目录
一、线程与进程很简单的介绍
1.1 线程与进程的区别
二、多进程Process
2.1 多进程与多线程的区别
2.2 多进程为啥要使用队列
2.3 控制进程运行顺序
2.3.1 join ,
2.3.1 daemon 守护进程
2.4 进程id
2.5 进程 存活状态is_alive()
2.5 实现自定义多进程类
三、多线程 threading
3.1 线程锁
四、线程池、进程池
4.1 线程池
4.2 进程池
4.2.1 pool.map( func, iterable)
4.2.2 pool.map_async( func, iterable)
4.2.3 pool.apply(self, func, args=(), kwds={})
4.2.4 pool.apply_async(self, func, args=(), kwds={})
五、协程
六、进程的相关知识
6.1 进程的各种状态
6.2 上下文切换
一、线程与进程很简单的介绍
多任务的实现方式:
多进程、多线程、协程
串行运行:
运行完命令1之后,再运行命令2。
在linux 中 ,串行多条命令用&
我们在启动tomcat时,一般是需要启动同时观察日志输出的。
sh startup.sh & tail -f ../logs/catalina.out并行运行:
命令1与命令2,同时运行。
apt install xx && apt install yy同时下载xx 与 yy
1.1 线程与进程的区别
1、线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。
2、资源(主要是内存资源):进程占用内存资源,线程使用的资源是进程的。
3、切换:
进程与进程间的切换,更消耗时间。
线程与线程之间,切换,速度比较快,因为线程之间,使用的资源,都是同一个进程的。
二、多进程Process
举例:多进程下载场景
一个下载场景,我们需要从网站上下载大量的图片。比如有一万条数据。我们需要将这一万张图片下载下来。
我们将大量图片的下载链接,放到队列里。
# 多进程
from multiprocessing import Process,Queue
def download(q: Queue):
while True:
url = q.get()
print(url)
if q.empty():
break
if __name__ == '__main__':
tasks = Queue()
tasks.put("http://aaa.jpg")
tasks.put("http://bbb.jpg")
# target 函数的名字
# args 函数,所需的参数,这里是元组,元组里只有一个元素时,也许需要加,
p1 = Process(target=download,args=(tasks,)) # 创建进程1
p2 = Process(target=download, args=(tasks,)) # 创建进程1
p1.start() # 启动进程1
p2.start() # 启动进程2注意:
1、# target 函数的名字
# args 函数,所需的参数,这里是元组,元组里只有一个元素时,也许需要加逗号
# target 函数的名字
# args 函数,所需的参数,这里是元组,元组里只有一个元素时,也许需要加,
p1 = Process(target=download,args=(tasks,)) # 创建进程1
p2 = Process(target=download, args=(tasks,)) # 创建进程12、我们这里启动了2个进程,来执行下载任务。进程启动后,是由操作系统控制执行的。具体是并发执行还是并行执行,这个是根据操作系统来的,如果系统是单核的,就只能是并发。
如果系统是多核的,可能是并行。
3、这里图片的下载列表,用的是队列,不是list。
2.1 多进程与多线程的区别
以上面的下载大量图片的场景为例:
多进程,会独享资源,2个进程不能共享变量(例如:不能共享list),所以实现共享资源的方式,就要使用其他手段,如使用队列Queue 、 内存数据库redis等等
多线程:占用资源少,2个线程是共享变量的。一般的网盘下载之类的应用,使用的是多线程的技术。
2.2 多进程为啥要使用队列
多进程中,使用队列时,不能使用其他包的中的队列,必需使用 多进程包中的队列
from multiprocessing import Process,Queue多进程,会独享资源,2个进程不能共享变量(例如:不能共享list),所以实现共享资源的方式,就要使用其他手段。
进程1,会占用一块单独的内存,存放 变量(list),进程2,也会占用一块单独的内存,存放 变量(list), 每个进程,都有一份自己的变量,这样执行时,list就会被执行两次。
队列可以被进程1,与进程2 共享,队列只会被遍历一次。
举个小例子:
使用list作为变量,存储数据。
from multiprocessing import Process
def worker1(data:list):
print("worker1 开始工作")
while data:
print(f"worker1 取到列表中元素{data.pop()}")
def worker2(data:list):
print("worker2 开始工作")
while data:
print(f"worker2 取到列表中元素{data.pop()}")
if __name__ == '__main__':
list = [x for x in range(10)]
p1 = Process(target=worker1,args=(list,))
p2 = Process(target=worker2, args=(list,))
p1.start()
p2.start()
print("主程序运行完毕")打印结果:
worker1 开始工作
worker1 取到列表中元素9
worker1 取到列表中元素8
worker1 取到列表中元素7
worker1 取到列表中元素6
worker1 取到列表中元素5
worker1 取到列表中元素4
worker1 取到列表中元素3
worker1 取到列表中元素2
worker1 取到列表中元素1
worker1 取到列表中元素0
主程序运行完毕
worker2 开始工作
worker2 取到列表中元素9
worker2 取到列表中元素8
worker2 取到列表中元素7
worker2 取到列表中元素6
worker2 取到列表中元素5
worker2 取到列表中元素4
worker2 取到列表中元素3
worker2 取到列表中元素2
worker2 取到列表中元素1
worker2 取到列表中元素0
使用队列Queue作为变量,存储数据。
import time
from multiprocessing import Process,Queue
def worker1(data:Queue):
print("worker1 开始工作")
while not data.empty():
print(f"worker1 取到列表中元素{data.get()}")
time.sleep(1)
def worker2(data:Queue):
print("worker2 开始工作")
while not data.empty():
print(f"worker2 取到列表中元素{data.get()}")
time.sleep(1)
if __name__ == '__main__':
q = Queue()
for x in range(10):
q.put(x)
p1 = Process(target=worker1,args=(q,))
p2 = Process(target=worker2, args=(q,))
p1.start()
p2.start()
print("主程序运行完毕")
打印结果:
worker1 开始工作
worker1 取到列表中元素0
主程序运行完毕
worker2 开始工作
worker2 取到列表中元素1
worker1 取到列表中元素2
worker2 取到列表中元素3
worker1 取到列表中元素4
worker2 取到列表中元素5
worker1 取到列表中元素6
worker2 取到列表中元素7
worker1 取到列表中元素8
worker2 取到列表中元素92.3 控制进程运行顺序
2.3.1 join ,
join 以后的代码,要等当前进程运行完才开始执行
import time
from multiprocessing import Process,Queue
def worker1(data:Queue):
print("worker1 开始工作")
while not data.empty():
print(f"worker1 取到列表中元素{data.get()}")
time.sleep(1)
def worker2(data:Queue):
print("worker2 开始工作")
while not data.empty():
print(f"worker2 取到列表中元素{data.get()}")
time.sleep(1)
if __name__ == '__main__':
q = Queue()
for x in range(10):
q.put(x)
p1 = Process(target=worker1,args=(q,))
p2 = Process(target=worker2, args=(q,))
p1.start()
p2.start()
print("主程序运行完毕")
打印结果:
worker1 开始工作
worker1 取到列表中元素0
主程序运行完毕
worker2 开始工作
worker2 取到列表中元素1
worker1 取到列表中元素2
worker2 取到列表中元素3
worker1 取到列表中元素4
worker2 取到列表中元素5
worker1 取到列表中元素6
worker2 取到列表中元素7
worker1 取到列表中元素8
worker2 取到列表中元素9我们一共运行了三个进程,一个主进程,一个worker1 进程,一个 worker2 进程。
三个进程运行,属于并发运行。我们想要控制进程的运行顺序,可以使用join() 函数。
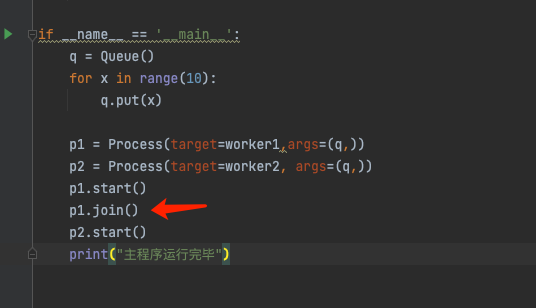
运行p1 进程后,调用join()方法。
则 p1.join()后面的代码 ,只能等到p1进程运行完成后,才开始执行。
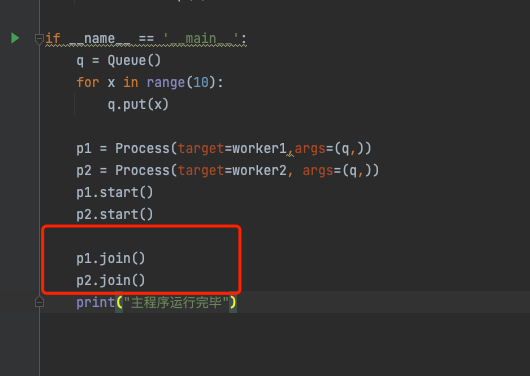
===
子进程运行完成后,再运行主进程。
p1.join()
p2.join()
2.3.1 daemon 守护进程
在主进程,运行完成后,守护进程会被强制关闭。
# -*- coding:utf-8 -*-
# @Author: 喵酱
# @time: 2023 - 02 -25
# @File: list1.py
import os
import time
from multiprocessing import Process, Queue
def worker1(data: Queue):
print(f"worker1 开始工作,进程id为:{os.getpid()}")
while not data.empty():
print(f"worker1 取到列表中元素{data.get()}")
time.sleep(1)
def worker2(data: Queue):
print(f"worker2 开始工作,进程id为:{os.getpid()}")
while not data.empty():
print(f"worker2 取到列表中元素{data.get()}")
time.sleep(1)
if __name__ == '__main__':
q = Queue()
for x in range(10):
q.put(x)
p1 = Process(target=worker1, args=(q,))
p2 = Process(target=worker2, args=(q,))
p1.daemon = True
p2.daemon = True
print(f"主进程的id: {os.getpid()}")
p2.start()
p1.start()
print("主程序运行完毕")
主进程的id: 36116
worker2 开始工作,进程id为:36117
主程序运行完毕
worker2 取到列表中元素0注意:
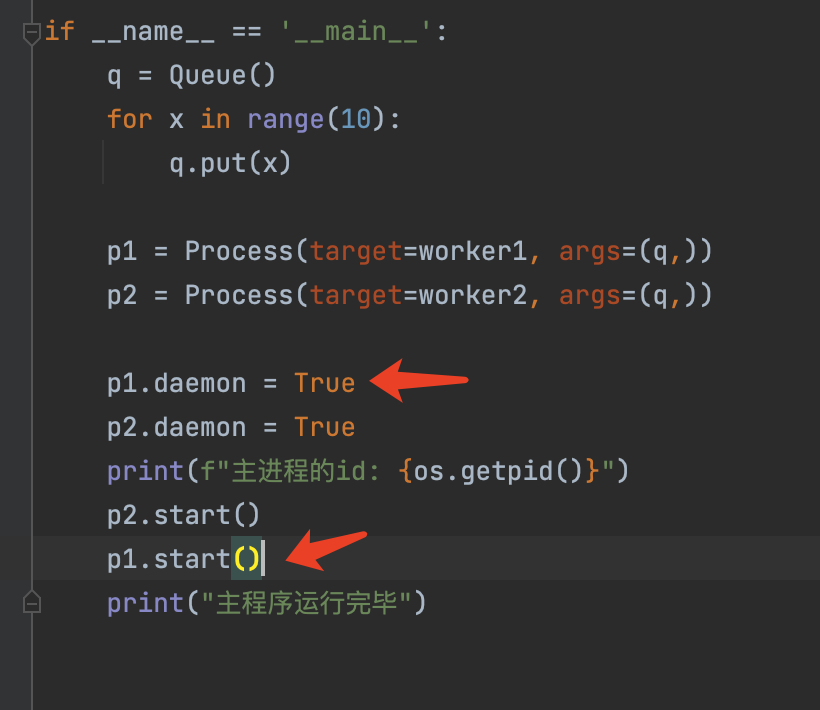
1、设置守护进程
p1.daemon = True默认为False, 为True时,将这个进程设置为守护进程
2、只有未开始执行的进程,才能被设置成守护进程。已经开始执行的进程(已经调用start方法的进程,正在执行的进程)是不可以被设置成守护进程。
先设置
p1.daemon = True
再执行
p1.start()
应用场景:
主进程结束后,需要同时结束其他的子进程。
2.4 进程id
我们通过os模块,来获取进程id
import os
import time
from multiprocessing import Process,Queue
def worker1(data:Queue):
print(f"worker1 开始工作,进程id为:{os.getpid()}")
while not data.empty():
print(f"worker1 取到列表中元素{data.get()}")
time.sleep(1)
def worker2(data:Queue):
print(f"worker2 开始工作,进程id为:{os.getpid()}")
while not data.empty():
print(f"worker2 取到列表中元素{data.get()}")
time.sleep(1)
if __name__ == '__main__':
q = Queue()
for x in range(10):
q.put(x)
p1 = Process(target=worker1,args=(q,))
p2 = Process(target=worker2, args=(q,))
p1.start()
p2.start()
print(f"主进程的id: {os.getpid()}")
print("主程序运行完毕")
worker1 开始工作,进程id为:25249
主进程的id: 25248
主程序运行完毕
worker1 取到列表中元素0
worker2 开始工作,进程id为:25250
worker2 取到列表中元素1
worker1 取到列表中元素2
worker2 取到列表中元素3
worker1 取到列表中元素4
worker2 取到列表中元素5
worker1 取到列表中元素6
worker2 取到列表中元素7
worker1 取到列表中元素8
worker2 取到列表中元素9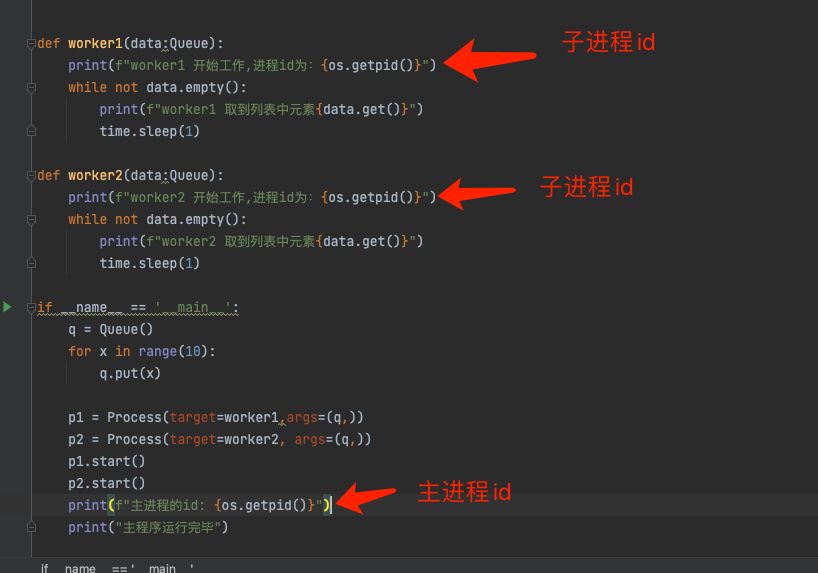
2.5 进程 存活状态is_alive()
p1.is_alive() 为True p1进程当前为存活状态。
2.5 实现自定义多进程类
实现自定义多进程类的模版
from multiprocessing import Process
class MyProcess(Process):
def __init__(self):
super().__init__()
def run(self) -> None:
print("运行")
if __name__ == '__main__':
p1 = MyProcess()
p2 = MyProcess()
p1.start() # start() 会调用MyProcess 中的run方法
p2.start()
1、继承Process
2、重写run方法。start 调用的run方法
三、多线程 threading
java 程序,是多线程。jmeter 与 tomcat 是java编写的,是多线程。
nginx 是C语言编写的。nginx的工作模式,是多进程的,而不是多线程的。
什么场景适用于多线程?
--------间歇性占用CPU的场景适合多线程(IO密集型的)
比如网络io、磁盘读写的时候,是不需要消耗cpu的,此时就可以把cpu让出来,给其他线程,来支持多线程。
举个小例子:
在日常生活中,一个人可以同时熬3锅粥。每锅粥只需要小部分时间的搅拌,其他时间就等待。
工作人员,可以在第一锅粥的等待时间去给第二锅粥做搅拌,合理利用时间,来支持3个线程。
------CPU密集型的不适合多线程。
某个场景,需要一直消耗cpu,把cpu让出去,再拿回来,反而会影响我们的效率。
就比如一个人 做2道数学题。单线程就是:先做完一道,再做下一道。
多线程就是,第一道数据题,先做一分钟,然后下一分钟再去做另一道。然后再回来做第一道数学题。 这种一直需要使用cpu场景,不适合多线程。
import threading
import time
def music(name: str):
print(f"正在播放音乐:{name}")
time.sleep(1)
def play_game(name: str):
print(f"正在{name}游戏")
time.sleep(2)
if __name__ == '__main__':
# 创建线程1
t1 = threading.Thread(target=music, args=("无地自容",), name="线程1")
# 创建线程2
t2 = threading.Thread(target=play_game, args=("英雄联盟",), name="线程2")
# 开始线程
t1.start()
t2.start()
# 阻塞主程序
t1.join()
t2.join()
print("所有线程都结束了")
打印结果:
正在播放音乐:无地自容
正在英雄联盟游戏
所有线程都结束了注意:
1、可以设置每个线程的名字,name=
2、传参,是元组,当只有一个参数时,后面也需要加逗号
3、join() 可以阻塞主程序
3.1 线程锁
多线程时,尽量不要使用全局变量。
操作内存(或者文件)的代码,要上锁。同一时间,只允许一个线程进行访问。
注意:
1、锁住的代码越少越好。
举例子:
多个线程,操作同一个内存
import threading
n = 500000
def work():
global n
for i in range(100000):
n -= 1
if __name__ == '__main__':
t1 = threading.Thread(target=work,name = "线程1")
t2 = threading.Thread(target=work, name="线程2")
t3 = threading.Thread(target=work, name="线程3")
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(n)打印结果:
291376分析:
n=500000
三个线程,每个线程操作n- 1000000 ,最后 n的值应该为 200000。
但是为啥最后值不对呢?
因为在某一个瞬间,多个线程对n 操作时,造成数据错乱。
比如,当n 为 100 时, 线程1 ,与线程2 在这一瞬间同时读取n, 则读到的n都是 100, 再进行-1,
线程1 与线程2 操作完后,n 的值 为 99。 我们期望的结果是 98。 线程1 与线程2 使n 减少2
解决办法,加锁
import threading
n = 500000
lock = threading.Lock()
def work():
global n
for i in range(100000):
# 在对内存进行操作之前加锁
lock.acquire()
n -= 1
# 在对内存进行操作之后释放锁
lock.release()
if __name__ == '__main__':
t1 = threading.Thread(target=work,name = "线程1")
t2 = threading.Thread(target=work, name="线程2")
t3 = threading.Thread(target=work, name="线程3")
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(n)打印结果:
200000 # 在对内存进行操作之前加锁
lock.acquire()
n -= 1
# 在对内存进行操作之后释放锁
lock.release()
也可以用with lock: 这种写法来加锁
import threading
n = 500000
lock = threading.Lock()
def work():
global n
for i in range(100000):
with lock:
n -= 1
if __name__ == '__main__':
t1 = threading.Thread(target=work,name = "线程1")
t2 = threading.Thread(target=work, name="线程2")
t3 = threading.Thread(target=work, name="线程3")
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(n)
贴个链接:
python 多线程就这么简单 - 虫师 - 博客园
虫师写的很通俗易懂且经典。
值得注意的是
threads = []
t1 = threading.Thread(target=music,args=(u'爱情买卖',))
threads.append(t1)
t2 = threading.Thread(target=move,args=(u'阿凡达',))
threads.append(t2)这里添加线程的时候,args内,即使传一个参数,后面也需要跟一个逗号
args=(u'爱情买卖',)
不然会报错。args里面传的是一个元组。
四、线程池、进程池
4.1 线程池
from multiprocessing.pool import ThreadPool
import queue
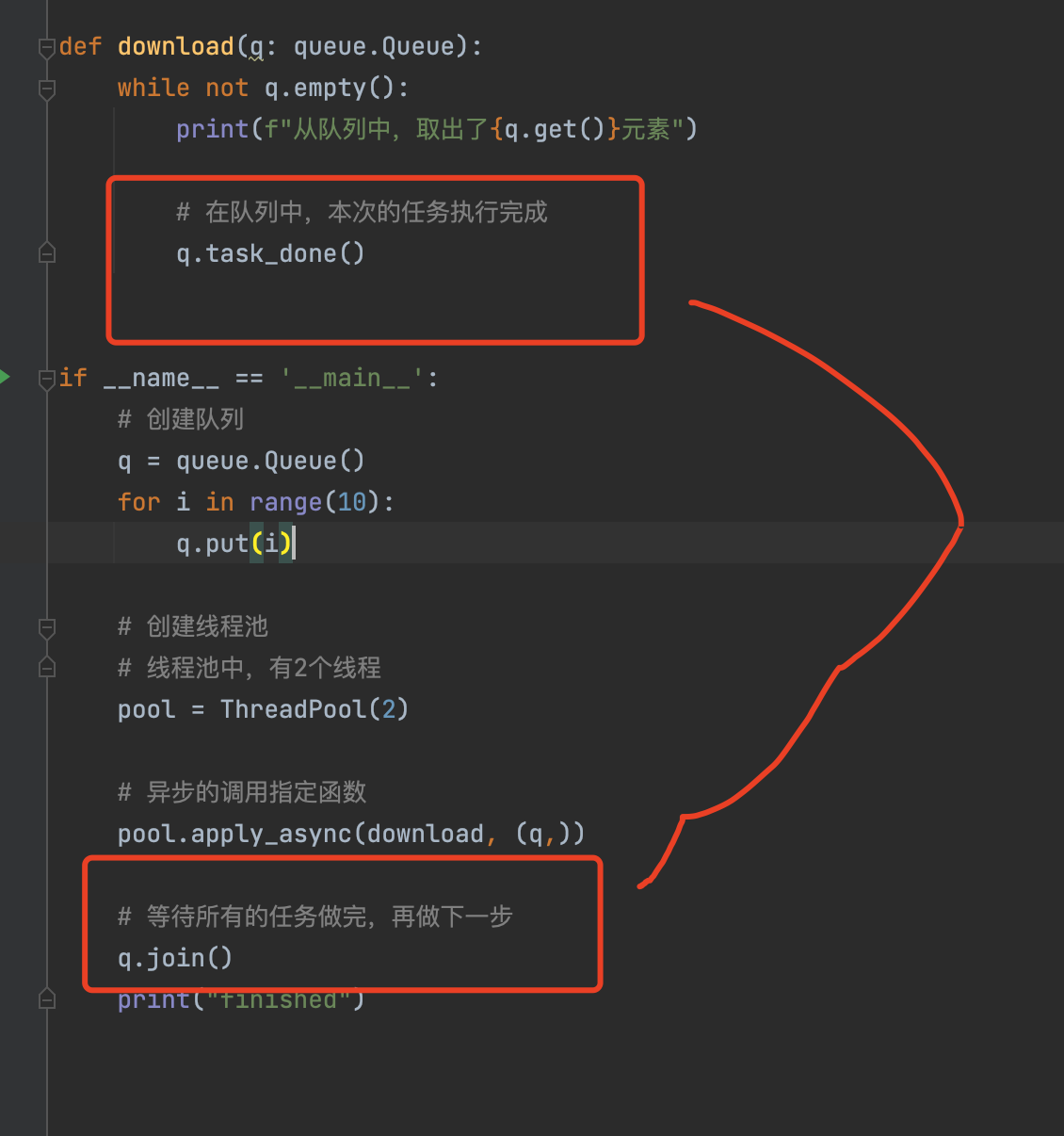
def download(q: queue.Queue):
while not q.empty():
print(f"从队列中,取出了{q.get()}元素")
# 在队列中,本次的任务执行完成
q.task_done()
if __name__ == '__main__':
# 创建队列
q = queue.Queue()
for i in range(10):
q.put(i)
# 创建线程池
# 线程池中,有2个线程
pool = ThreadPool(2)
# 异步的调用指定函数
pool.apply_async(download, (q,))
# 等待所有的任务做完,再做下一步
q.join()
print("finished")
1、线程池引入& 队列引入
from multiprocessing.pool import ThreadPool
import queue2、多个线程异步执行(效率高)
# 异步的调用指定函数
pool.apply_async(download, (q,))
3、队列执行完毕的通知
q.task_done()
队列q,每执行完一次任务。就-1
q.join(),
当q中所有的任务都被执行完成时,才会执行下一行代码。
4.2 进程池
导包
from multiprocessing import Pool4.2.1 pool.map( func, iterable)
import time
from multiprocessing import Pool
def square(x):
print(f"x 的平方是 {x * x}")
time.sleep(1)
return x * x
if __name__ == '__main__':
# 开始运行时间
start_time = time.time()
# 设置进程池中,有2个进程
pool = Pool(2)
result = pool.map(square, [1, 2, 3, 4, 5, 6, 7])
print(f"result is {result}")
# 结束进程池
pool.close()
end_time = time.time()
print(f"总共用了{(end_time - start_time):.2f}")
打印结果:
x 的平方是 1
x 的平方是 4
x 的平方是 9
x 的平方是 16
x 的平方是 25
x 的平方是 36
x 的平方是 49
result is [1, 4, 9, 16, 25, 36, 49]
总共用了4.05注意:
1、pool.map(func, iterable)
func ,函数名称
iterable,一个可迭代对象
可迭代对象[1,2,3,4,5,6,7] 里的每一个元素,分别执行square 函数。(本次启动了2个进程来完成这些)
pool.map(square, [1, 2, 3, 4, 5, 6, 7])这里我们没有调用join 函数,因为map函数可以阻塞主程序。当执行map时,可迭代对象中没有执行完所有的任务时,不会执行下一步主程序代码,所以不需要我们再加join方法。
2、时间保留了小数点后两位
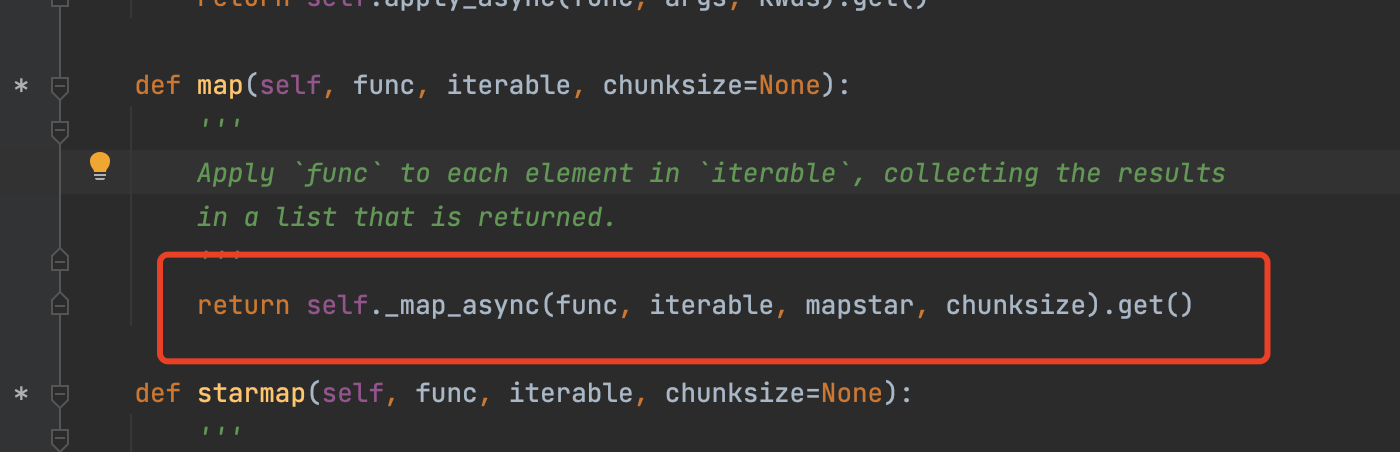
end_time - start_time):.2f3、 查看map源码
4.2.2 pool.map_async( func, iterable)
# -*- coding:utf-8 -*-
# @Author: 喵酱
# @time: 2023 - 02 -26
# @File: jinchengchi1.py
import time
from multiprocessing import Pool
def square(x):
print(f"x 的平方是 {x * x}")
time.sleep(1)
return x * x
if __name__ == '__main__':
# 设置进程池中,有2个进程
pool = Pool(2)
result = pool.map_async(square, [1, 2, 3, 4, 5, 6, 7]).get() # <=> 等价于 pool.map
print(result)
# 结束进程池
pool.close()
执行结果
x 的平方是 1
x 的平方是 4
x 的平方是 9
x 的平方是 16
x 的平方是 25
x 的平方是 36
x 的平方是 49
[1, 4, 9, 16, 25, 36, 49]
pool.map 与 pool.async 有啥区别?
查看map源码。
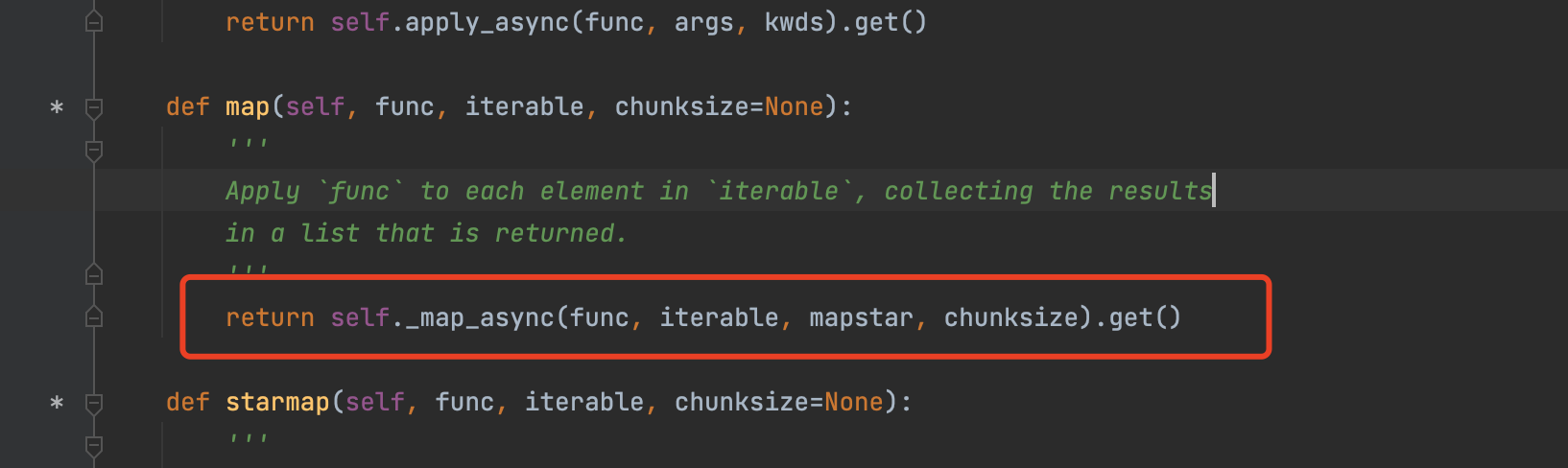
pool.map 比 pool.async 多调用了一个get
感觉好像,多了一个get 函数(取执行结果)之外,没啥区别。。
4.2.3 pool.apply(self, func, args=(), kwds={})
源码:
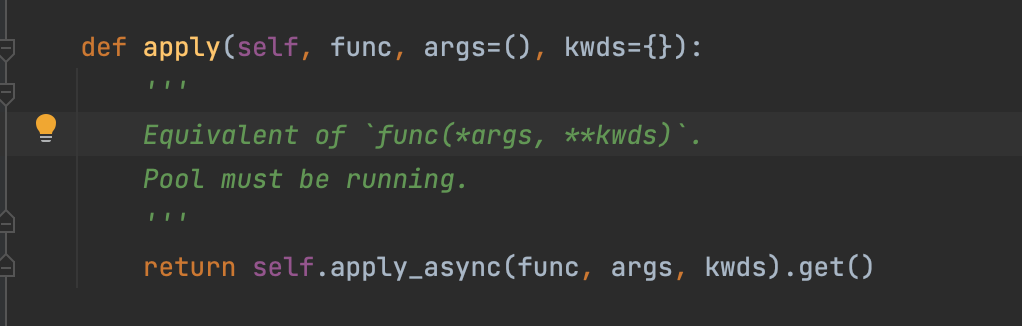
注意,传参,第一个为函数,第二个是 参数,不是可迭代对象。
举例:
import time
from multiprocessing import Pool
def num_add(x,y):
print(f"{x} + {y} = {x+y}")
time.sleep(1)
return x + y
if __name__ == '__main__':
# 设置进程池中,有2个进程
pool = Pool(2)
result = pool.apply(num_add,(2,3),)
print(result)打印结果:
2 + 3 = 5
5apply 与 map 的区别:
apply : 调用函数,传递任意参数
map: 把一个可迭代对象,映射到函数。(每个元素都会分别执行一次函数)
传参:
当函数里有关键参数时,传参需要加一个字典。
举例:
from multiprocessing import Pool
def num_add(x,y,z = 0):
return x + y + z
if __name__ == '__main__':
# 设置进程池中,有2个进程
pool = Pool(2)
result = pool.apply(num_add,(2,3),{"z":4})
print(result)
给函数中的z赋值时,可以加一个字典{"z":4}
4.2.4 pool.apply_async(self, func, args=(), kwds={})
apply_async 与 apply 使用方法是一致的
表现形式上:apply_async 比 apply 多了一个get()
但是本质上, apply 会阻塞主程序,apply_async 不会阻塞主程序。
举例:
import time
from multiprocessing import Pool
def num_add(x,y):
print(f"{x} + {y} = {x+y}")
time.sleep(1)
return x + y
if __name__ == '__main__':
# 设置进程池中,有2个进程
pool = Pool(2)
result = pool.apply_async(num_add,(2,3),)
print(result)
print("运行结束")
打印结果:
<multiprocessing.pool.ApplyResult object at 0x7feb20127550>
运行结束
2 + 3 = 5分析:
由于 子进程比较消耗时间,所以主程序先执行完,子进程后执行完。
子进程没有阻塞主程序的进行。
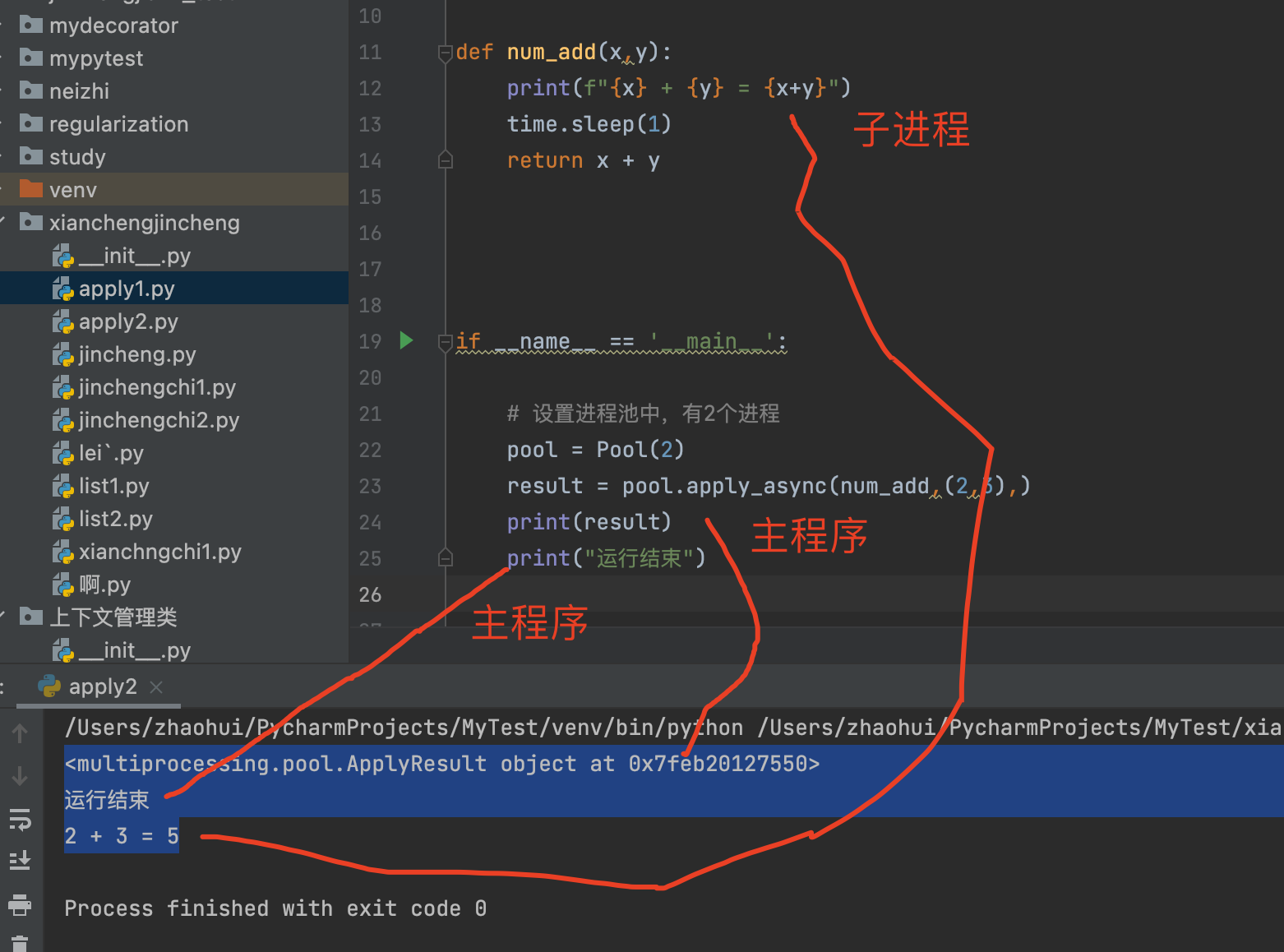
result = pool.apply_async(num_add,(2,3),)
print(result)打印结果:
<multiprocessing.pool.ApplyResult object at 0x7fe018181790>想要获取 result的值,需要加get()
result = pool.apply_async(num_add,(2,3),).get()
print(result)打印结果:
5当 apply_async 加了get() 之后,就等价于 apply 了。
决定 子进程是否会阻塞主程序的因素是get()
有get()就会阻塞主程序。apply 里,有get函数。
五、协程
六、进程的相关知识
6.1 进程的各种状态
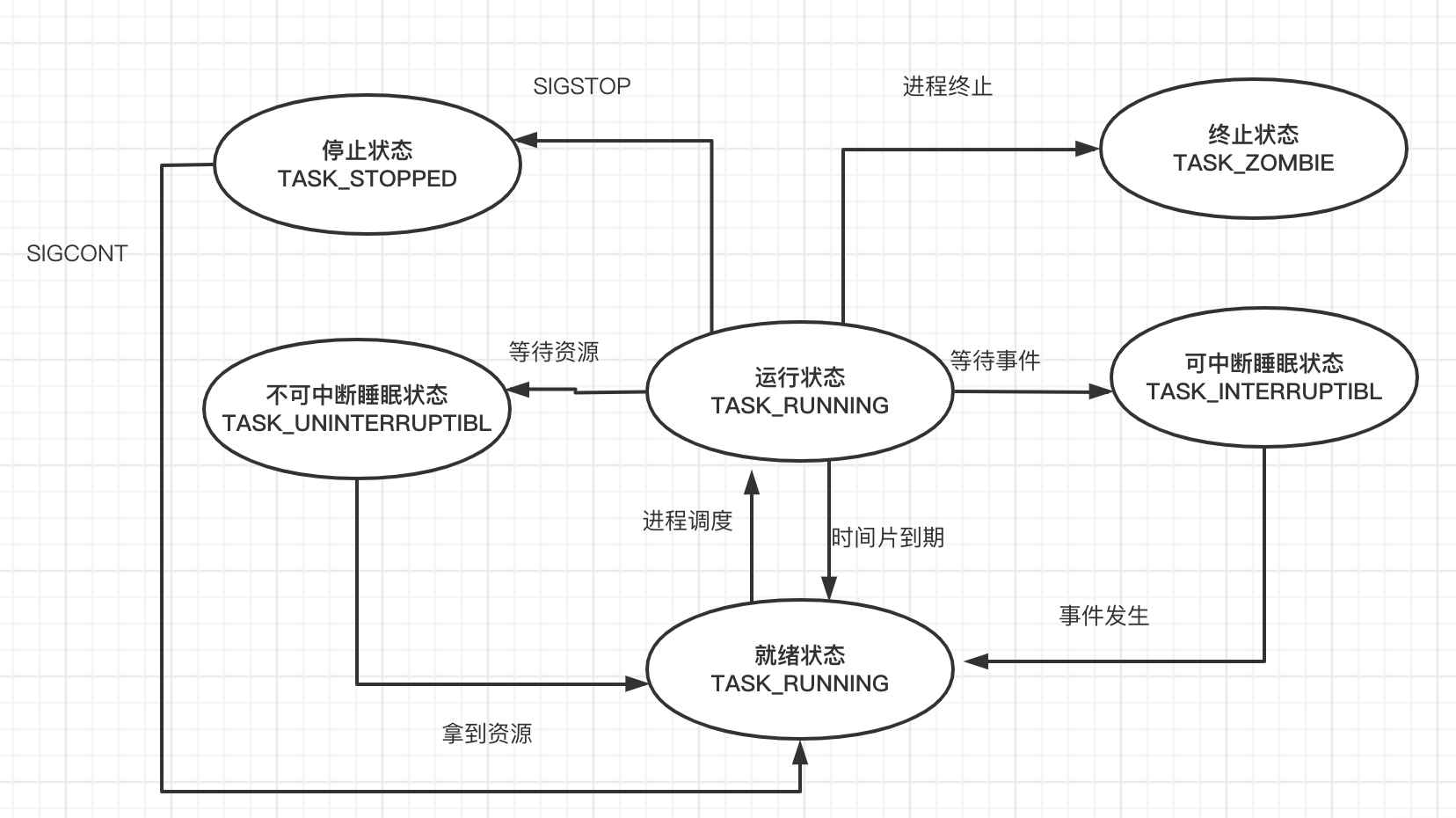
就绪状态(Running):
进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
运行态和就绪态之间的转换是由进程调度程序引起的,进程调度程序是操作系统的一部分。
就绪状态不消耗cpu
运行状态(Running):
进程处于就绪状态被调度后,进程进入执行状态
可中断睡眠状态:
正在运行的进程由于某些事件而暂时无法运行,进程受到阻塞。在条件满足就会被唤醒(也可以提前被信号打断唤醒),进入就绪状态等待系统调用
一般都是等待事务,这个过程很长,不知道啥时候返回结果。比如python中的input
不可中断睡眠状态(磁盘休眠状态):
除了不会因为接收到信号而被唤醒运行之外,他与可中断状态相同。
等待资源,过程很快会返回结果,毫秒级别,不用打断。在满足请求时进入就绪状态等待系统调用。
在这个状态的进程通常会等待IO的结束。
比如:
cpu是在内存里运行的,数据缺失,会去磁盘里取,读取磁盘,等待数据磁盘从数据返回,这个过程是就是不可中断。
这个过程很快。
终止状态/僵尸状态(ZOMBIE):
该进程已经结束了,但是父进程还没有使用wait()系统调用。因为父进程不能读取到子进程退出的返回代码,所以就会产生僵死进程。为了父进程能够获知它的消息,子进程的进程描述符仍然被保留,一但父进程调用wait(),进程描述符就会被释放。该进程无法再被执行
停止状态:
进程停止执行,进程不能投入运行。通常这种状态发生在接受到SIGSTOP、SIGTSTP、SIGTTIN、SIGOUT等信号(停止信号)的时候,正常停止。此外,在调试期间接受到的任何信号,都会使进程进入这种状态。
在linux中,可以使用top命令,查看s列,为每个进程的状态。
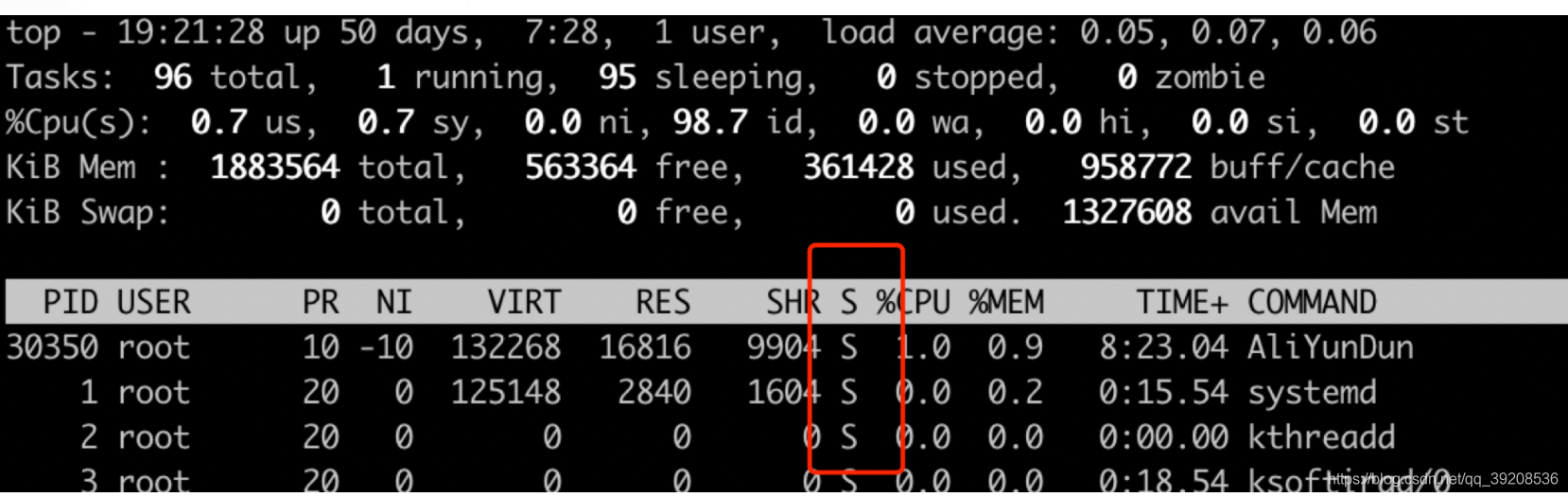
线程的就绪状态与运行状态,都是R(RUNNING)状态。我们无法从R上区分当前进程到底是就绪还是正在运行。
进程与线程:
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
6.2 上下文切换
在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
3种上下文切换情况:
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
进程内核空间/用户空间切换导致CPU上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,CPU 特权等级的 Ring 0 和 Ring 3。进程既可以在用户空间运行,又可以在内核空间中运行。
进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。
比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
系统调用(进程内核空间/用户空间切换)的过程发生 CPU 上下文切换
CPU 寄存器里原来用户态的指令位置,需要先保存起来。
接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。
最后才是跳转到内核态运行内核任务 。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。
所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行。
进程上下文切换
进程是由内核来管理和调度的,进程的切换只能发生在内核态。
所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:
在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;
而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。
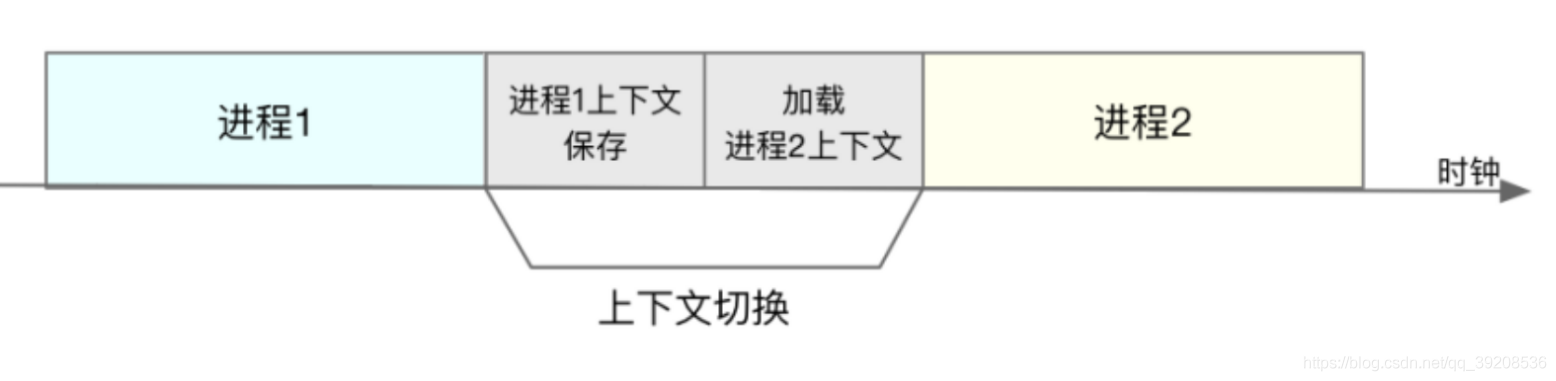
每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。
这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
大量的上下文切换会消耗我们的cpu,导致平均负载升高。
进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。
Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
进程在什么时候才会被调度到cpu上运行:
场景一:
就是一个进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。
场景二:
为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。
这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
场景三:
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
场景四:
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
场景五:
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
场景六:
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。
所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
可以这么理解线程和进程:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程的上下文切换其实就可以分为两种情况:
第一种,前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。
中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题