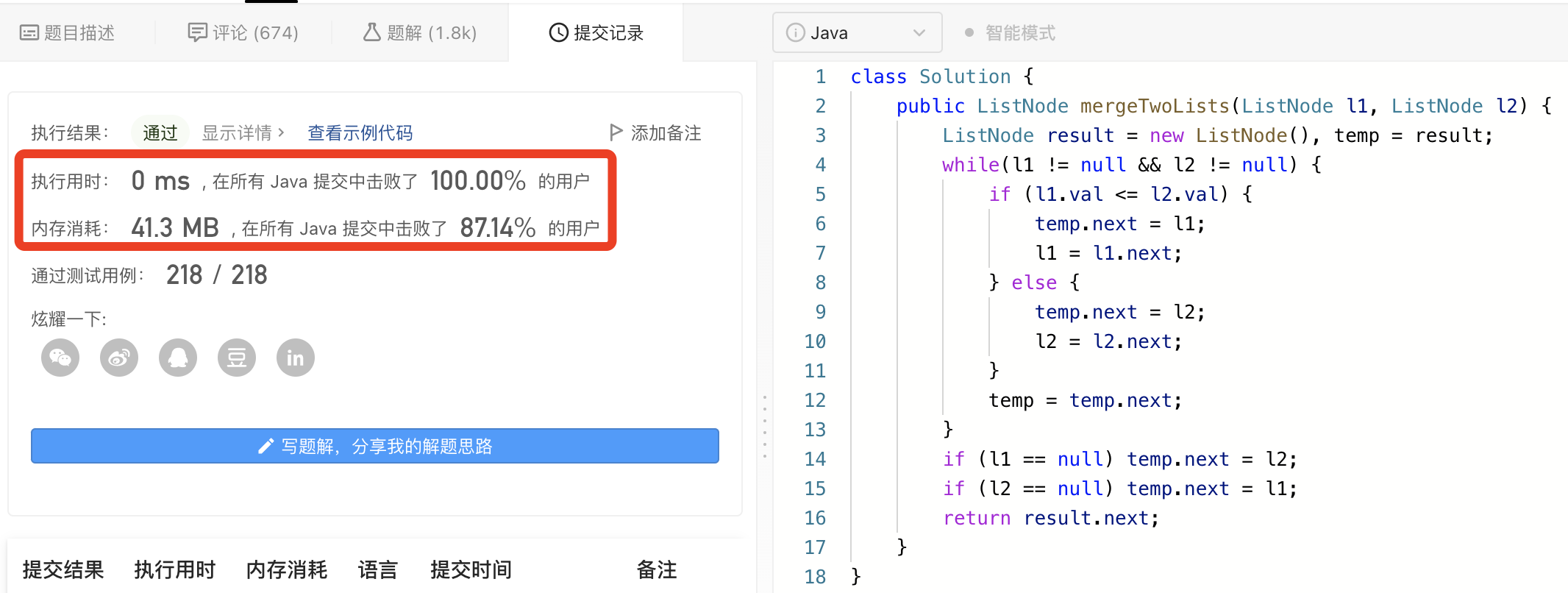
正则表达式:
英文Regular Expression,是计算机科学的一个重要概念,她使用一种数学算法来解决计算机程序中的文本检索,匹配等问题,正则表达式语言是一种专门用于字符串处理的语言。在很多语言中都提供了对它的支持,re模块就是我们python中关于正则表达式的第三方模块,它可以帮我们解决下面的问题:
检索:通过正则表达式,从字符串中获取我们想要的部分、匹配:判断给定的字符串是否符合正则表达式的过滤逻辑
很多语言都有正则表达式比如:Java javascript python php c c++........等等。
re模块中有很多函数?
re.compile()
re.match()
re.findall()
re.search()
re.sub()
re.split()首先给大家讲一下这些函数的用法:
1.re.comiple(pattern,flags=0)
将常用的正则表达式编译成为一个正则表达式对象,函数本身并不具备特殊意义,需要搭配findall(), search(), match()等常用函数一起使用。
其中第一个参数 “pattern“为正则表达式,第二个参数“flags”编译标志位,用于扩展匹配字符的功能
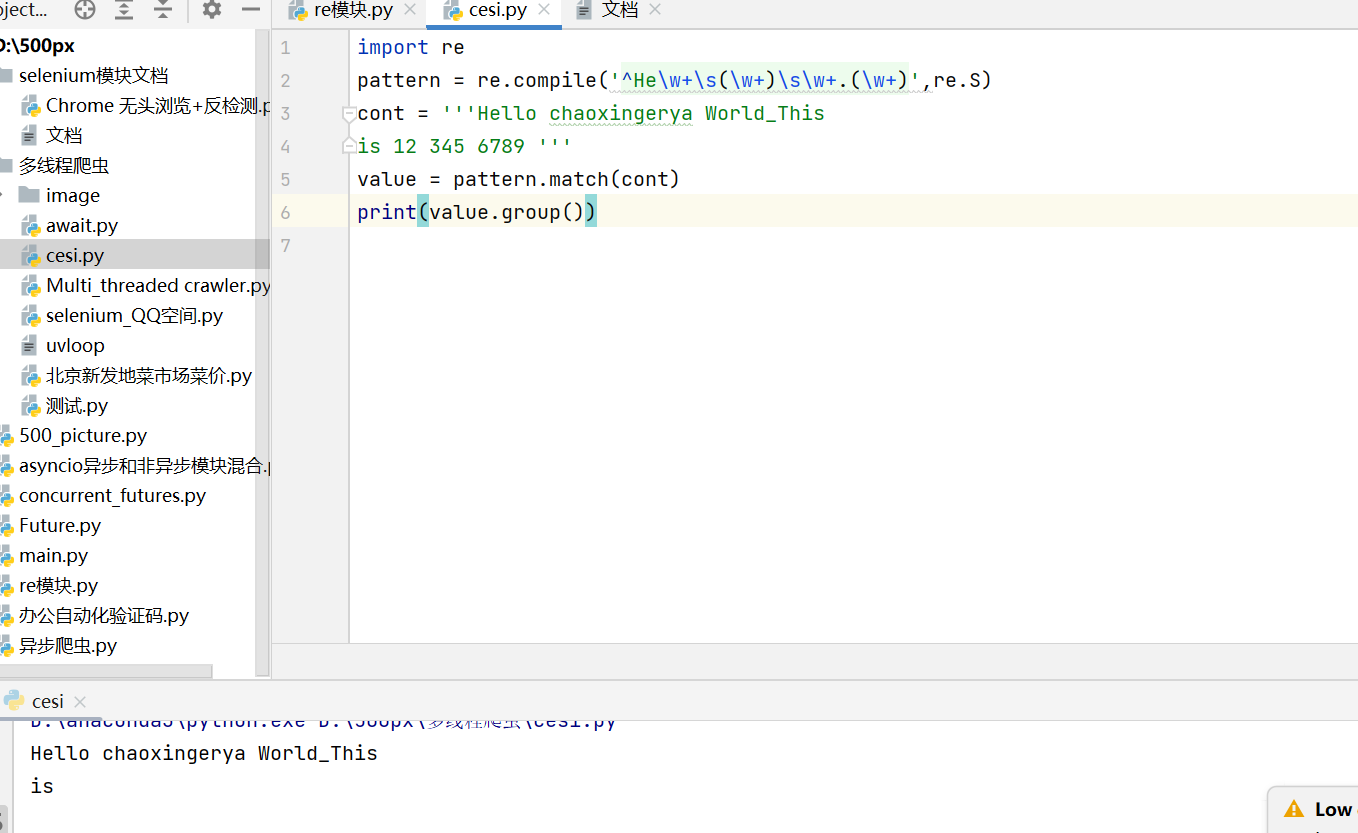
import re
pattern = re.compile('^He\w+\s(\w+)\s\w+.(\w)+',re.S)
cont = '''Hello chaoxingerya World_This
is 12 345 6789 '''
value = pattern.match(cont)
print(value.group(1))其中第一个参数为:'^He\w+\s(\w+)\s\w+.+(\w)+' 正则表达匹配式
符号:“^”表示从什么开始,题目中是以“He”开始,符号“\w”表示匹配大写英文字母,数字、下划线即:“a-z、A-Z、0-9、_”,符号“+”表示 匹配前一个字符至少1次到n次,这两个字符组合在题目中用来表示:“llo”,符号“\s”表示匹配空格 也就是tab键,在题目中用来匹配“Hello“和 “chaoxingerya“之间的空格键,符号“(\w+)“,是由小括号“()”和“\+”组成,符号“()”的作用是将“()“中的字符作为⼀个分组,在后期可以通过value.group(1)将第一个分组中的内容“chaoxingerya”拿出来,符号“\s“用来匹配题目中“chaoxingerya”和 World_This之间的空格,\w+用来匹配"World_This",
符号点“ . ”用来匹配
'''Hello chaoxingerya World_This
is 12 345 6789 '''
之间的换行,符号“(\w)+“,用来匹配题目中“is”,其中剩余的数字我并没有对它进行匹配,如果没
第二个参数为:re.S 功能标志位,扩展正则字符的匹配
S :表示 . (点符号)在正则表达式中包括换行符在内的任意字符,也就是所有字符
re.match(pattern,string)
pattern :匹配正则语法,可以单独写也可以有re.compile()编译的对象得来。
string 需要被匹配的字符串
并且与group搭配使用
总是从被匹配对象的第一个字符开始,如果匹配你到了第一个字符则继续往下匹配,如果第一个字符没有匹配得到则会报错
为了给大家讲清楚我直接搞了csdn一片文章的博客链接方便大家爬虫学习
import re
cont = '<a data-report-query="spm=1000.2115.3001.5927" data-report-click="{"spm":"1000.2115.3001.5927","dest":"https://csdnnews.blog.csdn.net/article/details/129187745","extra":"{\"fId\":558,\"fName\":\"floor-www-index\",\"compName\":\"www-swiper\",\"compDataId\":\"www-headhot\",\"fTitle\":\"\",\"pageId\":141}"}" target="_blank" href="https://csdnnews.blog.csdn.net/article/details/129187745?spm=1000.2115.3001.5927" class="title" data-v-0045335f="">Linus 怒怼:请不要提交垃圾!</a>'
ret = re.match("^<a.*?([a-z]+://[a-z./0-9]+\?).*?>",cont)
print(ret.group(1))我将这篇文章的链接所在的标签给你拿出来
<a data-report-query="spm=1000.2115.3001.5927" data-report-click="{"spm":"1000.2115.3001.5927","dest":"https://csdnnews.blog.csdn.net/article/details/129187745","extra":"{\"fId\":558,\"fName\":\"floor-www-index\",\"compName\":\"www-swiper\",\"compDataId\":\"www-headhot\",\"fTitle\":\"\",\"pageId\":141}"}" target="_blank" href="https://csdnnews.blog.csdn.net/article/details/129187745?spm=1000.2115.3001.5927" class="title" data-v-0045335f="">Linus 怒怼:请不要提交垃圾!</a>
我需要其中在href中的链接地址:
https://csdnnews.blog.csdn.net/article/details/129187745
我写的正则匹配式为:
^<a.*?([a-z]+://[a-z./0-9]+\?).*?>其中对符号解释如下:
符号:“^”表示从那个地方开始,"^<a" 表示从<a开始,符号“ [a-z]+“[]是定义匹配的字符范围,[a-z],说明要匹配的文本内容的某一位置是a,b,c,d,....., q, y, z的某一区间,在本次为了匹配 https,因为 [a-z]加上了“+”表示匹配多个,如果不加只能匹配一个。符号:“://“为了匹配文本内容的://,为何是这样写的,因为正则中没有什么特殊符号用来表示,:或//,在正则表达式中可以用原来的字符匹配,只要不涉及到正则和普通字符相关联的特殊字符就好,比如 : 符号 "?",正则中符号"?",表示非贪婪模式,至多匹配一个,要是一个也没有也不会报错,在符号识别中它就是普通问号,用在正则匹配表达式中,就必须要加上符号“\”,让符号恢复原意。
3.re.search(pattern,string,flags)
pattern: 正则匹配表达式
string: 被匹配的文本
flags :标志位,扩展字符的效果
作用:re.search会匹配整个字符串,并返回第一个成功的匹配,如果匹配成功则返回结果,匹配失败则返回None,它和re.match()的区别在一个是从字符串首字母匹配文本内容,一个是从任意位置匹配内容。并且re.search会扫描整个被匹配对象,只会返回一个被成功匹配的对象,如果这列被匹配的文本内容中没有符合要求的,则会返回None
re.match从字符串首字母的开始匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到符合正则表达式的文本内容。
案例:
import re
import requests
cont = 'dd44--32ff_88'
ret = re.search("\d+",cont)
print(ret.group())
仅返回了44 为什么没有返回32 我说过了re.search只会返回第一个符合正则表达式匹配的内容,其他no pass。
如果是matchhanshune?
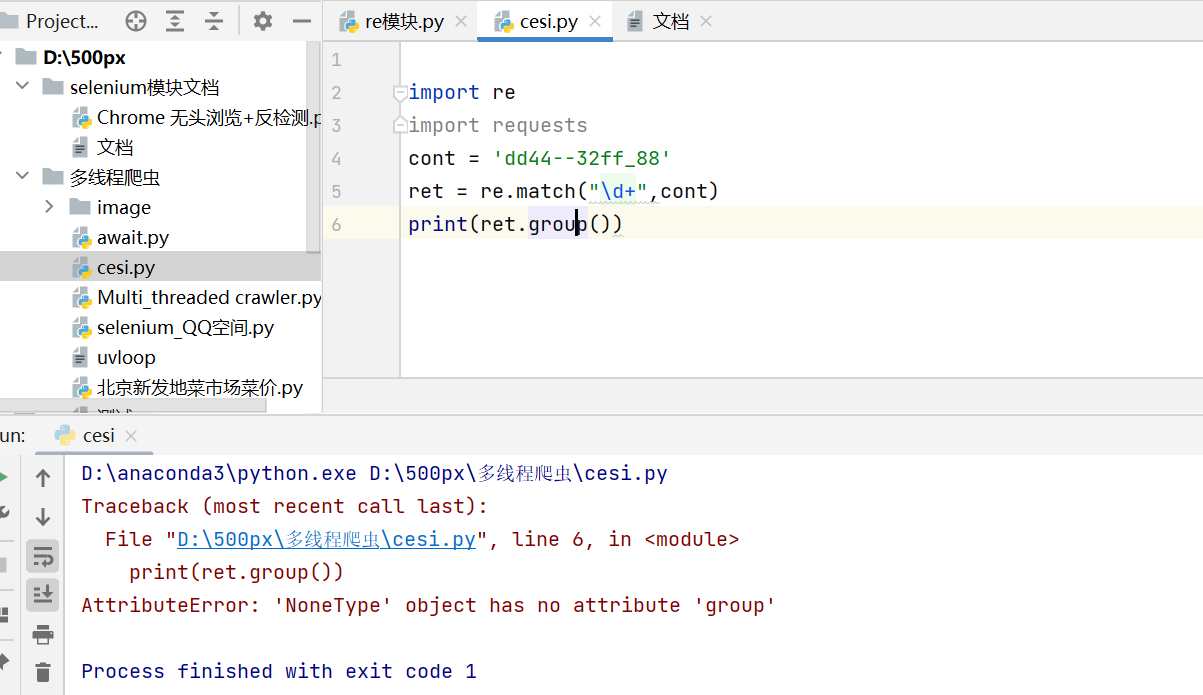
直接pass掉了,为啥呢?我说了,re.match()方法会从被匹配内容首字母开始匹配如果不符合,则直接pass掉,显然 被匹配对象 dd44--32ff_88开始位置是英文单词,所以用\d 以数字匹配显然是不对的。
我通过正确的方式去匹配:
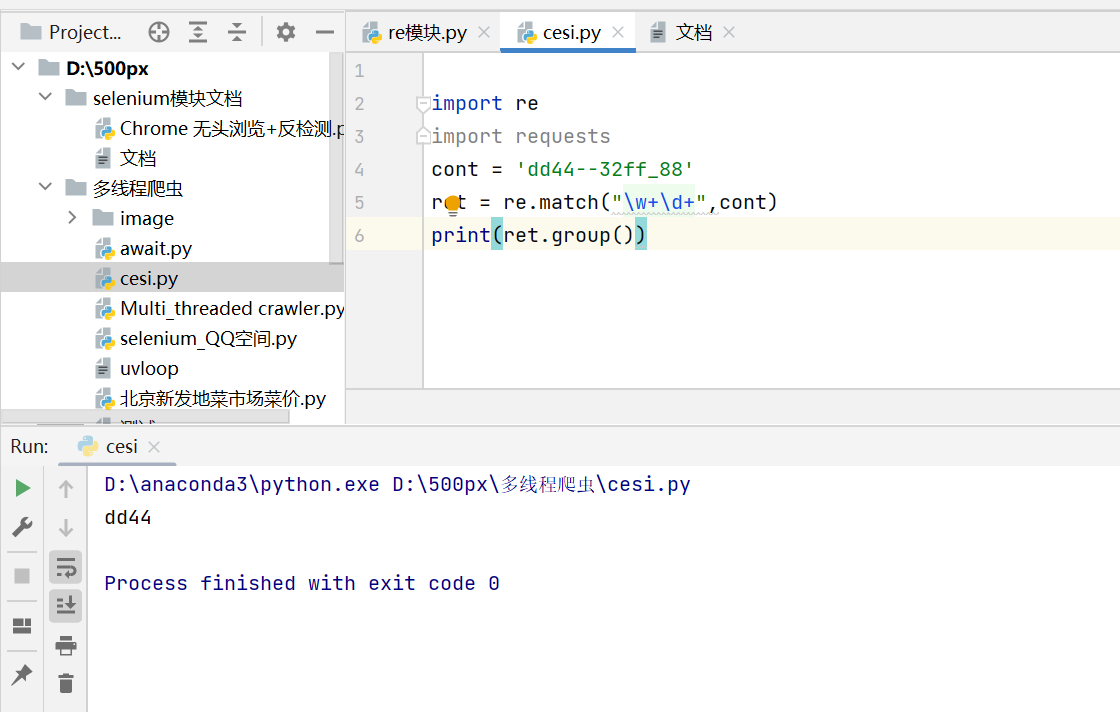
显然可以成功匹配但是并不是我们想要的纯数字内容
re.findall(pattern, string, flags)
pattern : 编译的正则表达式
string :被匹配的文本内容
flags : 扩展字符的特殊功能
re.findall 函数作用 :
在被匹配对象中找到符合正则表达式所编译的所有文本内容,将结果返回为一个列表,如果没有找到匹配的,则返回空列表。特别注意的是: match ()和search() 只会匹配首次遇到且符合结果的文本内容,而 findall()则会匹配所有内容。findall没有group参数
案例测试:
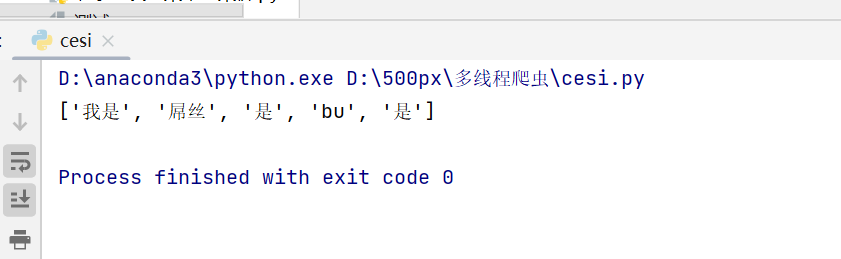
import re
import requests
cont = '我是44--54屌丝77是_bu_是88'
ret = re.findall("[\u4e00-\u9fa5a-z]+",cont)
print(ret)符号“[\u4e00-\u9fa5]“用来匹配中文字符,为什么后面加了符号“a-z”因为文本内容中还有个“bu“,为什么我还加上符号“+”因为符号“+”,表示匹配多次如果不加则会匹配一个中文字符,加了可以返回多个
三,关于函数中flags : 扩展字符的特殊功能内容及其作用
flags 标志位参
re.I(re.IGNORECASE) 使匹配对大小写不敏感
re.L(re.LOCAL) 做本地化识别(locale-aware)匹配
re.M(re.MULTILINE) 多行匹配,影响 ^ 和 $
re.S(re.DOTALL) 使 . 匹配包括换行在内的所有字符
re.U(re.UNICODE)根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.正则匹配其实并不是很难,重点是函数太多注意的事项太多,常见及其常用的就是那么几个,在这个函数我认为最常用的的是,re.findall, re.compile,re.sub
有很多我没有写出来不是不重要,我准备在下一篇文章中写出来,近期我会持续更新python面向对象编程,异步编程,python高级进阶,爬虫js逆向技术+app逆向