Linux基础命令和工具使用详解
- 一、grep搜索字符
- 二、find查找文件
- 三、ls 显示文件
- 四、wc命令计算字数
- 五、uptime机器启动时间+负载
- 六、ulimit用户资源
- 七、curl http
- 八、scp远程拷贝
- 九、dos2unix和unix2dos
- 十、sed 行处理
- 10.1、简单模式
- 10.2、替换模式
- 十一、awk 列处理
- 11.1、打印某几列
- 11.3、判断语句
- 11.4、BEGIN 定义表头
- 11.5、END 添加结尾符
- 11.6、数据计算
- 11.7、使用示例:网络状态统计
一、grep搜索字符
grep 命令用于在文件中执行关键词搜索,并显示匹配的效果。部分常用选项 :
- -c 仅显示找到的行数
- -i 忽略大小写
- -n 显示行号
- -v 反向选择 – 仅列出没有关键词的行。v 是 invert 的缩写。
- -r 递归搜索文件目录
- -C n 打印匹配行的前后n行
(1)在指定文件查找,查找login关键字:
grep battery ./shell/battery.sh
(2)在多个文件搜索的时候,可以使用通配符。比如在以 sh结尾的文件中,搜索包含battery的行:
grep battery *.sh
(3)递归搜索目录下所有文件, 搜索 msg_server目录下所有文件,打印出包含battery的行:
grep battery -r msg_server
(4)反向查找,查找文件中,不包含battery的行:
grep -v battery ImUser.cpp
(5)找出文件中包含 battery 的行,并打印出行号:
grep -n battery ./shell/battery.sh
(6)找出文件中包含 login的行,打印出行号,并显示前后3行。
grep login -C 3 -n test.cpp
(7)找出文件中包含 login的行,打印出行号,并显示前后3行,并忽略大小写:
grep login -n -C 3 -i test.cpp
二、find查找文件
通过文件名查找文件的所在位置,文件名查找支持模糊匹配。
find [指定查找目录] [查找规则] [查找完后执行的action]
常用的操作:
find . -name FILE_NAME
find . -iname FILE_NAME #忽略文件名称大小写
find /etc -maxdepth 1 -name passwd ##查找/etc/下名称中带有passwd的文件,查找一层
find /mnt -size 20K ##查找/mnt文件大小近似20k的文件
find /mnt -size +20K ##查找/mnt文件大小大于20k的文件
find /mnt -size -20K ##查找/mnt文件大小小于20k的文件
find /etc -maxdepth 2 -mindepth 2 -name .conf ##查找/etc/下名称中带有.conf的文件,且只查找第二层
find /mnt -type d ##按type查找/mnt中目录
find /mnt -type f ##按type查找/mnt中文件
find /mnt -cmin 10 ##查找/mnt中十分钟左右修改的
find /mnt -cmin +10 ##查找/mnt中十分钟以上修改的
find /mnt -cmin -10 ##查找/mnt中十分钟以内修改的
find /mnt -ctime 10 ##查找/mnt中十天左右修改的
find /mnt -ctime +10 ##查找/mnt中十天以上修改的
find /mnt -ctime -10 ##查找/mnt中十天以内修改的
三、ls 显示文件
参数 作用
- -t 查看最新修改时间
- -l 每行显示一个条目
- -h 可以结合显示文件的GB,MB等(human);
- -R 递归显示
- -n 显示组id和gid
(1)按最新修改的时间排序,新修改的在前面显示。
ls -lt
(2)按最新修改的时间排序,新修改的在前面显示,并显示子目录的文件信息 。
ls -ltR
(3)以单位显示文件大小。
ls -lh
四、wc命令计算字数
wc命令用于计算字数。 利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法:
wc [-clw][--help][--version][文件...]
参数:
- -c或–bytes或–chars:只显示Bytes数。
- -l或–lines:只显示行数。
- -w或–words:只显示字数。
- –help: 在线帮助。
- –version:显示版本信息。
示例:
$ wc ./shell/battery.sh
125 333 3157 ./shell/battery.sh
行数为125、单词数333、字节数3157。
五、uptime机器启动时间+负载
查看机器的启动时间、登录用户、平均负载等情况,通常用于在线上应急或者技术攻关中,确定操作系统的重启时间。
示例:
$ uptime
15:29:42 up 9 days, 5:58, 1 user, load average: 0.00, 0.00, 0.00
从上面的输出可以看到如下信息:
- 当前时间:15:29:42
- 系统已经运行的时间:9天5小时58分钟。
- 前在线用户:1个用户,是总连接数量,不是不同用户数量(开一个终端连接就算一个用户)。
- 系统平均负载:0.00 , 0.00, 0.00,为最近1分钟、5分钟、15分钟的系统负载情况。
系统的平均负载是指在特定的时间间隔内队列中运行的平均进程数。如果一个进程满足以条件,它就会位于运行队列中。
- 它没有在等待I/O操作的结果。
- 它没有主动进入等待状态(也就是没有调用’wait’相关的系统API ) 。
- 没有被停止(例如:等待终止)。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能还算可以支持。
如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
负载说明(针对单核情况,不是单核时则乘以核数):
- load<1:没有等待
- load==1:系统已无额外的资源跑更多的进程了
- load>1:进程都堵着等待资源
注意:
- load < 0.7时:系统很闲,要考虑多部署一些服务
- 0.7 < load < 1时:系统状态不错
- load == 1时:系统马上要处理不多来了,赶紧找一下原因
- load > 5时:系统已经非常繁忙了
不同load值说明的问题:
- 1分钟 load >5,5分钟 load < 3,15分钟 load <1 ,短期内繁忙,中长期空闲,初步判断是一个抖动或者是拥塞前兆 。
- 1分钟 load >5,5分钟 load >3,15分钟 load <1 ,短期内繁忙,中期内紧张,很可能是一个拥塞的开始。
- 1分钟 load >5,5分钟 load >5,15分钟 load >5 ,短中长期都繁忙,系统正在拥塞 。
- 1分钟 load <1,5分钟Load >3,15分钟 load >5 ,短期内空闲,中长期繁忙,不用紧张,系统拥塞正在好转。
补充:
- 查看cpu信息:cat /proc/cpuinfo 。
- 直接获取cpu核数:grep ‘model name’ /proc/cpuinfo | wc -l 。
六、ulimit用户资源
Linux系统对每个登录的用户都限制其最大进程数和打开的最大文件句柄数。为了提高性能,可以根据硬件资源的具体情况设置各个用户的最大进程数和打开的最大文件句柄数。
(1)可以用ulimit -a来显示当前的各种系统对用户使用资源的限制:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 31574
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1048576
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 31574
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
(2)设置用户的最大进程数:
ulimit -u 1024
(3)设置用户可以打开的最大文件句柄数:
ulimit -n 65530
七、curl http
由于当前的线上服务较多地使用了RESTful风格的API,所以集成测试就需要进行HTTP调用,查看返回的结果是否符合预期,curl命令当然是首选的测试方法。
使用方式:
curl -i "http://www.sina.com" # 打印请求响应头信息
curl -I "http://www.sina.com" # 仅返回http头
curl -v "http://www.sina.com" # 打印更多的调试信息
curl -verbose "http://www.sina.com" # 打印更多的调试信息
curl -d 'abc=def' "http://www.sina.com" # 使用post方法提交http请求
curl -sw '%{http_code}' "http://www.sina.com" # 打印http响应码
八、scp远程拷贝
secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
scp命令是Linux系统中功能强大的文件传输命令,可以实现从本地到远程,以及从远程到本地的双向文件传输,用起来非常方便,常用来在线上定位问题时将线上的一些文件下载到本地进行详查,或者将本地的修改上传到服务器上。
语法:
scp [option] username@IP:filepath savepath
前提:
sudo apt-get install openssh-server
使用方式:
# 下载192.168.11.59的文件
scp fly@192.168.11.59:~/workspace/battery.sh .
# 上传文件到122.152.222.180
scp mi9.aac fly@192.168.11.59:~/workspace/
# 下载test整个目录到本地
scp -r fly@192.168.11.59:~/workspace/ .
# 上传本地test整个目录到192.168.11.59
scp -r test fly@192.168.11.59:~/workspace/
九、dos2unix和unix2dos
用于转换Windows和UNIX的换行符,通常在Windows系统开发的脚本和配置,UNIX系统下都需要转换。
使用方式:
dos2unix test.txt
unix2dos test.txt
#转换整个目录
find . -type f -exec dos2unix {} \;
find ./ -type f # 此命令是显示当前目录下所有的文件
十、sed 行处理
命令格式1:
sed 's/原字符串/新字符串/' 文件
命令格式2:
sed 's/原字符串/新字符串/g' 文件
这两种命令格式的区别在于是否有个“g”。没有“g”表示只替换第一个匹配到的字符串,有“g”表示替换所有能匹配到的字符串,“g”可以认为是“global”(全局的)的缩写,没有“全局的”结尾就不要替换全部。
sed命令是用来批量修改文本内容的,比如批量替换配置中的某个ip。
sed命令在处理时,会先读取一行,把当前处理的行存储在临时缓冲区中,处理完缓冲区中的内容后,打印到屏幕上。然后再读入下一行,执行下一个循环。不断的重复,直到文件末尾。
10.1、简单模式
一个简单的sed命令包含三个主要部分: 参数 、 范围 、 操作 。要操作的文件,可以直接挂在命令行的最后。
sed -n '2,5 p' filename.txt
# -n是参数
# 2,5 是范围
# p 是操作
# filename.txt是文件
(1)参数 :
-n 这个参数是 --quiet 或者 --silent 的意思。表明忽略执行过程的输出,只输出我们的结果即可。
还有另外一个参数 : -i 。使用此参数后,所有改动将在原文件上执行。你的输出将覆盖原文件。非常危险,一定要注意。
(2)范围:
2,5 表示找到文件中,2,3,4,5行的内容。
这个范围的指定很有灵性,比如:
5 选择第5行。2,5 选择2到5行,共4行。1~ 2 选择奇数行,2~2 选择偶数行。
范围的选择还可以使用正则匹配。比如:
/void/,+3 选择出现void字样的行,以及后面的三行。2^void/,/mem/选择以void开头的行,和出现mem字样行之间的数据。
例子:
sed -n '5p' sed1.cpp
sed -n '2,5 p' sed1.cpp
sed -n '1~2 p' sed1.cpp
sed -n '2~2 p' sed1.cpp
sed -n '2,+3p' sed1.cpp
sed -n '2,$ p' sed1.cpp
sed -n '/void/,+3 p' sed1.cpp
sed -n '/^void/,/CLIENT_TYPE_FLAG_BOTH/p' sed1.cpp
sed -n '/^BroadcastPdu/,/CLIENT_TYPE_FLAG_BOTH/p' sed1.cpp
sed -n '/^void CImUserManager::BroadcastPdu/,/CLIENT_TYPE_FLAG_BOTH/p' sed1.cpp
(3)操作 :
最常用的操作就是 p ,意思就是打印。比如,以下两个命令就是等同的:
cat file
sed -n 'p' file
除了打印,还有以下操作:
- p 对匹配内容进行打印。
- d 对匹配内容进行删除。这个时候就要去掉 -n 参数了,思考为什么?
- w 将匹配内容写入到其他地方。
- a , i , c 等操作虽基本但使用少,不做介绍。
sed -n '2,5 p' sed2.cpp
sed '2,5 d' sed2.cpp
sed -n '2,5 w output.txt' sed2.cpp
10.2、替换模式
sed还有一个强大的替换模式,意思就是查找替换其中的某些值,并输出结果。
使用替换模式很少使用 -n 参数。
sed '/^sys/S/a/b/g' filename
替换模式的参数有点多,但第一部分和第五部分都是可以省略的。替换后会将整个文本输出出来。前半部分用来匹配一些范围,而后半部分执行替换的动作。
(1)范围 :
这个范围和上面的范围语法类似。比如:
/sys/,+3 选择出现sys字样的行,以及后面的三行。/^sys/,/mem/ 选择以sys开头的行,和出现mem字样行之间的数据。
示例:
sed -n '/void/,+3 s/void/int/g' sed2.cpp
sed '/^void/,/CLIENT_TYPE_FLAG_BOTH/s/ImUser/User/g' sed2.cpp
(2)命令 :
这里的命令是指s。也就是substitute的意思。 查找部分会找到要被替换的字符串。这部分可以接受纯粹的字符串,也可以接受正则表达式。比如:
a 查找范围行中的字符串 a。[a,b,c] 从范围行里查找字符串a或者b或者c。
示例:
sed 's/a/b/g' file
sed 's/[a,b,c]/<&>/g' file
(3)替换 :
将替换查找匹配部分找到的内容。 可惜的是,这部分不能使用正则。常用的就是精确替换。比如把a替换成b。
但也有高级功能。和java或者python的正则api类似,sed的替换同样有 Matched Pattern 的含义,同样可以得到Group,不深究。常用的替位符,就是 &,当它用在替换字符串中的时候,代表的是原始的查找匹配数据。
[&] 表明将查找到的数据使用[]包围起来。“&” 表明将查找的数据使用””包围起来。
下面这条命令,将会把文件中的每一行,使用引号包围起来。
sed 's/.*/"&"/' file
(4)flag 参数 :
这些参数可以单个使用,也可以使用多个,仅介绍最常用的。
- g 默认只匹配行中第一次出现的内容,加上g,就可以全文替换了。常用。
- p 当使用了 -n 参数, p 将仅输出匹配行内容。
- w 和上面的w模式类似,但是它仅仅输出有变换的行。
- i 这个参数比较重要,表示忽略大小写。e 表示将输出的每一行,执行一个命令。不建议使用,可以使用xargs配合 完成这种功能。
看两个命令的语法:
sed -n 's/a/b/gipw output.txt' file
sed 's/^/ls -la/e' file
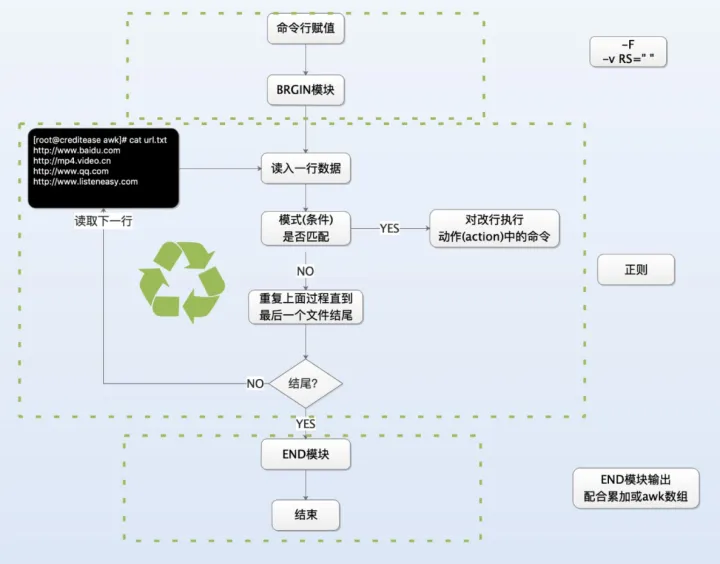
十一、awk 列处理
awk同sed命令类似,只不过sed擅长取行,awk命令擅长取列。
原理:一般是遍历一个文件中的每一行,然后分别对文件的每一行进行处理
用法:
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
11.1、打印某几列
比如:
$ echo 'I do that' | awk '{print $3 $2 $1}'
thatdoI
将字符串 I do that 通过管道传递给awk命令,相当于awk处理一个文件,该文件的内容就是I do that,默认通过空格作为分隔符(不管列之间有多少个空格都将当作一个空格处理) I do that就分割成三列了。假如分割符号为.,可以这样用:
$ echo '192.168.1.1' | awk -F "." '{print $2}'
168
11.2、条件过滤
awk的用法是这样的:
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
那么pattern部分怎么用呢?示例如下:
$ cat score.txt
tom 60 60 60
kitty 90 95 87
jack 72 84 99
$ awk '$2>=90{print $0}' score.txt
kitty 90 95 87
$2>=90 表示如果当前行的第2列的值大于90则处理当前行,否则不处理。说白了pattern部分是用来从文件中筛选出需要处理的行进行处理的,这部分是空的代表全部处理。pattern部分可以是任何条件表达式的判断结果,例如>,<,==,>=,<=,!=同时还可以使用+,-,*,/运算与条件表达式相结合的复合表达式,逻辑 &&,||,!同样也可以使用进来。另外pattern部分还可以使用 /正则/ 选择需要处理的行。
11.3、判断语句
判断语句是写在pattern{ 命令 }命令中的,他具备条件过滤一样的作用,同时他也可以让输出更丰富。
$ awk '{if($2>=90 )print $0}' score.txt
kitty 90 95 87
$ awk '{if($2>=90 )print $1,"优秀"; else print $1,"良好"}' score.txt
tom 良好
kitty 优秀
jack 良好
$ awk '{if($2>=90 )print $0,"优秀"; else print $1,"良好"}' score.txt
tom 良好
kitty 90 95 87 优秀
jack 良好
11.4、BEGIN 定义表头
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
示例:
$ awk 'BEGIN{print "姓名 语文 数学 英语"}{printf "%-8s%-5d%-5d%-5d\n",$1,$2,$3,$4}' score.txt
姓名 语文数学英语
tom 60 60 60
kitty 90 95 87
jack 72 84 99
要注意,例子中为了输出格式好看,做了左对齐的操作(%-8s左对齐,宽8位),printf用法和c++类似。不仅可以用来定义表头,还可以做一些变量初始化的工作,例如:
$ awk 'BEGIN{OFMT="%.2f";print 1.2567,12E-2}'
1.26 0.12
这里OFMT是个内置变量,初始化数字输出格式,保留小数点后两位。
11.5、END 添加结尾符
和BEGIN用法类似
$ echo ok | awk '{print $1}END{print "end"}'
ok
end
11.6、数据计算
$ awk 'BEGIN{print "姓名 语文 数学 英语 总成绩"; \
sum1=0;sum2=0;sum3=0;sumall=0} \
{printf "%5s%5d%5d%5d%5d\n",$1,$2,$3,$4,$2+$3+$4;\
sum1+=$2;sum2+=$3;sum3+=$4;sumall+=$2+$3+$4}\
END{printf "%5s%5d%5d%5d%5d\n","总成绩",sum1,sum2,sum3,sumall}'\
score.txt
姓名 语文 数学 英语 总成绩
tom 60 60 60 180
kitty 90 95 87 272
jack 72 84 99 255
总成绩 222 239 246 707
因为命令太长,末尾用\符号换行。
- BEGIN体里输出表头,并给四个变量初始化0。
- pattern体里输出每一行,并累加运算。
- END体里输出总统计结果 当然了,一个正常人在用linux命令的时候是不会输入那么多格式化符号来对齐的,所以新命令又来了 column -t。
11.7、使用示例:网络状态统计
采用awk统计netstat命令的一些网络状态,来看一下awk语言的基本要素。netstat命令的执行后显示的结果在第6列标明了网络连接所处于的网络状态。awk命令看一下统计结果。
netstat -ant |
awk ' \
BEGIN{print "State","Count" } \
/^tcp/ \
{ rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
netstat -ant |
awk ' \
BEGIN{print "State","Count" } \
/^tcp/ \
{ if($4=="0.0.0.0:3306" ) rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
输出结果:
State Count
LAST_ACK 1
LISTEN 64
CLOSE_WAIT 43
ESTABLISHED 719
SYN_SENT 5
TIME_WAIT 146
awk和通常的程序不太一样,它分为四个部分:
- BEGIN 开头部分,可选的。用来设置一些参数,输出一些表头,定义一些变量等。上面的命令仅打印了一行信息而已。
- END 结尾部分,可选的。用来计算一些汇总逻辑,或者输出这些内容。上面的命令,使用简单的for循环,输出了数组rt中的内容。
- Pattern 匹配部分,依然可选。用来匹配一些需要处理的行。上面的命令,只匹配tcp开头的行,其他的不进入处理。
- Action 模块。主要逻辑体,按行处理,统计打印,都可以。
注意:
- awk的主程序部分使用单引号‘包围,而不能是双引号。
- awk的列开始的index是0,而不是1。
更多的详细内容