hive建分区表,分桶表,内部表,外部表
一、概念介绍
Hive是基于Hadoop的一个工具,用来帮助不熟悉 MapReduce的人使用SQL对存储在Hadoop中的大规模数据进行数据提取、转化、加载。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表(hive表对应着hdfs文件),并提供SQL查询功能,Hive能将SQL语句转变成MapReduce任务来执行。
分区表,分桶表,内部表,外部表的概念:
hive表由存储的数据和描述表数据形式的元数据组成。
内部表(默认):
建表时没有用EXTERNAL关键字,状态下hive表会维护数据,将数据移入仓库目录(warehouse),表被删除时会同步删除元数据和数据
外部表(external table)
建表时使用了EXTERNAL关键字,删除表时仅仅删除hive中的元数据,不会去删除数据。
内部表和外部表的区别表现在LOAD和DROP命令的不同上。
LOAD 内部表会把数据移动到仓库目录(warehouse)
外部表不会移动数据,只是记录数据路径信息,甚至不会检查路径是否存在
DROP 内部表会将元数据和数据一起删除
外部表只删除元数据
分区表:
分区只是表目录下的子目录。比如按天分区,这样同一天的记录会被保存在同一分区(目录),优点在于查询特定日期的时候特别高效。
分区是在创建表时使用 PARTITIONED BY子句定义的,分区列不在数据文件中。
create table logs(ts INT,line STRING)
PARTITIONED by(dt STRING);
分区表加载数据时需要指定分区值
load data local inpath ‘/home/public_train/part.txt’ into table logs PARTITION (dt=’2023-01-01’);
使用show partitions logs;查看logs下的分区
分桶表:使用CLUSTERED BY子句指定划分通的列和桶的个数。每个桶是表(或分区)目录里的一个文件。
create table bucketed_user(id INT,name STRING)
CLUSTERED BY (id) into 4 BUCKETS;
桶中的数据库可以进行排序:
create table bucketed_users(id INT,name STRING)
CLUSTERED BY (id) SORTED BY (id ASC) into 4 BUCKETS;
查看分桶文件
hdfs dfs -ls /user/hive/warehouse/bucketed_users
分桶的优点在于快速取样和在表连接的时候提高效率。
下面我们使用hive建分区表,分桶表,内部表,外部表来熟悉hive的建表操作。
二、 hive建表实操
${HIVE_HOME}/bin/hive启动hive客户端
-- 准备工作, 创建数据文件,这里字段分割符是Tab键,对应着表定义中的'\t'
vi stu.txt
1 xiapi
2 xiaoxue
3 qingqin
4 lisi
--上传文件到hdfs
hdfs dfs -mkdir -p /hive/stu
hdfs dfs -put -f stu.txt hdfs://192.168.129.130:8020/hive/stu/stu.txt
下面使用${HIVE_HOME}/bin/hive启动hive客户端进行演示:
1. 创建表并将数据文件导入表中
建hive表(默认为内部表)会在数据仓库(hdfs默认/user/hive/warehouse)中创建同名表目录,load数据文件会将文件移动到表目录下。
-- drop table test;
-- 建hive表对应的是数据仓库warehouse中的hdfs文件,所以需要指定文件中的字段分隔符和行分隔符
create table test (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
-- 查看表字段
desc test;
-- 查看建表语句
show create table test;
show tables;
-- 查看表文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test
-- 导入数据的语法为
-- LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
-- INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
-- 导入本地数据,需要加上LOCAL
load data LOCAL inpath '/home/public_train/stu.txt' INTO TABLE test;
select * from test;
-- 导入HDFS数据, 会将HDFS文件移动到hive数据仓库
load data inpath 'hdfs://192.168.129.130:8020/hive/stu/stu.txt' INTO TABLE test;
select * from test;
-- 查看表文件,增加了1个文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test
-- hdfs文件已经不见了(被移动到hive数据仓库了)
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu/stu.txt
-- OVERWRITE覆盖导入HDFS数据
load data inpath 'hdfs://192.168.129.130:8020/hive/stu/stu.txt' OVERWRITE INTO TABLE test;
select * from test;
-- 查看表文件,只剩下一个文件
$ hdfs dfs -ls hdfs://192.168.129.130:8020/user/hive/warehouse/public_train.db/test
2. 基于现有表,创建新表
create table test_copy as select * from test;
3. 创建内部表和外部表,分别load和drop后查看数据文件观察区别。
内部表会维护数据文件即load时移动文件,drop时删除数据文件;
外部表hive不会维护数据文件, drop时不会删除数据文件,仅仅删除表定义;
-- 内部表使用上面的test表即可
-- 建外部表使用external关键字
create external table stu (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
location 'hdfs://192.168.129.130:8020/hive/stu' ;
-- 查看建表语句
show create table stu;
select * from stu;
$ hdfs dfs -put -f stu.txt hdfs://192.168.129.130:8020/hive/stu/stu.txt
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu;
select * from stu;
-- 删除外部表后,数据文件还在
drop table stu;
$ hdfs dfs -ls hdfs://192.168.129.130:8020/hive/stu;
create external table stu (
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
location 'hdfs://192.168.129.130:8020/hive/stu' ;
select * from stu;
4. 创建分区表,并导入分区数据
分区是表目录下的子目录。分区字段值就是子目录名,分区字段不存在于数据文件中。
分区是表的水平拆分,查询特定分区的时候特别高效,只需要读取分区子目录下的文件。
-- PARTITIONED by指定分区字段
create table logs(ts INT,line STRING)
PARTITIONED by(dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
-- 加载数据
load data local inpath '/home/public_train/stu.txt' into table logs PARTITION (dt='2023-01-01');
-- 查看分区
show partitions logs;
-- 查看表文件(子目录名称即是分区)
dfs -ls /user/hive/warehouse/public_train.db/logs
select * from logs where dt='2023-01-01';
-- 动态分区, 根据分区字段的值自动创建分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert into logs partition (dt) values (8,'auto','2024-01-01');
dfs -ls /user/hive/warehouse/public_train.db/logs
show partitions logs;
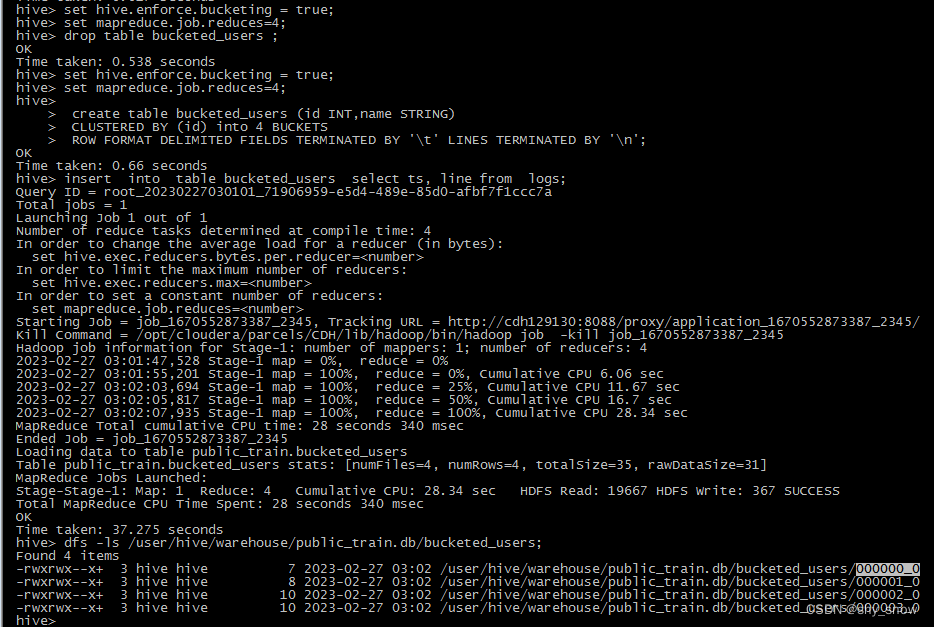
5. 建表分桶
单个分桶是表或分区下的单个表文件。
分桶可以将原本的单个表文件拆分为多个表文件,好处在于快速取样和表jion时的效率提升。
-- 强制分区及设置reduces数目为分区数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
create table bucketed_users (id INT,name STRING)
CLUSTERED BY (id) into 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
insert into table bucketed_users select ts, line from logs;
dfs -ls /user/hive/warehouse/public_train.db/bucketed_users;
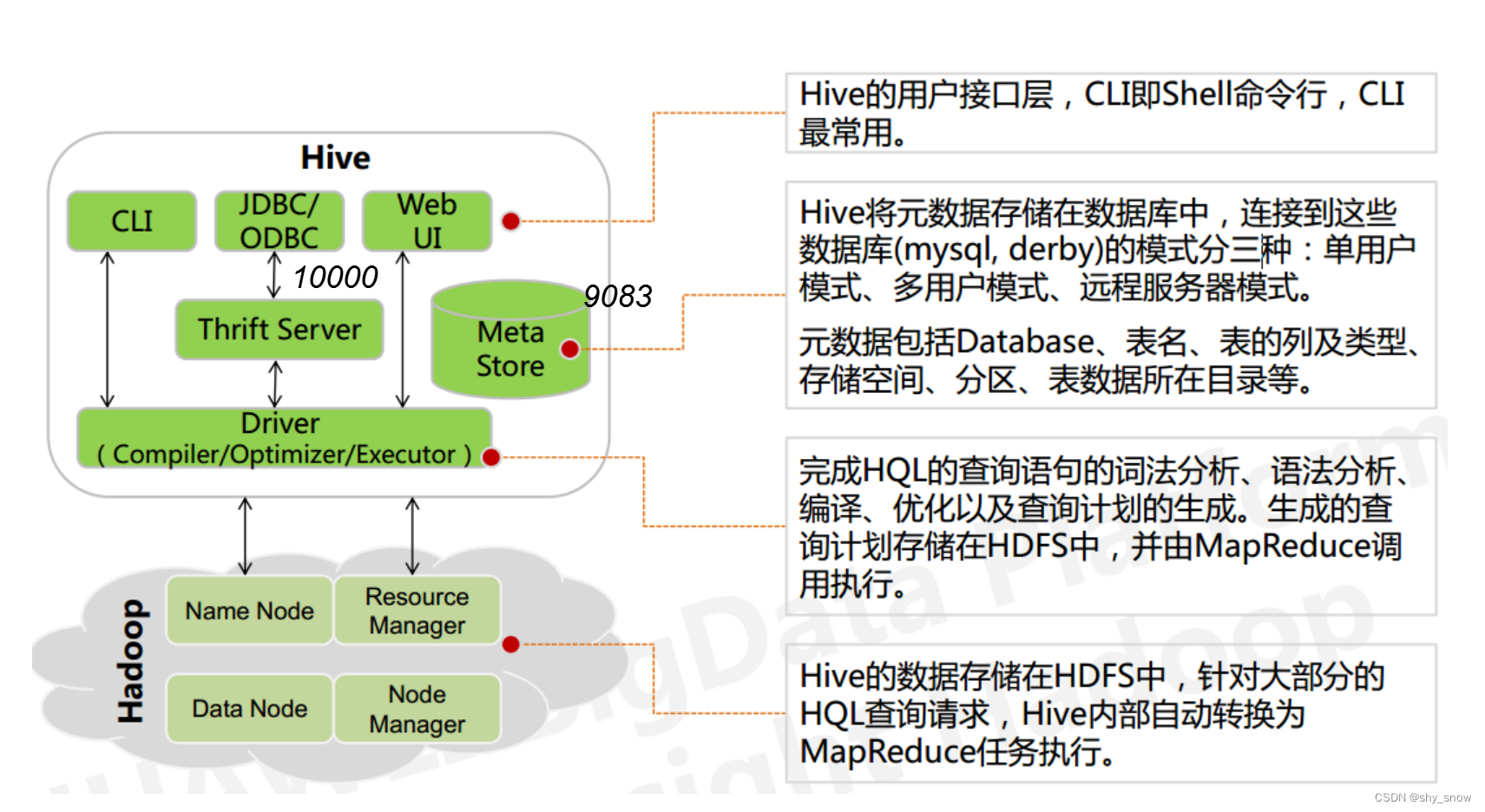
三、hive原理及架构
Hive 实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。下图简要说明Hive如何将SQL语句转换成MapReduce的实现原理。
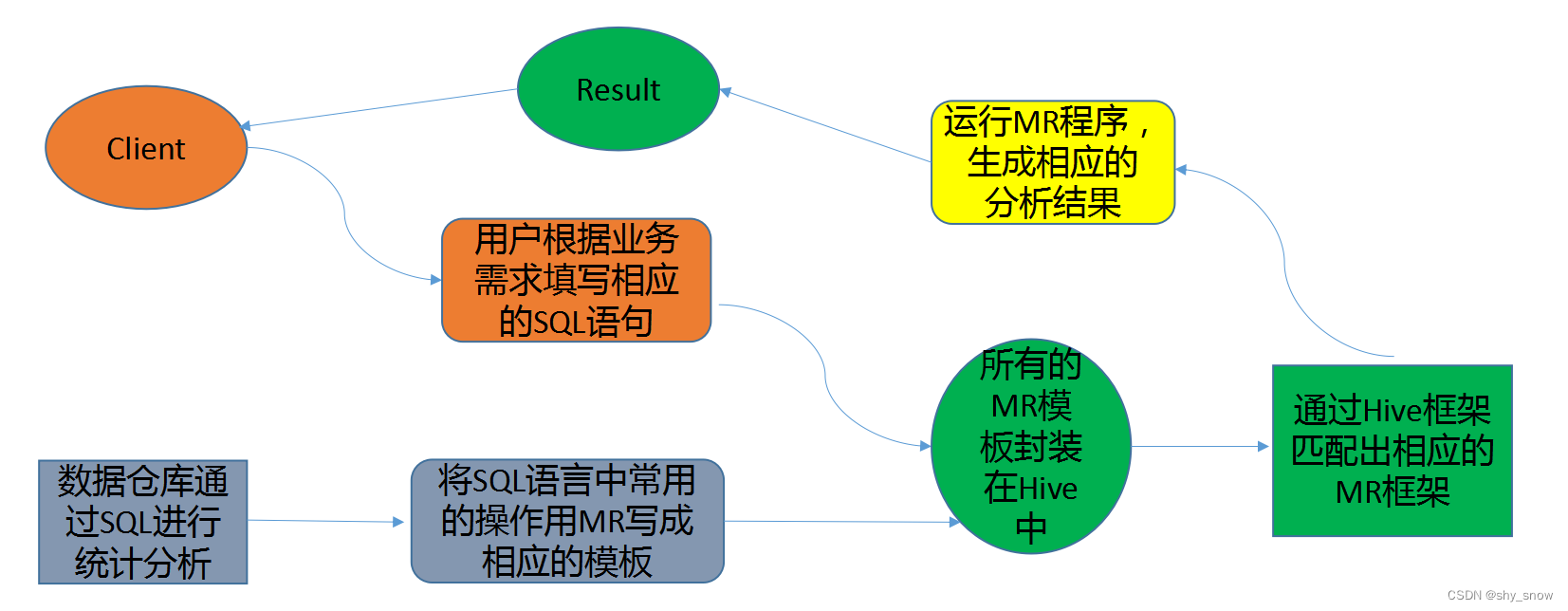
基本概念:
底层数据是存储在 HDFS 上
元数据存储在元数据库中
Hive的本质是将 SQL 语句转换为 MapReduce 任务运行
使不熟悉 MapReduce 的用户很方便地利用 HQL 处理和计算 HDFS 上的结构化的数据,适用于离线的批量数据计算。
Hive的架构及常用端口