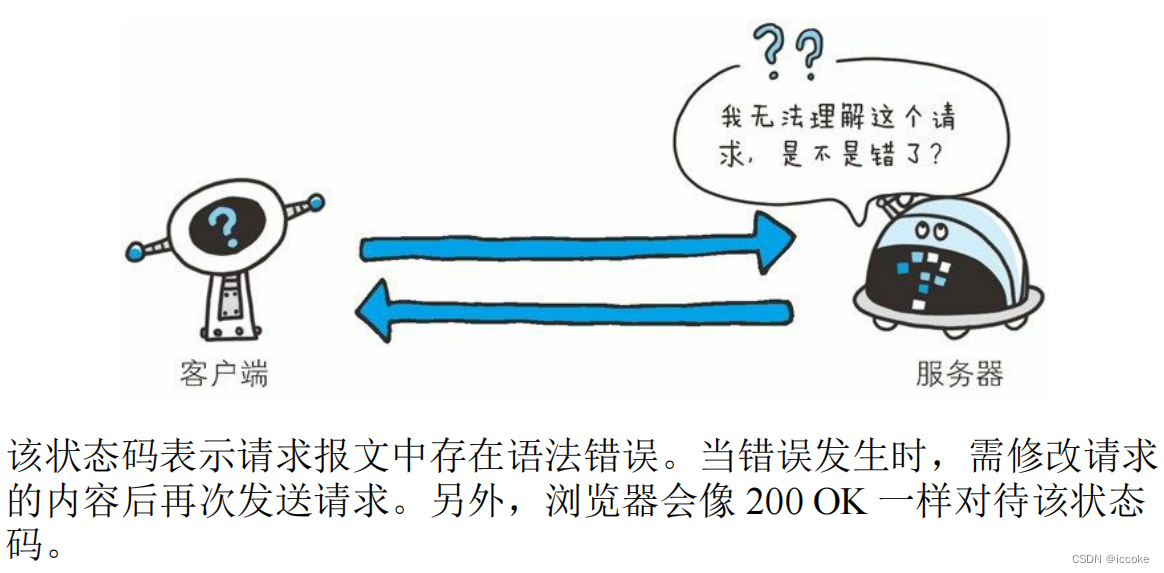
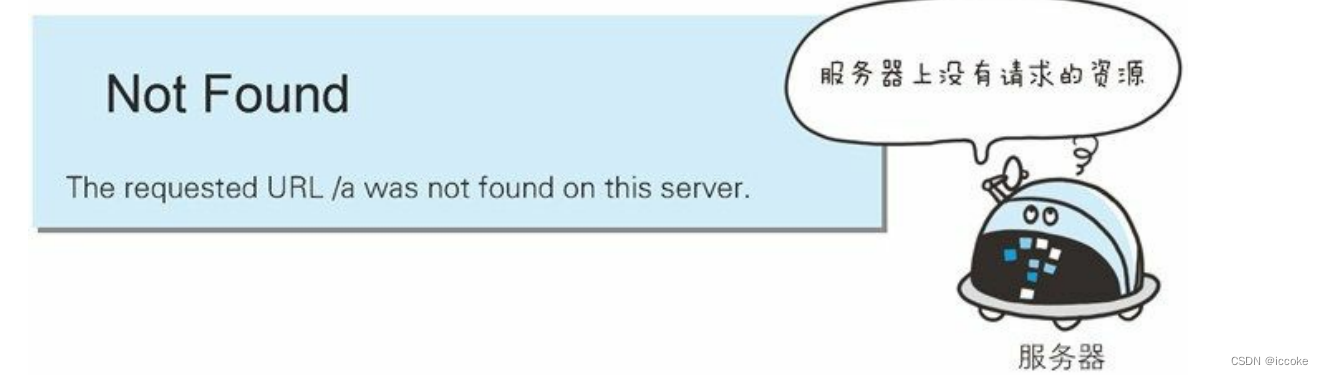
400请求报文错误
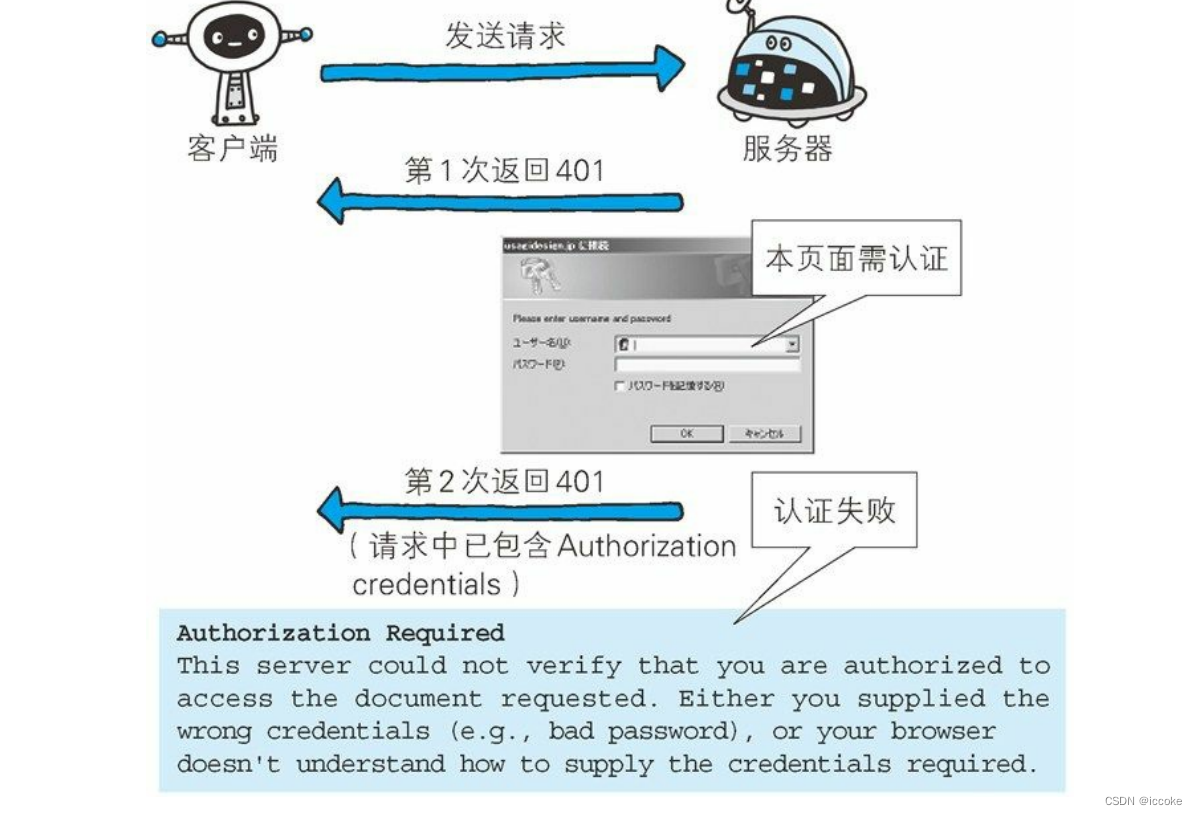
401发送的请求需要验证
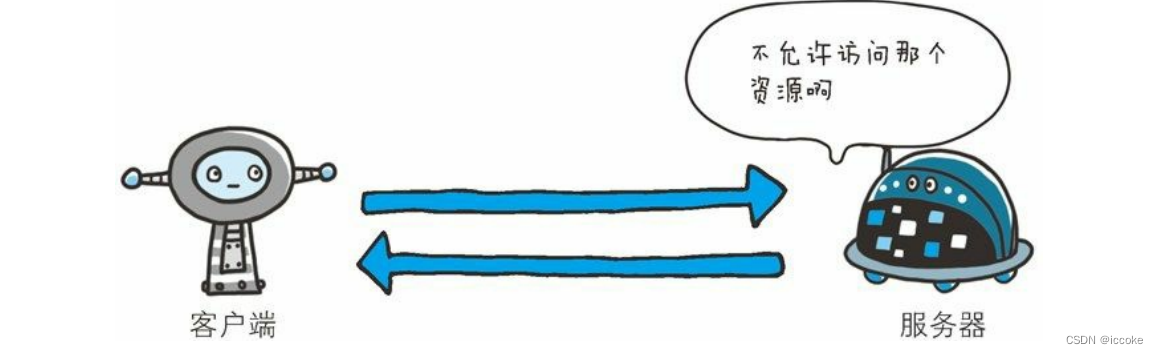
403不允许访问
5xx
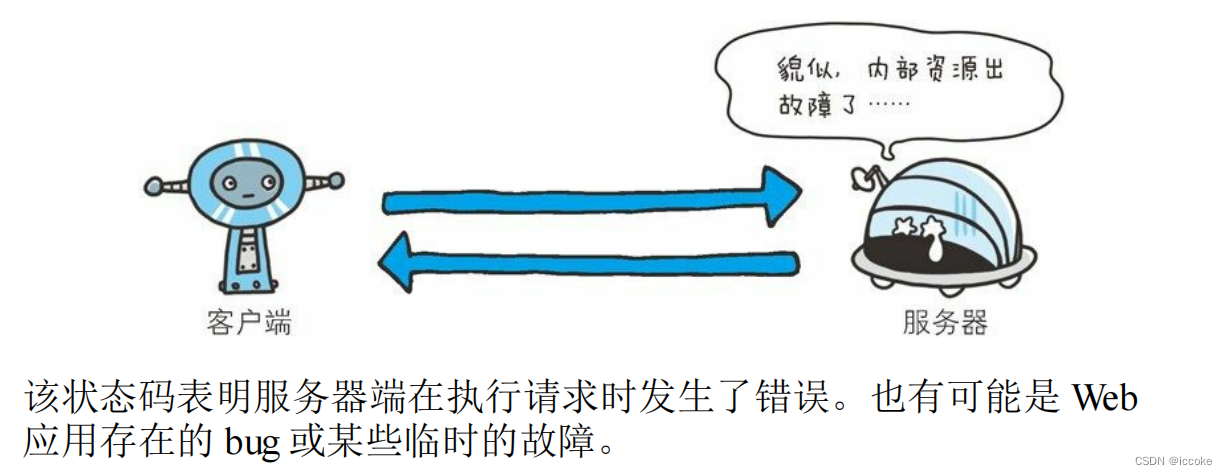
500内部资源出现问题
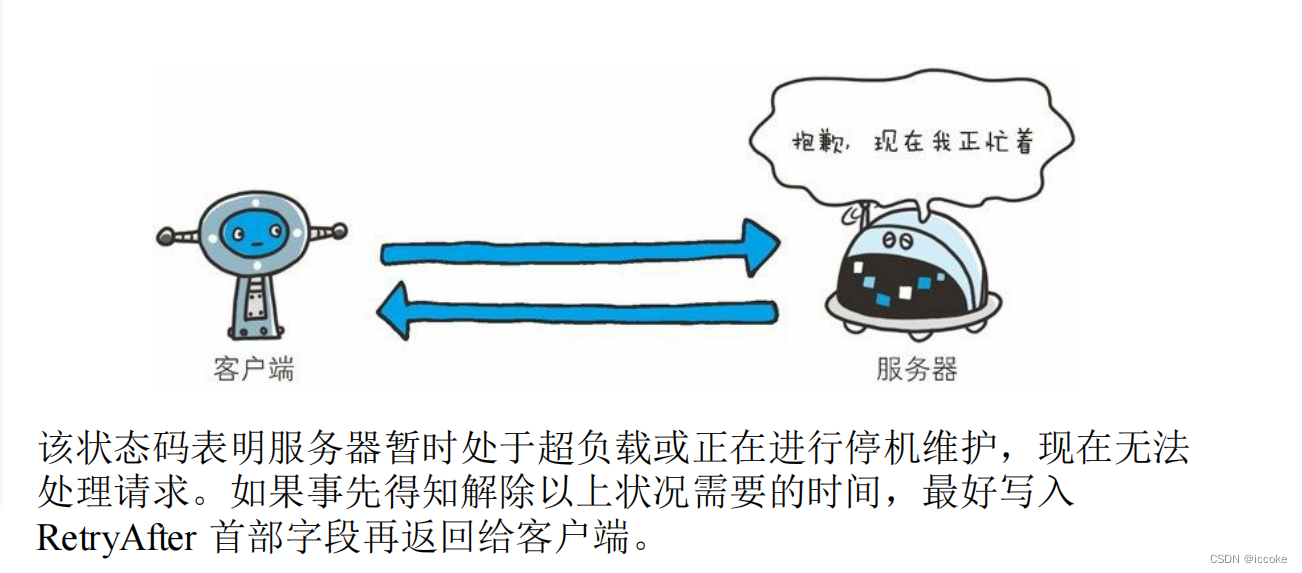
503服务器停机维护
 4.常见HTTP方法
4.常见HTTP方法
每个HTTP报文都包含一个方法 这个方法决定服务器执行什么动作

这一节我们简单介绍了http协议的一些基础信息 下一节我们就可以使用HTML语言建立起客户端和服务器的链接 并且可以使用到http协议
参考书目
图解HTTP
Linux高性能服务器编程