目录
一.TF-IDF
二.LSI
三.相似度
四.主题和主题分布
五. LDA计算的相似度
六.LDA过程
七.主题
八.主题和主题分布
九.数据处理流程
十.常用正则表达式
十一.代码
一.TF-IDF

二.LSI

三.相似度

四.主题和主题分布

五. LDA计算的相似度

六.LDA过程

七.主题

八.主题和主题分布
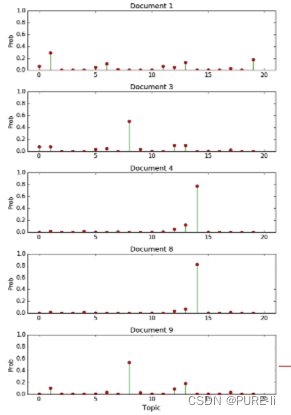
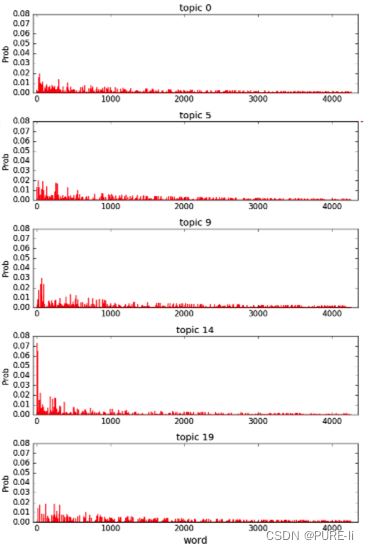
九.数据处理流程
1.获取QQ群聊天记录:txt文本格式
2.整理成“QQ号/时间/留言”的规则形式
正则表达式
清洗特定词:表情、@XX
使用停止词库
获得csv表格数据
3.合并相同QQ号的留言
长文档利于计算每人感兴趣话题
4.LDA模型计算主题
调参与可视化
5.计算每个QQ号及众人感兴趣话题
十.常用正则表达式
匹配中文字符: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空白行:\n\s*\r
匹配HTML标记:<(\S*?)[^>]*>.*?</\1>|<.*? />
匹配首尾空白字符:^\s*|\s*$
匹配Email地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL:[a-zA-z]+://[^\s]*
匹配帐号合法(5-16位,字母开头,允许字母数字下划线):^[a-zA- Z][a-zA-Z0-9_]{4,15}$
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
匹配腾讯QQ号:[1-9][0-9]{4,}
匹配中国邮政编码:[1-9]\d{5}(?!\d)
匹配身份证:\d{15}|\d{18}|\d{17}[xX]
匹配ip地址:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
匹配特定数字:
匹配正整数:^[1-9]\d*$
匹配负整数:^-[1-9]\d*$
匹配整数:^-?[1-9]\d*$
匹配非负整数(正整数 + 0):^[1-9]\d*|0$
匹配非正整数(负整数 + 0):^-[1-9]\d*|0$
匹配正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$
匹配负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$
匹配浮点数:^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
匹配非负浮点数(正浮点数 + 0):^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
匹配非正浮点数(负浮点数 + 0):^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ 匹配特定字符串:
匹配由26个英文字母组成的字符串:^[A-Za-z]+$
匹配由26个英文字母的大写组成的字符串:^[A-Z]+$
匹配由26个英文字母的小写组成的字符串:^[a-z]+$
匹配由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
匹配由数字26个英文字母或下划线组成的字符串:^\w+$
十一.代码
if __name__ == '__main__':
f = open('LDA_test.txt')
stop_list = set('for a of the and to in'.split())
# texts = [line.strip().split() for line in f]
# print 'Before'
# pprint(texts)
print ('After')
texts = [[word for word in line.strip().lower().split() if word not in stop_list] for line in f]
print ('Text = ')
pprint(texts)
dictionary = corpora.Dictionary(texts)
print (dictionary)
V = len(dictionary)
corpus = [dictionary.doc2bow(text) for text in texts]
corpus_tfidf = models.TfidfModel(corpus)[corpus]
# corpus_tfidf = corpus
print( 'TF-IDF:')
for c in corpus_tfidf:
print( c)
print ('\nLSI Model:')
lsi = models.LsiModel(corpus_tfidf, num_topics=2, id2word=dictionary)
topic_result = [a for a in lsi[corpus_tfidf]]
pprint(topic_result)
print ('LSI Topics:')
pprint(lsi.print_topics(num_topics=2, num_words=5))
similarity = similarities.MatrixSimilarity(lsi[corpus_tfidf]) # similarities.Similarity()
print ('Similarity:')
pprint(list(similarity))
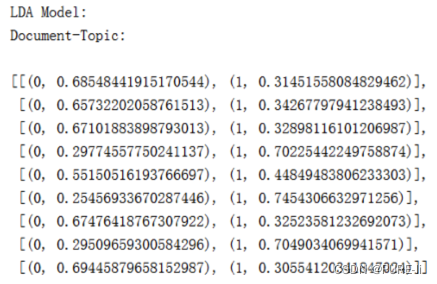
print ('\nLDA Model:')
num_topics = 2
lda = models.LdaModel(corpus_tfidf, num_topics=num_topics, id2word=dictionary,
alpha='auto', eta='auto', minimum_probability=0.001, passes=10)
doc_topic = [doc_t for doc_t in lda[corpus_tfidf]]
print ('Document-Topic:\n')
pprint(doc_topic)
for doc_topic in lda.get_document_topics(corpus_tfidf):
print (doc_topic)
for topic_id in range(num_topics):
print ('Topic', topic_id)
# pprint(lda.get_topic_terms(topicid=topic_id))
pprint(lda.show_topic(topic_id))
similarity = similarities.MatrixSimilarity(lda[corpus_tfidf])
print ('Similarity:')
pprint(list(similarity))
hda = models.HdpModel(corpus_tfidf, id2word=dictionary)
topic_result = [a for a in hda[corpus_tfidf]]
print ('\n\nUSE WITH CARE--\nHDA Model:')
pprint(topic_result)
print ('HDA Topics:')
print (hda.print_topics(num_topics=2, num_words=5))
![洛谷P5015 [NOIP2018 普及组] 标题统计 C语言/C++](https://img-blog.csdnimg.cn/9d776aeee0144218bba5eb98c6c262e1.png)